DN-DETR 论文精度,并解析其模型结构 & 2022年CVPR论文
- 继DETR提出以后,Transformer在目标检测领域越发闪耀,由于DETR模型的简单高效性能,与其相关的论文层出不穷。
- DN-DETR通过分析DETR收敛速度慢的其中一个原因是二分图匹配的不稳定性,从而提出去噪方法来稳定匹配,加速模型的收敛。当然,还有很多的细节,接下来通过精读论文来挖掘其中的趣味想法。
- 更多计算机视觉文章见精度论文系列的大纲,链接在文章末尾。
DN-DETR: Accelerate DETR Training by Introducing Query DeNoising
Dn-Detr:通过引入查询去噪来加速DETR训练
目录
一、摘要
二、结论
三、发现问题和解决问题
(1)问题的提出
(2)问题的解决
四、为什么去噪能加速DETR的训练?
五、解析DN-DETR模型结构
(1)DAB - DETR和DN - DETR的交叉注意力部分比较
(2)去噪
(3)注意力掩码
(4)标签嵌入
六、实验
(1)实验细节
(2)实验结果
七、未来工作
一、摘要
本文提出了一种新的去噪训练方法来加速DETR ( DEtection TRansformer )训练,并加深了对DETR类方法收敛速度慢问题的理解。我们表明,缓慢的收敛是由于二分图匹配的不稳定性导致在早期训练阶段优化目标不一致。为了解决这个问题,除了匈牙利损失外,我们的方法还将带有噪声的真实边界框输入到Transformer解码器中,并训练模型来重建原始框,这有效地降低了二分图匹配的难度,并导致更快的收敛。 我们的方法具有普适性,可以通过添加几十行代码很容易地插入到任何类似DETR的方法中,从而实现显著的改进。因此,我们的DN - DETR在相同的设置下取得了显著的提升( + 1.9AP ),并在ResNet - 50主干的DETR - like方法中取得了最好的结果( AP 43.4和48.6 ,分别接受12次和50次epoch )。与相同设置下的 baseline 相比,DN - DETR在50 %的训练次数下获得了相当的性能。
论文链接:https://arxiv.org/abs/2203.01305
源码链接:https://github.com/FengLi-ust/DN-DETR
二、结论
本文分析了不稳定二分图匹配中DETR训练收敛速度慢的原因,并提出了一种新的去噪训练方法来解决这个问题。基于此分析,我们提出了DN - DETR,将去噪训练融入到DAB - DETR中,以检验其有效性。DN - DETR将解码器嵌入指定为标签嵌入,并引入了 box 和标签的去噪训练。我们还在Deformable DETR中加入了去噪训练以显示其通用性。结果表明,去噪训练显著加快了收敛速度并提高了性能,在以ResNet - 50和ResNet - 101为主干的1x ( 12epoch )设置中取得了最佳结果。本研究表明,去噪训练可以很容易地集成到DETR - like模型中,作为一种通用的训练方法,只需要很小的训练开销,并且在训练收敛和检测性能方面都有显著的改善。
Limitations and Future Work: 在这项工作中,所添加的噪声简单地从均匀分布中采样。我们还没有探索更复杂的噪声方案,并留给未来的工作。重构噪声数据在无监督学习中取得了巨大的成功。这项工作是将其应用于目标检测的第一步。未来,我们将探索如何使用无监督学习技术在弱标记数据上预训练检测器,或者探索其他无监督学习方法,如对比学习。
三、发现问题和解决问题
(1)问题的提出
先前的很多工作都试图找出根本原因并缓解收敛缓慢的问题。尽管取得了很多的进展,但很少有工作关注两分图匹配部分以获得更有效的训练。在这项研究中,我们发现慢收敛问题也是由离散二分图匹配组件造成的,由于随机优化的性质,这种组件在训练的早期阶段是不稳定的。因此,对于同一幅图像,查询往往与不同时期的不同对象进行匹配,这使得优化变得模糊和不稳定。
(2)问题的解决
为了解决这个问题,我们提出了一种新的训练方法,通过引入查询去噪任务来帮助稳定训练过程中的二部图匹配。由于先前的工作已经证明将查询解释为参考点《Anchor detr》《Deformable detr》或锚框《DAB-DETR》是有效的,其中包含位置信息,因此我们遵循他们的观点,使用4D锚框作为查询。我们的解决方案是将带噪的 ground truth 边界框作为带噪查询与可学习的锚查询一起输入到Transformer解码器。这两种查询具有相同的( x , y , w , h )输入格式,可以同时输入到Transformer解码器中。对于带噪查询,我们执行一个去噪任务来重建它们对应的 ground truth boxes。对于其他可学习的锚查询,我们使用与vanilla DETR中相同的训练损失,包括二分匹配。由于带噪边界框不需要经过二分图匹配组件,因此去噪任务可以被视为一个更简单的辅助任务,帮助DETR缓解不稳定的离散二分图匹配,并更快速地学习边界框预测。同时,去噪任务也有助于降低优化难度,因为添加的随机噪声通常很小。为了最大限度地发挥这个辅助任务的潜力,我们还将每个解码器查询视为一个边界框和一个类标签嵌入,这样我们就能够同时进行框去噪和标签去噪。
总之,我们的方法是一种去噪训练方法。我们的损失函数由两部分组成。一个是重建损失,另一个是匈牙利损失,这与其他类似DETR的方法相同。我们的方法可以很容易地插入到任何现有的类似DETR的方法中。为了方便起见,我们使用DAB - DETR来评估我们的方法,因为他们的解码器查询显式地表示为4D锚框( x , y , w , h)。
- 对于只支持2D锚点的DETR变体,如anchor DETR,我们可以对锚点进行去噪。
- 对于那些不支持锚点的查询,比如vanilla DETR,我们可以做线性变换将4D锚框映射到与其他可学习查询相同的潜在空间。
据我们所知,这是第一个将去噪原理引入检测模型的工作。我们将我们的贡献总结如下:
- 我们设计了一种新的训练方法来加速DETR的训练。实验结果表明,我们的方法不仅加快了训练收敛速度,而且训练结果也得到了显著的改善---在设置epoch=12的情况下取得了所有检测算法中最好的结果。此外,我们的方法比基准的DAB - DETR有显著的改进( + 1.9 AP ),并且可以很容易地集成到其他类似DETR的方法中。
- 我们从一个新的角度分析了DETR的缓慢收敛,并对DETR训练有了更深入的理解。我们设计了一个度量来评估二分匹配的不稳定性,并验证了我们的方法可以有效地降低不稳定性。
- 我们进行了一系列的消融研究来分析我们模型的不同组成部分的有效性,例如噪声、标签嵌入和注意力掩模。
四、为什么去噪能加速DETR的训练?
匈牙利匹配是图匹配中的一种流行算法。给定一个代价矩阵,算法输出一个最优的匹配结果。DETR是第一个在目标检测中采用匈牙利匹配的算法,用来解决预测目标和真实目标之间的匹配问题。DETR将真值分配问题转化为一个动态过程,由于其离散的二分匹配和随机的训练过程,导致了一个不稳定问题。有工《The stable marriage prob-lem: An interdisciplinary review from the physicist’s per-spective》表明,由于存在阻塞对,匈牙利匹配不会导致稳定匹配。代价矩阵的微小变化可能会导致匹配结果的巨大改变,这将进一步导致解码器查询的优化目标不一致。
我们将DETR - like模型的训练过程分为学习"good anchors"和学习相对偏移两个阶段。解码器查询负责学习锚点,如以前的工作《Deformable detr》《DAB-DETR》所示。锚的更新不一致会使学习相对偏移量变得困难,因此,在我们的方法中,我们利用去噪任务作为训练捷径,使相对偏移学习更容易,因为去噪任务绕过了二分匹配。由于我们将每个解码器查询解释为一个4-D锚框,所以一个噪声查询可以被视为一个"good anchors",其附近有一个对应的真值框。去噪训练因此有了明确的优化目标---预测原始边界框,从本质上避免了匈牙利匹配带来的歧义。
为了定量评估二分匹配结果的不稳定性,我们设计了如下的度量指标。对于训练图像:
A) Transformer解码器中的预测对象表示为第 i 个 epoch 中的![]() ,其中 N 是预测对象的数量,
,其中 N 是预测对象的数量,
B) 而真实对象表示为![]() ,其中 M 是真实对象的数量。
,其中 M 是真实对象的数量。
C) 在进行二分匹配后,我们计算一个索引向量![]()
![]() 来存储 epoch i 的匹配结果,如下所示:
来存储 epoch i 的匹配结果,如下所示:
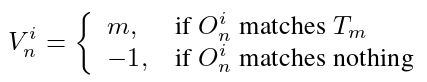
D) 我们将一个训练图像的epoch i 的不稳定性定义为其 ![]() 之间的差值,差值越小,匹配越完美,其计算公式为:
之间的差值,差值越小,匹配越完美,其计算公式为:
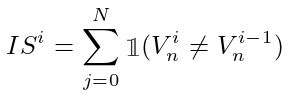
其中![]() 是指示函数。如果 x 为 true,则
是指示函数。如果 x 为 true,则![]() ,否则为 0。整个数据集的 epoch i 的不稳定度在所有图像的不稳定度上取平均。上面两个公式式中省略了图像的简单性指数。
,否则为 0。整个数据集的 epoch i 的不稳定度在所有图像的不稳定度上取平均。上面两个公式式中省略了图像的简单性指数。
图2 显示了DN-DETR ( DeNoising DETR )和DAB-DETR之间的 IS 比较。我们在COCO 2017验证集上执行此评估,该验证集平均每个图像有7.36个对象。所以最大可能的 IS 为7.36 × 2 = 14.72。图2 清楚地表明我们的方法有效地缓解了匹配的不稳定性。对于每种方法,我们在相同的设置上训练12个epoch。我们测试验证集为 IS 的每两个epoch之间匈牙利匹配的变化。
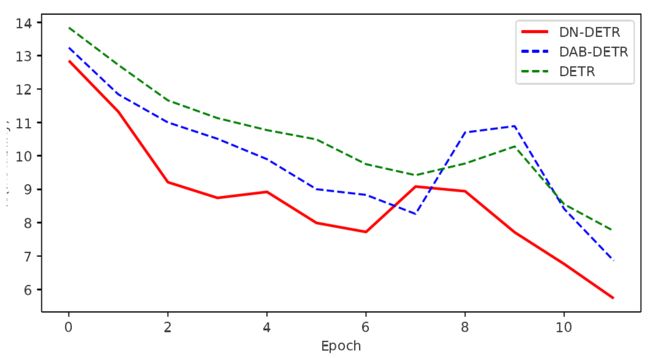
图2 训练期间DAB - DETR和DN - DETR的 IS
五、解析DN-DETR模型结构
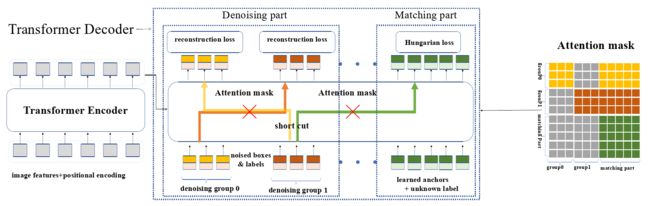
图4 训练方法的概述
图4 中的查询有两个部分,即去噪部分和匹配部分。去噪部分包含 ≥1 个去噪组。从匹配部分到去噪部分以及去噪组之间的注意力掩码设置为1 (block)以阻止信息泄漏( 具体内容往下阅读便可知 )。最右侧的图像是注意力掩模( Attention Mask ),其中黄色、棕色和绿色网格代表0 (unblock),灰色网格代表1 (block)。
我们基于DAB - DETR的架构《DAB-DETR:Dynamicanchor boxes are better queries for DETR》来实现我们的训练方法。与DAB - DETR类似,我们将解码器查询显式地表示为框坐标。我们的架构与他们的架构唯一的区别在于解码器嵌入,它被指定为类标签嵌入以支持标签去噪。我们的主要贡献是训练方法,如图4所示。
与DETR类似,我们的体系结构包含一个Transformer编码器和一个Transformer解码器。在编码器端,使用CNN主干提取图像特征,然后将图像特征输入到带有位置编码的Transformer编码器中,得到细化的图像特征。在解码器端,查询被输入到解码器中以通过交叉注意力搜索对象。
我们将解码器查询表示为![]() ,Transformer解码器的输出表示为
,Transformer解码器的输出表示为![]()
![]() 。方法具体表述如下:
。方法具体表述如下:
![]()
式中:D 为Transformer解码器。F 表示经过Transformer编码器。A 表示基于去噪任务设计派生的注意力掩码之后的细化图像特征。
图4 中的解码器查询有两个部分:
- 一个是匹配部分( Matching Part )。这部分的输入是可学习的锚,它们的处理方式与DETR相同。也就是说,匹配部分采用二分图匹配,并学习用匹配的解码器输出来近似 ground truth box-label pairs 。
- 另一部分是去噪部分( Denoising Part )。这部分的输入是带噪的 Ground-truth ( GT ) box - label 对,在本文其余部分称为 GT 对象。
去噪部分的输出旨在重建( Recontruction ) GT 对象。
下面用符号表示去噪部分为![]() ,匹配部分为
,匹配部分为![]() 。所以我们方法的提法就变成了:
。所以我们方法的提法就变成了:
![]()
为了提高去噪效率,我们建议在去噪部分使用多个版本的带噪GT对象。更进一步,我们利用一个注意力掩模来防止信息从去噪部分泄漏到匹配部分以及同一GT对象的不同噪声版本之间。
(1)DAB - DETR和DN - DETR的交叉注意力部分比较
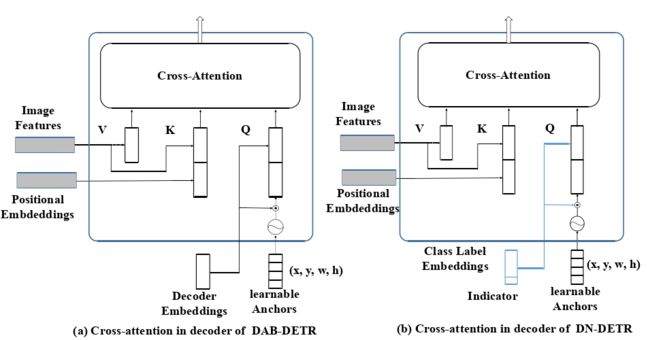
图3 DAB - DETR和DN - DETR的交叉注意力部分比较
- ( a ) DAB - DETR直接使用动态更新的锚框来同时提供一个参考查询点( x , y )和一个参考锚框大小( w , h )来提高交叉注意力计算。
- ( b ) DN-DETR将解码器嵌入指定为标签嵌入,并添加一个指示符( Indicator )以区分去噪任务和匹配任务。
最近的许多工作将DETR查询与不同的位置信息相关联。DAB-DETR遵循此分析,并将每个查询显式表示为4D锚坐标。如图3 ( a )所示,查询被指定为tuple( x , y , w , h),其中x,y为中心坐标,w,h分别为每个box对应的宽度和高度。此外,锚坐标是逐层动态更新的。每个解码器层的输出包含一个tuple(∆x ,∆y ,∆w ,∆h),锚更新为( x +∆x , y +∆y , w +∆w , h +∆h)。
需要注意的是,我们提出的方法主要是一种训练方法,可以集成到任何DETR - like模型中。为了在DAB - DETR上进行测试,我们只添加了最小修改:将解码器嵌入指定为标签嵌入,如图3 ( b )所示。
(2)去噪
对于每个图像,我们收集所有GT对象,并将随机噪声添加到它们的边界框和类标签。为了最大化去噪学习的效用,我们对每个GT对象使用多个加噪版本。
我们考虑以两种方式向 box 添加噪音:center shifting and box scaling。我们定义 λ1 和 λ2 为这两种噪声的噪声尺度。
- 对于中心偏移,我们在 bbox 中心添加一个随机噪声(∆x ,∆y),并确保|∆x | < λ1/w2和|∆y | < λ1/h2,其中λ 1∈( 0 , 1),这样噪声 bbox 的中心仍然位于原始 bbox 内部。
- 对于框缩放,我们设置一个超参数λ 2∈( 0 , 1)。box 的宽度和高度分别在[ ( 1-λ2 ) w , ( 1 + λ2 ) w]和[ ( 1-λ2 ) h , ( 1 + λ2 ) h]中随机采样。
对于标签噪音,我们采用标签翻转,这意味着我们随机翻转一些真实标签到其他标签。标签翻转迫使模型根据噪声框预测真实标签,以更好地捕获标签-框关系。我们有一个超参数γ来控制标签翻转的比例。与DAB - DETR一样,重构损失对于盒子是l1 loss和GIOU loss,对于类标签是focal loss [ 9 ]。我们用一个函数![]() 来表示带噪声的GT对象。因此,去噪部分中的每个查询都可以表示为
来表示带噪声的GT对象。因此,去噪部分中的每个查询都可以表示为![]() ,其中
,其中![]() 是第m个GT对象。(此处的定义在注意力掩码设计部分有用到)
是第m个GT对象。(此处的定义在注意力掩码设计部分有用到)
注意:去噪只在训练中考虑,在推理过程中去噪部分被移除,只留下匹配部分。
(3)注意力掩码
注意力掩码是我们模型中一个非常重要的组成部分。如果没有注意力掩码,去噪训练将损害性能,而不是提高性能,如表4所示。在相同的默认设置下,所有模型均使用ResNet - 50主干使用1个去噪组进行训练。当不选用Attention Mask时,AP下降了18个点左右。
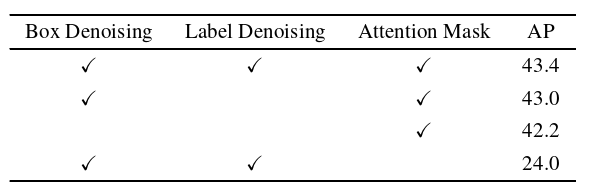
表4 DN-DETR的消融结果
为了引入注意力掩码,我们需要首先将带噪的GT对象分成组。每个组是所有GT对象的加噪版本,去噪部分变为:
![]()
其中 ![]() 被定义为第 p 个去噪组。每个去噪组包含 M 个查询,其中 M 为图像中 GT 对象的个数。定义
被定义为第 p 个去噪组。每个去噪组包含 M 个查询,其中 M 为图像中 GT 对象的个数。定义 ![]() ,则有:
,则有:
![]()
注意力掩码的目的是防止信息泄露。潜在的信息泄露有两种类型:
- 一种是匹配部分可以看到被噪声污染的GT对象,并且容易预测GT对象。
- 另一个是一个GT对象的一个噪声版本可能会看到另一个版本。
因此,我们的注意力掩码是确保匹配部分和去噪部分互相看不到,如图5 所示,其中黄色、棕色和绿色网格代表0 (unblock),灰色网格代表1 (block)。
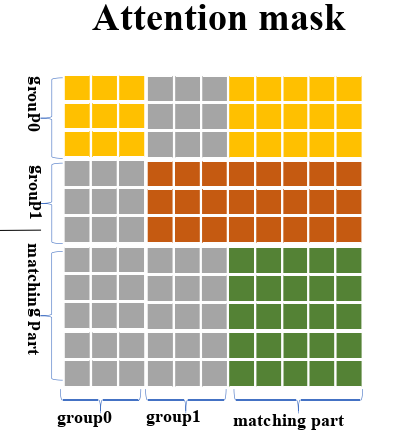
图5 注意力掩模( Attention Mask )概念图
我们使用![]() 来表示注意力掩码,其中 W = P × M + N。P 和 M 是去噪组和GT对象的数量。N 是匹配部分的查询数。令第一个 P × M 行和列表示去噪部分,N 表示匹配部分。
来表示注意力掩码,其中 W = P × M + N。P 和 M 是去噪组和GT对象的数量。N 是匹配部分的查询数。令第一个 P × M 行和列表示去噪部分,N 表示匹配部分。![]() 表示第 i 个查询不能看到第 j 个查询,否则
表示第 i 个查询不能看到第 j 个查询,否则  。我们设计注意力掩模如下:
。我们设计注意力掩模如下:
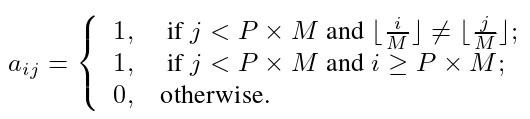
注意:去噪部分是否可以看到匹配部分不会影响性能,因为匹配部分的查询是学习的查询,不包含GT对象的信息。
多个去噪组引入的额外计算可以忽略不计---当引入5个去噪组时,用于训练的GFLOP仅从拥有R50骨干的DAB - DETR的AP从94.4增加到94.6,并且没有用于测试的计算开销。
(4)标签嵌入
在我们的模型中,解码器嵌入被指定为标签嵌入( Label Embeding ),以同时支持box去噪和标签去噪。除了COCO 2017 中的80个类之外,我们还考虑了一个未知的类嵌入,它用于匹配部分,以在语义上与去噪部分一致。我们还添加了一个指示符来标记嵌入,如果查询属于去噪部分,则该指标为1,否则为0。
六、实验
(1)实验细节
我们在DAB - DETR上测试了去噪训练的有效性,DAB - DETR由一个CNN主干、多个Transformer编码器层和解码器层组成。我们还表明,去噪训练可以插入到其他类似DETR的模型中以提高性能。例如,我们的DN-Deformable-DETR是在多尺度设置中基于Deformable DETR构建的。我们采用在ImageNet上预训练的多个ResNet模型作为主干网络,并在4个ResNet集上报告了我们的结果:ResNet-50 ( R50 ),ResNet-101 ( R101 ),以及它们的16 × 分辨率扩展ResNet - 50 - DC5 ( DC5-R50 )和ResNet - 101 - DC5 ( DC5-R101 )。对于超参数,我们遵循DAB - DETR使用6层Transformer编码器和6层Transformer解码器,并使用256作为隐藏层通道数。我们在box上添加均匀噪声,并设置关于噪声的超参数为 λ 1 = 0.4,λ2 = 0.4,γ = 0.2。对于学习率调度器,我们使用初始学习率( lr ) 1 × 10 - 4并在第40个epoch后,将 lr 乘以0.1作为50-epoch的设置,在第11个epoch,将 lr 乘以0.1作为12-epoch的设置。使用权重衰减为1 × 10^(-4)的AdamW优化器,在8个Nvidia A100 GPU上训练模型。batch_size大小为16。除非另有规定,我们使用5个去噪组。
(2)实验结果
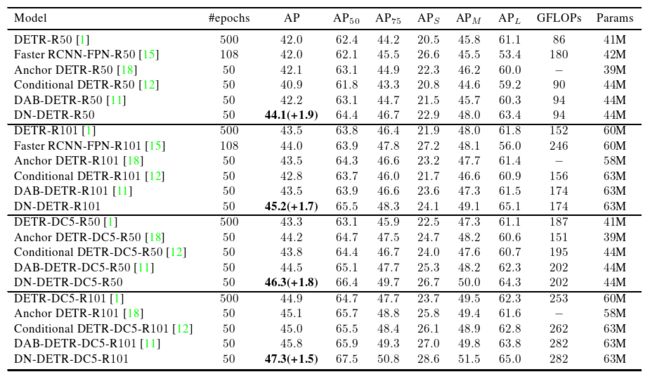
表1 DN - DETR和其他检测模型在相同的设置下的结果。除DETR外的所有DETR - like模型均使用300个查询,而DETR使用100个查询。
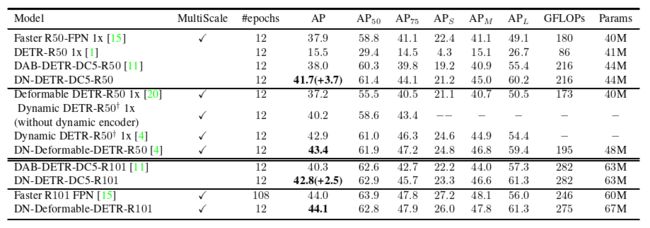
表2 DN - DETR和其他检测模型在1x设置( 12 epochs )上的结果。上标![]() 表示我们通过私有通信与Dynamic DETR的作者进行了验证,他们的编码器设计使得他们的单尺度和多尺度结果几乎完全一致。
表示我们通过私有通信与Dynamic DETR的作者进行了验证,他们的编码器设计使得他们的单尺度和多尺度结果几乎完全一致。
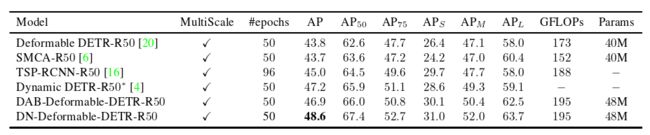
表3 DN - DETR和其他带有ResNet - 50主干的检测模型的最好的结果。* 指示它是test-dev结果。
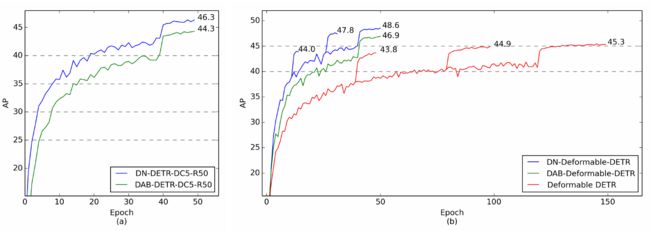
图5 Epoch-AP曲线图
- ( a ) DAB - DETR和DN - DETR与ResNet - DC5 - 50的收敛曲线。在学习率下降之前,DN - DETR在20个epoch内达到40AP,而DAB - DETR需要40个epoch。
- ( b ) ResNet - 50多尺度模型的收敛曲线。随着学习率的下降,DN - Deformable - DETR在30个epoch内达到47.8 AP,比收敛的DAB - Deformable - DETR高0.9 AP。
- 曲线突然抬高处,表示手动调节学习率,一般是当前的学习率×0.1。
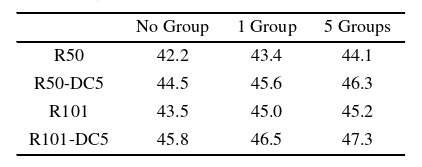
表5 使用不同数量的去噪组对DN - DETR的消融结果。所有模型均在相同的默认设置下使用ResNet - 50 Backbone进行训练。
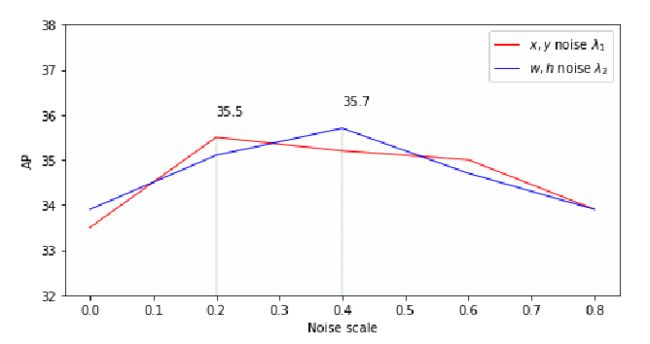
图6 不同噪声尺度下的DN - DETR。我们将一个噪声级固定为0.4并更改另一个。 故默认情况下,选取λ 1 = 0.4,λ2 = 0.4时,模型可以得到最好的性能。

表1 在相同的设置下,我们的方法训练了25个epoch,我们的基线方法( DAB-DETR or Deformable-DETR )训练了50个epoch。结果表明,通过去噪训练,我们实现了2倍的加速。
七、未来工作
这里有两个潜在的未来工作需要提及。一个是零样本检测,另一个是渐进推断。
- Zeroshot Detection:由于我们已经将解码器查询解耦为锚框和类标签,预训练的类标签嵌入可以输入到查询的类标签部分。为了实现零样本检测,可以将MSCOCO的80个类作为短语,并从预训练的语言模型中收集短语嵌入作为类标签嵌入。通过预训练的标签嵌入,可以训练一个给定的类检测器,该检测器以一个类标签嵌入作为输入并检测给定类的对象。在推理时间内,来自未知类的类标签嵌入可以被输入到解码器中,以实现零样本检测。
- Progressive inference:在已知物体检测的基础上,可以设计一种渐进式的推理方法。例如,我们可以训练一个能够进行已知物体检测的DN - DETR。在推理时,我们让检测器预测对象,然后,我们可以选择得分最高的对象,并将它们作为已知对象来进行已知对象检测。对于预测的每一步,我们选择得分最高的对象,并将它们添加到已知的框的集合。经过多次重复,我们得到了最终的预测结果。
>>> 论文大纲直达链接:
计算机视觉论文精度大纲_Flying Bulldog的博客-CSDN博客 https://blog.csdn.net/qq_54185421/article/details/125571690
https://blog.csdn.net/qq_54185421/article/details/125571690