MATLAB 随机森林超参数优化教程(Hyperparameters Tuning of Random Forest)
本文主要内容翻译自MATLAB官网,此外也增加了一些自己的注释,参考链接如下:
Tune Random Forest Using Quantile Error and Bayesian Optimization
使用分位数误差和贝叶斯最优化方法进行随进森林调参
以下例子将展示如何使用分位数误差来实现基于贝叶斯最优化的随机森林的超参数调整。如果您计划使用模型预测条件分位数(而不是条件平均值),那么更合适使用分位数误差(而不是均方误差)调优模型。
1 加载和预处理数据
加载carsmall数据集,构建一个模型,该模型能够根据汽车的acceleration, number of cylinders, engine displacement, horsepower, manufacturer, model year, and weight(加速度、汽缸数、发动机排量、马力、制造商、车型年份和重量)来预测汽车的燃油经济性中值,其中将Cylinders、Mfg和Model_Year视为分类变量
load carsmall
Cylinders = categorical(Cylinders);
Mfg = categorical(cellstr(Mfg));
Model_Year = categorical(Model_Year);
X = table(Acceleration,Cylinders,Displacement,Horsepower,Mfg,...
Model_Year,Weight,MPG);
rng('default'); % For reproducibility
%categorial 是MATLAB数据类型,可将数值分配给有限组的离散类别
%rng default可以用来产生固定的随机数控制器
2 指定调整参数
考虑调整的参数有:
- 随机森林中树的复杂度(深度)。复杂的树会过拟合,简单的树拟合效果不佳。 因此,指定每个叶片的最小观测次数不超过20次。
- 当树生长时,每个节点上要采样的预测数量。指定从1到所有预测期进行抽样。
bayesopt函数用于实现贝叶斯优化,使用该函数要求将上述指定调整参数以optimizableVariable对象传递。
maxMinLS = 20;
minLS = optimizableVariable('minLS',[1,maxMinLS],'Type','integer');
numPTS = optimizableVariable('numPTS',[1,size(X,2)-1],'Type','integer');
hyperparametersRF = [minLS; numPTS];
hyperparametersRF是一个2乘1的OptimizableVariable对象数组
还应该考虑调整集合中数的数量。bayesopt倾向于选择包含多棵树的随机森林,因为学习器越多的集合越准确。 如果想用由更少的树组成的集合或者想减少可用的计算资源的消耗,那么可以考虑在其他变量之外对树的数量进行单独调整,或者对包含过多学习器的模型进行惩罚。
3 定义目标函数
定义一个目标函数用于贝叶斯优化算法进行优化。该函数应满足以下条件:
① 以要调整的参数为输入;
② 使用TreeBagger训练随机森林。 在TreeBagger调用中,指定要调优的参数并指定返回袋外(out- out- bag)索引;
③ 根据中位数估计袋外分位数误差;
④ 返回袋外分位数误差
function oobErr = oobErrRF(params,X)
%oobErrRF Trains random forest and estimates out-of-bag quantile error
% oobErr trains a random forest of 300 regression trees using the
% predictor data in X and the parameter specification in params, and then
% returns the out-of-bag quantile error based on the median. X is a table
% and params is an array of OptimizableVariable objects corresponding to
% the minimum leaf size and number of predictors to sample at each node.
randomForest = TreeBagger(300,X,'MPG','Method','regression',...
'OOBPrediction','on','MinLeafSize',params.minLS,...
'NumPredictorstoSample',params.numPTS);
oobErr = oobQuantileError(randomForest);
end
4 使用贝叶斯优化方法进行目标最小化
使用贝叶斯优化方法,通过调整树的复杂度以及每个节点的用于采样的预测数,找到能够实现袋外分位数误差最小(经过惩罚后)的模型。 将期望改进加函数指定为采集函数,并抑制打印优化信息(?没太理解)。
results = bayesopt(@(params)oobErrRF(params,X),hyperparametersRF,...
'AcquisitionFunctionName','expected-improvement-plus','Verbose',0);
关于bayesopt函数的介绍:贝叶斯优化-matlab
batesopt函数的调用格式 Results = bayesopt(fun, vars, Name, Value)
其中:
fun——目标函数。fun返回具有可调超参数来控制其训练的机器学习模型的损失度量,简单地说,其需要返回一个具体的值,不管其有没有数学形式。
vars——定义要调整的超参数的对象的变量描述。在matlab中使用optimizableVariable对象来构建变量向量。
‘AcquisitionFunctionName’ ——选择下一次估计点的函数
‘Verbose’——命令行显示级别。其值为0意味着无命令行显示;值为1意味着在每次迭代中,显示迭代次数,目标函数模型,目标函数评估时间,最佳观察的目标函数值等。值为2—与1相同,添加诊断信息。
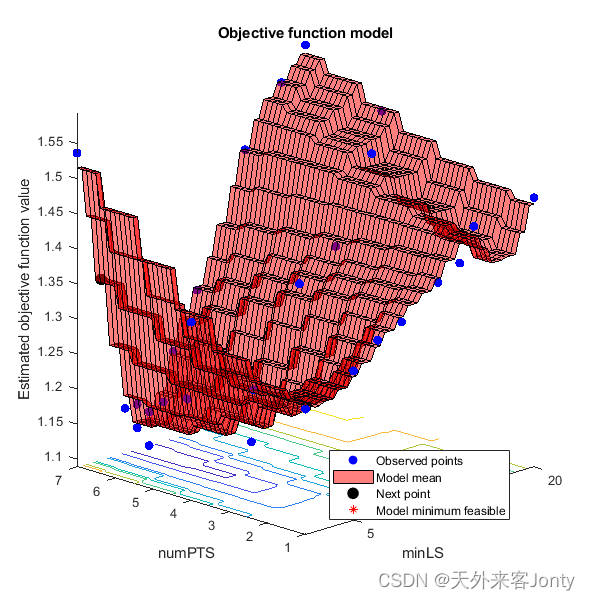
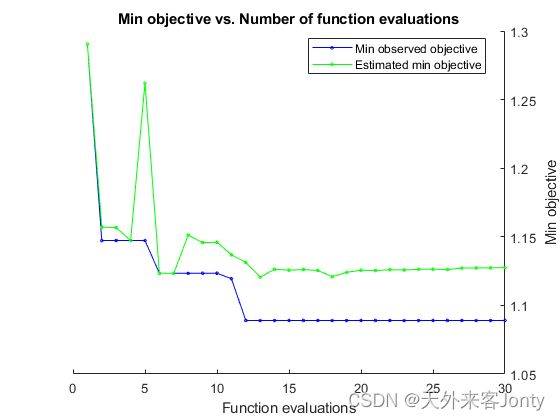
输出结果是贝叶斯优化对象,其中包含目标函数的最小值和优化后的超参数值,上两图展示的正是目标函数的最小值和优化后的超参数值。
bestOOBErr = results.MinObjective
bestHyperparameters = results.XAtMinObjective
输出结果:
bestOOBErr =
1.0890
bestHyperparameters =
1×2 table
minLS numPTS
_____ ______
7 7
5 利用优化后的超参数训练模型
使用全部数据集和优化后的超参数值训练随机森林模型
Mdl = TreeBagger(300,X,'MPG','Method','regression',...
'MinLeafSize',bestHyperparameters.minLS,...
'NumPredictorstoSample',bestHyperparameters.numPTS);
Mdl是经过优化的TreeBagger对象,为中值预测服务。 可以通过将Mdl和新数据传递给quantilePredict来预测给定预测器数据的燃油经济性中值。
