【深度学习】1.张量tensor(上)
【精神食粮使用指南:
1、如果你有一定深度学习的基础,可根据目录选择阅览
2、如果想要入门学习,建议手敲以下所有代码(大约1h)】
【每一篇文章都是按照零基础大约1h完成学习来编写】
目录
一、张量的数据类型
1、定义
2、数据类型的转化
3、张量的形状
4、小结实验
5、张量形变
6、特殊张量
7、数组、列表、张量之间的转换
二、张量的深拷贝与浅拷贝
三、张量的索引
1、类似于python原生的索引方式
2、使用函数来进行张量的索引 index_select
四、张量的分片与合并
1、tensor.view
2、分片
3、合并
一、张量的数据类型
1、定义
- 在数学中,一个数组的维度超过2我们便可以称之为张量。在深度学习中,或者说在PyTorch中,张量就不仅仅如此了。张量属于一种数据结构,它可以是一个标量、一个向量、一个矩阵,甚至是更高维度的数组。
- Pytorch中的张量(Tenser)和Numpy中的数组(ndarray)非常相似,在使用时也会经常将二者相互转化。
- 在深度学习中,基于Pytorch的相关计算和优化都是在Tenser的基础上完成的
在Pytorch中张量的数据类型如下:

import torch
import numpy as np
#张量创建法1——列表
t=torch.tensor([1,2])
print(t)
print(t.dtype)
#张量创建法2——数组
a=np.array((1,2))
print(a)
t1=torch.tensor(a)
print(t1)
print(t1.dtype) #张量默认创建长整形64位
l1=np.array([1.2,2.3])
print(l1.dtype)
l2=torch.tensor(np.array([1.2,2.3]))
print(l2.dtype) #数组默认创建双精度浮点型64位
l3=torch.tensor([1.2,2.3])
print(l3.dtype) #张量默认创建单精度浮点型32位
m1=torch.tensor([True,False])
print(m1.dtype)一定要手敲代码来理解啊!

可以通过torch.set_default_tensor_type()函数设置默认的浮点型的数据类型。也可以通过torch.tensor([],dtype=torch.float16)这样的形式来创建指定类型的张量。
2、数据类型的转化
- 张量中的元素属于不同数据类型时,系统会自动进行隐式转化。
t=torch.tensor([5,2,0,13.14])
print(t)
t1=torch.tensor([True,2.0,False])
print(t1)
整数和浮点数同时作为输入,输出转化为浮点数。
布尔型和浮点数同时作为输入,输出也会转化为浮点数。
![]()
这样操作可以统一所有元素的形式,便于在深度学习中做大规模大体量的数据计算和操作。
- 还可以根据我们自己的需求,用.int,.float做张量数据类型的转化。
t2=torch.tensor([5,4,3])
print (t2.dtype)
t2=t2.float()
print(t2)
print (t2.dtype)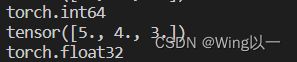
3、张量的形状
t1=torch.tensor([[1,2],[2,3],[3,4]])
print(t1.shape) #输出张量形状
print(t1.size()) #size是个函数,写作size()
print(t1.ndim) #输出张量维度
print(len(t1)) #有多少个N-1维元素
print(t1.numel()) #总共拥有多少个数

一个特殊的存在
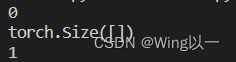
t=torch.tensor(9)
print(t.ndim)
print(t.shape)
print(t.numel())
这个张量是0维的,可以认为它是单独的一个数9。
在python中单独一个数字是标量(scalars),但是其无法在GPU上运行。故而衍生出“零维张量”来代表一个数在GPU上运行。
4、小结实验
用数组创建高位张量并输出其形状相关信息。
a1=np.array([[1,1,1],[2,2,2]])
a2=np.array([[3,3,3],[4,4,4]])
t1=torch.tensor([a1,a2])
print(t1)
print(t1.shape)
print(t1.size())
print(t1.ndim)
print(len(t1))
print(t1.numel()) 
5、张量形变
- 可以使用flatten和reshape方法对现有张量进行形变。
具体实验代码如下:
#flatten
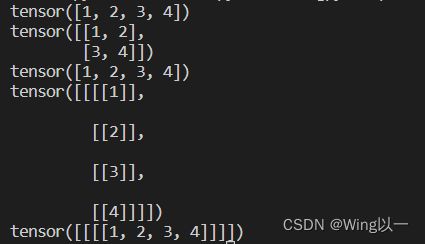
t1=torch.tensor([[1,2],[3,4]])
print(t1.flatten()) #将任意张量(包含零维张量)转化为一维张量
#reshape
t2=torch.tensor([1,2,3,4])
t3=t2.reshape(2,2) #将任意张量转化为固定行列的张量
print(t3) #t3为两行两列的张量(二维)
t2=t3.reshape(4) #转化为一维张量
print(t2)
t4=t2.reshape(1,4,1,1)
print(t4)
t5=t2.reshape(1,1,1,4)
print(t5)
- 升维和降维
squeeze:降维
t=torch.ones(1,1,4,1,3)
print(t)
print(t.shape) #这个五维张量里包含一个四维张量,四维张量里是一个三维张量,这个三维张量有四个二维张量,每个二维张量是一行三列
t1=torch.squeeze(t) #直接降维变成了一个一维张量
print(t1)
print(t1.shape)
unsqueeze:升维
t=torch.ones(1,2,3,4)
print(t.shape)
t2=torch.unsqueeze(t,dim=0) #第一个维度索引上升一个维度
#print(t2)
print(t2.shape)
t3=torch.unsqueeze(t,dim=3)
print(t3.shape)
6、特殊张量
- 0张量、1张量、对角线张量、单位张量
t1=torch.zeros([3,3])
print(t1)
t2=torch.ones([2,2])
print(t2)
t3=torch.eye(4)
print(t3)
t5=torch.tensor([1,2,3,4])
t6=torch.diag(t5)
print(t6)
- 服从不同统计概率的张量:0-1分布、正态分布、随机采样
t1=torch.rand(3,3) #0-1分布
t2=torch.randn(3,3) #标准正态分布
t3=torch.normal(3,4,size=(2,2)) #指定正态分布的张量,其均值为3,标准差为4
t4=torch.randint(1,100,[2,3]) #两行三列指定范围整数随机采样
print(t1)
print(t2)
print(t3)
print(t4) 
- 数列形式的张量
t1=torch.arange(9) #生成数列
print(t1)
t2=torch.arange(1,2,0.2) #[1,2)间隔0.2取值
print(t2)
t3=torch.linspace(1,2,4) #[1,2]之间等距离取4个值
print(t3)

- 指定取值张量、未初始化张量
t1=torch.empty(3,3) #内容为空未初始化的指定形状的张量
print(t1)
t2=torch.full([3,3],3) #指定形状指定取值的张量
print(t2)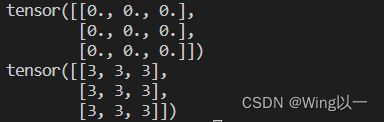
- 同形状填充的张量
t1=torch.tensor([1,2])
t2=torch.tensor([[1,2,3],[4,5,6]])
t3=torch.full_like(t1,9) #用9填充形状类似t1的张量
print(t3)
t4=torch.randint_like(t2,1,5) #用[1,5]填充形状类似于t2的张量
print(t4)
t5=torch.zeros_like(t2) #用零填充形状类似于t2的张量
print(t5)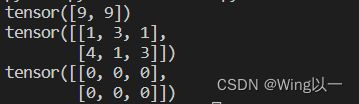
注意-like函数生成前后数据类型一致的问题
7、数组、列表、张量之间的转换

t1=torch.tensor([1,2,3,4,5])
print(t1)
t2=t1.numpy()
print(t2)
t3=np.array(t1)
print(t3)
t4=t1.tolist()
print(t4)
'''
为什么list不行呢?
'''
t5=list(t1) #t1这个一维张量,是由五个零维张量构成的
print(t5)
二、张量的深拷贝与浅拷贝
- 浅拷贝只复制指向某个对象的指针,而不复制对象本身,新旧对象还是共享同一块内存(分支)。
- 深拷贝会另外创造一个一模一样的对象,新对象跟原对象不共享内存,修改新对象不会改到原对象,是“值”而不是“引用”(不是分支)
t1=torch.tensor([1,2,3,4,5]) t2=t1 print(t2) t1[1]=9 #浅拷贝中,我们对t1元素的修改,同时改变了t2 print('t2=',t2) print('t1=',t1)
t1=torch.tensor([1,2,3,4,5]) t3=t1.clone() print(t3) t1[1]=9 #深拷贝中,我们对t1元素的修改,不会改变t3 print('t3=',t3) print('t1=',t1)
三、张量的索引
1、类似于python原生的索引方式
区别:步数间隔必须大于0(python中-1表示从后往前索引)
一维张量索引、切片举例 【start:end:step】
#索引
t1=torch.arange(1,13)
print(t1)
print(t1[2]) #张量按位置索引后的结果仍然是张量(零维张量)
print(t1[2].item()) #如果需要具体的数值,用item函数进行转化
#切片:用冒号分隔,取张量中的一段内容
print(t1[1:9])
print(t1[1:9:3]) #一段里间隔为3取
print(t1[1: :3]) #从1号位置开始索引到结束,间隔为3取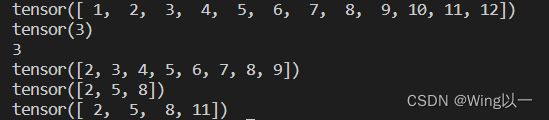
二维张量索引
t2=torch.arange(0,16).reshape(4,4)
print(t2)
print(t2[1,1]) #索引第二行、第二列的张量
print(t2[0,1::2]) #索引第一行张量,从第二个开始间隔两个取
print(t2[0,[1,3]]) #索引第一行张量,取序号为1和3的元素
print(t2[::2,::2]) #每隔两行取一行,在每一行中每隔两个取一个
print(t2[[2,3],0]) #索引第三行、第四行的首个张量 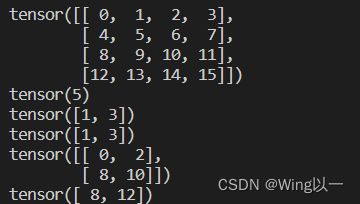
三维张量索引
t3=torch.arange(0,27).reshape(3,3,3)
print(t3) #三维张量可以理解为增加矩阵的个数
print(t3[2,2,2]) #第三个矩阵、第三行的第三个矩阵
print(t3[0,1::2,::2]) #三维张量中的每一个维度都遵循一维张量的格式[start:end:step]
print(t3[::2,::2,::2])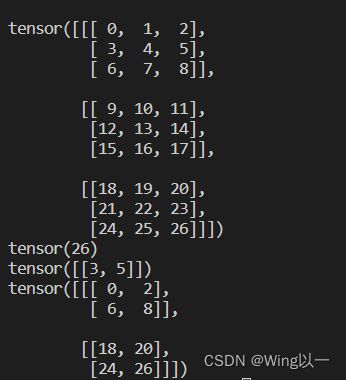
2、使用函数来进行张量的索引 index_select
#一维
t1=torch.arange(1,13)
indices=torch.tensor([1,2])
t11=torch.index_select(t1,0,indices) #对张量t1,索引标号为indices的零维张量(即第二个和第三个)
print(t1)
print(t11)
#二维
t2=torch.arange(16).reshape(4,4)
print(t2)
t22=torch.index_select(t2,0,indices) #这个0表示在第一个维度(即行)的方向上进行索引,索引标号为indices的一维张量(即第二个和第三个)
print(t22)
t23=torch.index_select(t2,1,indices) #这个1表示在第二个维度(即列)的方向上进行索引,索引标号为indices的一维张量(即第二个和第三个)
print(t23)
四、张量的分片与合并
1、tensor.view
对于张量产生一个类似视图的结果
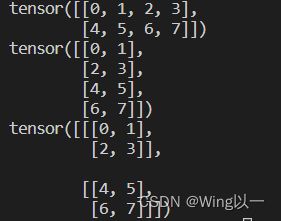
t=torch.arange(8).reshape(2,4)
print(t)
t1=t.view(4,2) #改变行列形状
print(t1)
t2=t.view(2,2,2) #改变维度
print(t2)t1是对t的一个浅拷贝的过程,我们对t的修改,同时也会改变t1
2、分片
- 分块:chunk
按照需要的维度对张量进行均匀切分,返回的是原来张量的视图
t=torch.arange(8).reshape(2,4)
print(t)
tchunk=torch.chunk(t,4,dim=1) #在第二个维度(列)上对t进行四等分
print(tchunk) #切分结果仍为二维张量
print(tchunk[2]) #索引得到一个二维张量
print(tchunk[2][0]) #索引得到一个一维张量
tchunk[2][0][0]=9 #索引得到一个零维张量,改变其数值
print(t) #浅拷贝,同时改变了t
- 拆分:split
可以自定义切分,返回结果依旧是视图
t=torch.arange(8).reshape(4,2)
print(t)
tsplit_average=torch.split(t,2,0) #等分为两份
print(tsplit_average)
tsplit_13=torch.split(t,[1,3],0) #总共有四行,切分为两份,一份一行,另一份三行
print(tsplit_13)
tsplit_1111=torch.split(t,[1,1,1,1],0)
print(tsplit_1111)
3、合并
- 拼接:cat
t1=torch.zeros(1,3)
t2=torch.ones(2,3)
t3=torch.eye(3)
t=torch.cat([t1,t2,t3]) #默认dim=0按行拼接torch.cat([,],dim=0)
print(t)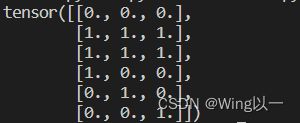
无法进行形状不匹配的拼接,会报错
- 堆叠:stack
将各个对象分装在更高维度的张量里。堆叠要求堆叠的对象形状必须完全相同。
t1=torch.zeros(1,3)
t4=torch.zeros(2,3)
t=torch.stack([t4,t2]) #堆叠成一个三维张量
print(t)
