简单三层全连接神经网络(普通,添加激活函数、添加批标准化)的构建及训练,nn.Linear()、tensorboard、time、的简单使用(没有废话,全部知识)
一、定义模型
对于一个三层网络需要传进去的参数:输入的维度,第一层网络神经元的个数,第二层网络神经元的个数,输出层神经元个数
先看一下普通版:
nn.Linear(inputs,output,bais)#Applies a linear transformation to the incoming data: :math:`y = xA^T + b`
对传入的数据进行线性变换
inputs:输入尺寸
output:输出尺寸
bais:偏置,默认为True
from torch import nn
class lixiang_1(nn.Module):
def __init__(self,in_dim,n_hidden_1,n_hidden_2,out_dim):
super(lixiang_1, self).__init__()
self.layer1 = nn.Linear(in_dim,n_hidden_1)
self.layer2 = nn.Linear(n_hidden_1,n_hidden_2)
self.layer3 = nn.Linear(n_hidden_2,out_dim)
def forward(self,inputs):
outputs = self.layer1(inputs)
outputs = self.layer2(outputs)
outputs = self.layer3(outputs)
return outputs
进阶版(增加激活函数):
# 添加激活函数
class lixiang_2(nn.Module):
def __init__(self,in_dim,n_hidden_1,n_hidden_2,out_dim):
super(lixiang_2, self).__init__()
self.layer1 = nn.Sequential(
nn.Linear(in_dim,n_hidden_1),
nn.ReLU(True)
)
self.layer2 = nn.Sequential(
nn.Linear(n_hidden_1,n_hidden_2),
nn.ReLU(True)
)
self.layer3 = nn.Sequential(
nn.Linear(n_hidden_2,out_dim),
)#最后一层输出层不能添加激活函数,因为输出的结果就表示得分
def forward(self,inputs):
outputs = self.layer1(inputs)
outputs = self.layer2(outputs)
outputs = self.layer3(outputs)
return outputs
解释:nn.Squeential()函数的用法是将网络的层组合到一起
最终版(在进阶版的基础上添加批标准化):
class lixiang_3(nn.Module):
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(lixiang_3, self).__init__()
# 批标准化一般放在全连接层后面 ,激活函数的前面
self.layer1 = nn.Sequential(
nn.Linear(in_dim, n_hidden_1),
nn.BatchNorm1d(n_hidden_1),
nn.ReLU(True)
)
self.layer2 = nn.Sequential(
nn.Linear(n_hidden_1, n_hidden_2),
nn.BatchNorm1d(n_hidden_2),
nn.ReLU(True)
)
self.layer3 = nn.Sequential(
nn.Linear(n_hidden_2, out_dim)
)
def forward(self, inputs):
outputs = self.layer1(inputs)
outputs = self.layer2(outputs)
outputs = self.layer3(outputs)
return outputs
解释:在这个网络中需要注意的是批标准化一般放在全连接层的后面,非线性层(激活函数)的前面
将上述模型保存为net.py
二、训练:
(1)导入一些包:
import torch
from net import * #网路模型保存在里面
from torch import optim #优化
from torch.autograd import Variable #提供自动求导功能
from torch.utils.data import DataLoader#加载数据
from torchvision import datasets,transforms
import time #计算训练时间
from torch.utils.tensorboard import SummaryWriter#使其能够看到训练时的数据
(2)定义超参数:
参数定义后面调用的时候会提到
batch_size , learning_rate , num_epoches = 64, 1e-2, 20
(3)数据预处理:
# 数据预处理
data_tf = transforms.Compose([transforms.ToTensor(),
transforms.Normalize([0.5],[0.5])])
transforms.Compose()的用法是将各种预处理操作组合到一起。ToTensor()很好理解,就是把图片转化为pytorch处理对象Tensor型(Tensor类型的范围是0~1)。
Normalize(),这个函数需要传入两个参数:第一个是均值,第二个是方差,处理就是减去均值,再除以方差。(本次所使用的为灰度图,只有一个通道,若是彩色图片三个通道则([a,b,c],[d,e,f])来表示每个通道对应的均值和方差)
(4)加载数据
我们这里所使用的是MNIST手写数字训练集(灰度图)
# 读取数据集
train_dataset = datasets.MNIST(root='./data',train=True,transform=transforms.ToTensor(),
download=True)
test_dataset = datasets.MNIST(root='./data',train=False,transform=transforms.ToTensor(),
download=True)
#当train为True表示为训练集,False表示测试集,download:表示是否要下载数据集。默认为True
train_loader = DataLoader(train_dataset,batch_size=batch_size,shuffle=True)
test_loader = DataLoader(test_dataset,batch_size=batch_size,shuffle=True)
#batch_size 就是每一次多少图片,shuffle:为是否要打乱顺序
# img,target = test_dataset[0]
# print(img.shape)
# print(target.size())
(5)实例化网络,定义损失函数,优化器
# 导入网络,定义损失函数,优化方法
model = lixiang_2(28*28,300,100,10)
if torch.cuda.is_available():#判断gpu是否可用
model = model.cuda()
loss_1 = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr = learning_rate)
(6)训练前需要准备的一些参数:
# length长度
train_data_size = len(train_dataset)
test_data_size = len(test_dataset)
print('训练数据集的长度为{}'.format(train_data_size))
print('测试数据集的长度为{}'.format(test_data_size))
# 记录训练的次数
total_train_step = 0
# 记录测试次数
total_test_step = 0
(7)使用tensorboard 并开始计时
# 添加tensorboard
writer = SummaryWriter('./logs_train')
# 计时
start_time = time.time()
(8)训练和测试:
for epoch in range(num_epoches):
print('----------第{}轮训练开始-----------'.format(epoch+1))
#训练
for data in train_loader:
imgs, targets = data
imgs = imgs.view(imgs.size(0), -1)
if torch.cuda.is_available():
imgs = Variable(imgs).cuda()
targets = Variable(targets).cuda()
else:
imgs = Variable(imgs)
targets = Variable(targets)
outputs = model(imgs)
loss = loss_1(outputs,targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
end_time = time.time()
print(end_time - start_time)
print('训练次数;{},Loss:{}'.format(total_train_step, loss.item())) # .item 返回真实值
writer.add_scalar('train_loss', loss.item(), total_train_step)
#测试
print('----------第{}轮测试开始-----------'.format(epoch + 1))
model.eval()
total_test_acc = 0
total_test_loss = 0
with torch.no_grad(): #以下代码没有梯度
for data in test_loader:
imgs , targets = data
imgs = imgs.view(imgs.size(0),-1)
if torch.cuda.is_available():
imgs = Variable(imgs).cuda()
targets = Variable(targets).cuda()
else:
imgs = Variable(imgs)
targets = Variable(targets)
outputs = model(imgs)
loss = loss_1(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_test_acc += accuracy
print('整体测试集上的Loss: {} '.format(total_test_loss/test_data_size))
print('整体测试集上的正确率使{}'.format(total_test_acc / test_data_size))
writer.add_scalar('test_accury', total_test_acc / test_data_size, total_test_step)
writer.add_scalar('./test_loss', total_test_loss, total_test_step)
total_test_step += 1
(9)三个模型对应的结果准确率,损失:
普通模型结果:
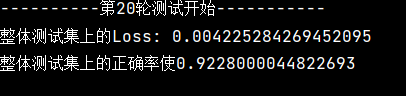
进阶版结果:

最终版结果:

通过三个模型运行结果的对比,可以知道模型设计的越好,其准确率越高,我们再设计模型的时候要尽量做到beautiful!
(10)tensorboard 再终端执行的命令:
![]()
打开终端按上图输入可得到下面的:

点击网站蓝色的,即可跳转: