Learning to Compose Task-Specific Tree Structures论文笔记
由于正在看的代码中用到了Gumbel tree LSTM这个模型,简单对这篇论文做了个笔记。
Gumbel-Softmax本文提出的Gumbel tree LSTM是一种新的RvNN结构,它不需要结构化的数据,在没有明确指导的情况下学习构造特定于任务的树结构。们的Gumbel Tree LSTM模型基于树形结构的长期短期记忆(Tree LSTM)架构(Tai、Socher和Manning 2015;Zhu、Sobihani和Guo 2015),这是最著名的RvNN变体之一。为了学习如何在不依赖于结构化输入的情况下组合特定于任务的树结构,我们的模型引入了组合查询向量来度量组合的有效性。使用由组合查询向量计算的有效性得分,我们的模型递归地选择组合,直到只剩下一个表示。我们使用直通(ST)Gumbel Softmax estimator(Jang,Gu,and Poole 2017;Maddison,Mnih,and Teh 2017)对训练阶段的作文进行抽样。ST-Gumbel-Softmax估计器使离散采样操作在后向过程中保持连续,因此我们的模型可以通过标准的后向传播进行训练。此外,由于计算是按层执行的,因此模型易于实现,并且自然支持批处理计算。通过对自然语言推理和情感分析任务的实验,我们发现我们提出的模型优于或至少可以与以前的句子编码模型相媲美,并且收敛速度明显快于它们。
工作贡献如下:
我们设计了一个新的句子编码架构,它可以从纯文本数据中学习如何组合特定于任务的树;我们从实验中证明,所提出的架构优于或有竞争力的最先进的模型。我们还观察到我们的模型比其他模型收敛得更快;具体地说,我们的模型在所有已进行的实验中都明显优于以前的基于解析树的RvNN工作,从中我们假设语法解析树可能不是每个任务的最佳结构,并且每个任务的最佳结构可能不同。
Model Description
架构是建立在树状结构的长短期记忆网路架构的基础上,在TreeLSTM架构中引入了一些额外的组件,以允许模型以自底向上的方式动态组合树结构,并有效地将句子编码为向量。
Tree-LSTM
跟标准的LSTM结构一样,每个单元都包括类似的输入门It,输出门Ot,单元状态ct和隐层输出ht.不同的是Tree-LSTM单元中门向量和单元状态的更新依赖于所有与之相关的子单元的状态,另外,相比于Standard LSTM的单个遗忘门,Tree LSTM拥有多个遗忘门,分别对应当前单元的子单元。LSTM具有超时保存序列信息的优良性能,同时更复杂的计算单元,因此在众多的序列任务中取得了很好的效果,仅仅基于LSTM结构至今仍然是一个线性链。然而,自然语言表现出自然地将单词与短语组合在一起的句法性质。本文提出了树结构的LSTM,将LSTM推广到树状的网络拓扑结构,Tree-LSTMs在预测两个句子的语义相关性和电影评论中进行情感分类两个方面上进行实验,证明都要优于现有的系统。
如图所示,上面的为Lstm的线性,下面图是Lstm的树形:
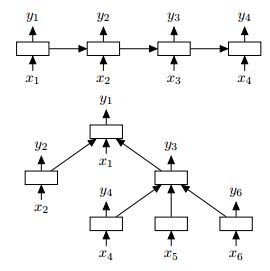
Tree-LSTM中的每一个单元都有一个输入向量xj。在我们的应用当中,每一个xj是一句话中一个单词的向量表示。每一个节点的输入单词依赖于当前网络的树结构。例如,在一个由依存树构成的Tree-LSTM中,树中每个结点都是以相应首要词的向量作为输入,而在一个由constituency tree构成的Tree-LSTM中,叶结点则以相应单词向量作为输入。
树结构的长期短期记忆网络(TreeLSTM)(Tai、Socher和Manning 2015;Zhu、Sobihani和Guo 2015)是RvNN的一个优雅变体,它使用与长期短期记忆(LSTM)相似的机制控制从孩子到父母的信息流(Hochreiter和Schmidhuber 1997)。树LSTM在计算父表示时引入单元状态,帮助每个单元捕获远处的垂直依赖关系。TreeLSTM复合函数(Tai等人,2015)将LSTM神经网络层概括为基于树而非基于序列的输入,它与LSTM共享将中间状态表示为一对活动状态表示~h和一个内存表示~c的思想。以下是模型用于从其子代计算父代表示的公式:
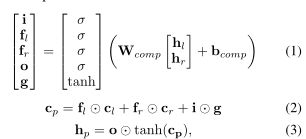
其中σ是激活函数 o是元素的乘积,hl和cl和hr和lr对是从堆栈中弹出的两个输入树节点
Gumbel-Softmax
Gumbel Softmax是一种在网络中利用离散随机变量的方法。由于它通过使一个one-hot向量连续来逼近从分类分布中采样的一个one-hot向量,因此可以使用重新参数化技巧和标准反向传播来计算模型参数的梯度。
在前向过程中,它将从Gumbel-Softmax分布中采样的连续概率向量y离散化,进入一个one-hot向量yST=(yST 1,···,yST k),其中
![]()
在后向通道中,它只使用连续的y,因此误差信号仍然能够反向传播。关于向前和向后传球的可视化,请参见图1。当模型需要直接利用离散值时,例如当模型基于从分类分布中提取的样本改变其计算路径时,ST-Gumbel-Softmax估计器是有用的。
Gumbel Tree-LSTM
在我们的Gumbel树LSTM模型中,一个由N个单词组成的输入句子被表示为一个单词向量序列(x1,··,xN),其中xi∈RDx。我们的基本模型对每个xi应用仿射变换以获得初始隐藏状态和单元状态:
![]()
我们称之为叶变换。

重复此过程,直到模型到达第N层,只剩下一个节点。值得注意的是,在每个阶段选择最佳节点对的特性类似于 easy-first parsing(Goldberg and Elhadad 2010)。
Parent selection 由于没有向模型提供有关输入的树结构的信息,因此需要一种特殊的机制,使模型能够学习以端到端的方式组合特定于任务的树结构。我们现在描述从非结构化句子构建树结构的机制。首先,我们的模型引入了可训练合成查询向量q。组合查询向量度量表示的有效性。具体来说,表征的有效性得分r=[h;c]由q·h定义。在t层,模型使用Eqs1-3计算父表示的候选项。然后,它计算每个候选人的有效性得分,并将其规范化。
在训练阶段,该模型使用上述ST-Gumbel-Softmax估计器从基于vi加权的候选样本中抽取父样本。由于反向传播过程中使用了连续的GumbelSoftmax函数,误差反向传播信号可以安全地通过采样操作,因此该模型能够学习构造特定于任务的树结构,以最小化反向传播的损失。在验证(或测试)阶段,模型只需选择使有效性得分最大化的父项。父选择的示例如图所示。
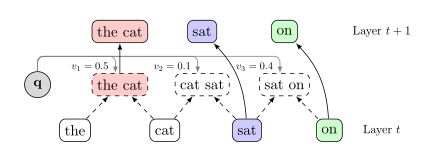
父选择的示例。在t层(底层),模型计算父候选对象(中间层)。然后使用查询向量q(表示为v1、v2、v3)计算每个候选的有效性得分。在训练时间内,利用ST-Gumbel-Softmax估计器对v1、v2、v3加权后的候选节点中的父节点进行采样,在测试时间内选择有效性最高的候选节点。在t+1层(顶层),所选候选对象(“cat”)的表示用作父对象,其余的从t层(“sat”、“on”)的表示复制。最好用彩色观看。
LSTM-based leaf transformation (基于LSTM的叶变换)用仿射变换(等式10)的基本叶变换不考虑关于输入的整个句子的信息,因此仅基于局部信息执行父选择。SPINN(Bowman等人。2016)通过使用跟踪LSTM来解决这个问题,跟踪LSTM按顺序读取输入单词。跟踪LSTM使得SPINN模型混合,该模型同时利用了树结构合成和顺序读取的优点。但是,跟踪LSTM不适用于我们的模型,因为我们的模型不使用shift-reduce解析或维护堆栈。在跟踪LSTM的情况下,我们的模型对输入表示应用LSTM,以向每个叶节点提供有关前面单词的信息:
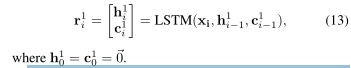
从实验结果来看,我们验证了应用于叶节点的LSTM比基本的叶变压器有很大的增益。