【SIFT】LoG 与 DoG
目录
- 1、拉普拉斯变换
- 2、拉普拉斯算子(Laplacian 算子)
- 3、LoG:Laplacian of Gaussian
- 4、用 DoG 近似 LoG
1、拉普拉斯变换
拉普拉斯变换的定义为: L a p l a c i a n = ∂ 2 f ∂ x 2 + ∂ 2 f ∂ y 2 Laplacian = \frac{\partial^2 f}{\partial x^2} + \frac{\partial^2 f}{\partial y^2} Laplacian=∂x2∂2f+∂y2∂2f
就是对原图像的 x方向 和 y方向,分别做 2阶偏导数,然后相加。
以上的拉普拉斯变换公式,应用在连续的函数中,我们应该都会求解,但是在图像这个离散的二维环境中,怎么做拉普拉斯变化呢,具体怎么计算呢?我们往下看:
我们知道连续的一阶导函数公式如下:
f ′ ( x 0 ) = l i m Δ x → 0 f ( x 0 + Δ x ) − f ( x 0 ) Δ x f'(x_0) = lim_{\Delta x \rightarrow 0} \frac{f(x_0+\Delta x) - f(x_0)}{\Delta x} f′(x0)=limΔx→0Δxf(x0+Δx)−f(x0)
那么,离散的一阶导函数公式为:
f ′ ( x 0 ) = l i m Δ x → 1 f ( x 0 + Δ x ) − f ( x 0 ) Δ x = f ( x 0 + 1 ) − f ( x 0 ) f'(x_0) = lim_{\Delta x \rightarrow 1}\frac{f(x_0+\Delta x) - f(x_0)}{\Delta x} = f(x_0+1)-f(x_0) f′(x0)=limΔx→1Δxf(x0+Δx)−f(x0)=f(x0+1)−f(x0)
所以,图像在 x , y x, y x,y 两个方向上的一阶偏导数分别为:
∂ f ∂ x = f ( x + 1 , y ) − f ( x , y ) ∂ f ∂ y = f ( x , y + 1 ) − f ( x , y ) \frac{\partial f}{\partial x} = f(x+1 ,y) - f(x, y) \\ \ \\ \frac{\partial f}{\partial y} = f(x, y+1) - f(x, y) ∂x∂f=f(x+1,y)−f(x,y) ∂y∂f=f(x,y+1)−f(x,y)
然后,在一阶偏导函数的基础上,求二阶偏导函数。因为在求一阶偏导函数的时候,我们是通过 x+1 的形式来近似求 x点 的偏导的,直观上来讲,有点偏右了,所以在求二阶导函数的时候,我们让 x = x − 1 x=x-1 x=x−1 来近似 x x x 点,更为恰当,所以,在 x , y x, y x,y 方向上的二阶偏导数分别为:
∂ 2 f ∂ x 2 = ∂ [ f ( x + 1 , y ) − f ( x , y ) ] ∂ x = ∂ f ( x + 1 , y ) ∂ x − f ( x , y ) ∂ x = [ f ( x + 1 , y ) − f ( x , y ) ] − [ f ( x , y ) − f ( x − 1 , y ) ] = f ( x − 1 , y ) + f ( x + 1 , y ) − 2 f ( x , y ) ∂ 2 f ∂ y 2 = ∂ [ f ( x , y + 1 ) − f ( x , y ) ] ∂ y = ∂ f ( x , y + 1 ) ∂ y − f ( x , y ) ∂ y = [ f ( x , y + 1 ) − f ( x , y ) ] − [ f ( x , y ) − f ( x , y − 1 ) ] = f ( x , y − 1 ) + f ( x , y + 1 ) − 2 f ( x , y ) \begin{aligned} \frac{\partial^2 f}{\partial x^2} &= \frac{\partial [f(x+1, y) - f(x, y)] }{\partial x} \\ \ \\ &= \frac{\partial f(x+1, y)}{\partial x} - \frac{f(x, y)}{\partial x} \\ \ \\ &= [f(x+1,y) - f(x, y)] - [f(x, y) - f(x-1, y)] \\ \ \\ &=f(x-1, y) + f(x+1, y) - 2 f(x, y)\\ \ \\ \frac{\partial^2 f}{\partial y^2} &= \frac{\partial [f(x, y+1) - f(x, y)] }{\partial y} \\ \ \\ &= \frac{\partial f(x, y+1)}{\partial y} - \frac{f(x, y)}{\partial y} \\ \ \\ &= [f(x, y+1) - f(x,y)] - [f(x,y) - f(x,y-1)] \\\ \\ &=f(x,y-1) + f(x,y+1) - 2 f(x,y) \end{aligned} ∂x2∂2f ∂y2∂2f =∂x∂[f(x+1,y)−f(x,y)]=∂x∂f(x+1,y)−∂xf(x,y)=[f(x+1,y)−f(x,y)]−[f(x,y)−f(x−1,y)]=f(x−1,y)+f(x+1,y)−2f(x,y)=∂y∂[f(x,y+1)−f(x,y)]=∂y∂f(x,y+1)−∂yf(x,y)=[f(x,y+1)−f(x,y)]−[f(x,y)−f(x,y−1)]=f(x,y−1)+f(x,y+1)−2f(x,y)
再由拉普拉斯算子的定义,把上面的两个式子求和,就得到了:
L a p l a c i a n = f ( x − 1 , y ) + f ( x + 1 , y ) + f ( x , y − 1 ) + f ( x , y + 1 ) − 4 f ( x , y ) Laplacian = f(x-1, y) + f(x+1, y) + f(x,y-1) + f(x,y+1) - 4 f(x, y) Laplacian=f(x−1,y)+f(x+1,y)+f(x,y−1)+f(x,y+1)−4f(x,y)
上面的式子,用在图像里,可以看作是 上、下、左、右点的求和,减去中心点的4倍。所以,对图像做拉普拉斯变换,可以看作是 用原图像 与下面的模板做卷积运算,下面的这个模版(mask / filter)也就是拉普拉斯算子了。

2、拉普拉斯算子(Laplacian 算子)
Laplacian 算子 (拉普拉斯算子)是一种二阶导数算子,其具有旋转不变性,可以满足不同方向的边缘锐化。

计算像素点P5的近似二阶导数值入下: P 5 l a p = ( P 2 + P 4 + P 6 + P 8 ) − 4 ⋅ P 5 P5_{lap} = (P2 + P4 + P6 + P8) - 4 \cdot P5 P5lap=(P2+P4+P6+P8)−4⋅P5
上面介绍的默认的拉普拉斯算子 只考虑了上下左右的情况,并没有考虑斜对角线方向的情况,如果连斜对角线的情况也考虑进来的话,我们就有了 拓展版的拉普拉斯算子:
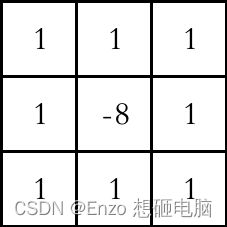
默认的拉普拉斯算子只在 90度方向上存在旋转不变性,而拓展模版则在45度方向上也具有旋转不变性。
3、LoG:Laplacian of Gaussian
上面我们知道了 Laplacian 变换是一个二阶导数变换,而二阶导数对噪声又特别敏感,所以在做Laplacian 变换操作之前,会先对原图像做一次 Gaussian 模糊。根据 卷积操作的结合性质,可以先对 Gaussian 模版做 Laplacian 变换操作,然后再将结果与原图像做卷积。
Laplacian of a Gaussian (LoG) is just another linear filter which is a combination of Gaussian followed by the Laplacian filter on an image. Since the 2 n d 2^{nd} 2nd derivative is very sensitive to noice. It is always a good idea to remove noice by smoothing the image before applying the Laplacian to ensure that noise is not aggravated.Because of the associative property of convolution it can be thought of as taking the 2 n d 2^{nd} 2nd derivative(Laplacian) of the Gaussian filter and then applying the resulting(combined) filter onto the image hence the name LoG.
对图像先做 Gaussian模糊,再做 Laplacian 变换 ,就等于对图像做LoG运算:
∇ 2 ( G ( x , y , σ ) ∗ I ( x , y ) ) = ∇ 2 G ( x , y , σ ) ∗ I ( x , y ) \nabla ^2 ( G_{(x, y, \sigma)} * I_{(x, y)}) = \nabla ^2 G_{(x, y, \sigma)} * I_{(x, y)} ∇2(G(x,y,σ)∗I(x,y))=∇2G(x,y,σ)∗I(x,y)
- I ( x , y ) I_{(x, y)} I(x,y) 是原图像
- G ( x , y , σ ) G_{(x, y, \sigma)} G(x,y,σ) 是高斯核
- 符号 ∗ * ∗ 表示卷积运算
- ∇ 2 \nabla^2 ∇2表示Laplacian运算
所以,LoG 的定义就是:对高斯核(Gaussian kernel) 做 Laplacian 运算
L o G = ∇ 2 G ( x , y , σ ) LoG= \nabla ^2 G_{(x, y, \sigma)} LoG=∇2G(x,y,σ)
4、用 DoG 近似 LoG
DoG:Difference of Gaussian
LoG:Laplacian of Gaussian
用两个不同尺度的 Gaussian 的差值(DoG)可以近似 LoG 的值,这样有效的减小运算量。
LoG can be efficiently approximated by using a difference of two Gaussians(DoG) at different scales.
下面我们来推导 LoG 与 DoG 的近似关系 (怕公式乱七八糟的,下面我按照几个部分模块写)
首先,我们先写出二维高斯核函数(1),以及其对 x 和 y 的二阶偏导数 (2)和(3)
G σ ( x , y ) = 1 2 π σ 2 e − x 2 + y 2 2 σ 2 (1) G_{\sigma}(x, y) = \frac{1}{2 \pi \sigma^2} e^{-\frac{x^2+y^2}{2 \sigma^2}}\tag{1} Gσ(x,y)=2πσ21e−2σ2x2+y2(1)
∂ 2 G σ ( x , y ) ∂ x 2 = 1 2 π σ 4 e − x 2 + y 2 2 σ 2 ( x 2 σ 2 − 1 ) (2) \frac{\partial^2 G_{\sigma}(x, y)}{\partial x^2} = \frac{1}{2 \pi \sigma^4}e^{-\frac{x^2+y^2}{2 \sigma^2}}( \frac{x^2}{\sigma^2}-1)\tag{2} ∂x2∂2Gσ(x,y)=2πσ41e−2σ2x2+y2(σ2x2−1)(2)
∂ 2 G σ ( x , y ) ∂ y 2 = 1 2 π σ 4 e − x 2 + y 2 2 σ 2 ( y 2 σ 2 − 1 ) (3) \frac{\partial^2 G_{\sigma}(x, y)}{\partial y^2} = \frac{1}{2 \pi \sigma^4}e^{-\frac{x^2+y^2}{2 \sigma^2}}( \frac{y^2}{\sigma^2}-1)\tag{3} ∂y2∂2Gσ(x,y)=2πσ41e−2σ2x2+y2(σ2y2−1)(3)
将(2)和(3)带入如下计算,得到 LoG 的公式(4):
L o G ( x , y ) = ∇ 2 G σ ( x , y ) = ∂ 2 G σ ( x , y ) ∂ x 2 + ∂ 2 G σ ( x , y ) ∂ y 2 = 1 2 π σ 4 e − x 2 + y 2 2 σ 2 ( x 2 σ 2 − 1 ) + 1 2 π σ 4 e − x 2 + y 2 2 σ 2 ( y 2 σ 2 − 1 ) = 1 2 π σ 4 e − x 2 + y 2 2 σ 2 [ ( x 2 σ 2 − 1 ) + ( y 2 σ 2 − 1 ) ] = 1 2 π σ 4 e − x 2 + y 2 2 σ 2 ( x 2 + y 2 σ 2 − 2 ) = x 2 + y 2 − 2 σ 2 2 π σ 6 e − x 2 + y 2 2 σ 2 (4) \begin{aligned}LoG(x, y) &= \nabla^2G_{\sigma}(x, y) \\ \ \\ &= \frac{\partial^2 G_{\sigma}(x, y)}{\partial x^2}+\frac{\partial^2 G_{\sigma}(x, y)}{\partial y^2} \\ \ \\ &= \frac{1}{2 \pi \sigma^4}e^{-\frac{x^2+y^2}{2 \sigma^2}}(\frac{x^2}{\sigma^2}-1) + \frac{1}{2 \pi \sigma^4}e^{-\frac{x^2+y^2}{2\sigma^2}}(\ \frac{y^2}{\sigma^2}-1) \\ \ \\ &=\frac{1}{2\pi \sigma^4}e^{-\frac{x^2+y^2}{2 \sigma^2}}[(\frac{x^2}{\sigma^2}-1) + (\ \frac{y^2}{\sigma^2}-1)] \\ \ \\ &=\frac{1}{2 \pi \sigma^4}e^{-\frac{x^2+y^2}{2 \sigma^2}}(\frac{x^2+y^2}{\sigma^2}-2) \\ \ \\ &=\frac{x^2+y^2-2\sigma^2}{2 \pi \sigma^6}e^{-\frac{x^2+y^2}{2\sigma^2}} \tag{4}\end{aligned} LoG(x,y) =∇2Gσ(x,y)=∂x2∂2Gσ(x,y)+∂y2∂2Gσ(x,y)=2πσ41e−2σ2x2+y2(σ2x2−1)+2πσ41e−2σ2x2+y2( σ2y2−1)=2πσ41e−2σ2x2+y2[(σ2x2−1)+( σ2y2−1)]=2πσ41e−2σ2x2+y2(σ2x2+y2−2)=2πσ6x2+y2−2σ2e−2σ2x2+y2(4)
然后计算高斯核函数 G ( x , y , σ ) G_{(x, y, \sigma)} G(x,y,σ) 对 σ \sigma σ的一阶导数,这个大家自己算下吧,我这里不写详细的计算过程了, 直接给出结果
∂ G ∂ σ = x 2 + y 2 − 2 σ 2 2 π σ 5 e − x 2 + y 2 2 σ 2 (5) \frac{\partial G}{\partial \sigma}=\frac{x^2+y^2-2\sigma^2}{2 \pi \sigma^5}e^{-\frac{x^2+y^2}{2 \sigma^2}} \tag{5} ∂σ∂G=2πσ5x2+y2−2σ2e−2σ2x2+y2(5)查看公式 (4)和(5),可以得出:
∂ G ∂ σ = σ ∇ 2 G (6) \frac{\partial G}{\partial \sigma}=\sigma \nabla^2G \tag{6} ∂σ∂G=σ∇2G(6)
由导数定义, 并且令 k σ = σ + Δ σ k\sigma = \sigma + \Delta \sigma kσ=σ+Δσ:
∂ G ∂ σ = l i m Δ σ → 0 G ( x , y , σ + Δ σ ) − G ( x , y , σ ) Δ σ ≈ G ( x , y , k σ ) − G ( x , y , σ ) k σ − σ (7) \begin{aligned}\frac{\partial G}{\partial \sigma} &=lim_{\Delta \sigma\rightarrow0}\frac{G(x, y, \sigma+\Delta\sigma)-G(x, y, \sigma)}{\Delta\sigma} \\ \ \\ &\approx \frac{G(x, y, k\sigma)-G(x, y, \sigma)}{k \sigma - \sigma} \tag{7}\end{aligned} ∂σ∂G =limΔσ→0ΔσG(x,y,σ+Δσ)−G(x,y,σ)≈kσ−σG(x,y,kσ)−G(x,y,σ)(7)由(6)和(7),得:
σ ∇ 2 G = G ( x , y , k σ ) − G ( x , y , σ ) k σ − σ \sigma \nabla^2G =\frac{G(x, y, k\sigma)-G(x, y, \sigma)}{k \sigma - \sigma} σ∇2G=kσ−σG(x,y,kσ)−G(x,y,σ)
变形得:
σ 2 ( k − 1 ) ∇ 2 G = G ( x , y , k σ ) − G ( x , y , σ ) (8) \sigma^2(k-1) \nabla^2G =G(x, y, k\sigma)-G(x, y, \sigma) \tag{8} σ2(k−1)∇2G=G(x,y,kσ)−G(x,y,σ)(8)
又因为
D o G = G ( x , y , k σ ) − G ( x , y , σ ) L o G = ∇ 2 G DoG = G(x, y, k\sigma)-G(x, y, \sigma) \\ \ \\ LoG = \nabla^2G DoG=G(x,y,kσ)−G(x,y,σ) LoG=∇2G所以,(8)换个写法就是: σ 2 ( k − 1 ) L o G = D o G \sigma^2(k-1) LoG =DoG σ2(k−1)LoG=DoG
至此,得证 (累死我了)
以上是代数层面的计算证明,然后我们也从几何图形角度来看看。
import numpy as np
import matplotlib.pyplot as plt
# --------- LoG ---------
sigma = 1.2
imput = []
output_LoG = []
a = -1 / (np.pi * sigma**4)
for x in np.arange(-6, 7, 0.1):
b = (x**2) / (2 * sigma ** 2)
result = a * np.exp(-b) * (1-b)
imput.append(x)
output_LoG.append(result)
# --------- DoG ---------
sigma1 = sigma / np.sqrt(2)
sigma2 = sigma * np.sqrt(2)
output_DoG = []
output_gaussian1 = []
output_gaussian2 = []
a1 = 1 / (2 * np.pi * sigma1**2)
a2 = 1 / (2 * np.pi * sigma2**2)
for x in np.arange(-6, 7, 0.1):
gaussian1 = a1 * np.exp(- (x**2)/(2 * sigma1**2))
gaussian2 = a2 * np.exp(- (x**2)/(2 * sigma2**2))
output_gaussian1.append(gaussian1)
output_gaussian2.append(gaussian2)
output_DoG.append(gaussian2 - gaussian1)
plt.plot(imput, output_gaussian1, label='gaussian1')
plt.plot(imput, output_gaussian2, label='gaussian2')
# plt.plot(imput, output_LoG, label='LOG')
# plt.plot(imput, output_DoG, label='DOG')
plt.legend()
plt.show()
print(sigma2 / sigma1)

顺便提一嘴,我看到好多地方都在使用下面这张图,有一点没搞明白 (或许是作者没在意写错了??)
按照左边的公式 ∇ 2 G σ = G ( x , y , k σ ) − G ( x , y , σ ) \nabla^2G_{\sigma} = G(x, y, k\sigma)-G(x, y, \sigma) ∇2Gσ=G(x,y,kσ)−G(x,y,σ),得到右边的图的情况下
- G σ 1 G_{\sigma1} Gσ1 是绿色那条线
- G σ 2 G_{\sigma2} Gσ2 是红色的
这时候, σ 1 > σ 2 \sigma_1> \sigma_2 σ1>σ2
但是右边又说最相似的时候,是当 σ 1 = σ 2 , σ 2 = 2 σ \sigma_1 = \frac{\sigma}{\sqrt{2}}, \sigma_2=\sqrt{2} \sigma σ1=2σ,σ2=2σ 的时候,这时 σ 1 < σ 2 \sigma_1 < \sigma_2 σ1<σ2
所以,是写错了 ??