【机器学习】基于LDA主题模型的人脸识别专利分析
作者 | Soren Gran
编译 | VK
来源 | Towards Data Science

介绍
作为一名数据科学家,文本数据提出了一个独特的挑战:虽然金融、年龄和温度数据可以立即被注入线性回归,但词汇和语言本身对统计模型毫无意义。
怎样才能有人对一系列随机的、毫无意义的字母进行建模或分析?广义上,这类工作属于自然语言处理(NLP)的范畴,这项研究跨越了各种领域——计算机科学、语言学、人工智能,当然还有数据科学。
然而,对于模型来说,重要的是模式,特别是文本数据语料库中的词汇排列。主题模型的统计方法是利用机器学习识别文本数据语料库中的词之间的关系。然后它基于“主题”来描述语料库,主题是模型推断出的属于一个主题的单词组。
在本文中,我将解释如何使用一种名为潜Dirichlet分配(LDA)的主题模型方法来识别这些关系。然后,我将在我从DergoInnovations索引数据库中提取的一些专利数据实现此方法,我通过Claremont学院图书馆(Claremont Colleges Library)访问了该数据库。最后,我将对模型的结果执行并可视化趋势分析。这个演示将使用Python实现,并且将依赖Gensim、pandas和自然语言工具包。
了解使用LDA的主题模型,你将能够对各种文本数据进行建模——推特、研究或专利摘要、报纸或任何其他文本数据语料库。
基于潜Dirichlet分配的主题模型
主题模型如何工作?它使用一种机器学习方法,称为“潜Dirichlet分配”。尽管这种方法听起来很吓人,但它的标题实际上很好地描述了它:
潜:这意味着隐藏或未被发现。我们假设主题在语料库中隐式地存在,我们只是去发现它们。
Dirichlet:你可以从统计中认识这个术语,特别是Dirichlet。Dirichlet是有限事件数的概率分布
其中

每个事件E都有自己的概率P,这些概率,一如既往地,总和为1。
分配:在主题模型中,我们为多种目的分配狄利克雷分布。我们为语料库中主题的分布分配了一个。此外,我们分配到每个主题,每个代表该主题中单词的分布。在前一种分布中,事件是主题;在后者中,事件是主题中的单词。
既然你对LDA有了一个想法,我们可以讨论它的实现。对于Gensim的LDAMulticore方法,我们指定了我们想要发现的主题的数量。
每个主题的Dirichlet概率分布是随机初始化的,并且在模型通过语料库时调整每个分布中单词的概率。
为了对LDA进行一个非常奇妙、更长的解释,我推荐ThushanGanegedara的直观教程。它与本文的水平差不多,但将进一步深入到数学细节:https://towardsdatascience.com/light-on-math-machine-learning-intuitive-guide-to-latent-dirichlet-allocation-437c81220158
专利数据主题模型的实现
让我们看看一个在真实数据集上的主题模型的实现。在这个案例中,我想分析成千上万的专利摘要,涉及一个新兴技术:人脸识别。
自1990年以来,我从世界各地提取了近3500份专利摘要。然而,一项快速的探索性数据分析显示,超过65%的摘要发生在2016年至2020年,这是有意义的,基于近年来面部识别应用程序的激增。EDA还显示,近80%的摘要来自美国和中国,两者之间几乎是均匀的。代码和数据在本文末尾链接。
提取数据
为了实现,我对技术专利的摘要进行了建模。我从DergoInnovations索引数据库中提取了这些数据,特别是搜索术语“facial recognition”。
除了专利申请日期和专利的来源国外,我对构成文本语料库的摘要感兴趣。日期和国家并不用于主题建模过程,而是用于我对主题模型结果进行的趋势分析。
一旦我们有了数据,我们就要导入我们的包。
import pandas as pd
import seaborn as sns # 用于可视化我们的主题
from gensim.corpora import Dictionary # 我们语料库中的单词
from gensim.models import TfidfModel, LdaMulticore # 我们的模型
from gensim.utils import simple_preprocess # 快速预处理包
from gensim.parsing.preprocessing import STOPWORDS # 停用词库
from nltk.stem import WordNetLemmatizer, SnowballStemmer, LancasterStemmer # 词干和词形还原
import matplotlib.pyplot as plt # 数据可视化
from nltk.corpus import wordnet
import numpy as np
np.random.seed(2018)
import nltk
from datetime import datetime
import csv
# 下载字典
nltk.download('wordnet')
nltk.download('averaged_perceptron_tagger')
数据的清理和预处理
一如既往,第一步是清理数据集。首先,因为原始数据集中没有“国家”列,所以我解析了专利号,它以国家代码开始。接下来,我删除了缺少数据的文档。
stemmer1 = SnowballStemmer('english') # 用于语料的词干提取。
stemmer2 = LancasterStemmer() # 比Snowball更好
def preprocess(self, text):
'''
建模数据的预处理。
标识化,删除停用词和短词,删除标点符号,
使所有东西都小写,词干,并删除相关的词
'''
result = []
for token in simple_preprocess(text):
if token not in STOPWORDS and len(token) > 3:
stemmed2 = stemmer2.stem(token)
if stemmed2 not in self.cleaned_terms: # 我们不关心我们的搜索条件
stemmed1 = stemmer1.stem(token)
result.append(stemmed1)
return result
processed_docs = self.clean_documents['abstract'].map(self.preprocess)
与所有文本相关的数据分析一样,第二步是预处理。
对于文本预处理的全面介绍,我推荐我的教程。
https://towardsdatascience.com/preprocessing-text-data-in-python-an-introduction-via-kaggle-7d28ad9c9eb
为了总结这个过程,我们从一个由文本字符串组成的数据集开始,其中充满了标点符号和数字。我们希望对这些数据进行预处理,以便语料库中的每个文档都是文档的基本部分列表—词干化、词形还原、小写化、有用的单词。这一过程可概括为五个步骤:
我们去掉标点和数字。我们把所有的字都改成小写。
我们将每个文档从一个字符串分解为一个单词列表。列表中的每一项都称为“标识”。
我们过滤掉停用词(介词、冠词等)。我们过滤掉短词。
我们将单词缩减为词根(例如,“runner”和“running”都变成“run”)——这个过程称为词干分析。我们对动词也这么做,这个过程叫做词形还原。
我们过滤掉原来的数据库搜索词(在我的例子中是“facial”和“recognition”)。
现在,语料库中的每个文档都是一组小写的词干标识。
词袋
# 索引语料库中的单词
dictionary = Dictionary(processed_docs)
# 删除极其罕见(少于15个文档)和常见(超过40%的语料库)的单词。
# 只保留前n个最常用的单词。
dictionary.filter_extremes(no_below=15, no_above=0.4, keep_n=100000)
# 转换文件到词袋(bow)
# bow由每个文档的标识id和它们的频率计数组成。
bow_corpus = [dictionary.doc2bow(doc) for doc in processed_docs]
在对文本数据建模时,从某种意义上讲,开始使用数字而不是单词是有利的。
第一步是编译一个字典,包含出现在整个语料库中的每个惟一标识,并为每个惟一标识建立索引——这是使用Gensim的dictionary模块完成的。
我们也过滤掉非常常见的或极为罕见的单词。然后,我们保留剩余的10万个最频繁的标识。使用这个字典,将每个文档从一个标识列表转换为出现在文档中的唯一标识列表及其在文档中的频率。这种语料库的表示称为词袋。
词频逆文档频率(tf-idf)
# tf-idf是一个单词重要性的度量,就像频率计数可以被认为是一个重要度量一样。
# 然而,tf-idf认为出现在高百分比文档中的单词不那么重要,
# 但是如果它们经常出现在一个文档中,它们就更重要了。
tfidf = TfidfModel(bow_corpus)
corpus_tfidf = tfidf[bow_corpus]
在编译我们的模型之前的最后一步是调整词袋的频率度量。虽然频率当然是衡量一个特定单词在文本语料库中的重要性的一个指标,但我们假设出现在更多文档中的单词就不那么重要了。
例如,如果我们没有过滤掉“facial”和“recognition”这两个词,它们可能会出现在我们语料库的文档中。尽管它们对语料库显然很重要,但对于我们最感兴趣的语料库中的变化和模式,它们提供了很少的见解。
基于这个原因,我们使用了一种称为“词频-逆文档频率”(tf-idf)的度量方法,而不是简单地使用词频作为我们对每个单词的重要性度量。
tf-idf对基本词频的唯一修改是,当一个单词出现在文档中时,它在文档中的频率除以它出现在整个语料库中的文档数。这使得出现在数千个文档中的单词不如出现在几百个文档中的单词重要。
基于潜在Dirichlet分配的主题模型
我们现在的目标是研究单词在tf-idf单词包语料库中是如何相互关联出现的,以辨别“主题”,这是模型认为的简单的单词组。
我前面解释过,这些主题潜在地存在于语料库中——在本例中,我们假设(并希望)我们发现的主题反映了面部识别领域中一些小的技术领域。
# 我们的LDA模型使用Gensim。
self.lda_model = LdaMulticore(corpus_tfidf, num_topics=num_topics, id2word=dictionary, passes=50, workers=2)
我们使用Gensim的LDAMulticore模型将tf-idf语料库放入LDA主题模型中。
例如,该模型从面部识别数据中识别出“authent、data、inform、biometr、mobil、content、person、comput、video、access”(这些词看起来被切断了,因为它们是词干化和词形还原的版本)。本主题似乎与使用面部识别的生物特征认证有关。
基于主题的语料库趋势分析
我们使用Gensim的LDAMulticore模型成功地创建了一个主题模型。现在让我们来了解一下基于这个模型的语料库。
通过确定每个主题随时间出现在多少文档中,我们可以根据其在专利中的流行程度对每个主题进行排序,并跟踪这种流行程度随时间的变化。
这可以让我们知道在过去的二十年中,人脸识别技术的哪些领域(基于每个主题中的单词)得到了发展。利用seaborn的catplot,我们可以将这项技术的发展可视化。

2009年至2018年最受欢迎的主题(蓝色)似乎与生物特征认证有关。这还不完全清楚,所以我们可以对这个主题中最为重要的五个专利摘要进行抽样,以便更好地了解这个主题涉及的技术类型。

这一专利摘要似乎如预期的那样涉及到为了身份验证目的而进行的面部识别,也涉及识别——可能涉及罪犯或受害受害者。
然而,2003年至2009年,另一个主题(橙色)似乎与摄影中的面部检测有关,颇受欢迎。2017年以来,一个不同的主题(绿色)迅速崛起。从文字上看还不完全清楚,但看一下这个主题的专利,就可以看出,它与安装的具有面部识别能力的安全摄像头有关。
比较国家
让我们再做一个分析:2009年美国和中国的比较。

美国的面部识别专利显然已严重关注生物特征认证,其次是摄影。尽管最近安全摄像头和家庭安全系统都有上升趋势,但这些年来,所有主题基本保持稳定。
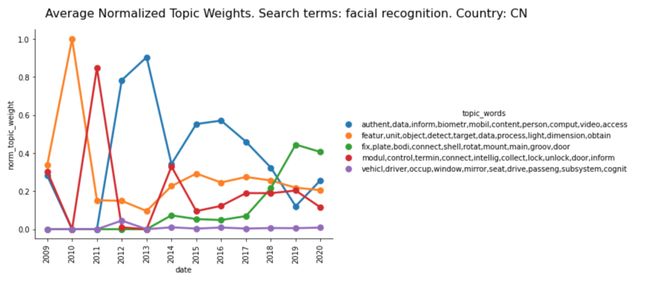
另一方面,自2009年以来,中国的面部识别专利一直非常不稳定。虽然生物识别认证是最重要的,但也有一些挑战,包括家庭安全系统,摄影,以及最近的安全摄像头。
通过对美国和中国面部识别专利的对比分析,可以得出有趣的结论,说明这两个国家的技术发展是如何不同的,以及为什么。
结论
主题模型是一种用于大量文本数据的NLP方法。潜Dirichlet分配是一种强大但可解释的机器学习方法。
LDA的简洁和优雅对数据科学家来说是一个福音,他们经常要向同事和高管解释他们的方法。LDA提供了简单与力量的完美融合。
虽然我用专利数据演示了一个实现,但同样的方法也可以应用于其他文本数据集,从研究论文摘要到报纸文章或再到推特。
代码
我使用该代码将数据文件合并到一个数据集中:https://github.com/stgran/personal/blob/master/lda_topic_modeling/jupyter_notebook/web_of_science_data.ipynb
我用于预处理、建模和趋势分析的完整Jupyter笔记本位于此处:https://github.com/stgran/personal/blob/master/lda_topic_modeling/jupyter_notebook/lda_topic_modeling.ipynb
包含所有代码文件、我的数据和Readme.md在这里:https://github.com/stgran/personal/tree/master/lda_topic_modeling


往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑温州大学《机器学习课程》视频
本站qq群851320808,加入微信群请扫码: