机器学习——决策树
什么是决策树?
分类决策树模型是一种描述对实例进行分类的树形结构。 决策树由结点和有向边组成。结点有两种类型:内部结点和叶 节点。内部结点表示一个特征或属性,叶节点表示一个类
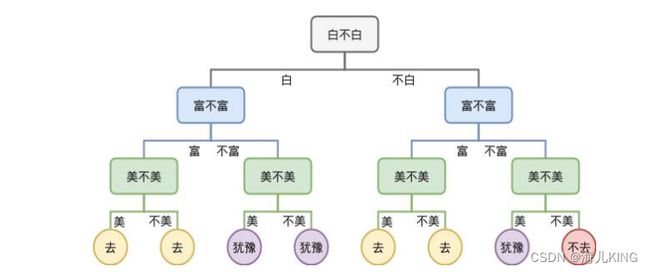
# 相亲角
#
# ID 白 富 美
# 1 0 0 0
# 2 0 0 1
# 3 0 1 0
# 4 0 1 1
# 5 1 0 0
# 6 1 0 1
# 7 1 1 0
# 8 1 1 1
from math import log
import operator
def calcShannonEnt(dataSet):
numEntries=len(dataSet)
labelCounts={}
for featVec in dataSet:
currentLabel=featVec[-1] #提取标签信息
if currentLabel not in labelCounts.keys(): #如果标签没有放入统计次数的字典,添加进去
labelCounts[currentLabel]=0
labelCounts[currentLabel]+=1 #label计数
shannonEnt=0.0 #经验熵
for key in labelCounts:
prob=float(labelCounts[key])/numEntries #选择该标签的概率
shannonEnt-=prob*log(prob,2) #利用公式计算
return shannonEnt #返回经验熵
def createDataSet():
dataSet=[[0, 0, 0, 'no'],
[0, 0, 1, 'maybe'],
[0, 1, 0, 'yes'],
[0, 1, 1, 'yes'],
[1, 0, 0, 'maybe'],
[1, 0, 1, 'maybe'],
[1, 1, 0, 'yes'],
[1, 1, 1, 'yes']]
labels=['白','富','美','去否']
return dataSet,labels
def splitDataSet(dataSet,axis,value):
retDataSet=[]
for featVec in dataSet:
if featVec[axis]==value:
reduceFeatVec=featVec[:axis]
reduceFeatVec.extend(featVec[axis+1:])
retDataSet.append(reduceFeatVec)
return retDataSet
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet))
newEntropy += prob * calcShannonEnt((subDataSet))
infoGain = baseEntropy - newEntropy
print("第%d个特征的增益为%.3f" % (i, infoGain))
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
def majorityCnt(classList):
classCount={}
for vote in classList:
if vote not in classCount.keys():
classCount[vote]=0
classCount[vote]+=1
sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet,labels,featLabels):
classList=[example[-1] for example in dataSet]
if classList.count(classList[0])==len(classList):
return classList[0]
if len(dataSet[0])==1:
return majorityCnt(classList)
bestFeat=chooseBestFeatureToSplit(dataSet)
bestFeatLabel=labels[bestFeat]
featLabels.append(bestFeatLabel)
myTree={bestFeatLabel:{}}
del(labels[bestFeat])
featValues=[example[bestFeat] for example in dataSet]
uniqueVls=set(featValues)
for value in uniqueVls:
myTree[bestFeatLabel][value]=createTree(splitDataSet(dataSet,bestFeat,value),
labels,featLabels)
return myTree
if __name__=='__main__':
dataSet,labels=createDataSet()
featLabels=[]
myTree=createTree(dataSet,labels,featLabels)
print(myTree)
运行输出
第0个特征的增益为0.156
第1个特征的增益为1.000
第2个特征的增益为0.156
第0个特征的增益为0.311
第1个特征的增益为0.311
第0个特征的增益为1.000
{'富': {0: {'白': {0: {'美': {0: 'no', 1: 'maybe'}}, 1: 'maybe'}}, 1: 'yes'}}
Process finished with exit code 0