论文阅读|HigherHRNet
HigherHRNet: Scale-Aware Representation Learning forBottom-Up Human Pose Estimation
原文:https://openaccess.thecvf.com/content_CVPR_2020/papers/Cheng_HigherHRNet_Scale-Aware_Representation_Learning_for_Bottom-Up_Human_Pose_Estimation_CVPR_2020_paper.pdf https://openaccess.thecvf.com/content_CVPR_2020/papers/Cheng_HigherHRNet_Scale-Aware_Representation_Learning_for_Bottom-Up_Human_Pose_Estimation_CVPR_2020_paper.pdf
https://openaccess.thecvf.com/content_CVPR_2020/papers/Cheng_HigherHRNet_Scale-Aware_Representation_Learning_for_Bottom-Up_Human_Pose_Estimation_CVPR_2020_paper.pdf
参考资料:(64条消息) HigherHRNet 论文阅读笔记_酉意铭的博客-CSDN博客_higherhrnet
HigherHRNet:更长更宽更高更强_openRiemann的blog-CSDN博客
代码:GitHub - HRNet/HigherHRNet-Human-Pose-Estimation: This is an official implementation of our CVPR 2020 paper "HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation" (https://arxiv.org/abs/1908.10357)
目录
Abstract
Introduction
our controbutions:
Related works
自上而下的方法
自下而上的方法
特征金字塔
高分辨率特征图
Higher-Resolution Network
HigherHRNet
HRNet
HigherHRNet
Grouping
Deconvolution Module
Multi-Resolution Supervision
Heatmap Aggregation for Inference
Experiments
COCO Keypoint detection
消融实验
HRNet vs. HigherHRNet
HigherHRNet gain breakdown.
Training with larger image size
Larger backbone
CrowdPose
Conclusion
Abstract
对于small persons,自下而上的人体姿态估计方法存在困难,在这篇文章中提出HigherHRNet:一种新的自下而上的人体姿势估计方法,用于使用高分辨率特征金字塔学习尺度感知表示。采用了用于训练的多分辨率监督和用于推理的多分辨率聚合,能够解决自下而上的多人姿势估计中的尺度变化挑战,并能更精确地定位关键点,尤其是对于小人物。HigherHRNet中的特征金字塔包括HRNet的特征图输出和通过转置卷积进行上采样的高分辨率输出。
在COCO test-dev中,HigherHRNet的中等人体的AP性能比以前最佳的自下而上方法高2.5%,显示了其在处理尺度变化方面的有效性。此外,HigherHRNet在COCO test-dev(AP: 70.5%)上获得了最新的最新结果,而无需使用优化或其他后处理技术,从而超越了所有现有的自下而上的方法。 HigherHRNet甚至在CrowdPose测试(AP:67.6%)上超过了所有自上而下的方法,表明它在拥挤场景中的稳健性。
Introduction
自下而上的方法首先通过预测不同解剖关键点的热图来定位输入图像中所有人员的无身份关键点,然后将它们分组为个人实例。 这种策略有效地使自下而上的方法更快,更有能力实现实时姿态估计。 然而,由于自下而上的方法需要处理尺度变化,自下而上的方法和自上而下的方法的性能仍然存在较大的差距,尤其是对于小规模的人。
自下而上方法预测小人物的关键点方面的挑战:
- 一是处理尺度变化,即在不牺牲大人物的性能的情况下提高小人物的性能。
- 另一个是生成高质量的高分辨率热图,用于精确定位小人物的关键点。
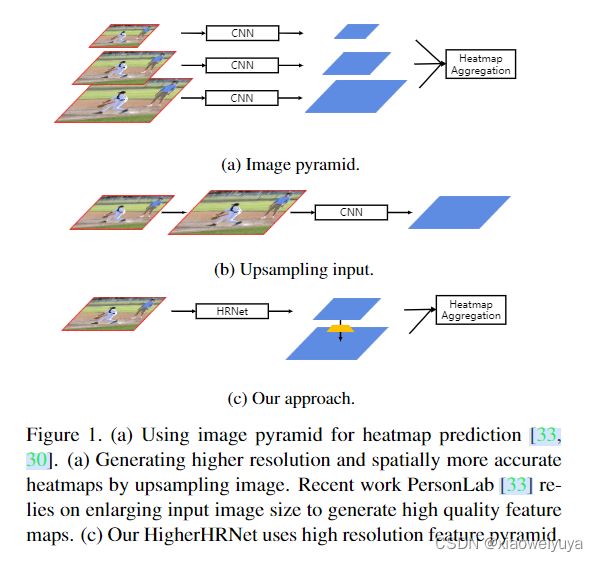
以前的自底向上方法主要集中在对关键点进行分组,简单地使用单一分辨率的特征图,即输入图像分辨率的1/4来预测关键点的热图。这些方法忽略了尺度变化的挑战,在推理过程中依赖于图像金字塔(图 1(a))。 特征金字塔是处理尺度变化的基本组件,然而,自上而下特征金字塔中较小分辨率的特征图通常会遇到第二个挑战。 PersonLab [33] 通过增加输入分辨率来生成高分辨率热图(图 1(b))。虽然小人物的表现随着输入分辨率持续增加,但当输入分辨率太大时,大人物的表现开始下降 .为了解决这些挑战,在不牺牲计算成本的情况下,以自然而简单的方式为自下而上的关键点预测生成空间上更准确和尺度感知的热图至关重要。
HigherHRNet 通过新的高分辨率特征金字塔模块生成高分辨率热图。 与传统的特征金字塔从 1/32 分辨率开始,使用带横向连接的双线性上采样逐渐将特征图分辨率提高到 1/4 不同,高分辨率特征金字塔直接从1/4分辨率开始,这是最高分辨率的特征。在主干中,并通过反卷积生成更高分辨率的特征图(图 1(c))。我们在 HRNet [38, 40] 的 1/4 分辨率路径上构建高分辨率特征金字塔,使其高效。 为了使 HigherHRNet 能够处理尺度变化,我们进一步提出了一种多分辨率监督策略,将不同分辨率的训练目标分配给相应的特征金字塔级别。 最后,我们在推理过程中引入了一种简单的多分辨率热图聚合策略,以生成具有尺度感知的高分辨率热图。
HigherHRNet在COCO2017 test-dev上无需任何后期处理即可达到70.5%的AP,大大优于所有现有的自下而上的方法。 此外,我们观察到,大多数收益来自中级人体(关键点检测任务没有小人体标注),HigherHRNet在不牺牲性能的情况下,对中型人体的性能比以前最佳的自下而上方法高2.5%。 大人体(+0.3%AP)。 这一观察结果证明HigherHRNet确实在解决尺度变化难题。 我们还为新的CrowdPose [24]数据集上的自下而上方法提供了坚实的基础。 我们的HigherHRNet在CrowdPose测试中的AP达到67.6%,超过了所有现有方法。 该结果表明,自下而上的方法在拥挤的场景中自然具有优势。
our controbutions:
- 试图解决在自下而上的多人姿态估计中很少研究的尺度变化挑战。
- 在训练阶段生成具有多分辨率监督的高分辨率特征金字塔,在推理阶段生成多分辨率热图聚合,以预测对小人物有益的尺度感知的高分辨率热图。
- HigherHRNet在具有挑战性的COCO数据集上有效,优于所有其他自下而上的方法,尤其是针对medium person。
- 在人群姿势数据集上获得了一个新的最先进的结果,这表明自下而上的方法比自上而下的方法更适用于拥挤的场景。
Related works
自上而下的方法
自下而上的方法
特征金字塔
高分辨率特征图
生成高分辨率特征图的方法主要有4种。
- Encoderdecoder:捕获编码器路径中的上下文信息,并恢复解码器路径中的高分辨率特征。解码器通常包含一系列双线性上采样操作,并具有相同分辨率的编码器功能的跳过连接。
- 扩展卷积(也称为“atrous”卷积)用于删除多个跨步卷积/最大池,以保留特征图分辨率。扩散卷积可防止丢失空间信息,但会带来更多的计算成本。
- 在网络末端依次使用反卷积(转置卷积),以有效地提高特征图的分辨率。 SimpleBaseline [42]演示了反卷积可以生成用于热图预测的高质量特征图。
- 最近,提出了一种高分辨率网络HRNet,作为在整个网络上保持高分辨率传输的有效方法。 HRNet由具有不同分辨率的多个分支组成。较低分辨率的分支捕获上下文信息,而较高分辨率的分支保留空间信息。通过分支之间的多尺度融合,HRNet可以生成具有丰富语义的高分辨率特征图
我们采用HRNet作为我们的基础网络来生成高质量的特征图。 并且我们添加了一个反卷积模块,以生成更高分辨率的特征图以预测热图。 生成的模型称为“尺度感知“的高分辨率网络HigherHRNet。 由于HRNet 和反卷积都是有效的,HigherHRNet是一种高效模型,可用于生成用于热图预测的高分辨率特征图。
Higher-Resolution Network
HigherHRNet
HRNet
HRNet在第一阶段从高分辨率分支开始。 在随后的每个阶段中,都会将一个新分支与当前分支中分辨率最低的1/2并行添加到当前分支中。 随着网络具有更多阶段,它将具有更多具有不同分辨率的并行分支,并且先前阶段的分辨率都保留在以后阶段。 图2显示了一个包含3个并行分支的示例网络结构。
我们使用与HRNet类似的方式实例化backbone。 网络从一个stem开始,该stem由两个跨步的3×3卷积组成,将分辨率降低到1/ 4。 第一级包含4个残差单元,其中每个单元由一个bottleneck(宽度(通道数)为64)形成,然后是一个3×3卷积,将特征图的宽度减小到C。第二,第三,第四级包含1, 4个和3个多分辨率块。 四个分辨率的卷积宽度分别为C,2C,4C和8C。 多分辨率群卷积中的每个分支都有4个残差单位,每个单元在每个分辨率中都有2个3×3卷积。 通过将C分别设置为32和48,我们可以测试两个容量不同的网络。
HRNet最初是为自上而下的姿势估计而设计的。 在这项工作中,我们通过添加1×1卷积来预测热图和标记图,从而将HRNet应用于自下而上的方法,类似于[30]。 我们仅使用最高分辨率(输入图像的1/4)的特征图进行预测。 [30]之后,我们为每个关键点使用标量tag。
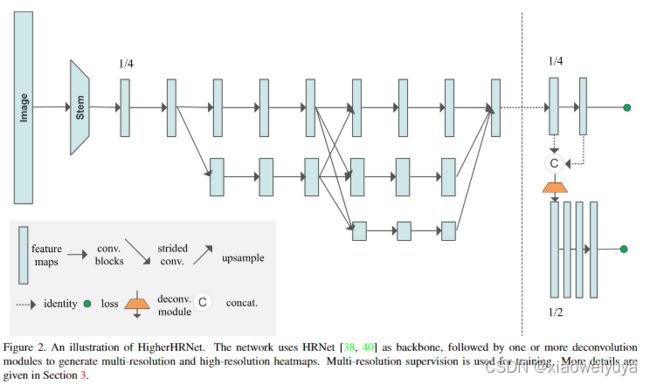
HigherHRNet
热图的分辨率对于预测小型人群的关键点很重要。 现有的大多数人体姿势估计方法都是通过准备ground truth 热图来预测高斯平滑的热图,并将未标准化的高斯核应用于每个关键点位置。 添加此高斯核有助于训练网络,因为CNN倾向于输出空间平滑的响应,这是卷积运算的本质。 但是,应用高斯核也会给关键点的精确定位带来混乱,特别是对于属于小人物的关键点。 减少这种混乱的简单方法是减少高斯核的标准偏差。 但是,从经验上我们发现,这会使优化变得更加困难,并导致更糟糕的结果。
我们没有减小标准差,而是通过在不同分辨率下预测标准差不变的更高分辨率的热图来解决这个问题,自下而上的方法通常以输入图像分辨率为1/4预测热图。然而,我们发现这个分辨率不足以预测准确的热图。受[42](它表明反卷积可以有效地生成高质量和高分辨率的特征图)的启发,我们在HRNet中最高分辨率的特征图的基础之上通过增加一个反卷积模块来构建HigherHRNet,如图2所示,如第3.3节所述。
反卷积模块将来自HRNet的特征和预测热图作为输入,并生成分辨率比输入特征图大2倍的新特征图。 因此,反卷积模块会与HRNet的特征图一起生成具有两种分辨率的特征金字塔。 反卷积模块还通过添加额外的1×1卷积来预测热图。 我们遵循第3.4节,以不同的分辨率训练热图预测变量,并使用第3.5节中所述的热图聚合策略进行推理。
如果需要更大的分辨率,可以添加更多的反卷积模块。 我们发现反卷积模块的数量取决于数据集人体尺度的分布。 一般而言,包含较小人体的数据集需要较大分辨率的特征图才能进行预测,反之亦然。 在实验中,我们发现添加单个反卷积模块可在COCO数据集上实现最佳性能。
Grouping
最近的工作[30,23]表明,可以通过使用关联嵌入的简单方法以高精度解决分组问题。 有证据表明,[30]中的实验结果表明,在带有COCO关键点检测数据集的500个训练图像上,使用具有预测tags的ground truth检测将AP从59.2提高到94.0 [27] 。 我们遵循[30]将关联嵌入(associative embedding)用于关键点分组。 分组过程通过将tags具有小的L2距离的关键点分组,将无身份的关键点聚类为多个个体。
Deconvolution Module 转置卷积
我们提出了一个简单的反卷积模块,用于生成高质量的特征图,其分辨率是输入特征图的两倍。 [42]之后,我们使用4×4反卷积(也称为转置卷积),然后使用BatchNorm和ReLU来学习对输入特征图进行上采样。 可选地,我们可以在反卷积之后进一步添加几个基本残差块,以细化上采样的特征图。 我们在HigherHRNet中添加4个残差块。
与[42]不同,反卷积模块的输入是来自HRNet或以前的反卷积模块的特征图和预测的热图的串联。 每个反卷积模块的输出特征图也可用于以多尺度方式预测热图。


Multi-Resolution Supervision 多分辨率监督
与其他仅对最大分辨率热图应用监视的自下而上的方法不同,我们在训练过程中引入了多分辨率监督以处理尺度变化。 我们将ground truth关键点位置转换为所有分辨率的热图上的位置,以生成具有不同分辨率的ground truth热图。 然后,我们将具有相同标准偏差(默认情况下使用标准偏差= 2)的高斯核应用于所有这些ground truth热图。 我们发现重要的是不要缩放高斯核的标准偏差。 这是因为特征金字塔的不同分辨率适合于预测不同尺度的关键点。 在更高分辨率的特征图上,需要相对较小的标准偏差(与特征图的分辨率相比)以更精确地定位小人物的关键点。
在HigherHRNet中的每个预测尺度上,我们计算该尺度的预测热图与其关联的ground truth热图之间的均方误差。 热图的最终损失是所有分辨率的均方误差之和。
值得强调的是,由于以下原因,我们没有将不同尺度的人体分配给特征金字塔中的不同级别。 首先,用于分配训练目标的启发式方法取决于数据集和网络体系结构。 由于数据集(人对所有目标的尺度分布)和体系结构(HigherHRNet仅具有2个金字塔等级,而FPN有4个)变化,很难将FPN 的启发式方法转换为HigherHRNet。 其次,由于我们应用了高斯核,因此ground truth关键点目标彼此相互作用。 因此,仅通过设置忽略区域来分离关键点非常困难。 我们认为模型能够自动关注特征金字塔不同级别中的特定尺度。
在HigherHRNet当中, tagmap的训练与热图不同。 我们仅以最低分辨率预测标签图,而不使用所有分辨率。 这是因为学习标记图需要全局推理,它更适合于以较低的分辨率预测标记图。 根据经验,我们还发现更高的分辨率无法很好地预测标签图,甚至无法收敛。 因此,我们遵循[30]来以 分辨率的输入图像在特征图上训练标签图。
分辨率的输入图像在特征图上训练标签图。
Heatmap Aggregation for Inference 热图聚合
我们提出了推理过程中的热图聚合策略。 我们使用双线性插值法将具有不同分辨率的所有预测热图上采样到输入图像的分辨率,并平均所有尺度的热图以进行最终预测。 此策略与以前的方法完全不同,以前的方法仅使用单个尺度或单个阶段的热图进行预测。
我们使用热图聚合的原因是为了启用尺度感知姿势估计。 例如,COCO关键点数据集包含从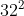 个像素到超过
个像素到超过![]() 个像素的大规模尺度变化的人。 自上而下的方法通过将人的区域近似标准化为单个尺度来解决此问题。 但是,自下而上的方法需要注意尺度,以从所有尺度中检测关键点。 我们在HigherHRNet中发现了不同尺度的热图,更好地捕获了不同尺度的关键点。 例如,可以在较高分辨率的热图中恢复在较低分辨率的热图中丢失的小人们的关键点。 因此,对来自不同分辨率的预测热图进行平均,使HigherHRNet成为可识别尺度的姿势估计器。
个像素的大规模尺度变化的人。 自上而下的方法通过将人的区域近似标准化为单个尺度来解决此问题。 但是,自下而上的方法需要注意尺度,以从所有尺度中检测关键点。 我们在HigherHRNet中发现了不同尺度的热图,更好地捕获了不同尺度的关键点。 例如,可以在较高分辨率的热图中恢复在较低分辨率的热图中丢失的小人们的关键点。 因此,对来自不同分辨率的预测热图进行平均,使HigherHRNet成为可识别尺度的姿势估计器。
Experiments
COCO Keypoint detection
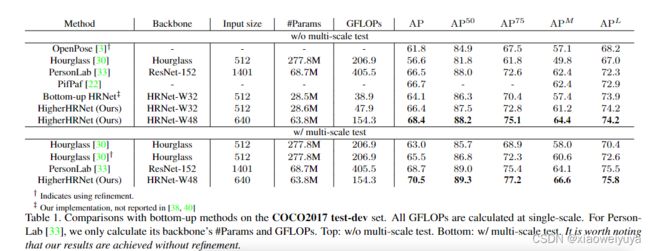
Tabel1:COCO2017测试集上自下而上的方法的比较
从结果可以看出,使用HRNet本身已成为自下而上方法(64.1 AP)的简单而强大的基准。 我们的仅使用单一尺度测试的HRNet baseline方法优于使用多尺度测试的Hourglass,而HRNet在FLOP方面的参数和计算量要少得多。 配备轻量级反卷积模块,我们提出的HigherHRNet(66.4 AP)在参数(+0.4%)和FLOPs(+23.1%)略有增加的情况下,以+2.3 AP胜过HRNet。 HigherHRNet可与PersonLab 媲美,但参数仅为50%,FLOP为11%。 如果我们进一步使用多尺度测试,我们的HigherHRNet将达到70.5的AP,大大优于所有现有的自下而上的方法。 在[3,30]中,我们不使用任何自上而下的方法来进行后期处理,例如进行优化。
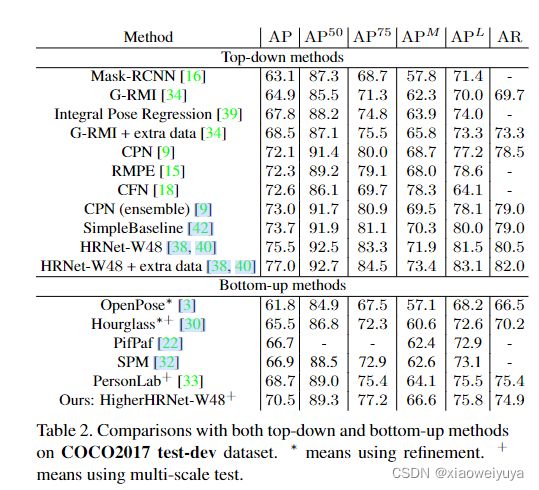
表2列出了COCO2017 test-dev数据集的自下而上和自上而下的方法。 HigherHRNet进一步缩小了自下而上和自上而下方法之间的性能差距。
消融实验
HRNet vs. HigherHRNet

对于HigherHRNet,使用无额外残差块的反卷积模块,并且使用热图聚合进行推理。 结果显示在表3中。通过使用特征步长为4的HRNet的简单的自下而上的基线可以达到AP = 64.4。 通过添加一个反卷积模块,我们的HighHRHRNet的特征跨度为2,大大超过了HRNet +2.5 AP(实现了66.9 AP)。 此外,主要改进来自中型人体,其中APM从HRNet的57.1提高到HigherHRNet的61.0。
这些结果表明,HigherHRNet由于具有高分辨率的热图,因此在小尺度下的性能要好得多。 我们还发现大人体姿势的AP不会下降。 这主要是因为我们还使用较小分辨率的热图进行预测。 它表明
- 以更高的分辨率进行预测对自下而上的姿势估计很有帮助
- 尺度感知预测很重要。
如果我们在HRNet之后添加两个反卷积模块的序列以生成与输入图像具有相同分辨率的特征图,则会观察到性能从66.9 AP降低到66.5 AP,仅添加一个反卷积模块。 中型人体的改善很小(+0.1 AP),但大人体的表现却有很大的下降(-0.8 AP)。 我们假设这是因为特征图尺度和目标尺度之间的不匹配。 较大的分辨率特征图(特征步幅= 1)适合于检测甚至更小的人的关键点,但不考虑COCO中的小人进行姿势估计。 因此,默认情况下,我们仅对COCO数据集使用一个反卷积模块。 但我们想指出的是,级联反卷积模块的数量应取决于数据集,我们将在以后的工作中在更多数据集上对此进行验证。
HigherHRNet gain breakdown.
为了更好地理解所提出组件的增益,我们对每个单独的组件进行了详细的消融研究。 图3展示了我们实验的所有架构。 结果示于表4。
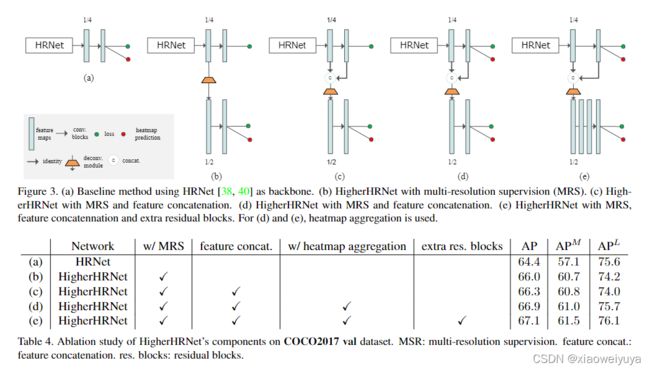
反卷积模块的效果
我们对添加反卷积模块以生成更高分辨率的热图的效果进行消融研究。 为了公平地比较,我们仅使用最高分辨率的特征图来生成用于预测的热图(图3(b))。 HRNet(图3(a))达到了64.4 AP的baseline。 通过添加一个反卷积模块,该模型可实现66.0 AP,这比baseline好1.6 AP。 这种改进完全归因于在更大的更高质量的特征图上进行预测。 该结果验证了我们的主张,即对于自下而上的姿势估计,预测更高分辨率的特征图非常重要。
特征连接的效果
我们将特征图与来自HRNet的预测热图连接起来,作为反卷积模块的输入(图3(c)),性能进一步提高到66.3 AP。 我们还观察到,中型人体的收益很大,而大型人体的表现却有所下降。 比较方法(a)和(c),以较高的分辨率预测热图的收益主要来自中等人体(+3.7APM)。 此外,大人体的AP下降(-1.6 AP)证明了我们的主张,即特征图的不同分辨率对不同尺度的人敏感。
热图聚合的效果
我们根据热图聚合策略进一步使用热图的所有分辨率进行inference(图3(d))。 与仅使用最高分辨率的热图进行inference的图3(c)(66.3 AP)相比,应用热图聚合策略可实现66.9 AP。 比较方法(d)和(e),热图聚合的收益来自大人体(+1.7 AP)。 大人体的表现甚至比较低分辨率下的预测要好一些(方法(a))。 这意味着使用热图聚合策略预测热图是真正尺度感知的。
额外残差块的效果
我们在反卷积模块中添加了4个残差块,我们的最佳模型实现了67.1 AP。 添加残差块可以进一步细化特征图,并且同样增加中型和大型人员的AP。
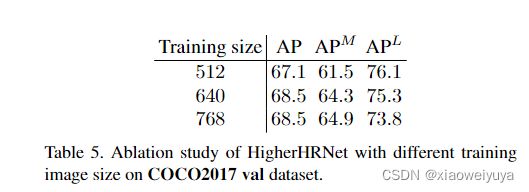
Training with larger image size
一个自然的问题是,使用更大的输入size进行训练是否可以进一步提高性能? 为了回答这个问题,我们用640×640和768×768训练HigherHRNet,结果如表5所示,所有三种模型都使用训练图像尺寸进行了测试。 我们发现,通过将训练图像大小增加到640,可以显着提高AP的1.4增益。 大部分收益来自中型人体,而大型人体的表现则略有下降。 当我们进一步将训练图像大小更改为768时,整个AP不再变化。 我们观察到中等人体的略微改善以及大人体的大幅度衰减。
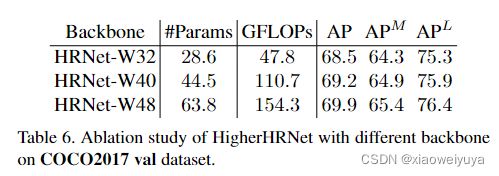
Larger backbone
在先前的实验中,我们使用HRNet-W32(1/4分辨率特征图具有32个通道)作为backbone。 我们使用较大backbone 的HRNet W40和HRNet-W48进行实验。 结果显示在表6中。我们发现使用较大的backbone可以持续提高中型和大型人体的性能。
CrowdPose
CrowdPose数据集由20,000张图像组成,包含约80,000个人。 训练,验证和测试子集按5:1:4的比例分配。 与COCO关键点数据集相比,CrowdPose的场景更为拥挤,给姿势估计方法带来了更多挑战。 评估指标与COCO相同。
另一方面,自下而上的方法自然在拥挤的场景中具有优势。 为了验证HigherHRNet在拥挤场景中的稳健性,以及为自下而上的方法设置一个强大的基准。 我们在CrowdPose训练和val集合上训练了最好的HigherHRNet-W48模型,并在测试集中报告了性能。 所有训练参数均严格遵循COCO,我们使用640×640的crop size进行训练和测试。
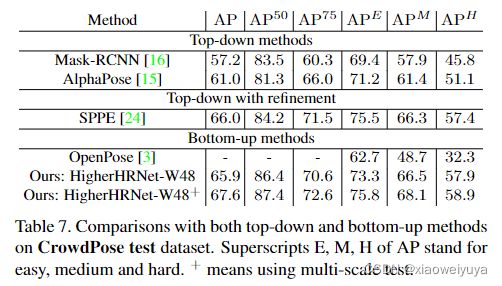
结果显示在表7中。我们的HigherHRNet优于单纯的自上而下的方法,大大提高了6.6 AP。 HigherHRNet还以1.6 AP优于以前的最佳方法SPPE(对自上而下的方法[15]进行了global refinement),大部分收益来自APM(+1.8 AP)和APH(+1.5 AP) ,其中包含人群最多的图像。 即使没有多尺度测试,HigherHRNet在![]() 中也比SPPE高出0.5。
中也比SPPE高出0.5。
Conclusion
- 高分辨率特征金字塔——由HRNet的特征图输出加上转置卷积上采样输出组成——用于尺度感知
- 多分辨率监督——用于训练(让模型同时关注多尺度)
- 对分辨率聚合——用于推理(增加模型的尺度感知能力)
- 特征连接和额外的残差块(模型内部的细节调整,让最后的结果更加准确)