使用python将发票数据追加到数据库
如何使用python连接数据库,并将执行的结果写入数据库?
对于pdf发票内容的提取有大佬已经写过了,可参考(13条消息) 浅谈发票识别方案-开篇_yczha的博客-CSDN博客_发票识别 https://blog.csdn.net/zyc121561/article/details/115354424
https://blog.csdn.net/zyc121561/article/details/115354424
这里主要内容是将获取的信息数据插入到数据库中,以发票为例
一.提取pdf发票中的信息,并写入到excel
# _*_ coding:utf-8 _*_
# @Time : 2022/9/29 13:24
# @Author : ice_Seattle
# @File : 发票贴贴.py
# @Software: PyCharm
import os
import re
import pandas as pd
import xlwings as xw
import pdfplumber as pb
class Extractor(object):
def __init__(self, path):
self.file = path if os.path.isfile else None
def _load_data(self):
if self.file and os.path.splitext(self.file)[1] == '.pdf':
pdf = pb.open(self.file)
page = pdf.pages[0]
words = page.extract_words(x_tolerance=5)
lines = page.lines
# convert coordination
for index, word in enumerate(words):
words[index]['y0'] = word['top']
words[index]['y1'] = word['bottom']
for index, line in enumerate(lines):
lines[index]['x1'] = line['x0']+line['width']
lines[index]['y0'] = line['top']
lines[index]['y1'] = line['bottom']
return {'words': words, 'lines': lines}
else:
print("file %s can't be opened." % self.file)
return None
def _fill_line(self, lines):
hlines = [line for line in lines if line['width'] > 0] # 筛选横线
hlines = sorted(hlines, key=lambda h: h['width'], reverse=True)[:-2] # 剔除较短的两根
vlines = [line for line in lines if line['height'] > 0] # 筛选竖线
vlines = sorted(vlines, key=lambda v: v['y0']) # 按照坐标排列
# 查找边框顶点
hx0 = hlines[0]['x0'] # 左侧
hx1 = hlines[0]['x1'] # 右侧
vy0 = vlines[0]['y0'] # 顶部
vy1 = vlines[-1]['y1'] # 底部
thline = {'x0': hx0, 'y0': vy0, 'x1': hx1, 'y1': vy0} # 顶部横线
bhline = {'x0': hx0, 'y0': vy1, 'x1': hx1, 'y1': vy1} # 底部横线
lvline = {'x0': hx0, 'y0': vy0, 'x1': hx0, 'y1': vy1} # 左侧竖线
rvline = {'x0': hx1, 'y0': vy0, 'x1': hx1, 'y1': vy1} # 右侧竖线
hlines.insert(0, thline)
hlines.append(bhline)
vlines.insert(0, lvline)
vlines.append(rvline)
return {'hlines': hlines, 'vlines': vlines}
def _is_point_in_rect(self, point, rect):
'''判断点是否在矩形内'''
px, py = point
p1, p2, p3, p4 = rect
if p1[0] <= px <= p2[0] and p1[1] <= py <= p3[1]:
return True
else:
return False
def _find_cross_points(self, hlines, vlines):
points = []
delta = 1
for vline in vlines:
vx0 = vline['x0']
vy0 = vline['y0']
vy1 = vline['y1']
for hline in hlines:
hx0 = hline['x0']
hy0 = hline['y0']
hx1 = hline['x1']
if (hx0-delta) <= vx0 <= (hx1+delta) and (vy0-delta) <= hy0 <= (vy1+delta):
points.append((int(vx0), int(hy0)))
return points
def _find_rects(self, cross_points):
# 构造矩阵
X = sorted(set([int(p[0]) for p in cross_points]))
Y = sorted(set([int(p[1]) for p in cross_points]))
df = pd.DataFrame(index=Y, columns=X)
for p in cross_points:
x, y = int(p[0]), int(p[1])
df.loc[y, x] = 1
df = df.fillna(0)
# 寻找矩形
rects = []
COLS = len(df.columns)-1
ROWS = len(df.index)-1
for row in range(ROWS):
for col in range(COLS):
p0 = df.iat[row, col] # 主点:必能构造一个矩阵
cnt = col+1
while cnt <= COLS:
p1 = df.iat[row, cnt]
p2 = df.iat[row+1, col]
p3 = df.iat[row+1, cnt]
if p0 and p1 and p2 and p3:
rects.append(((df.columns[col], df.index[row]), (df.columns[cnt], df.index[row]), (
df.columns[col], df.index[row+1]), (df.columns[cnt], df.index[row+1])))
break
else:
cnt += 1
return rects
def _put_words_into_rect(self, words, rects):
# 将words按照坐标层级放入矩阵中
groups = {}
delta = 2
for word in words:
p = (int(word['x0']), int((word['y0']+word['y1'])/2))
flag = False
for r in rects:
if self._is_point_in_rect(p, r):
flag = True
groups[('IN', r[0][1], r)] = groups.get(
('IN', r[0][1], r), [])+[word]
break
if not flag:
y_range = [
p[1]+x for x in range(delta)]+[p[1]-x for x in range(delta)]
out_ys = [k[1] for k in list(groups.keys()) if k[0] == 'OUT']
flag = False
for y in set(y_range):
if y in out_ys:
v = out_ys[out_ys.index(y)]
groups[('OUT', v)].append(word)
flag = True
break
if not flag:
groups[('OUT', p[1])] = [word]
return groups
def _find_text_by_same_line(self, group, delta=1):
words = {}
group = sorted(group, key=lambda x: x['x0'])
for w in group:
bottom = int(w['bottom'])
text = w['text']
k1 = [bottom-i for i in range(delta)]
k2 = [bottom+i for i in range(delta)]
k = set(k1+k2)
flag = False
for kk in k:
if kk in words:
words[kk] = words.get(kk, '')+text
flag = True
break
if not flag:
words[bottom] = words.get(bottom, '')+text
return words
def _split_words_into_diff_line(self, groups):
groups2 = {}
for k, g in groups.items():
words = self._find_text_by_same_line(g, 3)
groups2[k] = words
return groups2
def _index_of_y(self, x, rects):
for index, r in enumerate(rects):
if x == r[2][0][0]:
return index+1 if index+1 < len(rects) else None
return None
def _find_outer(self, k, words):
df = pd.DataFrame()
for pos, text in words.items():
if re.search(r'发票$', text): # 发票名称
df.loc[0, '发票名称'] = text
elif re.search(r'发票代码', text): # 发票代码
num = ''.join(re.findall(r'[0-9]+', text))
df.loc[0, '发票代码'] = num
elif re.search(r'发票号码', text): # 发票号码
num = ''.join(re.findall(r'[0-9]+', text))
df.loc[0, '发票号码'] = num
elif re.search(r'开票日期', text): # 开票日期
date = ''.join(re.findall(
r'[0-9]{4}年[0-9]{1,2}月[0-9]{1,2}日', text))
df.loc[0, '开票日期'] = date
elif '机器编号' in text and '校验码' in text: # 校验码
text1 = re.search(r'校验码:\d+', text)[0]
num = ''.join(re.findall(r'[0-9]+', text1))
df.loc[0, '校验码'] = num
text2 = re.search(r'机器编号:\d+', text)[0]
num = ''.join(re.findall(r'[0-9]+', text2))
df.loc[0, '机器编号'] = num
elif '机器编号' in text:
num = ''.join(re.findall(r'[0-9]+', text))
df.loc[0, '机器编号'] = num
elif '校验码' in text:
num = ''.join(re.findall(r'[0-9]+', text))
df.loc[0, '校验码'] = num
elif re.search(r'收款人', text):
items = re.split(r'收款人:|复核:|开票人:|销售方:', text)
items = [item for item in items if re.sub(
r'\s+', '', item) != '']
df.loc[0, '收款人'] = items[0] if items and len(items) > 0 else ''
df.loc[0, '复核'] = items[1] if items and len(items) > 1 else ''
df.loc[0, '开票人'] = items[2] if items and len(items) > 2 else ''
df.loc[0, '销售方'] = items[3] if items and len(items) > 3 else ''
return df
def _find_and_sort_rect_in_same_line(self, y, groups):
same_rects_k = [k for k, v in groups.items() if k[1] == y]
return sorted(same_rects_k, key=lambda x: x[2][0][0])
def _find_inner(self, k, words, groups, groups2, free_zone_flag=False):
df = pd.DataFrame()
sort_words = sorted(words.items(), key=lambda x: x[0])
text = [word for k, word in sort_words]
context = ''.join(text)
if '购买方' in context or '销售方' in context:
y = k[1]
x = k[2][0][0]
same_rects_k = self._find_and_sort_rect_in_same_line(y, groups)
target_index = self._index_of_y(x, same_rects_k)
target_k = same_rects_k[target_index]
group_context = groups2[target_k]
prefix = '购买方' if '购买方' in context else '销售方'
for pos, text in group_context.items():
if '名称' in text:
name = re.sub(r'名称:', '', text)
df.loc[0, prefix+'名称'] = name
elif '纳税人识别号' in text:
tax_man_id = re.sub(r'纳税人识别号:', '', text)
df.loc[0, prefix+'纳税人识别号'] = tax_man_id
elif '地址、电话' in text:
addr = re.sub(r'地址、电话:', '', text)
df.loc[0, prefix+'地址电话'] = addr
elif '开户行及账号' in text:
account = re.sub(r'开户行及账号:', '', text)
df.loc[0, prefix+'开户行及账号'] = account
elif '密码区' in context:
y = k[1]
x = k[2][0][0]
same_rects_k = self._find_and_sort_rect_in_same_line(y, groups)
target_index = self._index_of_y(x, same_rects_k)
target_k = same_rects_k[target_index]
words = groups2[target_k]
context = [v for k, v in words.items()]
context = ''.join(context)
df.loc[0, '密码区'] = context
elif '价税合计' in context:
y = k[1]
x = k[2][0][0]
same_rects_k = self._find_and_sort_rect_in_same_line(y, groups)
target_index = self._index_of_y(x, same_rects_k)
target_k = same_rects_k[target_index]
group_words = groups2[target_k]
group_context = ''.join([w for k, w in group_words.items()])
items = re.split(r'[((]小写[))]', group_context)
b = items[0] if items and len(items) > 0 else ''
s = items[1] if items and len(items) > 1 else ''
df.loc[0, '价税合计(大写)'] = b
df.loc[0, '价税合计(小写)'] = s
elif '备注' in context:
y = k[1]
x = k[2][0][0]
same_rects_k = self._find_and_sort_rect_in_same_line(y, groups)
target_index = self._index_of_y(x, same_rects_k)
if target_index:
target_k = same_rects_k[target_index]
group_words = groups2[target_k]
group_context = ''.join([w for k, w in group_words.items()])
df.loc[0, '备注'] = group_context
else:
df.loc[0, '备注'] = ''
else:
if free_zone_flag:
return df, free_zone_flag
y = k[1]
x = k[2][0][0]
same_rects_k = self._find_and_sort_rect_in_same_line(y, groups)
if len(same_rects_k) == 8:
free_zone_flag = True
for kk in same_rects_k:
yy = kk[1]
xx = kk[2][0][0]
words = groups2[kk]
words = sorted(words.items(), key=lambda x: x[0]) if words and len(
words) > 0 else None
key = words[0][1] if words and len(words) > 0 else None
val = [word[1] for word in words[1:]
] if key and words and len(words) > 1 else ''
val = '\n'.join(val) if val else ''
if key:
df.loc[0, key] = val
return df, free_zone_flag
def extract(self):
data = self._load_data()
words = data['words']
lines = data['lines']
lines = self._fill_line(lines)
hlines = lines['hlines']
vlines = lines['vlines']
cross_points = self._find_cross_points(hlines, vlines)
rects = self._find_rects(cross_points)
word_groups = self._put_words_into_rect(words, rects)
word_groups2 = self._split_words_into_diff_line(word_groups)
df = pd.DataFrame()
free_zone_flag = False
for k, words in word_groups2.items():
if k[0] == 'OUT':
df_item = self._find_outer(k, words)
else:
df_item, free_zone_flag = self._find_inner(
k, words, word_groups, word_groups2, free_zone_flag)
df = pd.concat([df, df_item], axis=1)
return df
if __name__ == "__main__":
path = r'滴滴电子发票.pdf'
data = Extractor(path).extract()
print(data)
path_save = f'E:/py/{path[:-4]}.xlsx'
data.to_excel(path_save, sheet_name='Sheet1', index=False)
app = xw.App(visible=False, add_book=False)
app.display_alerts = False
app.screen_updating = True
wb = app.books.open(path_save)
sht = wb.sheets.active # 获取当前活动的工作表
A1 = sht['A1:AD2']
"""设置单元格 字体格式"""
# 修改宽高
A1.column_width = 12
# sht.range('B1:E1').column_width = 20.5
A1.row_height = 30
"""设置边框"""
# Borders(11) 内部垂直边线。
A1.api.Borders(11).LineStyle = 1
A1.api.Borders(11).Weight = 2
# Borders(12) 内部水平边线。
A1.api.Borders(12).LineStyle = 1
A1.api.Borders(12).Weight = 2
# LineStyle = 1 直线。
A1.api.Borders(9).LineStyle = 1
A1.api.Borders(9).Weight = 2 # 设置边框粗细。
A1.api.Borders(10).LineStyle = 1
A1.api.Borders(10).Weight = 2
A1.api.HorizontalAlignment = -4108 # 水平居中
A1.api.VerticalAlignment = -4130 # 自动换行对齐
file_path = r'./发票/'+data.loc[0][0] + data.loc[0][1] + '.xlsx'
wb.save(file_path)
app.quit()
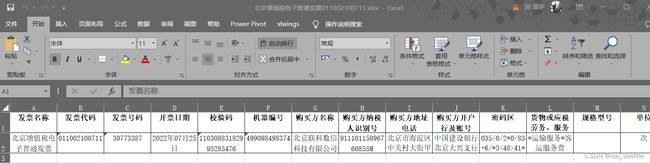
其中程序中path变量的路径文件内容如下:

运行上述程序得到excl表:
二.数据插入到数据库中
方式(1)
Kettle工具中可以使用
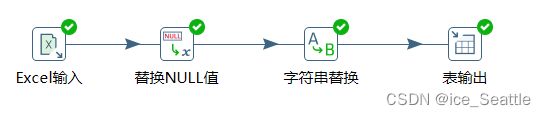
对数据内容稍加处理即可获取数据

(2)使用python,本程序添加了GUI界面
# _*_ coding:utf-8 _*_
# @Time : 2022/9/29 19:02
# @Author : ice_Seattle
# @File : 发票贴贴追加.py
# @Software: PyCharm
import re
import tkinter as tk
import MySQLdb
import pandas as pd
import time as t
from tkinter import *
from tkinter import scrolledtext
judge = []
def database_info():
global db, cursor, table
db = MySQLdb.connect("localhost", "root", "489000", "Fapiao", charset='utf8')
cursor = db.cursor()
cursor.execute("SELECT VERSION()")
version = cursor.fetchone()
print("Database version : %s " % version)
table = "fapiao"
def anomaly_detection(sql):
try:
if cursor.execute(sql):
alert = 'Affected rows: 1!\n'
judge.append(alert)
print(alert)
except Exception as e:
alert = str(e) + '\nERROR:主键约束限制,添加失败\n'
judge.append(alert)
print(alert)
class DBUtils:
def __init__(self, db, cursor, data, table):
self.db = db
self.cursor = cursor
self.data = data
self.table = table
# 按主键去重追加更新
def insert_data(self):
fapiao_data = []
for r in range(0, len(data.columns)):
fapiao_data.append(data.loc[0][r])
values = ', '.join(map(str, fapiao_data)) # * len(self.data.columns)
values.replace('合计', "")
values = re.sub('[0-9.]*[\n]¥', '¥', values, 2) # \d*.\d*\n¥
values = values.split(', ')
txt_path = 'E:/py/learn info/信息录入.txt'
# 删除原表数据, 隔绝上一次运行的追加信息
f_data = open(txt_path, "r+")
f_data.truncate()
# 刷新并生成本次调用的日志文件数据
for i in range(0, len(data.columns)):
with open(txt_path, 'a+', encoding='utf-8') as f:
print(f"'{values[i]}',", file=f) # end=''
# 拼接插入语句
x = "'"
for a in values[0:-1]:
x += str(a)+"', '"
x += str(values[-1])+"'"
values = x
# print(values)
global sql_1, sql_3
sql_1 = """INSERT INTO {table} VALUES ({values}) """.format(table=self.table, values=values)
# print(sql_1, '\n')
# anomaly_detection(sql_1)
print("表中数据如下:")
global list1
list1 = []
sql_2 = f"""select * from {table}"""
cursor.execute(sql_2)
for i in range(1, 10000):
sql_2 = cursor.fetchone()
if sql_2 is None:
break
else:
for j in range(1, len(sql_2)+1):
list1.append(sql_2[j - 1])
print(sql_2)
sql_3 = """COMMIT;""" # 若不执行,数据库中不显示
cursor.execute(sql_3)
def fapiao_gui():
# 添加文本区
sql_1_ares = scrolledtext.ScrolledText(window, width=100, height=10)
sql_1_ares.place(x=15, y=285, width=650)
def clear_content():
sql_1_ares.delete('1.0', END)
def in_data():
p = l.get()
anomaly_detection(p)
anomaly_detection(sql_3)
sql_1_ares.insert(INSERT, judge[0])
judge.clear()
def refresh():
DBUtils.insert_data(DBUtils(db, cursor, data, table))
fapiao_gui()
l = tk.Entry()
l.place(x=45, y=215, width=600)
l.insert(INSERT, sql_1)
lb3 = Label(window, text="SQL", font=('微软雅黑', 8))
lb3.place(x=15, y=215, width=30)
lb = Label(window, text="执行SQL语句结果", font=('微软雅黑', 8),
width=1, height=1, # 标签内容大小
padx=0, pady=1, borderwidth=1)
lb.place(x=15, y=260, width=100)
btn_execute = Button(window, text="Execute", bg="black", fg="white",
command=lambda: in_data())
btn_execute.place(x=680, y=370, width=100)
btn_clear = Button(window, text="Clear", bg="black", fg="white",
command=lambda: clear_content())
btn_clear.place(x=680, y=320, width=100)
lb2 = Label(window, text="数据库中fapiao表内容", font=('微软雅黑', 8))
lb2.place(x=195, y=10, width=120)
sql_2_ares = scrolledtext.ScrolledText(window)
sql_2_ares.place(x=195, y=35, width=550)
sb = Scrollbar(sql_2_ares, orient=HORIZONTAL) # 设置滚动条
sb.pack(side=BOTTOM, fill=X, padx=2) # 滚动条位置
sql_list = tk.Listbox(sql_2_ares, xscrollcommand=sb.set, width=550, height=5)
# 当窗口改变大小时会在X与Y方向填满窗口
sql_list.pack(side=LEFT, fill=BOTH)
list_group = 30
index = []
def fapiao_every(n):
for k in range(0, n, list_group):
index.append(str(k))
return index
fapiao_every(3000)
print(len(index))
count = len(list1)/list_group
for i in range(0, len(index)-1):
j = i+1
if i < len(index):
sql_list.insert(END, list1[int(index[i]):int(index[j])])
else:
count = count + 1
break
# 使用command关联控件的xview方法
sb.config(command=sql_list.xview)
btn_refresh = Button(window, text="Refresh", bg="black", fg="white",
command=lambda: refresh())
btn_refresh.place(x=680, y=210, width=100)
lb_info = Label(window, text=f"[{count} rows * 30 columns]", bg='#cde6c7', font=('微软雅黑', 8)) # bg='#7bbfea'
lb_info.place(x=15, y=40, width=160, height=80)
window.mainloop() # 执行窗体
# 打开数据库连接
global db, cursor, table
global sql_1, sql_3
global list1
database_info()
# 读取数据集
file_path = r'./发票/北京增值税电子普通发票011002100711.xlsx'
data = pd.read_excel(file_path, index_col=False)
data.fillna(" ", inplace=True, method=None) # 替换NaN,否则数据写入时会报错,也可替换成其他
# print(data) # Dataframe
t1 = t.time()
DBUtils.insert_data(DBUtils(db, cursor, data, table))
t2 = t.time()
t_end = t2-t1
print('用时', round(t_end, 2), 's')
window = Tk() # 常见窗口对象
window.title("发票信息追加到数据库") # 添加窗体名称
window.geometry('800x450+380+200') # 设置窗体大小
window.resizable(width=False, height=False)
fapiao_gui()
cursor.close()
db.close()运行以上得到:
Database version : 8.0.29
表中数据如下:
('天津增值税电子普通发票', '12002000411', '8133587', '2021年03月08日', '2930361211675111161', '499099255104', '上海艺赛旗软件股份有限公司', '91310105572715984J', ' ', ' ', '0313*<31+-5>1+>>>0*>3*66*9*<74*<5+-7666>>2+358/-609>*051+16>0-488657216*/995-317>-5>>8557+*33701067319+/<2332589', '*运输服务*客运服务费', ' ', '次', '1', '34.33', '¥34.33', '3%', '¥1.03', '叁拾伍圆叁角陆分', '¥35.36', '滴滴出行科技有限公司', '911201163409833307', '天津经济技术开发区南港工业区综合服务区办公楼C座103室12单元022-59002850', '招商银行股份有限公司天津自由贸易试验区分行122905939910401', ' ', '张雪丽', '王慧颖', '王秀丽', '(章)')
用时 0.01 s
100

执行Execute 一次

执行refresh刷新,并执行Execute 三次的效果

clear为清除执行SQL语句结果这栏的列表数据,其列表为异常try expect 数据得到的judge列表
因我在发票代码和发票号码中添加了主键约束,所以当再次执行SQL时,会提示并限制
在SQL文本框中修改第二个数据11002100711将末尾11改成22并Execute执行一次
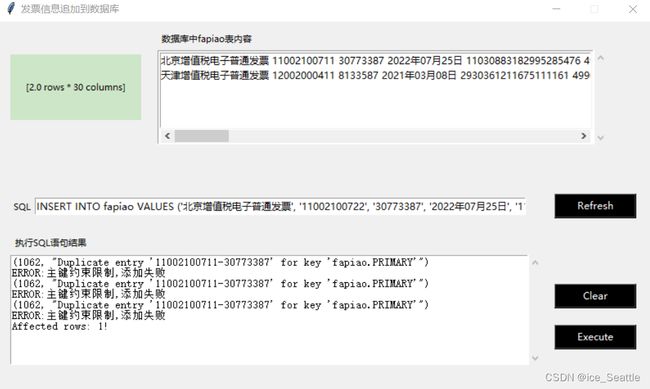
refresh刷新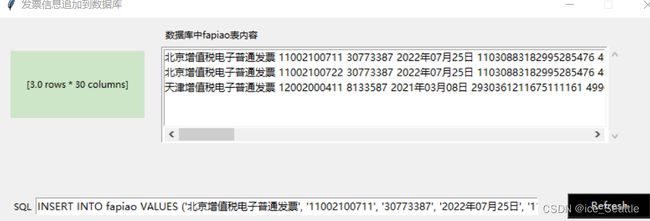
其在数据库中
由于在执行SQL中同时默认执行了COMMIT的,所以可以在数据库中成功添加,否则不显示
程序实现意义:在python中制作语句模板,增加对数据库操作的便捷性,正常情况下,对查询的表,语句,信息并没有集中在一个界面,并且需要反复调用,目的是为了简化操作,由于结合了pandas,所以可以直接读取数据并做替换,数据清洗,生成语句等操作,对于大量数据的写人可以增加准确性并减少人工操作。