【毕业设计】机器学习股票大数据量化分析与预测系统 - python 毕业设计
文章目录
- 0 前言
- 1 课题背景
- 2 实现效果
-
- UI界面设计
- web预测界面
- RSRS选股界面
- 3 软件架构
- 4 工具介绍
-
- Flask框架
- MySQL数据库
- LSTM
- 5 最后
0 前言
这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
机器学习股票大数据量化分析与预测系统
学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:3分
选题指导, 项目分享:
https://gitee.com/dancheng-senior/project-sharing-1/blob/master/%E6%AF%95%E8%AE%BE%E6%8C%87%E5%AF%BC/README.md
1 课题背景
基于机器学习的股票大数据量化分析系统,具有以下功能:
- 采集保存数据;
- 分析数据;
- 可视化;
- 深度学习股票预测
2 实现效果
UI界面设计
功能简述

日常数据获取更新

交易功能

web预测界面
- LSTM长时间序列预测
- RNN预测
- 机器学习预测
- 股票指标分析

预测效果如下:

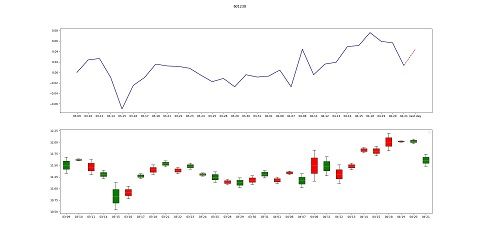
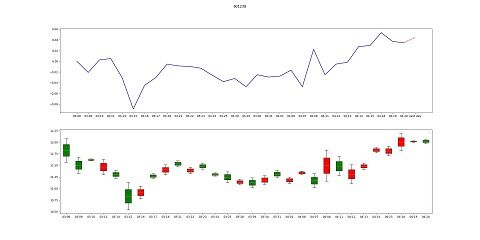
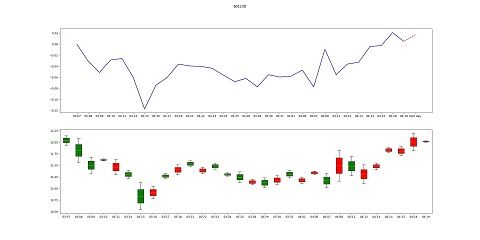
RSRS选股界面
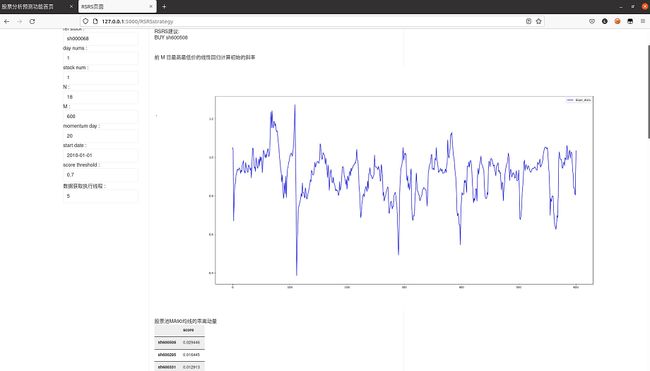
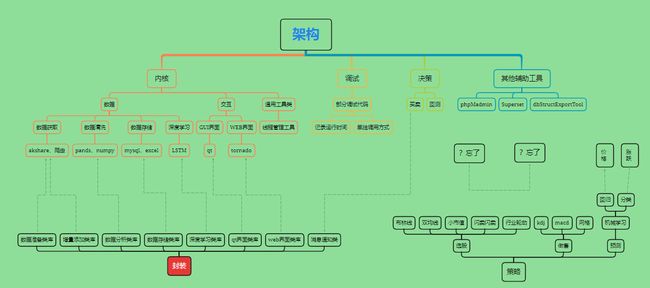
3 软件架构
整体的软件功能结构如下图
4 工具介绍
Flask框架
简介
Flask是一个基于Werkzeug和Jinja2的轻量级Web应用程序框架。与其他同类型框架相比,Flask的灵活性、轻便性和安全性更高,而且容易上手,它可以与MVC模式很好地结合进行开发。Flask也有强大的定制性,开发者可以依据实际需要增加相应的功能,在实现丰富的功能和扩展的同时能够保证核心功能的简单。Flask丰富的插件库能够让用户实现网站定制的个性化,从而开发出功能强大的网站。
本项目在Flask开发后端时,前端请求会遇到跨域的问题,解决该问题有修改数据类型为jsonp,采用GET方法,或者在Flask端加上响应头等方式,在此使用安装Flask-CORS库的方式解决跨域问题。此外需要安装请求库axios。
Flask框架图

代码实例
from flask import Flask, render_template, jsonify
import requests
from bs4 import BeautifulSoup
from snownlp import SnowNLP
import jieba
import numpy as np
app = Flask(__name__)
app.config.from_object('config')
# 中文停用词
STOPWORDS = set(map(lambda x: x.strip(), open(r'./stopwords.txt', encoding='utf8').readlines()))
headers = {
'accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
'accept-language': "en-US,en;q=0.9,zh-CN;q=0.8,zh-TW;q=0.7,zh;q=0.6",
'cookie': 'll="108296"; bid=ieDyF9S_Pvo; __utma=30149280.1219785301.1576592769.1576592769.1576592769.1; __utmc=30149280; __utmz=30149280.1576592769.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); _vwo_uuid_v2=DF618B52A6E9245858190AA370A98D7E4|0b4d39fcf413bf2c3e364ddad81e6a76; ct=y; dbcl2="40219042:K/CjqllYI3Y"; ck=FsDX; push_noty_num=0; push_doumail_num=0; douban-fav-remind=1; ap_v=0,6.0',
'host': "search.douban.com",
'referer': "https://movie.douban.com/",
'sec-fetch-mode': "navigate",
'sec-fetch-site': "same-site",
'sec-fetch-user': "?1",
'upgrade-insecure-requests': "1",
'user-agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36 Edg/79.0.309.56"
}
login_name = None
# --------------------- html render ---------------------
@app.route('/')
def index():
return render_template('index.html')
@app.route('/search')
def search():
return render_template('search.html')
@app.route('/search/' )
def search2(movie_name):
return render_template('search.html')
MySQL数据库
简介
MySQL是一个关系型数据库,由瑞典MySQL AB公司开发,目前已经被Oracle收购。
Mysql是一个真正的多用户、多线程的SQL数据库。其使用的SQL(结构化查询语言)是世界上最流行的和标准化的数据库语言,每个关系型数据库都可以使用MySQL是以客户机/服务器结构实现的,也就是俗称的C/S结构,它由一个服务器守护程序mysqld和很多不同的客户程序和库组成。
Python操作mysql数据库
本项目中我们需要使用python来操作mysql数据库,因此需要用到pymysql这个库
安装:
pip install pymysql
数据库连接实例:
# 导入pymysql
import pymysql
# 定义一个函数
# 这个函数用来创建连接(连接数据库用)
def mysql_db():
# 连接数据库肯定需要一些参数
conn = pymysql.connect(
host="127.0.0.1",
port=3307,
database="ksh",
charset="utf8",
user="root",
passwd="123456"
)
if __name__ == '__main__':
mysql_db()
数据库连接实例:
# 导入pymysql
import pymysql
# 定义一个函数
# 这个函数用来创建连接(连接数据库用)
def mysql_db():
# 连接数据库肯定需要一些参数
conn = pymysql.connect(
host="127.0.0.1",
port=3307,
database="ksh",
charset="utf8",
user="root",
passwd="123456"
)
if __name__ == '__main__':
mysql_db()
LSTM
简介
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
LSTM结构(图右)和普通RNN的主要输入输出区别如下所示。


Torch代码实现
import torch
from sklearn.metrics import accuracy_score
#定义需要的模型结构,继承自torch.nn.Module
#必须包含__init__和forward两个功能
class mylstm(torch.nn.Module):
def __init__(self, lstm_input_size, lstm_hidden_size, lstm_batch, lstm_layers):
# 声明继承关系
super(mylstm, self).__init__()
self.lstm_input_size, self.lstm_hidden_size = lstm_input_size, lstm_hidden_size
self.lstm_layers, self.lstm_batch = lstm_layers, lstm_batch
# 定义lstm层
self.lstm_layer = torch.nn.LSTM(self.lstm_input_size, self.lstm_hidden_size, num_layers=self.lstm_layers, batch_first=True)
# 定义全连接层 二分类
self.out = torch.nn.Linear(self.lstm_hidden_size, 2)
def forward(self, x):
# 激活
x = torch.sigmoid(x)
# LSTM
x, _ = self.lstm_layer(x)
# 保留最后一步的输出
x = x[:, -1, :]
# 全连接
x = self.out(x)
return x
def init_hidden(self):
#初始化隐藏层参数全0
return torch.zeros(self.lstm_batch, self.lstm_hidden_size)