论文阅读笔记(RethinkDIP):Rethinking Deep Image Prior for Denoising
Rethinking Deep Image Prior for Denoising
论文地址:https://arxiv.org/abs/2108.12841
代码地址:GitHub - gistvision/DIP-denosing: Code and models for “Rethinking Deep Image Prior for Denoising” (ICCV 2021)
引用格式:
@inproceedings{jo2021rethinking,
title={Rethinking Deep Image Prior for Denoising},
author={Jo, Yeonsik and Chun, Se Young and Choi, Jonghyun},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={5087--5096},
year={2021}
}
目录
- Rethinking Deep Image Prior for Denoising
-
- Abstract
- Preliminaries
-
- **问题描述:**
- Effective degrees of freedom(DF):
- 过零点停止标准(Zero-crossing stopping criterion):
- 随机时间集成(Stochastic temporal ensembling):
- 关于DF的补充:
- 思考
Abstract
DIP局限性:
- 对噪声过拟合
- 没有迭代停止标准
改进点:
- DF(Degrees of freedom)监控优化过程
- 过零点停止标准(Zero-crossing stopping criterion)
- 随机时间集成STE(Stochastic temporal ensembling)
- 将任务扩充到possion噪声
- 增加评价标准:学习感知图像块相似度(Learned Perceptual Image Patch Similarity, LPIPS)
Preliminaries
问题描述:
沿用了DIP的思路, y y y为噪声图像, x x x为干净图像, n n n为噪声。
y = x + n y=x+n y=x+n
参数优化: θ ^ = a r g m i n θ L ( h ( n ˙ ; θ ) , y ) \hat{\theta}= \mathop{argmin}\limits_{\theta}\mathcal{L}(h(\dot{n};\theta),y) θ^=θargminL(h(n˙;θ),y)
【我的理解此处的 n ˙ \dot{n} n˙为DIP中的随机变量 z z z】
Effective degrees of freedom(DF):
模型对训练数据的拟合量。
输入: y y y , $ h(.)$
D F ( h ) = 1 σ 2 ∑ i = 1 n C o v ( h i ( . ) , y i ) DF(h) = \frac{1}{\sigma^2} \sum^{n}_{i=1}{Cov(h_i(.),y_i)} DF(h)=σ21∑i=1nCov(hi(.),yi)
其中, C o v Cov Cov为协方差, σ \sigma σ为噪声的标准差。
使用Stein’s lemma简化协方差计算:
1 σ 2 ∑ i = 1 n C o v ( h i ( . ) , y i ) = E [ ∑ i = 1 n ∂ h i ( y ) ∂ y i ] \frac{1}{\sigma^2} \sum^{n}_{i=1}{Cov(h_i(.),y_i)}=\mathbb{E}[\sum^{n}_{i=1}\frac{\partial h_i(y)}{\partial y_i}] σ21∑i=1nCov(hi(.),yi)=E[∑i=1n∂yi∂hi(y)]
引入Stein’s unbiased risk estimator (SURE)对loss函数进行无偏估计,抑制DF:
η ( h ( y ) , y ) = L ( y , h ( y ) ) + 2 σ 2 N ∑ i = 1 n ∂ h i ( y ) ∂ y i − σ 2 \eta(h(y),y)=L(y,h(y))+\frac{2\sigma^2}{N}\sum^{n}_{i=1}\frac{\partial h_i(y)}{\partial y_i} - \sigma^2 η(h(y),y)=L(y,h(y))+N2σ2∑i=1n∂yi∂hi(y)−σ2
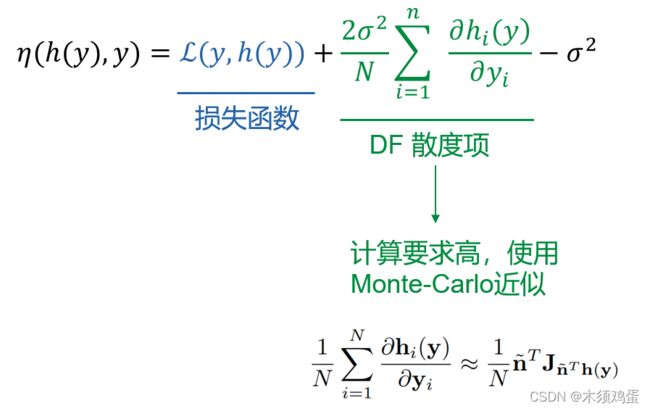
分成损失函数与散度项的组合,由于散度项的计算要求依然很高所以使用Monte-Carlo近似。
过零点停止标准(Zero-crossing stopping criterion):
现象:散度项在收敛前上升,在收敛后发散到 − ∞ -\infty −∞。
措施:目标函数偏离零时停止迭代。
随机时间集成(Stochastic temporal ensembling):
- 噪声正则化:在迭代中为输入添加噪声。
- θ ^ = a r g m i n θ L ( h ( n ˙ + γ ) , y ) \hat{\theta}=\mathop{argmin}\limits_{\theta} \mathcal{L}(h(\dot{n}+\gamma),y) θ^=θargminL(h(n˙+γ),y)
- γ \gamma γ为噪声向量, γ ∼ N ( 0 , σ γ 2 I ) \gamma \sim N(0,\sigma^2_\gamma I) γ∼N(0,σγ2I)
- 指数移动平均:对上次迭代获得的恢复图像进行平均。集成操作
将以上两种方法融合得到STE:
η ( h ( y 2 ) , y 1 ) = L ( h ( y 2 ) , y 1 ) + 2 σ 2 N ∑ i = 1 n ∂ h i ( y 2 ) ∂ ( y 2 ) i − σ 2 \eta(h(y_2),y_1)=\mathcal{L}(h(y_2),y1)+\frac{2\sigma^2}{N}\sum^{n}_{i=1}\frac{\partial h_i(y_2)}{\partial (y_2)_i} - \sigma^2 η(h(y2),y1)=L(h(y2),y1)+N2σ2∑i=1n∂(y2)i∂hi(y2)−σ2
其中, y 1 = y , y 2 = y 1 + γ y_1=y,y_2=y_1+γ y1=y,y2=y1+γ, σ σ σ为 y 1 y_1 y1 的已知噪声水平。 L ( h ( y 2 ) , y 1 ) \mathcal{L}(h(y_2),y1) L(h(y2),y1)为数据项, 2 σ 2 N ∑ i = 1 n ∂ h i ( y 2 ) ∂ ( y 2 ) i \frac{2\sigma^2}{N}\sum^{n}_{i=1}\frac{\partial h_i(y_2)}{\partial (y_2)_i} N2σ2∑i=1n∂(y2)i∂hi(y2)为正则项。
关于DF的补充:
DF与模型 h h h的估计类似(测试误差与训练误差之间的差异):
ρ ( h ) = E [ L ( y ~ , h ( . ) ) − L ( y , h ( . ) ) ] \rho(h)=\mathbb{E}[\mathcal{L}(\tilde{y},h(.))-\mathcal{L}(y,h(.))] ρ(h)=E[L(y~,h(.))−L(y,h(.))]
其中, L \mathcal{L} L为MSE Loss, y ~ \tilde{y} y~和 y y y为不同 n n n的噪声图像。
在其他研究中表示 ρ ( h ) = 2 ∑ i = 1 n C o v ( h i ( . ) , y i ) \rho(h)=2\sum^{n}_{i=1}{Cov(h_i(.),y_i)} ρ(h)=2∑i=1nCov(hi(.),yi)
由于 D F ( h ) = 1 σ 2 ∑ i = 1 n C o v ( h i ( . ) , y i ) DF(h) = \frac{1}{\sigma^2} \sum^{n}_{i=1}{Cov(h_i(.),y_i)} DF(h)=σ21∑i=1nCov(hi(.),yi)
因此, 2 σ 2 ⋅ D F ( h ) = ρ ( h ) 2\sigma^2 · DF(h) = \rho(h) 2σ2⋅DF(h)=ρ(h)
引入DF的简单估计和单个ground truth得到 D F G T DF_{GT} DFGT:
2 σ 2 ⋅ D F G T ( h ) ≈ L ( x , h ( . ) ) − L ( y , h ( . ) ) + σ 2 2\sigma^2 · DF_{GT}(h) \approx \mathcal{L}(x,h(.))-\mathcal{L}(y,h(.))+\sigma^2 2σ2⋅DFGT(h)≈L(x,h(.))−L(y,h(.))+σ2
DF越大代表过度拟合了输入 y y y。若DIP的结果靠近干净图像 x x x,则 D F G T DF_{GT} DFGT接近于0;若DIP的结果越靠近噪声图像 y y y,DF结果越大。【使用这个性质可以分析DIP的优化过程】
思考
在论文中的Figure1中,选择作为展示的图片,BM3D的去噪效果在PSNR的比较上反而是最佳的,甚至超过了Self2Self。只是在新增加的评价标准LPIPS上本方法最佳。
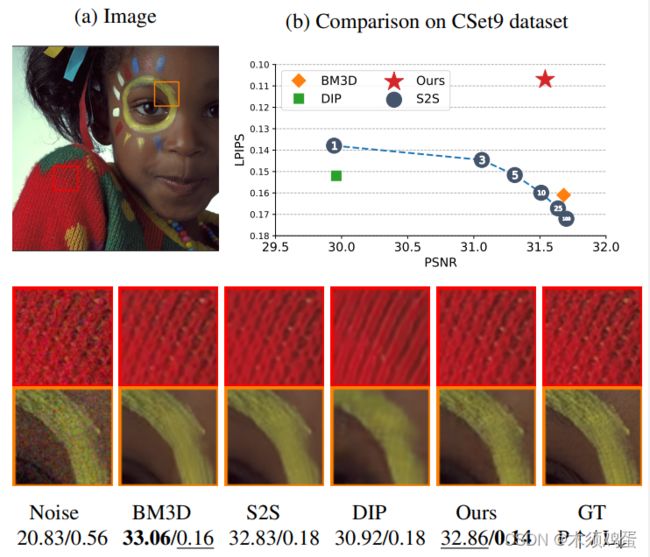
在实验结果对比中也有体现了类似的现象:

【对于这些新算法需要更多一点辩证的思维来看待,不能完全信任所描述的结果。】
DIP 类方法基于单幅图像,需要对不同 的图像重新训练模型,这样并不符合实际的应用场景。