Stanford-CS231n-assignment1-SVM及向量化梯度详解
首先贴代码,后面会着重讲解SVM的向量化求梯度,
Q2. Linear_SVM.py
from builtins import range
import numpy as np
from random import shuffle
from past.builtins import xrange
def svm_loss_naive(W, X, y, reg):
"""
Structured SVM loss function, naive implementation (with loops).
Inputs have dimension D, there are C classes, and we operate on minibatches
of N examples.
Inputs:
- W: A numpy array of shape (D, C) containing weights.
- X: A numpy array of shape (N, D) containing a minibatch of data.
- y: A numpy array of shape (N,) containing training labels; y[i] = c means
that X[i] has label c, where 0 <= c < C.
- reg: (float) regularization strength
Returns a tuple of:
- loss as single float
- gradient with respect to weights W; an array of same shape as W
"""
dW = np.zeros(W.shape) # initialize the gradient as zero
# compute the loss and the gradient
num_classes = W.shape[1]
num_train = X.shape[0]
loss = 0.0
for i in range(num_train):
scores = X[i].dot(W)
correct_class_score = scores[y[i]] #对应标签的那一列的得分
for j in range(num_classes):
if j == y[i]:
continue #在正确分类的那一次跳过计算边界
margin = scores[j] - correct_class_score + 1 # note delta = 1
if margin > 0: # 如果错误分类的得分值在正确得分的分值上的差值在1以内或者比正确得分还要高
loss += margin
dW[:, y[i]] += -X[i].T
dW[:, j] += X[i].T
# Right now the loss is a sum over all training examples, but we want it
# to be an average instead so we divide by num_train.
loss /= num_train
dW /= num_train
# Add regularization to the loss.
loss += reg * np.sum(W * W) #W*W是元素相乘,np.sum()把所有元素相加得到一个数,如果带上axis=0/1,才会求每行/每列的和
#############################################################################
# TODO: #
# Compute the gradient of the loss function and store it dW. #
# Rather that first computing the loss and then computing the derivative, #
# it may be simpler to compute the derivative at the same time that the #
# loss is being computed. As a result you may need to modify some of the #
# code above to compute the gradient. #
#############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
dW += 2 * reg * W
pass
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return loss, dW
def svm_loss_vectorized(W, X, y, reg):
"""
Structured SVM loss function, vectorized implementation.
Inputs and outputs are the same as svm_loss_naive.
"""
loss = 0.0
dW = np.zeros(W.shape) # initialize the gradient as zero
num_train = X.shape[0]
scores = X.dot(W) #scores是一个N*10的矩阵
#############################################################################
# TODO: #
# Implement a vectorized version of the structured SVM loss, storing the #
# result in loss. #
#############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
correct_scores = scores[np.arange(num_train), y] #按顺序把scores的每一行与标签相对应起来,取出scores矩阵中每一行正确分类的那一项的得分,然后得到N*1的行向量
print('correct_scroe\' shape is', correct_scores.shape)
correct_scores = correct_scores.reshape((num_train,-1)) #将correct_scores转换成N*1的列向量
margins = scores - correct_scores + 1
# 两种方法取出margins中大于0的部分
# 方法一
mask = margins > 0 # mask是一个由TRUE和FALSE组成的矩阵
margins = margins * mask # 对应元素相乘,TRUE代表1,FALSE代表0
# 方法二
margins_two = np.maximum(margins, 0) # 直接比较矩阵中元素与0的大小
loss += np.sum(margins)-num_train # 在margins=scores-correct_scores+1,碰到正确分类的时候,由于scores-correct_scores+1=1,每一次都给Loss多加了1,所以这里要减去分类正确时候多加的num_train个1
loss /= num_train
loss += reg*np.sum(W*W)
pass
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
#############################################################################
# TODO: #
# Implement a vectorized version of the gradient for the structured SVM #
# loss, storing the result in dW. #
# #
# Hint: Instead of computing the gradient from scratch, it may be easier #
# to reuse some of the intermediate values that you used to compute the #
# loss. #
#############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
mask_ones = np.ones_like(scores) # mask_ones是shape和scores相同的全为1的矩阵
mask_ones = mask_ones * mask # 得到对loss有影响的参数的分布矩阵,这个矩阵中每一行上的Wj(j是列号)求偏导所得值是相同的,都是Xi(i是行号)
mask_sum_row = (np.sum(mask_ones, axis = 1) - 1) # 对每一行求和
mask_ones[np.arange(num_train), y] = -mask_sum_row # 根据公式margin=sj-syi+1,要用每一行分类错-1的数量来更新Wyi
dW = 1/num_train * np.dot(X.T,mask_ones) + 2*reg*W # 用XT来乘以mask矩阵,得到每一次更新时候W每一列所需要加上的Xi的值,因为S的每一行都是由不同的Xi乘以同一个Wj所得到的,所以在更新W的一列时,要遍历所有Xi
pass
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return loss, dW
个人觉得SVM的向量化实现有些抽象,所以着重解释一下向量化实现每一句代码的意思,也便于加深自己的理解,
首先SVM这个loss function就有点怪,是个不光滑的函数,不方便直接求导,所以就感觉有点怪,具体函数如下图:

首先,先看一下用循环的方法迭代计算的过程:
def svm_loss_naive(W, X, y, reg):
"""
Structured SVM loss function, naive implementation (with loops).
Inputs have dimension D, there are C classes, and we operate on minibatches
of N examples.
Inputs:
- W: A numpy array of shape (D, C) containing weights.
- X: A numpy array of shape (N, D) containing a minibatch of data.
- y: A numpy array of shape (N,) containing training labels; y[i] = c means
that X[i] has label c, where 0 <= c < C.
- reg: (float) regularization strength
Returns a tuple of:
- loss as single float
- gradient with respect to weights W; an array of same shape as W
"""
dW = np.zeros(W.shape) # initialize the gradient as zero
# compute the loss and the gradient
num_classes = W.shape[1]
num_train = X.shape[0]
loss = 0.0
for i in range(num_train):
scores = X[i].dot(W)
correct_class_score = scores[y[i]] #对应标签的那一列的得分
for j in range(num_classes):
if j == y[i]:
continue #在正确分类的那一次跳过计算边界
margin = scores[j] - correct_class_score + 1 # note delta = 1
if margin > 0: # 如果错误分类的得分值在正确得分的分值上的差值在1以内或者比正确得分还要高
loss += margin
dW[:, y[i]] += -X[i].T
dW[:, j] += X[i].T
# Right now the loss is a sum over all training examples, but we want it
# to be an average instead so we divide by num_train.
loss /= num_train
dW /= num_train
# Add regularization to the loss.
loss += reg * np.sum(W * W) #W*W是元素相乘,np.sum()把所有元素相加得到一个数,如果带上axis=0/1,才会求每行/每列的和
#############################################################################
# TODO: #
# Compute the gradient of the loss function and store it dW. #
# Rather that first computing the loss and then computing the derivative, #
# it may be simpler to compute the derivative at the same time that the #
# loss is being computed. As a result you may need to modify some of the #
# code above to compute the gradient. #
#############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
dW += 2 * reg * W
pass
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return loss, dW
这里的做法就相当于是对 这个函数进行求导,因为我们知道在SVM中,只有间隔超过一定距离(大间距分类器),才会对Loss function产生影响(也就是式子中otherwise的情况),否则对Loss function没有影响,所以在上面的代码中判断if margin > 0才对权重W进行更新,因为若margin小于零,这时候这一项根本不会对Loss function产生影响,所以也就不会来反向更新W的权重了。
这个函数进行求导,因为我们知道在SVM中,只有间隔超过一定距离(大间距分类器),才会对Loss function产生影响(也就是式子中otherwise的情况),否则对Loss function没有影响,所以在上面的代码中判断if margin > 0才对权重W进行更新,因为若margin小于零,这时候这一项根本不会对Loss function产生影响,所以也就不会来反向更新W的权重了。
然后由矩阵乘法知道,因为S=XW,所以Sij是由X的第i行与W的第j列相乘而得到的,而上述代码中的margin是由S矩阵的第i行的第j列与正确分类的那一列(也就是Syi)所作比较得出的一个变量,当margin>0时,说明第i行的这一列分类错误且错误足够大,因此要更新W的值,那么怎么更新呢?
这个时候根据式![]() ,这个式子可以写为
,这个式子可以写为![]() ,这样看起来比较直观,这时候对W求偏导,可以得到,对于
,这样看起来比较直观,这时候对W求偏导,可以得到,对于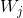 这一列,要通过加上
这一列,要通过加上![]() 来进行更新,而对于
来进行更新,而对于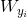 这一列,要通过减去
这一列,要通过减去![]() 来进行更新,所以也就出现了这两行代码:
来进行更新,所以也就出现了这两行代码:
dW[:, y[i]] += -X[i].T
dW[:, j] += X[i].T这样明白了循环更新的方式之后,向量化的理解就变得容易一些了,下面来看向量化的更新方式,先看代码(前面的代码中都有注释详细解释每一步的过程),
mask_ones = np.ones_like(scores) # 1
mask_ones = mask_ones * mask # 2
mask_sum_row = (np.sum(mask_ones, axis = 1) - 1) # 3
mask_ones[np.arange(num_train), y] = -mask_sum_row # 4
dW = 1/num_train * np.dot(X.T,mask_ones) + 2*reg*W # 5首先第一行,生成了一个模板矩阵,按照scores矩阵的shape生成一个全是1的mask_ones矩阵,这里为什么要用1作为矩阵元素,因为![]() 这个式子中求偏导所得到的系数都是1,所以直接用1来作矩阵元素
这个式子中求偏导所得到的系数都是1,所以直接用1来作矩阵元素
然后通过模板mask(前面代码中得到的矩阵)来把这个mask_ones中的对loss function有影响的项留下,其余项置为0,
第三步,对每一行求和然后减去1,这么做是因为每一次迭代更新中,都会对分类正确的那一项进行更新,这个减去1是因为正确分类(正确分类时maigin的值是1)的情况也被算在了计算loss值的式子里面(每一行都有且仅有一个正确分类,下图中W2是正确的项),
然后第四步,其中mask_ones[np.arange(num_train), y]这一句是对mask_ones中分类正确的部分进行赋值,把第三步求出的值的相反数赋给矩阵中对应的这些元素,
当把分类正确的部分的梯度求出之后,再来求分类不正确且对Loss function有影响的部分,也就是第五步,
第五步,首先X矩阵的每一行代表衣服图片所有像素组成的向量,也就是一个train_data,这个时候对X进行转置,转置之后那么就是一列代表一个train_data(例如X1、X2等等),这时候再来看mask_ones矩阵,在mask_ones矩阵中除了第四步赋值改变的一些元素以外,其余元素都与原来保持不变,那么这个时候我们单独取出mask_ones中的一行来看(这样容易理解),
例如第一列是![]() 这样的向量,那么如果我们用
这样的向量,那么如果我们用![]() 这个矩阵去乘这个向量,就得到
这个矩阵去乘这个向量,就得到![]() 这个列向量,同理,对于后面的每一列都可以得到这样一个列向量,然后把这些列向量在对应的W矩阵中的列加起来,就可以得到更新后的W_grad矩阵了。
这个列向量,同理,对于后面的每一列都可以得到这样一个列向量,然后把这些列向量在对应的W矩阵中的列加起来,就可以得到更新后的W_grad矩阵了。