#论文学习#第二篇:CNN-SLAM: Real-time dense monocular SLAM with learned depth prediction
CNN-SLAM: Real-time dense monocular SLAM with learned depth prediction
CNN-SLAM:基于学习深度预测的实时稠密单目slam
Abstract:
本文研究了如何利用深度神经网络预测对深度地图进行精确和稠密的单目重建。我们提出了一种方法,将cnn预测的稠密深度地图与直接单目SLAM获得的深度测量自然融合在一起。我们的融合方案在单眼SLAM方法容易失败的图像位置上具有深度预测的优势,例如沿着低纹理区域,反之亦然。我们证明了使用深度预测对重建的绝对尺度的估计,因此也克服了单目SLAM的主要局限性之一。最后,我们提出了一个框架来有效地融合从单帧中获得的语义标签,通过稠密SLAM,从单一视图中得到语义一致的场景重建。在两个基准数据集上的评价结果表明了该方法的鲁棒性和准确性。
一、Introduction

SfM (Structure-from-Motion)和SLAM (Simultaneous Localization and Mapping)是计算机视觉和机器人领域中一个非常活跃的研究领域,旨在通过3D和成像传感器实现三维场景重建和相机姿态估计。
用学习方法从单个图像中进行深度预测。这种办法会出现边界条纹不清晰,为了恢复模糊的深度边界,CNN预测的深度图被用作密集重建的初始猜测,并通过依赖于类似于[4]中的小基线立体匹配的直接SLAM方案依次细化。重要的是,小基线立体匹配有可能在预测的深度图像上细化边缘区域,而这正是它们往往更模糊的地方。同时,从CNN预测的深度图中获得的初始猜测可以提供绝对比例信息来驱动姿态估计,因此与单目SLAM中的现有技术相比,估计的姿势轨迹和场景重建在绝对比例方面可以明显更准确。图1,a)显示了一个例子,说明了以精确的绝对尺度进行场景重建的有用性,例如本工作中提出的比例。此外,跟踪可以变得更加强大,因为CNN预测的深度不会受到上述纯旋转问题的影响,因为它是在每一帧上单独估计的。
最近cnn的另一个相关方面是,相同的网络架构可以成功地用于不同的高维回归任务,而不仅仅是深度估计:一个典型的例子是语义分割[3,29]。我们利用这一点提出了对我们框架的扩展,该扩展使用像素级标签,将语义标签与稠密SLAM进行一致且高效的融合,从而从单个视图获得语义上一致的场景重建:如图1,c)所示。
二、Related work
我们在框架内集成的两个领域,即SLAM和深度预测。
SLAM:有大量关于SLAM的文献。从被处理的输入数据类型来看,方法可以分为基于深度相机的[21,30,11]和基于单目相机的[22,4,20]。相反,从方法论的角度来看,它们被分为基于特征的[12,13,20]和直接的[22,5,4]。鉴于本文的范围,我们将在这里只关注单目SLAM方法。
orb-slam依赖于从输入图像中提取稀疏ORB特征来执行场景的稀疏重建以及估计摄像机姿势,还采用局部束调整和姿势图优化。对于直接使用单目SLAM,[22]的密集跟踪和映射(DTAM)通过使用短基线多视图立体匹配和正则化方案,在GPU上实现了实时稠密重建,从而在彩色图像中的低纹理区域上进行了更平滑的深度估计。
Depth prediction from single view:经典的深度预测方法采用手工制作的特征和概率图形模型[10,18]来生成正则化的深度图,通常对场景几何图形做出强有力的假设。特别是,预测的深度图被用作Keller的基于点的Fusion RGB-D SLAM算法[11]的输入,表明基于SLAM的场景重建可以使用深度预测获得,尽管它缺乏形状细节,主要是由于前面提到的模糊伪像与通过CNN的收缩部分丢失精细空间信息有关。
三、Proposed Monocular Semantic SLAM
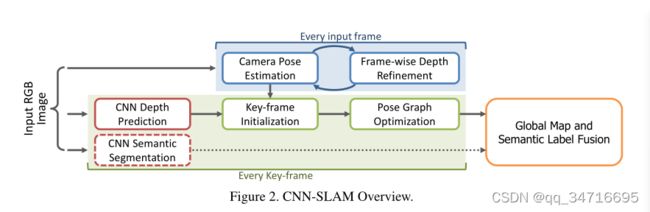
在本节中,我们说明了提出的3D重建框架,其中CNN预测的密集深度图与从直接单目SLAM获得的深度测量值融合在一起。此外,我们还展示了如何将cnn预测的语义分割与全局重建模型相融合。图2中的流程图勾勒了我们框架的管道。我们采用了一个基于关键帧的SLAM范式[12,4,20],特别是我们在[4]中使用直接半稠密方法作为基线。在这种方法中,视觉上不同的帧的子集被收集为关键帧,其位姿受到基于位姿图优化的全局细化的影响。同时,在每一输入帧上,通过估计该输入帧与最接近关键帧之间的变换来进行摄像机姿态估计。
为了保持较高的帧率,我们建议仅在关键帧上通过CNN预测深度图。特别的,如果当前估计的姿态距离现有的关键帧很远,则在当前帧和通过CNN估计的帧深度的基础上创建一个新的关键帧。此外,通过测量每个深度预测的像素置信度来构建不确定性图。由于在大多数情况下,用于SLAM的摄像机不同于用于获取CNN训练的数据集的摄像机,我们提出了一个特定的深度图归一化过程,旨在对不同的摄像机内在参数获得鲁棒性。在进行语义标签融合的同时,我们使用第二个卷积网络来预测输入帧的语义分割。最后,在关键帧上创建一个姿态图,对关键帧的相对姿态进行全局优化。
该框架的一个特别重要的阶段,也是我们提议的一个主要贡献,是通过小基线立体匹配,通过强制关键帧和相关输入帧之间的颜色一致性最小化,来细化与每个关键帧相关的cnn预测深度图。特别是,深度值将主要围绕具有梯度的图像区域进行细化,即对极匹配可以提供更高的精度。这将在第3.3和3.4小节中概述。
3.1、相机位姿评估
使用深度预测的测量置信度对其进行初始化,在每一帧上,我们的目标是估计当前摄像机的位姿。
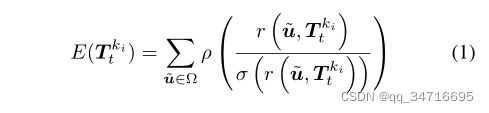
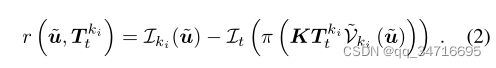
使用加权高斯-牛顿优化,使得残差流最小。其中ρ是Huber正则化。
3.2、基于CNN的深度预测和语义分割
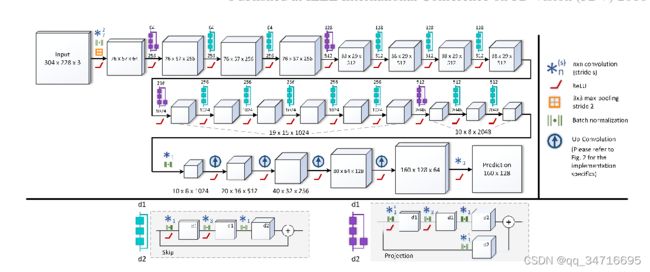
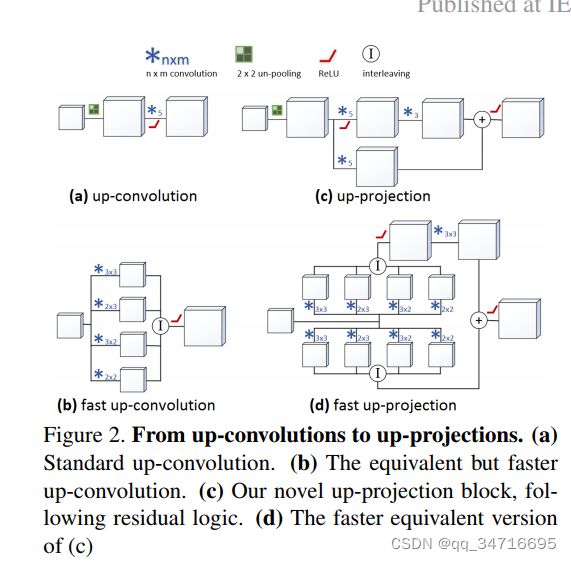
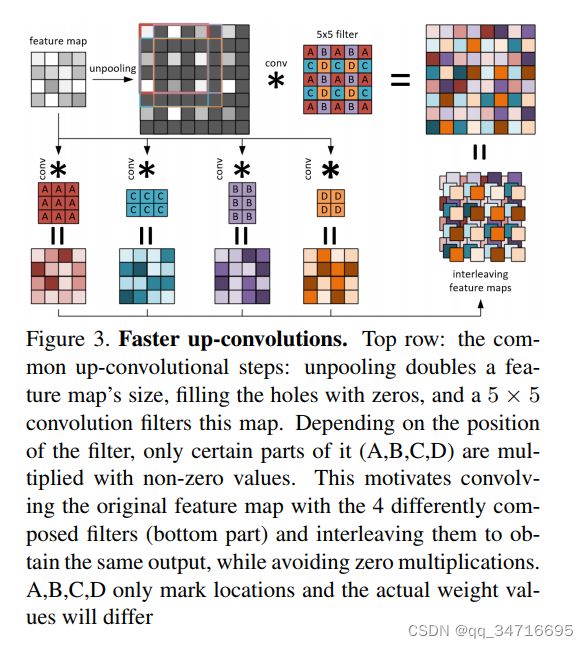
每次创建新的关键帧时,都会通过 CNN 预测相关的深度图。我们采用的深度预测架构是[16]中提出的最先进的方法,基于残余网络(ResNet)架构[9]扩展到完全卷积网络。特别是,架构的第一部分基于ResNet-50 [9],并在ImageNet上使用预先训练的权重进行初始化[24]。该架构的第二部分将 ResNet-50 中最初提供的最后一个池化和完全连接层替换为一系列由非池化层和卷积层组合组成的残差上采样块。上采样后,在最后卷积层之前应用drop-out,卷积层输出一个1通道的输出图,表示预测的深度图。损失函数基于反向 Huber 函数 [16]。
3.3、关键帧的创建和位姿图优化
使用预先训练的CNN进行深度预测的一个限制是,如果用于SLAM的传感器与用于捕捉训练集的传感器具有不同的内在参数,那么得到的三维重建的绝对尺度将是不准确的。为了改善这个问题,我们建议调整通过CNN回归的深度,使当前相机的焦距fcur与用于训练的传感器的焦距之间的比率。

此外,我们把每一个深度图Dki与不确定的图Uki联系在一起。在 [4] 中,通过将每个元素设置为较大的常量值来初始化此映射。由于CNN在每一帧都为我们提供了稠密的映射,但不依赖于任何时间正则化,因此我们建议通过基于当前深度图与其在最近的关键帧上各自的场景点之间的差异来计算置信度值来初始化我们的不确定性图。因此,这个置信度度量了每个预测深度值在不同帧之间的一致性:对于那些与高置信度相关的元素,后续的细化过程将比[4]中的细化过程更快、更有效。
为了进一步提高每个新初始化的关键帧的精度,我们建议将其深度图和不确定性图与从最近的关键帧传播的深度图和不确定性图融合在一起(这个显然不适用于第一个关键帧),因为它们已经用新的输入帧进行了细化(深度细化过程在3.4小节中进行了描述)。
最后,位姿图也会在每个新关键帧处更新,方法是使用图中已经存在的关键帧创建新边缘,这些关键帧与新添加的关键帧共享相似的视场(即具有较小的相对位姿)。此外,每次都通过位姿图优化[14]对关键帧的位姿进行全局细化。
3.4、Frame-wise Depth Refinement
这一阶段的目标是根据每一帧新帧估计的深度图,不断细化当前活动关键帧的深度图。为了实现这一目标,我们使用[5]的半密集方案中描述的小基线立体匹配策略,通过在当前帧t的每个像素处计算沿对极线的基于5像素匹配的深度图Dt和不确定性图Ut。这两种图基于当前所评估的相机位姿相对齐。
然后,估计的深度图和不确定性图直接与最近的关键帧ki的深度图和不确定性图融合,如下所示:
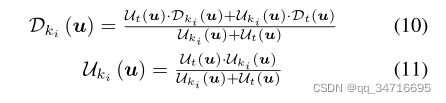
重要的是,由于提出的基于cnn的预测将关键帧与稠密的深度图关联起来,因此该过程可以稠密进行,即对关键帧的每个元素进行细化,而不是像[5]那样只对高梯度区域的深度值进行细化。由于在低纹理区域内观测到的深度往往具有很高的不确定性(即Ut值较高),因此,本文提出的方法自然会产生一个精细的深度图,在该图中,高强度梯度附近的元素将通过每帧估计的深度进行细化,而在越来越多的低纹理区域内的元素将逐渐保留CNN预测的深度值,而不会受到不确定深度观测的影响。
3.5、全局模型与语义标签融合
获得的一组关键帧可以融合在一起,以生成重建场景的3D全局模型。由于CNN被训练为除了深度图之外还提供语义标签,因此语义信息也可以通过我们表示为语义标签融合的过程与3D全局模型的每个元素相关联。
在我们的框架中,我们采用了[27]中提出的实时方案,该方案旨在将深度图和从RGB-D序列的每一帧获得的连接分量图逐步的融合在一起。该方法使用全球分割模型(GSM)平均分配标签到每个3D元素的时间,因此在帧的分割中对噪声又更好的鲁棒性。
四、与其他方法相比较


五、Conclusion
我们已经展示了如何通过深度神经网络将SLAM与深度预测相结合是一个很有前途的方向,可以解决传统单目重建固有的局限性,特别是在估计绝对尺度、沿着无纹理区域获取密集深度以及处理纯旋转运动方面。本文提出的基于小基线立体匹配的cnn预测深度地图精化方法自然地克服了这些问题,同时在存在摄像机平移和高图像梯度的情况下保持了直接单目SLAM的鲁棒性和准确性。该框架能够在融合语义分割标签和全局3D模型的同时联合重建场景,为单目相机理解场景开辟了新的视角。将深度预测与闭环相结合是未来的研究方向,即利用几何精细深度图改进深度估计。