基于MATLAB的车牌识别(GUI)
目录
车牌识别系统的介绍与展示
图像预处理
1.灰度处理
2.边缘检测
车牌定位
1.图像腐蚀
2.图像平滑
3.移除对象
4.图像切割
车牌识别
1.灰度处理
2.直方图均衡化
3.二值化
4.中值滤波
5.字符识别
车牌识别系统的介绍与展示
车牌识别技术的推广普及对加强道路管理、城市交通事故、违章停车、处理车辆被盗案件、保障社会稳定等方面有非常重大的影响。恰逢今年学习了数字图像处理这门课程,开发了一个车牌识别的小APP,可以进行车牌的正确识别。
一个完整的车牌号识别系统要完成从图像采集到字符识别输出,过程相当复杂,基本可以分成硬件部分和软件部分,硬件部分包括系统触发、图像采集,软件部分包括图像预处理、车牌定位、车牌识别三个部分。下面是一个车牌识别后的运行结果图:
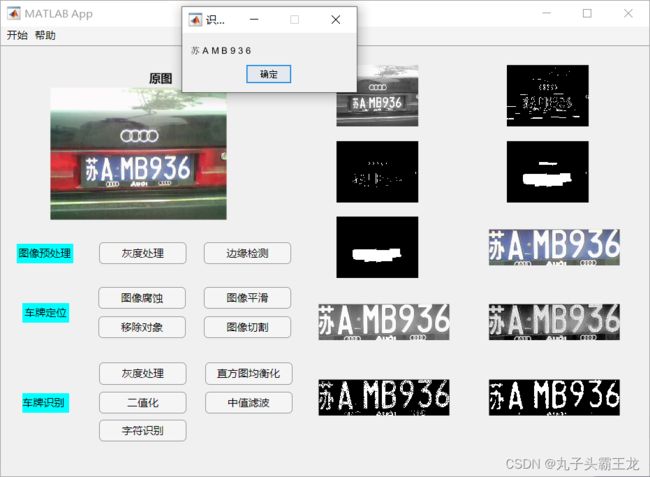
图像预处理
1.灰度处理
由于彩色图不易确定车牌边界,将彩色图转换为灰度图以进一步处理图片。这里使用了rgb2gray函数,该函数接收一个rgb图像变量作为参数,返回该图像转换为灰度图后的图像数据,并将该数据赋值给变量I1。
若想得到该灰度图的灰度分布情况,可使用imhist函数画出该灰度图的灰度值分布直方图。
%% 灰度处理
img1 = rgb2gray(img); % RGB图像转灰度图像
figure;
subplot(1, 2, 1);
imshow(img1);
title('灰度图像');
subplot(1, 2, 2);
imhist(img1);
title('灰度处理后的灰度直方图');2.边缘检测
在将彩色图转换为灰度图后,便可用edge函数识别该图像的边界,edge函数通过使用一阶导数和二阶导数检测亮度的不连续来确定图像的边界,它可以使用Sobel,Prewitt,Roberts,Canny,LoG,零交叉等多种算子,这里使用Roberts算子进行边缘检测。
%% 边缘检测
img4 = edge(img1, 'roberts', 0.15, 'both');
figure('name','边缘检测');
imshow(img4);
title('roberts算子边缘检测');车牌定位
1.图像腐蚀
由于边缘检测后的图像中无关结构太多,这里需对图像进行腐蚀处理,实现腐蚀处理的函数为imerode,它接收一个图像数据和一个结构子,图像中背景与结构子完全重合的像素点输出值为1,不完全重合的和完全不重合的像素点输出值为0,最后返回使用该结构子腐蚀过后的图像数据,以此实现削减无关结构的目的。
%% 图像腐蚀
se=[1;1;1];
img5 = imerode(img4, se);
figure('name','图像腐蚀');
imshow(img5);
title('图像腐蚀后的图像');
2.图像平滑
腐蚀后的图像结构大多呈分散状分布,不连贯。为了方便之后确认车牌位置,这里需对该图像进行平滑处理,在此我们使用闭操作使车牌平滑,并减小噪音,闭操作可以理解为先膨胀后腐蚀,实现函数为imclose。
%% 平滑图像
se = strel('rectangle', [30, 30]);
img6 = imclose(img5, se);
figure('name','平滑处理');
imshow(img6);
title('平滑图像的轮廓');3.移除对象
%% 从图像中删除所有少于2200像素8邻接
img7 = bwareaopen(img6, 2200);
figure('name', '移除小对象');
imshow(img7);
title('从图像中移除小对象');4.图像切割
在经过上面的处理之后,最初要识别的彩色图像已经变成了以车牌为主要结构的二值图像,我们可以对这种主体结构清晰的二值图像进行扫描,进而确定出车牌的位置。
这里确定车牌位置的思路为:
首先使用size函数得到该图像矩阵的行数y和列数x,用zero函数建立一个y行1列的零矩阵blue_Y,然后使用嵌套循环结构遍历该二值图像的每一个像素点,把每行值为1的像素点(也就是蓝色像素点)的数量分别记录在先前创建的矩阵blue_y中。遍历完之后,找出blue_y矩阵中值最大的元素,它所对应的行即为该二值图像中蓝色像素点最多的行,该行可认为是靠近车牌中心的一行。
然后我们以这一行为起点,分别向上向下逐行扫描,当被扫描到的蓝中白色像素点多于某个值时(该值只是一个用于判断的估计值),继续向上(或向下)扫描,直到扫描到某行中的蓝色像素点数量小于估计值时,停止扫描,并记录这一行的行数,该行数即为车牌的上边界(或下边界)。
同理,我们可以用相同的方法确定出车牌的左边界和右边界。
然后将原图按照上述方法确定的坐标进行裁剪,即可得到仅有车牌的图像。
%% 图像切割
[y, x, z] = size(img7);
img8 = double(img7); % 转成双精度浮点型
% 车牌的蓝色区域
% Y方向
blue_Y = zeros(y, 1);
for i = 1:y
for j = 1:x
if(img8(i, j) == 1) % 判断车牌位置区域
blue_Y(i, 1) = blue_Y(i, 1) + 1; % 像素点统计
end
end
end
% 找到Y坐标的最小值
img_Y1 = 1;
while (blue_Y(img_Y1) < 5) && (img_Y1 < y)
img_Y1 = img_Y1 + 1;
end
% 找到Y坐标的最大值
img_Y2 = y;
while (blue_Y(img_Y2) < 5) && (img_Y2 > img_Y1)
img_Y2 = img_Y2 - 1;
end
% x方向
blue_X = zeros(1, x);
for j = 1:x
for i = 1:y
if(img8(i, j) == 1) % 判断车牌位置区域
blue_X(1, j) = blue_X(1, j) + 1;
end
end
end
% 找到x坐标的最小值
img_X1 = 1;
while (blue_X(1, img_X1) < 5) && (img_X1 < x)
img_X1 = img_X1 + 1;
end
% 找到x坐标的最小值
img_X2 = x;
while (blue_X(1, img_X2) < 5) && (img_X2 > img_X1)
img_X2 = img_X2 - 1;
end
% 对图像进行裁剪
img9 = img(img_Y1:img_Y2, img_X1:img_X2, :);
figure('name', '定位剪切图像');
imshow(img9);
title('定位剪切后的彩色车牌图像')
% 保存提取出来的车牌图像
% imwrite(img9, '车牌图像.jpg');车牌识别
1.灰度处理
% 转换成灰度图像
plate_img1 = rgb2gray(img9); % RGB图像转灰度图像
figure;
subplot(1, 2, 1);
imshow(plate_img1);
title('灰度图像');
subplot(1, 2, 2);
imhist(plate_img1);
title('灰度处理后的灰度直方图');2.直方图均衡化
为了使识别更加准确,我们将上一步得到的直方图使用histeq函数进行均衡化,增强图像的对比度。
% 直方图均衡化
plate_img2 = histeq(plate_img1);
figure('name', '直方图均衡化');
subplot(1,2,1);
imshow(plate_img2);
title('直方图均衡化的图像');
subplot(1,2,2);
imhist(plate_img2);
title('直方图');3.二值化
为了便于将其中的字符分离,我们将它转换为二值图像
% 二值化处理
plate_img3 = im2bw(plate_img2, 0.76);
figure('name', '二值化处理');
imshow(plate_img3);
title('车牌二值图像');4.中值滤波
在车牌转换为二值图像后,为了使图像中干扰元素减少,我们对其进行中值滤波,以减小图中噪音。
% 中值滤波
plate_img4 = medfilt2(plate_img3);
figure('name', '中值滤波');
imshow(plate_img4);
title('中值滤波后的图像');
5.字符识别
目前用于车牌字符识别(OCR)的算法主要有基于模板匹配的OCR算法以及基于人工神经网络的OCR算法。基于模板匹配的OCR的基本过程是:首先对待识别字符进行二值化并将其尺寸大小缩放为字符数据库中模板的大小,然后与所有的模板进行匹配,最后选最佳匹配作为结果。用人工神经网络进行字符识别主要有两种方法:一种方法是先对待识别字符进行特征提取,然后用所获得的特征来训练神经网络分类器。识别效果与字符特征的提取有关,而字符特征提取往往比较耗时。因此,字符特征的提取就成为研究的关键。另一种方法则充分利用神经网络的特点,直接把待处理图像输入网络,由网络自动实现特征提取直至识别。
模板匹配的主要特点是实现简单,当字符较规整时对字符图像的缺损、污迹干扰适应力强且识别率相当高。综合模板匹配的这些优点我们将其用为车牌字符识别的主要方法。
模板匹配是图象识别方法中最具代表性的基本方法之一,它是将从待识别的图象或图象区域f(i,j)中提取的若干特征量与模板T(i,j)相应的特征量逐个进行比较,计算它们之间规格化的互相关量,其中互相关量最大的一个就表示期间相似程度最高,可将图象归于相应的类。也可以计算图象与模板特征量之间的距离,用最小距离法判定所属类。然而,通常情况下用于匹配的图象各自的成像条件存在差异,产生较大的噪声干扰,或图象经预处理和规格化处理后,使得图象的灰度或像素点的位置发生改变。在实际设计模板的时候,是根据各区域形状固有的特点,突出各类似区域之间的差别,并将容易由处理过程引起的噪声和位移等因素都考虑进去,按照一些基于图象不变特性所设计的特征量来构建模板,就可以避免上述问题。
此处采用相减的方法来求得字符与模板中哪一个字符最相似,然后找到相似度最大的输出。汽车牌照的字符一般有七个,大部分车牌第一位是汉字,通常代表车辆所属省份,或是军种、警别等有特定含义的字符简称;紧接其后的为字母与数字。车牌字符识别与一般文字识别在于它的字符数有限,汉字共约50多个,大写英文字母26个,数字10个。所以建立字符模板库也极为方便。为了实验方便,结合本次设计所选汽车牌照的特点,只建立了7个汉字26个字母与10个数字的模板。其他模板设计的方法与此相同。
首先取字符模板,接着依次取待识别字符与模板进行匹配,将其与模板字符相减,得到的0越多那么就越匹配。把每一幅相减后的图的0值个数保存,然后找数值最大的,即为识别出来的结果。
%% 字符识别
plate_img5 = my_imsplit(plate_img4);
[m, n] = size(plate_img5);
s = sum(plate_img5); %sum(x)就是竖向相加,求每列的和,结果是行向量;
j = 1;
k1 = 1;
k2 = 1;
while j ~= n
while s(j) == 0
j = j + 1;
end
k1 = j;
while s(j) ~= 0 && j <= n-1
j = j + 1;
end
k2 = j + 1;
if k2 - k1 > round(n / 6.5)
[val, num] = min(sum(plate_img5(:, [k1+5:k2-5])));
plate_img5(:, k1+num+5) = 0;
end
end
y1 = 10;
y2 = 0.25;
flag = 0;
word1 = [];
while flag == 0
[m, n] = size(plate_img5);
left = 1;
width = 0;
while sum(plate_img5(:, width+1)) ~= 0
width = width + 1;
end
if width < y1
plate_img5(:, [1:width]) = 0;
plate_img5 = my_imsplit(plate_img5);
else
temp = my_imsplit(imcrop(plate_img5, [1,1,width,m]));
[m, n] = size(temp);
all = sum(sum(temp));
two_thirds=sum(sum(temp([round(m/3):2*round(m/3)],:)));
if two_thirds/all > y2
flag = 1;
word1 = temp;
end
plate_img5(:, [1:width]) = 0;
plate_img5 = my_imsplit(plate_img5);
end
end
figure;
subplot(2,4,1), imshow(plate_img5);
% 分割出第二个字符
[word2,plate_img5]=getword(plate_img5);
subplot(2,4,2), imshow(plate_img5);
% 分割出第三个字符
[word3,plate_img5]=getword(plate_img5);
subplot(2,4,3), imshow(plate_img5);
% 分割出第四个字符
[word4,plate_img5]=getword(plate_img5);
subplot(2,4,4), imshow(plate_img5);
% 分割出第五个字符
[word5,plate_img5]=getword(plate_img5);
subplot(2,3,4), imshow(plate_img5);
% 分割出第六个字符
[word6,plate_img5]=getword(plate_img5);
subplot(2,3,5), imshow(plate_img5);
% 分割出第七个字符
[word7,plate_img5]=getword(plate_img5);
subplot(2,3,6), imshow(plate_img5);
figure;
subplot(5,7,1),imshow(word1),title('1');
subplot(5,7,2),imshow(word2),title('2');
subplot(5,7,3),imshow(word3),title('3');
subplot(5,7,4),imshow(word4),title('4');
subplot(5,7,5),imshow(word5),title('5');
subplot(5,7,6),imshow(word6),title('6');
subplot(5,7,7),imshow(word7),title('7');
word1=imresize(word1,[40 20]);%imresize对图像做缩放处理,常用调用格式为:B=imresize(A,ntimes,method);其中method可选nearest,bilinear(双线性),bicubic,box,lanczors2,lanczors3等
word2=imresize(word2,[40 20]);
word3=imresize(word3,[40 20]);
word4=imresize(word4,[40 20]);
word5=imresize(word5,[40 20]);
word6=imresize(word6,[40 20]);
word7=imresize(word7,[40 20]);
subplot(5,7,15),imshow(word1),title('11');
subplot(5,7,16),imshow(word2),title('22');
subplot(5,7,17),imshow(word3),title('33');
subplot(5,7,18),imshow(word4),title('44');
subplot(5,7,19),imshow(word5),title('55');
subplot(5,7,20),imshow(word6),title('66');
subplot(5,7,21),imshow(word7),title('77');
imwrite(word1,'1.jpg'); % 创建七位车牌字符图像
imwrite(word2,'2.jpg');
imwrite(word3,'3.jpg');
imwrite(word4,'4.jpg');
imwrite(word5,'5.jpg');
imwrite(word6,'6.jpg');
imwrite(word7,'7.jpg');
%% 进行字符识别
liccode=char(['0':'9' 'A':'Z' '京辽鲁陕苏豫浙贵']);%建立自动识别字符代码表;'京津沪渝港澳吉辽鲁豫冀鄂湘晋青皖苏赣浙闽粤琼台陕甘云川贵黑藏蒙桂新宁'
% 编号:0-9分别为 1-10;A-Z分别为 11-36;
% 京 津 沪 渝 港 澳 吉 辽 鲁 豫 冀 鄂 湘 晋 青 皖 苏
% 赣 浙 闽 粤 琼 台 陕 甘 云 川 贵 黑 藏 蒙 桂 新 宁
% 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59
% 60 61 62 63 64 65 66 67 68 69 70
subBw2 = zeros(40, 20);
num = 1; % 车牌位数
for i = 1:7
ii = int2str(i); % 将整型数据转换为字符串型数据
word = imread([ii,'.jpg']); % 读取之前分割出的字符的图片
segBw2 = imresize(word, [40,20], 'nearest'); % 调整图片的大小
segBw2 = im2bw(segBw2, 0.5); % 图像二值化
if i == 1 % 字符第一位为汉字,定位汉字所在字段
kMin = 37;
kMax = 44;
elseif i == 2 % 第二位为英文字母,定位字母所在字段
kMin = 11;
kMax = 36;
elseif i >= 3 % 第三位开始就是数字了,定位数字所在字段
kMin = 1;
kMax = 36;
end
l = 1;
for k = kMin : kMax
fname = strcat('字符模板\',liccode(k),'.jpg'); % 根据字符库找到图片模板
samBw2 = imread(fname); % 读取模板库中的图片
samBw2 = im2bw(samBw2, 0.5); % 图像二值化
% 将待识别图片与模板图片做差
for i1 = 1:40
for j1 = 1:20
subBw2(i1, j1) = segBw2(i1, j1) - samBw2(i1 ,j1);
end
end
% 统计两幅图片不同点的个数,并保存下来
Dmax = 0;
for i2 = 1:40
for j2 = 1:20
if subBw2(i2, j2) ~= 0
Dmax = Dmax + 1;
end
end
end
error(l) = Dmax;
l = l + 1;
end
% 找到图片差别最少的图像
errorMin = min(error);
findc = find(error == errorMin);
% error
% findc
% 根据字库,对应到识别的字符
Code(num*2 - 1) = liccode(findc(1) + kMin - 1);
Code(num*2) = ' ';
num = num + 1;
end
% 显示识别结果
disp(Code);
msgbox(Code,'识别出的车牌号');完整的代码及GUI我上传到这里了,有需要的可以进行下载,也可以私信联系我
基于MATLAB的车牌识别系统(GUI)-C#文档类资源-CSDN文库 https://download.csdn.net/download/S2191300319/85075374?spm=1001.2014.3001.5501
https://download.csdn.net/download/S2191300319/85075374?spm=1001.2014.3001.5501
写在最后:
此算法参考网上诸多算法,其中有不太正确之处,我将其进行整合调试,目前运行非常顺畅,效果也还可以,后续我会继续改进,若有不当之处,希望大家多多指正!