【mmdetection】
mmdetection使用文档
- 1. 安装[^1]
-
- 1.1 准备环境
- 1.2 安装MMDetection
- 1.3 安装验证
- 2. 整体构建流程(一)[^2]
-
- 2.1 摘要
- 2.2 目标检测算法抽象流程
- 2.3 MMDetection整体构建流程和思想
-
- 2.3.1 训练核心组件
-
- 2.3.1.1Backbone
- 2.3.1.2 Neck
- 2.3.1.3 Head
- 2.3.1.4 Enhance
- 2.3.1.5 BBox Assigner
- 2.3.1.6 BBox Sampler
- 2.3.1.7 BBox Encoder
- 2.3.1.8 Loss
- 2.3.1.9 Training Tricks
- 2.3.2 测试核心组件
-
- 2.3.2.1 BBox Decoder
- 2.3.2.2BBox Postprocess
- 2.3.2.3Testing Tricks
- 2.3.3 训练测试算法流程
-
- 2.3.3.1 bbox_head.forward_train
- 2.3.3.2 bbox_head.get_bboxes
- 2.4 总结
- 3. 整体构建流程(二)[^3]
-
- 3.1 摘要
- 3.2 第一层整体抽象
- 3.3 第二层模块抽象
-
- 3.3.1 Pipeline
- 3.3.2 DataParalell和Model
- 3.3.3 Runner和Hooks
- 3.4 第三层代码抽象
-
- 3.4.1 训练和测试整体代码抽象流程
- 3.4.2 Runner训练和验证代码抽象
- 3.4.3 Model训练和测试代码抽象
-
- 3.4.3.1 train 或者 val 流程
- 3.4.3.2 test流程
- 3.5 总结
1. 安装[^1]
1.1 准备环境
-
创建一个conda虚拟环境并激活它。
conda create -n openmmlab python=3.7 -y conda activate openmmlab -
安装PyTorch和torchvision。
conda install pytorch torchvision -c pytorch
1.2 安装MMDetection
pip install openmim
mim install mmdet
1.3 安装验证
from mmdet.apis import init_detector, inference_detector
config_file = 'configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py'
# download the checkpoint from model zoo and put it in `checkpoints/`
# url: https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth
checkpoint_file = 'checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth'
device = 'cuda:0'
# init a detector
model = init_detector(config_file, checkpoint_file, device=device)
# inference the demo image
inference_detector(model, 'demo/demo.jpg')
2. 整体构建流程(一)[^2]
2.1 摘要
本章讲解主要内容:
- MMDetection整体构建流程和思想
- 目标检测算法核心组件划分
- 目标检测核心组件功能
2.2 目标检测算法抽象流程
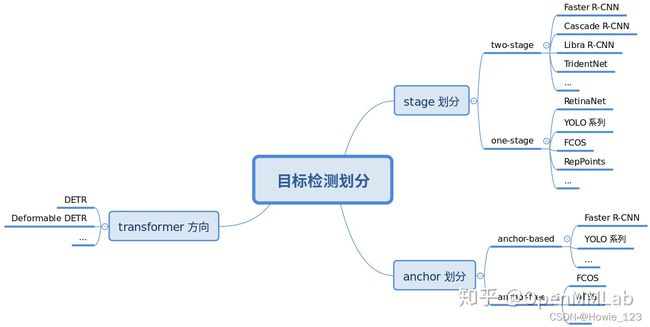
简单来说目标检测算法可以按照3个维度划分:
- 按照stage个数划分,常规是one-stage和two-stage,但实际界限不是特别清晰,例如带refine阶段的RepPoints,实际可以认为是1.5 stage算法,而Cascade R-CNN 可以认为是多阶段算法。
- 按照是否需要预定义anchor划分,常规是anchor-based和anchor-free,当然也有些算法是两者混合的。
- 按照是否采用了transformer划分,目前基于transformer结构的目标检测算法发展迅速,也引起了极大的关注,所以这里特意增加了这个分类。
不管哪种划分方式,其实都可以分成若干模块, 然后通过模块堆叠来构建整个检测算法体系。
2.3 MMDetection整体构建流程和思想
基于目前代码实现,所有目标检测算法都按照以下流程进行划分:
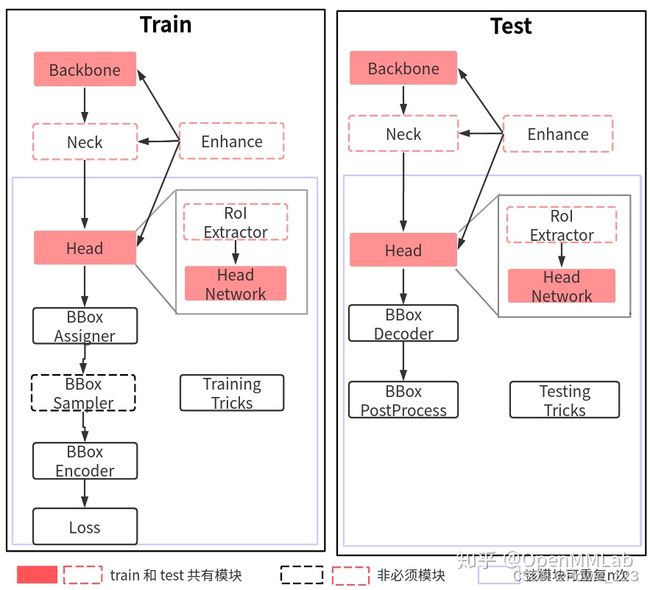
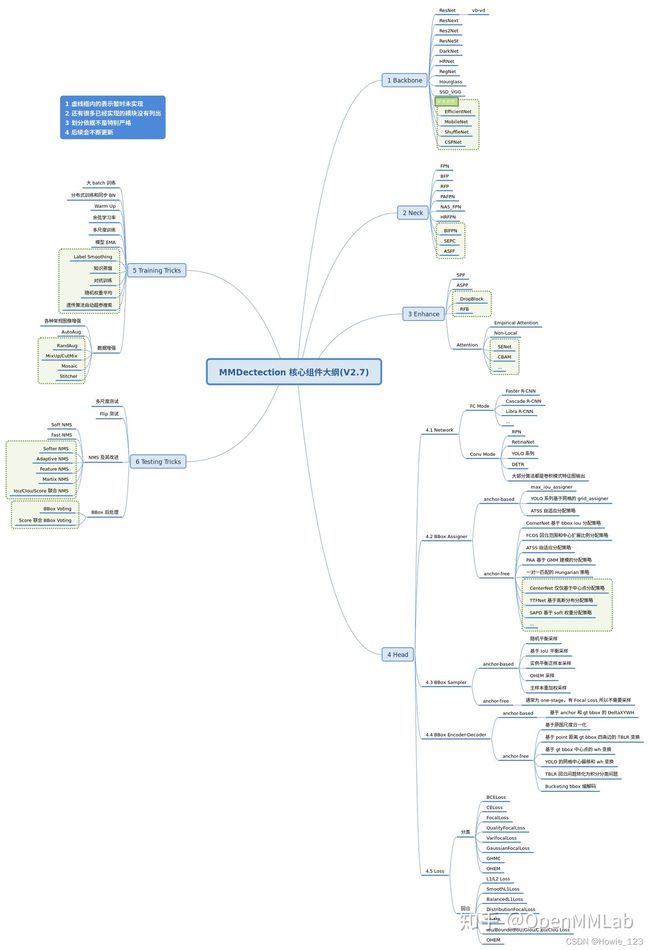
上述流程对应MMDetection代码构建流程,理解每个组件的作用不仅仅对阅读算法源码有帮助,而且还能快速理解新提出算法对应的改进部分。下面对每个模块进行详细解读。
2.3.1 训练核心组件
训练部分一般包括9个核心组件,总体流程是:
- 任何一个batch的图片先输入到backbone中进行特征提取,典型的骨干网络是ResNet。
- 输出的单尺度或多尺度特征图输入到neck模块中进行特征融合或增强,典型的neck是FPN。
- 上述多尺度特征最终输入到head部分,一般都会包括分类和回归分支输出。
- 在整个网络构建阶段都可以引入一些即插即用的增强算子来增加提取特征的能力,典型如SPP、DCN等等。
- 目标检测head输出一般是特征图,对于分类任务存在严重的正负样本不平衡,可以通过正负样本属性分配和采样控制。
- 为了方便收敛和平衡多分支,一般都会对gt bbox进行编码。
- 最后一步是计算分类和回归loss,进行训练。
- 在训练过程中也包括非常多的trick,例如优化器选择、参数调节等内容。
注意上述9个组件不是每个算法都需要的下面详细分析。
2.3.1.1Backbone
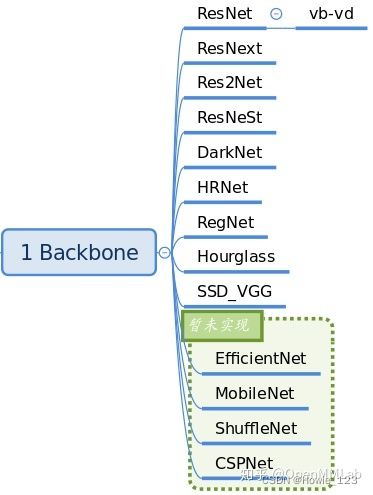
Backbone的作用主要是特征提取。目前MMDetection已经集成了大部分骨架网络,具体见文件:mmdet/models/backbones,已经实现的骨架如下:
__all__ = [
'RegNet', 'ResNet', 'ResNetV1d', 'ResNeXt', 'SSDVGG', 'HRNet',
'MobileNetV2', 'Res2Net', 'HourglassNet', 'DetectoRS_ResNet',
'DetectoRS_ResNeXt', 'Darknet', 'ResNeSt', 'TridentResNet', 'CSPDarknet'
]
如果你需要对骨架进行扩展,可以继承上述网络,然后通过注册器机制注册使用。一个典型的用法为:
# 骨架的预训练权重路径
pretrained='torchvision://resnet50',
backbone=dict(
type='ResNet', # 骨架类名,后面的参数都是该类的初始化参数
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch'),
通过MMCV中的注册器机制,你可以通过dict的形式来配置实例化任何已经注册的类,非常方便和灵活。
2.3.1.2 Neck

neck可以认为是backbone和head的连接层,主要负责对backbone的特征进行高校融合和增强,能够对输入的单尺度或者多尺度特征进行融合、增强输出等。具体见文件:mmdet/models/necks,已经实现的neck如下:
__all__ = [
'FPN', 'BFP', 'ChannelMapper', 'HRFPN', 'NASFPN', 'FPN_CARAFE', 'PAFPN',
'NASFCOS_FPN', 'RFP', 'YOLOV3Neck', 'FPG', 'DilatedEncoder',
'CTResNetNeck', 'SSDNeck', 'YOLOXPAFPN'
]
最常用的FPN的一个典型用法是:
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048], # 骨架多尺度特征图输出通道
out_channels=256, # 增强后通道输出
num_outs=5), # 输出num_outs个多尺度特征图
2.3.1.3 Head
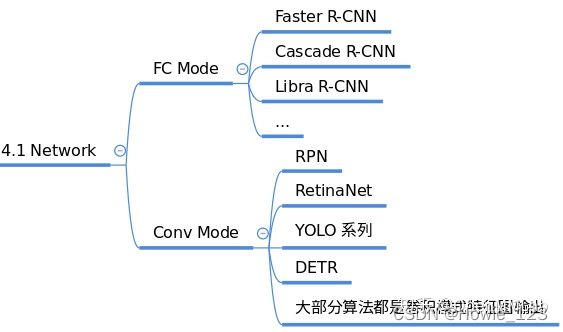
目标检测算法输出一般包括分类和框坐标回归两个分支,不同算法Head模块的复杂程度不同,灵活度比较高。在网络构建方面,理解目标检测算法主要是理解Head模块。
MMDetection中Head模块又划分为two-stage所需的RoIHead和one-stage所需的DenseHead,也就是说所有的one-stage算法的head模块都在mmdet/models/dense_heads中,而two-stage算法还包括额外的mmdet/models/roi_heads。
目前已经实现的dense_heads包括:
__all__ = [
'AnchorFreeHead', 'AnchorHead', 'GuidedAnchorHead', 'FeatureAdaption',
'RPNHead', 'GARPNHead', 'RetinaHead', 'RetinaSepBNHead', 'GARetinaHead',
'SSDHead', 'FCOSHead', 'RepPointsHead', 'FoveaHead',
'FreeAnchorRetinaHead', 'ATSSHead', 'FSAFHead', 'NASFCOSHead',
'PISARetinaHead', 'PISASSDHead', 'GFLHead', 'CornerHead', 'YOLACTHead',
'YOLACTSegmHead', 'YOLACTProtonet', 'YOLOV3Head', 'PAAHead',
'SABLRetinaHead', 'CentripetalHead', 'VFNetHead', 'StageCascadeRPNHead',
'CascadeRPNHead', 'EmbeddingRPNHead', 'LDHead', 'CascadeRPNHead',
'AutoAssignHead', 'DETRHead', 'YOLOFHead', 'DeformableDETRHead',
'CenterNetHead', 'YOLOXHead'
]
几乎每个算法都包含一个独立的Head,而roi_heads比较杂,就不列出了。
需要注意的是:two-stage或者multi-stage算法,会额外包括一个区域提取器roi extractor,用于将不同大小的RoI特征图统一成相同大小。
虽然head部分的网络构建比较简单,但是由于正负样本属性定义、正负样本采样和bbox编解码都在head模块中进行组合调用,故MMDetection中最复杂的模块就是head。在最后的整体流程部分会对该模块进行详细分析。
2.3.1.4 Enhance
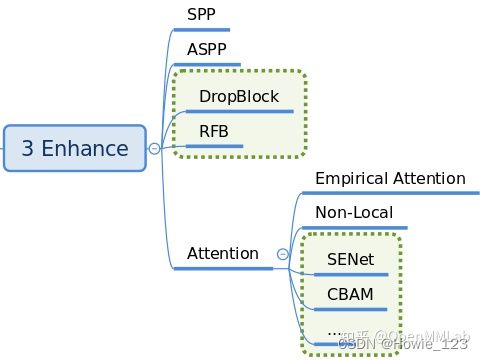
enchance是即插即用、能够对特征图进行增强的模块,其具体代码可以通过dict形式注册到backbone、neck和head中,非常方便。常用的enhance模块是SPP、ASPP、Dropblock、DCN和各种注意力模块SeNet、Non_Local、CBA等。目前MMDetection中部分模块支持Enhance的接入,例如ResNet骨架中的plugins,这个部分的解读放在具体算法中讲解。
2.3.1.5 BBox Assigner
正负样本属性分配模块的作用是进行正负样本定义或者正负样本分配(也可能包括忽略样本定义),正样本就是常说的前景样本(可以是任意类别),负样本就是背景样本。因为目标检测是一个同时进行分类和回归的问题,对于分类场景必然需要确定正负样本,否则无法训练。该模块至关重要,不同的正负样本分配策略会带来显著的性能差异,目前大部分目标检测算法都会对这个部分进行改进。一些典型的分配策略如下:

对应的代码在mmdet/core/bbox/assigners中,主要包括:
__all__ = [
'BaseAssigner', 'MaxIoUAssigner', 'ApproxMaxIoUAssigner', 'AssignResult',
'PointAssigner', 'ATSSAssigner', 'CenterRegionAssigner', 'GridAssigner',
'HungarianAssigner', 'RegionAssigner', 'UniformAssigner', 'SimOTAAssigner'
]
2.3.1.6 BBox Sampler
在确定每个样本的正负属性后,可能还需要进行样本采样平衡操作。本模块作用是对前面定义的正负样本不平衡进行采样,力争克服该问题。一般在目标检测中gt bbox都是非常少的,所以正负样本比是远远小于1的。而基于机器学习的观点:在数据极度不平衡情况下进行分类会出现预测倾向于样本多的类别,出现过拟合,为了克服该问题,适当的正负样本采样策略是非常必要的,一些典型采样策略如下:
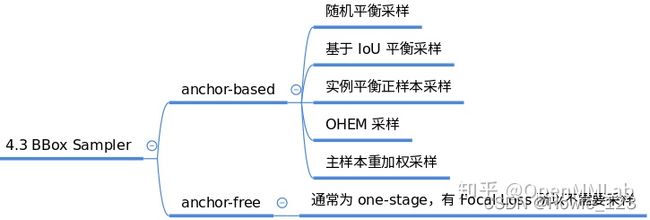
对应的代码在mmdet/core/bbox/samplers中,主要包括:
__all__ = [
'BaseSampler', 'PseudoSampler', 'RandomSampler',
'InstanceBalancedPosSampler', 'IoUBalancedNegSampler', 'CombinedSampler',
'OHEMSampler', 'SamplingResult', 'ScoreHLRSampler'
]
2.3.1.7 BBox Encoder
为了更好的收敛和平衡多个loss,具体解决办法非常多,而bbox编解码策略也算其中一个,bbox编码阶段对应的是对正样本的gt bbox采用某种编码变换(反操作就是bbox解码),最简单的编码是对gt bbox除以图片宽高进行归一化以平衡分类和回归分支,一些典型的编解码策略如下:

对应的代码在mmdet/core/bbox/coder中,主要包括:
__all__ = [
'BaseBBoxCoder', 'PseudoBBoxCoder', 'DeltaXYWHBBoxCoder',
'LegacyDeltaXYWHBBoxCoder', 'TBLRBBoxCoder', 'YOLOBBoxCoder',
'BucketingBBoxCoder'
]
2.3.1.8 Loss
Loss通常都分为分类和回归loss,其对为网络head输出的预测值和bbox encoder得到的targets进行梯度下降迭代训练。
loss的设计也是各大算法重点改进的对象,常用的loss如下:

对应的代码在mmdet/models/losses中,主要包括:
__all__ = [
'accuracy', 'Accuracy', 'cross_entropy', 'binary_cross_entropy',
'mask_cross_entropy', 'CrossEntropyLoss', 'sigmoid_focal_loss',
'FocalLoss', 'smooth_l1_loss', 'SmoothL1Loss', 'balanced_l1_loss',
'BalancedL1Loss', 'mse_loss', 'MSELoss', 'iou_loss', 'bounded_iou_loss',
'IoULoss', 'BoundedIoULoss', 'GIoULoss', 'DIoULoss', 'CIoULoss', 'GHMC',
'GHMR', 'reduce_loss', 'weight_reduce_loss', 'weighted_loss', 'L1Loss',
'l1_loss', 'isr_p', 'carl_loss', 'AssociativeEmbeddingLoss',
'GaussianFocalLoss', 'QualityFocalLoss', 'DistributionFocalLoss',
'VarifocalLoss', 'KnowledgeDistillationKLDivLoss', 'SeesawLoss'
]
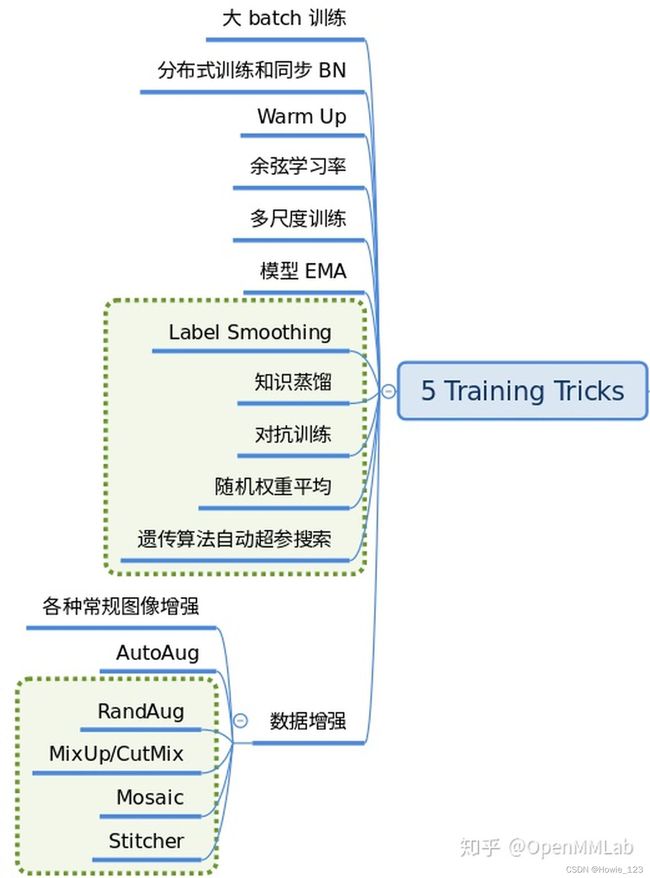
2.3.1.9 Training Tricks
训练技巧非常多,常说的调参很大一部分工作都是在设置这部分超参。这部分内容比较杂乱,很难做到完全统一,目前主流的tricks如下所示:
2.3.2 测试核心组件
测试核心组件和训练非常类似,但是简单很多,除了必备的网络构建部分外(backbone、neck、head和enchance),不需要正负样本定义、正负样本采样和loss计算三个最难的部分,但是其额外需要一个bbox后处理模块和测试trick。
2.3.2.1 BBox Decoder
训练时候进行了编码,那么测试的时候就需要进行解码。根据编码的不同,解码也是不同的。举个简单的例子:假设训练的时候对bbox的宽高直接除以图片的宽高进行归一化,那么解码过程就需要乘以图片的宽高回复bbox的实际尺度。其代码和bbox encoder放在一起,在mmdet/core/bbox/coder中。
2.3.2.2BBox Postprocess
在得到原图尺度bbox后,由于可能会出现重叠bbox现象,故一般都需要进行后处理,最常用的后处理就是非极大值抑制以及其变种。
其对应的文件在mmdet/core/post_processing中,主要包括:
__all__ = [
'multiclass_nms', 'merge_aug_proposals', 'merge_aug_bboxes',
'merge_aug_scores', 'merge_aug_masks', 'fast_nms'
]
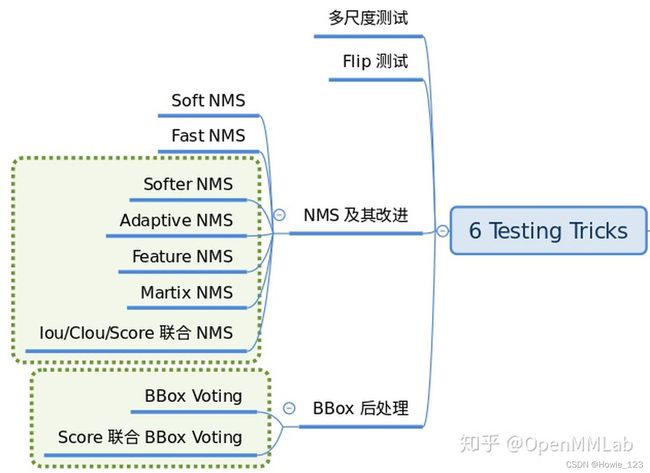
2.3.2.3Testing Tricks
为了提高检测性能,测试阶段也会采用trick。这个阶段的tricks也非常多,难以完全统一,最典型的是多尺度测试以及各种模型集成手段,典型配置如下:
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=True,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
2.3.3 训练测试算法流程
在分析完每个训练流程的各个核心组件后,为了方便大家理解整个算法构建,下面分析MMDetection是如何组合各个组件进行训练的,这里以one-stage检测器为例,two-stage也比较类似。
class SingleStageDetector(---):
def __init__(...):
# 构建骨架、neck和head
self.backbone = build_backbone(backbone)
if neck is not None:
self.neck = build_neck(neck)
self.bbox_head = build_head(bbox_head)
def forward_train(---):
# 先运行backbone+neck进行特征提取
x = self.extract_feat(img)
# 对head进行forward train,输出loss
losses = self.bbox_head.forward_train(x, img_metas, gt_bboxes,
gt_labels, gt_bboxes_ignore)
return losses
def simple_test(---):
# 先运行backbone+neck进行特征提取
x = self.extract_feat(img)
# head输出预测特征图
outs = self.bbox_head(x)
# bbox解码和还原
bbox_list = self.bbox_head.get_bboxes(
*outs, img_metas, rescale=rescale)
# 重组结果返回
bbox_results = [
bbox2result(det_bboxes, det_labels, self.bbox_head.num_classes)
for det_bboxes, det_labels in bbox_list
]
return bbox_results
以上就是整个检测器算法训练和测试最简逻辑,可以发现训练部分最核心的就是bbox_head.forward_train,测试部分最核心的是bbox_head.get_bboxes,下面单独简要分析。
2.3.3.1 bbox_head.forward_train
forward_train是通用函数,如下所示:
def forward_train(...):
# 调用每个head自身的forward方法
outs = self(x)
if gt_labels is None:
loss_inputs = outs + (gt_bboxes, img_metas)
else:
loss_inputs = outs + (gt_bboxes, gt_labels, img_metas)
# 计算每个head自身的loss方法
losses = self.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
# 返回
return losses
对于不同的head,虽然forward的内容不同,但依然可以抽象为outs = self(x)
def forward(self, feats):
# 多尺度特征图,一个一个迭代进行forward_single
return multi_apply(self.forward_single, feats)
def forward_single(self, x):
# 运行各个head独特的head forward方法,得到预测图
....
return cls_score, bbox_pred...
而对于不同的head,其loss计算部分也比较复杂,可以简单抽象为:losses = self.loss(…)
def loss(...):
# 1 生成anchor-base需要的anchor或者anchor-free需要的points
# 2 利用gt bbox对特征图或者anchor计算其正负和忽略样本属性
# 3 进行正负样本采样
# 4 对gt bbox进行bbox编码
# 5 loss计算,并返回
return dict(loss_cls=losses_cls, loss_bbox=losses_bbox,...)
2.3.3.2 bbox_head.get_bboxes
def get_bboxes(...):
# 1 生成anchor-base需要的anchor或者anchor-free需要的points
# 2 遍历每个输出层,遍历batch内部的每张图片,对每张图片先提取指定个数的预测结果,缓解后面后处理压力;对保留的位置进行bbox解码和还原到原图尺度
# 3 统一nms后处理
return det_bboxes, det_labels...
2.4 总结
本章重点分析了一个目标检测器是如何通过多个核心组件堆叠而成,不涉及具体代码,大家只需总体把握即可,其中最应该了解的是:任何一个目标检测算法都可以分成n个核心组件,组件和组件之间是隔离的,方便复用和设计。 当面对一个新算法时候我们可以先分析其主要改进了哪几个组件,然后就可以高效的掌握该算法。
另外还有一些重要的模块没有分析,特别是dataset、dataloader和分布式训练相关的检测代码。最后附上总图:
3. 整体构建流程(二)[^3]
3.1 摘要
本章核心内容是按照抽象到具体方式,从多个层次进行训练和测试流程深入分析,从最抽象层讲起,到最后核心代码实现,希望帮助大家更容易理解MMDetection开源框架整体构建细节。
3.2 第一层整体抽象
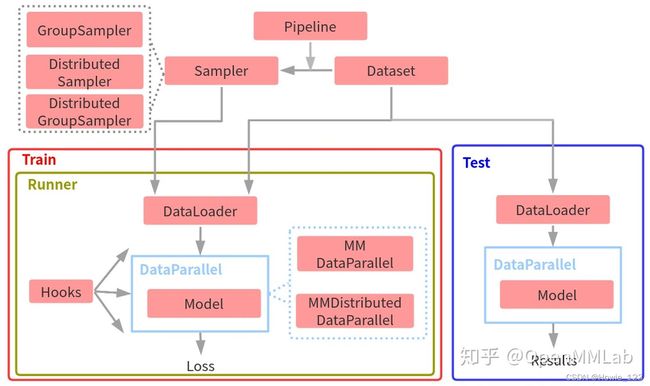
上图为MMDetection框架整体训练和测试抽象流程图。按照数据流过程,训练流程可以简单总结为:
- 给定任何一个数据集,首先需要构建DataSet类,用于迭代输出数据。
- 在迭代输出数据的时候需要通过数据pipeline对数据进行各种处理,最典型的处理流是训练中的数据增强操作,测试中的数据预处理等等。
- 通过Sampler采样器可以Dataset输出的数据顺序,最常用的是随机采样器RandomSampler。由于Dataset中输出的图片大小不一样,为了尽可能减少后续组成batch时pad的像素个数,MMDetection引入了分组采样器GroupSampler和DistributedGroupSampler,相当于在RandomSampler基础上额外新增了根据图像宽高比进行group的功能。
- 将Sampler和Dataset都输入给DataLoader,然后通过DataLoader输出已组成batch的数据,作为Model的输入。
- 对于任何一个Model,为了方便处理数据流以及分布式需求,MMDetection引入了两个Model的上层封装:单机版本MMDataParallel、分布式(单机多卡或多机多卡)版本MMDistibutedDataParallel。
- Model运行后会输出Loss以及其他一些信息,会通过logger进行保存或者可视化。
- 为了更好地解耦,方便地获取各个组件之间依赖和灵活扩展,MMDetection引入了Runner类进行生命周期管理,并通过Hook方便地获取、修改和拦截任何生命周期数据流,扩展非常便捷。
而测试流程就比较简单了,直接对DataLoader输出的数据进行前向推理即可,还原到最终原图尺度过程也是在Model中完成。
以上就是MMDetection框架整体训练流程,上图不仅仅反映了训练和测试数据流,而且还包括了模块和模块之间的调用关系。对于训练而言,最核心的部分应该是Runner,理解了Runner的运行流程,也就理解了整个MMDtection数据流。
3.3 第二层模块抽象
在总体把握了整个MMDetection框架训练和测试流程后,下个层次是每个模块内部抽象流程,主要包括Pipeline、DataParalell、Model、Runner和Hooks。
3.3.1 Pipeline
Pipeline实际上由一系列按照插入顺序运行的数据处理模块组成,每个模块完成某个特定功能,例如Resize,因为其流式顺序运行的特性,故叫做Pipeline。
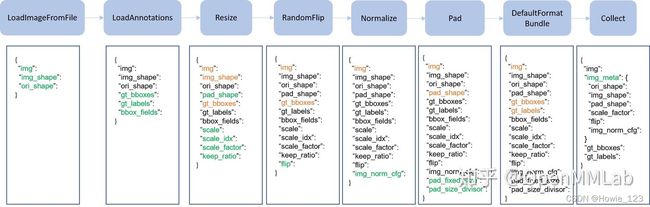
上图是一个非常典型的训练流程Pipeline,每个类都接收字典输入,输出也是字典,顺序执行,其中绿色表示该类运行后新增字段,橙色表示可能会进行修改。如果进一步细分的话,不同算法的pipeline都可以划分为如下四部分:
- 图片和标签加载,LoadImageFromFile和LoadAnnotations
- 数据前处理,例如统一Resiuze
- 数据增强,如各种图片几何变换,这部分是训练流程特有,测试阶段一般不采用(多尺度测试采用其他实现方式)
- 数据收集,例如Collect
在MMDetection框架中图片和标签加载和数据后处理流程一般是固定的,用户主要可能修改的是数据增强步骤,目前已经接入了第三方增强库Albumentations,可以按照示例轻松构建属于你自己的数据增强Pipeline。
在构建自己的Pipeline时一定要仔细检查修改或新增的字典key和value,因为一旦错误地覆盖或修改原先字典的内容,代码可能不会报错,如果出现bug则很难排查。
3.3.2 DataParalell和Model
在MMDetection中DataLoader输出的内容不是PyTorch能处理的标准格式,还包括了DataContainer对象,该对象的作用是包装不同类型的对象使之能按需组成batch。在目标检测中,每张图片 gt bbox 个数是不一样的,如果想组成 batch tensor,要么你设置最大长度,要么你自己想办法组成 batch。而考虑到内存和效率,MMDetection 通过引入 DataContainer 模块来解决上述问题,但是随之带来的问题是 pytorch 无法解析 DataContainer 对象,故需要在 MMDetection 中自行处理。
解决办法其实非常多,MMDetection 选择了一种比较优雅的实现方式:MMDataParallel 和 MMDistributedDataParallel。具体来说,这两个类相比 PyTorch 自带的 DataParallel 和 DistributedDataParallel 区别是:
- 可以处理 DataContainer 对象
- 额外实现了 train_step() 和 val_step() 两个函数,可以被 Runner 调用
关于这两个类的具体实现后面会描述。
而 Model 部分内容就是第一篇解读文章所讲的,具体如下:
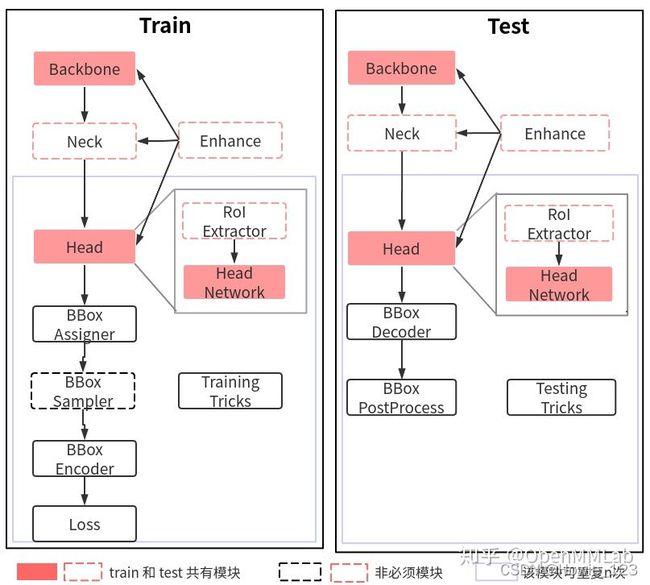
3.3.3 Runner和Hooks
对于任何一个目标检测算法,都需要包括优化器、学习率设置、权重保存等等组件才能构成完整训练流程,而这些组件是通用的。为了方便 OpenMMLab 体系下的所有框架复用,在 MMCV 框架中引入了 Runner 类来统一管理训练和验证流程,并且通过 Hooks 机制以一种非常灵活、解耦的方式来实现丰富扩展功能。
关于 Runner 和 Hooks 详细解读会发布在 MMCV 系列解读文章中,简单来说 Runner 封装了 OpenMMLab 体系下各个框架的训练和验证详细流程,其负责管理训练和验证过程中的整个生命周期,通过预定义回调函数,用户可以插入定制化 Hook ,从而实现各种各样的需求。下面列出了在 MMDetection 几个非常重要的 hook 以及其作用的生命周期:
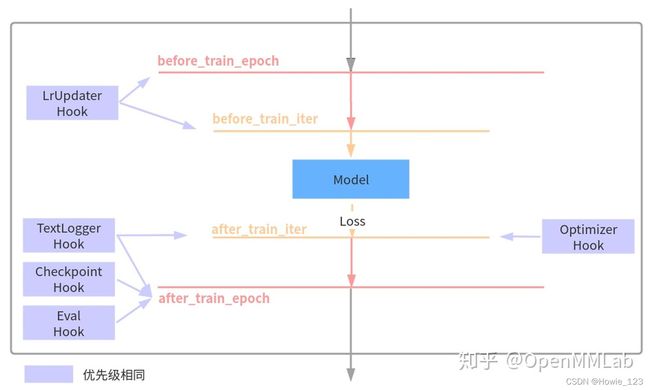
例如 CheckpointHook 在每个训练 epoch 完成后会被调用,从而实现保存权重功能。用户也可以将自己定制实现的 Hook 采用上述方式绘制,对理解整个流程或许有帮助。
3.4 第三层代码抽象
前面两层抽象分析流程,基本上把整个 MMDetection 的训练和测试流程分析完了,下面从具体代码层面进行抽象分析。
3.4.1 训练和测试整体代码抽象流程

上图为训练和验证的和具体代码相关的整体抽象流程,对应到代码上,其核心代码如下:
#=================== tools/train.py ==================
# 1.初始化配置
cfg = Config.fromfile(args.config)
# 2.判断是否为分布式训练模式
# 3.初始化 logger
logger = get_root_logger(log_file=log_file, log_level=cfg.log_level)
# 4.收集运行环境并且打印,方便排查硬件和软件相关问题
env_info_dict = collect_env()
# 5.初始化 model
model = build_detector(cfg.model, ...)
# 6.初始化 datasets
#=================== mmdet/apis/train.py ==================
# 1.初始化 data_loaders ,内部会初始化 GroupSampler
data_loader = DataLoader(dataset,...)
# 2.基于是否使用分布式训练,初始化对应的 DataParallel
if distributed:
model = MMDistributedDataParallel(...)
else:
model = MMDataParallel(...)
# 3.初始化 runner
runner = EpochBasedRunner(...)
# 4.注册必备 hook
runner.register_training_hooks(cfg.lr_config, optimizer_config,
cfg.checkpoint_config, cfg.log_config,
cfg.get('momentum_config', None))
# 5.如果需要 val,则还需要注册 EvalHook
runner.register_hook(eval_hook(val_dataloader, **eval_cfg))
# 6.注册用户自定义 hook
runner.register_hook(hook, priority=priority)
# 7.权重恢复和加载
if cfg.resume_from:
runner.resume(cfg.resume_from)
elif cfg.load_from:
runner.load_checkpoint(cfg.load_from)
# 8.运行,开始训练
runner.run(data_loaders, cfg.workflow, cfg.total_epochs)
上面的流程比较简单,一般大家比较难以理解的是 runner.run 内部逻辑,下小节进行详细分析,而对于测试逻辑由于比较简单,就不详细描述了,简单来说测试流程下不需要 runner,直接加载训练好的权重,然后进行 model 推理即可。
3.4.2 Runner训练和验证代码抽象
runner 对象内部的 run 方式是一个通用方法,可以运行任何 workflow,目前常用的主要是 train 和 val。
- 当配置为:workflow = [(‘train’, 1)],表示仅仅进行 train workflow,也就是迭代训练
- 当配置为:workflow = [(‘train’, n),(‘val’, 1)],表示先进行 n 个 epoch 的训练,然后再进行1个 epoch 的验证,然后循环往复,如果写成 [(‘val’, 1),(‘train’, n)] 表示先进行验证,然后才开始训练
当进入对应的 workflow,则会调用 runner 里面的 train() 或者 val(),表示进行一次 epoch 迭代。其代码也非常简单,如下所示:
def train(self, data_loader, **kwargs):
self.model.train()
self.mode = 'train'
self.data_loader = data_loader
self.call_hook('before_train_epoch')
for i, data_batch in enumerate(self.data_loader):
self.call_hook('before_train_iter')
self.run_iter(data_batch, train_mode=True)
self.call_hook('after_train_iter')
self.call_hook('after_train_epoch')
def val(self, data_loader, **kwargs):
self.model.eval()
self.mode = 'val'
self.data_loader = data_loader
self.call_hook('before_val_epoch')
for i, data_batch in enumerate(self.data_loader):
self.call_hook('before_val_iter')
with torch.no_grad():
self.run_iter(data_batch, train_mode=False)
self.call_hook('after_val_iter')
self.call_hook('after_val_epoch')
核心函数实际上是 self.run_iter(),如下:
def run_iter(self, data_batch, train_mode, **kwargs):
if train_mode:
# 对于每次迭代,最终是调用如下函数
outputs = self.model.train_step(data_batch,...)
else:
# 对于每次迭代,最终是调用如下函数
outputs = self.model.val_step(data_batch,...)
if 'log_vars' in outputs:
self.log_buffer.update(outputs['log_vars'],...)
self.outputs = outputs
上述 self.call_hook() 表示在不同生命周期调用所有已经注册进去的 hook,而字符串参数表示对应的生命周期。以 OptimizerHook 为例,其执行反向传播、梯度裁剪和参数更新等核心训练功能:
@HOOKS.register_module()
class OptimizerHook(Hook):
def __init__(self, grad_clip=None):
self.grad_clip = grad_clip
def after_train_iter(self, runner):
runner.optimizer.zero_grad()
runner.outputs['loss'].backward()
if self.grad_clip is not None:
grad_norm = self.clip_grads(runner.model.parameters())
runner.optimizer.step()
3.4.3 Model训练和测试代码抽象
前面说到,训练和验证的时候实际上调用了 model 内部的 train_step 和 val_step 函数,理解了两个函数调用流程就理解了 MMDetection 训练和测试流程。
注意,由于 model 对象会被 DataParallel 类包裹,故实际上上此时的 model,是指的 MMDataParallel 或者 MMDistributedDataParallel。以非分布式 train_step 流程为例,其内部完成调用流程图示如下:
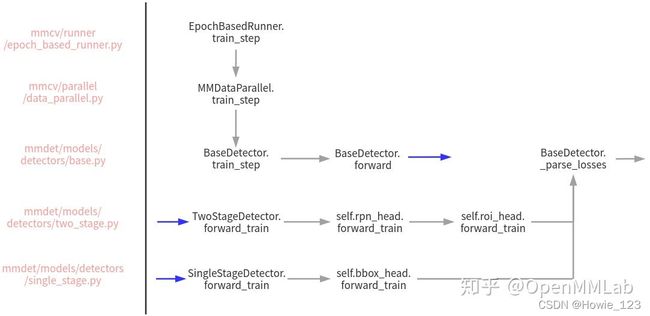
3.4.3.1 train 或者 val 流程
(1)调用runner中的train_step或者val_step,代码如下:
#=================== mmcv/runner/epoch_based_runner.py ==================
if train_mode:
outputs = self.model.train_step(data_batch,...)
else:
outputs = self.model.val_step(data_batch,...)
实际上,首先会调用 DataParallel 中的 train_step 或者 val_step ,其具体调用流程为:
# 非分布式训练
#=================== mmcv/parallel/data_parallel.py/MMDataParallel ==================
def train_step(self, *inputs, **kwargs):
if not self.device_ids:
inputs, kwargs = self.scatter(inputs, kwargs, [-1])
# 此时才是调用 model 本身的 train_step
return self.module.train_step(*inputs, **kwargs)
# 单 gpu 模式
inputs, kwargs = self.scatter(inputs, kwargs, self.device_ids)
# 此时才是调用 model 本身的 train_step
return self.module.train_step(*inputs[0], **kwargs[0])
# val_step 也是的一样逻辑
def val_step(self, *inputs, **kwargs):
inputs, kwargs = self.scatter(inputs, kwargs, self.device_ids)
# 此时才是调用 model 本身的 val_step
return self.module.val_step(*inputs[0], **kwargs[0])
可以发现,在调用 model 本身的 train_step 前,需要额外调用 scatter 函数,前面说过该函数的作用是处理 DataContainer 格式数据,使其能够组成 batch,否则程序会报错。
如果是分布式训练,则调用的实际上是 mmcv/parallel/distributed.py/MMDistributedDataParallel,最终调用的依然是 model 本身的 train_step 或者 val_step。
(2)调用 model 中的 train_step 或者 val_step,其核心代码如下:
#=================== mmdet/models/detectors/base.py/BaseDetector ==================
def train_step(self, data, optimizer):
# 调用本类自身的 forward 方法
losses = self(**data)
# 解析 loss
loss, log_vars = self._parse_losses(losses)
# 返回字典对象
outputs = dict(
loss=loss, log_vars=log_vars, num_samples=len(data['img_metas']))
return outputs
def forward(self, img, img_metas, return_loss=True, **kwargs):
if return_loss:
# 训练模式
return self.forward_train(img, img_metas, **kwargs)
else:
# 测试模式
return self.forward_test(img, img_metas, **kwargs)
forward_train 和 forward_test 需要在不同的算法子类中实现,输出是 Loss 或者预测结果。
(3)调用子类中的 forward_train 方法
目前提供了两个具体子类,TwoStageDetector 和 SingleStageDetector ,用于实现 two-stage 和 single-stage 算法。
对于TwoStageDetector 而言,其核心逻辑是:
#============= mmdet/models/detectors/two_stage.py/TwoStageDetector ============
def forward_train(...):
# 先进行 backbone+neck 的特征提取
x = self.extract_feat(img)
losses = dict()
# RPN forward and loss
if self.with_rpn:
# 训练 RPN
proposal_cfg = self.train_cfg.get('rpn_proposal',
self.test_cfg.rpn)
# 主要是调用 rpn_head 内部的 forward_train 方法
rpn_losses, proposal_list = self.rpn_head.forward_train(x,...)
losses.update(rpn_losses)
else:
proposal_list = proposals
# 第二阶段,主要是调用 roi_head 内部的 forward_train 方法
roi_losses = self.roi_head.forward_train(x, ...)
losses.update(roi_losses)
return losses
对于 SingleStageDetector 而言,其核心逻辑是:
#============= mmdet/models/detectors/single_stage.py/SingleStageDetector ============
def forward_train(...):
super(SingleStageDetector, self).forward_train(img, img_metas)
# 先进行 backbone+neck 的特征提取
x = self.extract_feat(img)
# 主要是调用 bbox_head 内部的 forward_train 方法
losses = self.bbox_head.forward_train(x, ...)
return losses
如果再往里分析,那就到各个 Head 模块的训练环节了,这部分内容请读者自行分析,应该不难。
3.4.3.2 test流程
由于没有 runner 对象,测试流程简单很多,下面简要概述:
- 调用 MMDataParallel 或 MMDistributedDataParallel 中的 forward 方法
- 调用 base.py 中的 forward 方法
- 调用 base.py 中的 self.forward_test 方法
- 如果是单尺度测试,则会调用 TwoStageDetector 或 SingleStageDetector 中的 simple_test 方法,如果是多尺度测试,则调用 aug_test 方法
3.5 总结
本章详细地从三个层面全面解读了 MMDetection 框架,希望读者读完本章,能够对 MMDetection 框架设计思想、组件间关系和整体代码实现流程了然于心。
[1]: MMDetection Doc
[2]: 轻松掌握MMDetection整体构建流程(一)
[3]: 轻松掌握 MMDetection 整体构建流程(二)