(IRCNN)CVPR-2017:Learning Deep CNN Denoiser Prior for Image Restoration
本文旨在训练一套快速有效的CNN(卷积神经网络)去噪器,并将其集成到基于模型的优化方法中。
code:GitHub - cszn/IRCNN: Learning Deep CNN Denoiser Prior for Image Restoration (CVPR, 2017) (Matlab)
贡献
(1)训练了一套快速有效的CNN去噪器。通过变量分割技术,强大的去噪器可以将强大的图像先验引入基于模型的优化方法中。
(2)学习的CNN去噪器集作为基于模型的优化方法的模块化部分插入,以处理其他逆问题。对经典IR问题的大量实验,包括去模糊和超分辨率,已经证明了集成灵活的基于模型的优化方法和基于CNN的快速判别学习方法的优点。
介绍
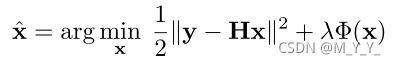 (2)
(2)
前一项为保真项,后一项为正则项(先验项)。保真项保证解决方案符合退化过程,而正则项加强输出的期望性质。
判别式学习方法试图通过优化损失函数来学习先验参数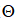 和一个紧凑的推理模型。
和一个紧凑的推理模型。
基于模型的优化方法与判别学习方法的一个区别是,前者通过指定退化矩阵H灵活地处理各种IR任务,而后者需要使用具有特定退化矩阵的训练数据来学习模型。
半二次分裂(HQS)方法
通常采用变量分裂技术来解耦保真项和正则化项,在半二次分裂法中,引入辅助变量z:
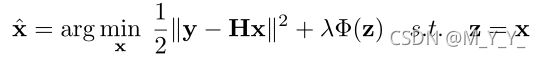
HQS方法:
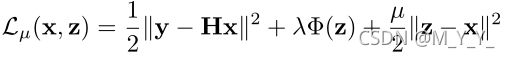
µ是惩罚参数,以非降序迭代变化,上式通过下列方法迭代:
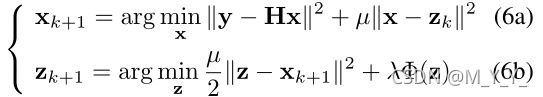
λ与σ^2相关,并在迭代过程中保持不变,µ控制去噪器的噪声级。
对于不同的退化矩阵有不同的快速解决方案。直接解由下式给出:
![]()
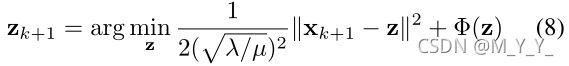
公式(8)对应于用噪声级![]() 的高斯去噪器对图像xk+1去噪。因此,任何高斯去噪器都可以作为模块部分来求解公式(2)。为了解决这个问题,重写了公式(8):
的高斯去噪器对图像xk+1去噪。因此,任何高斯去噪器都可以作为模块部分来求解公式(2)。为了解决这个问题,重写了公式(8):
![]()
图像先验Φ(·)可以用去噪先验隐式替换 。
学习深度CNN去噪先验
为什么选择CNN去噪器?
作为公式(2)的正则项,它对恢复性能起着至关重要的作用,因此去噪先验的选择在(9)中是非常重要的。
基于模型的优化方法在求解其他逆问题时已有的降噪先验包括:总变差(TV)、高斯混合模型(GMM)、K-SVD、非局部均值和BM3D。其缺点:TV会导致水彩效应;K-SVD先验去噪算法计算量大;如果图像不具有自相似性,非局部均值和BM3D去噪先验可能会使不规则结构过度平滑。
彩色图像预处理或去噪也是需要考虑的关键因素,而现有的方法主要集中于对灰度图像进行先验建模,而对彩色图像进行先验建模的工作很少。
通过手工设计的线性变换将RGB图像解关联到亮度-色度颜色空间中再操作,但变换后的亮度-色度颜色通道仍有一定的相关性,所以联合处理颜色通道比单独处理每个颜色通道产生更好的性能。因此,采用判别学习的方法来自动先验显示底层彩色图像是一个很好的选择。
选择深度CNN来学习鉴别去噪的原因:
(1)由于GPU的并行计算能力,CNN的推理非常高效
(2)CNN展示出强大的深度架构建模能力
(3)CNN利用了外部先验,这是许多现有的去噪器(如BM3D)的内部先验的补充
(4)CNN的训练和设计在过去取得了很大的进步,可以利用这些进步来促进判别学习
提出的CNN去噪器
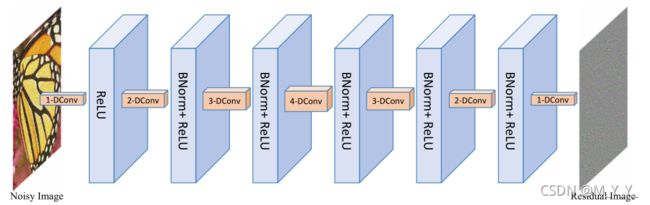
由三个不同的块共七个层组成。
第一个块:Dilated Convolution(扩张卷积)+ReLU。
第二个块:Dilated Convolution+Batch Normalization+ReLU。
第三个块:Dilated Convolution。
(1)利用扩张卷积来扩大感受野
扩大CNN的感受野有两种基本的方法,即增大过滤器的大小和增大深度。具有扩张因子s的扩张滤波器可以解释为大小为(2s+1)×(2s+1)的稀疏滤波器,其中只有9个固定位置可以是非零。
(2)使用批量归一化和残差学习加速训练
(3)使用小尺寸的训练样本帮助消除边界效应
由于卷积的特性,CNN去噪后的图像可能会引入边界伪影,使用对称填充和零填充可以解决这个问题。本文采用了零填充策略。使用较小的训练样本可以避免边界伪影。主要原因在于,与其使用大尺寸的训练patch,不如将它们裁剪成小块,这样CNN可以看到更多的边界信息。
(4)基于小区间噪声水平的特定去噪模型的学习
由于迭代优化框架需要不同噪声水平的降噪模型,因此需要考虑如何训练判别模型的问题。
不需要为每个噪声级学习许多有区别的去噪器模型,传统的高斯去噪的目的是恢复潜在的干净图像,然而,无论要去噪的图像的噪声类型和噪声水平如何,这里的去噪器都只起到自己的作用。因此,理想的判别式去噪器在公式(9) 应根据当前噪音水平进行训练。
损失函数
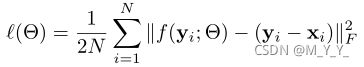
其中,(yi,xi)代表一个noise-clean patch对。
SISR
现有的超分辨率模型主要侧重于图像的先验建模,并针对特定的退化过程进行训练。当训练中采用的模糊核偏离真实核时,会使得学习模型严重恶化,但本文模型可以处理任何模糊内核,无需重新训练。
使用以下反投影迭代来求解等式(6a):
![]()
其中,↓sf表示降尺度因子为sf的退化算子,↑sf双三次函数表示具有放大因子sf的双三次插值算子,α为步长。
结论
(1)设计并训练了一套快速有效的CNN图像去噪器。借助于变量分裂技术,将学习到的去噪先验知识插入到HQS的基于模型的优化方法中,以解决图像去模糊和超分辨率问题。
(2)基于模型的优化方法和判别性CNN去噪器的集成为各种图像恢复任务提供了灵活、快速和有效的框架。
(3)学习表达CNN去噪先验是一个很好的替代模型图像先验。
进一步研究的空间:
(1)如何减少判别式CNN去噪器的数量和整个迭代的次数将是一个有趣的研究
(2)将提出的基于CNN去噪的HQS框架扩展到其他逆问题
(3)利用互补的多个先验来提高绩效是一个有前途的方向
(4)因为HQS框架可以被视为MAP推理,这项工作也为设计特定任务的区别学习的CNN架构提供了一些见解。