ECCV2022_Point-to-Box Network for Accurate Object Detection via Single Point Supervision 论文阅读
ECCV2022_P2BNet 论文阅读
文章目录
- ECCV2022_P2BNet 论文阅读
-
- 0 Abstract
-
- **0-1 MIL:multiple instance learning(多示例学习)**
- 1 Introduction
-
- **1-0 WSOD:weakly supervised object detection(弱监督对象检测)**
- 2 Contributions
-
- **2-0 P2BNet**
- **2-1 A coarse-to-fine fashion**
- **2-2 Performance**
- 3 Point-to-Box Network
-
- **3-0 Architecture**
- **3-1 Loss**
-
- 3-1-0 the loss of P2BNet
- **3-2 Coarse Pseudo Box Prediction**
-
- 3-2-0 CBP Sampling
- 3-2-1 CBP Module
- 3-2-2 CBP Loss
- 3-2-3 one-hot(独热编码)
- 3-2-4 Anchor
- 3-2-5 top-k归并策略
- **3-3 Pseudo Box Refinement**
-
- 3-3-0 PBR Sampling
- 3-3-1 PBR Module
- 3-3-2 PBR Loss
- 3-3-3 backbone
- 4 Experiments
-
- **4-0 Experiment Settings**
-
- 4-0-0 Datasets and Evaluate Metrics
- 4-0-1 Implementation Details
- 4-0-2 Quasi-Center Point Annotation *
- 4-0-3 Box Merging Policy
- **4-1 Performance Comparsions**
- **4-2 Ablation Study**
-
- 4-2-0 Training Loss in P2BNet
- 5 Conclusion
- 6 Appendix
0 Abstract
由于现成的提案(OTSP)未能生成高质量的候选框,而且候选框又对于多示例学习(MIL)十分重要,这会导致比较大的性能差异。为了解决这个问题,我们引入了一种轻量级的替代方案(P2BNet)。它可以通过以锚一样的方式生成提案开构造一个对象间平衡的提案包,通过充分研究准确的位置信息,P2BNet进一步构建了实例级包,避免了多个对象的混合。最后,采用从粗到细的级联策略来改善候选框和真值之间的IoU
0-1 MIL:multiple instance learning(多示例学习)
| MIL:multiple instance learning(多示例学习) |
|---|
| ***说明:*与监督学习,半监督学习和非监督学习有所不同,它是以多示例包(bag)**为训练单元的学习问题。在多示例中,多示例包bag(图像)的label是已知的(训练集给定的),但是示例instance(分割区域)的label是未知的 |
| 训练集***:由一组有分类标签*的多实例包(bag)组成,每个多包(bag)包含若干没有分类标签的示例(instance)。如果多示例包(bag)至少含有一个正示例(instance),则该包被标记为正类多示例包(正包)。如果多示例包的所有示例都是负示例,则该包被标记为负类多示例包(负包) |
| 目的***:通过对具有分类标签的多示例包的学习,建立多示例分类器*,并将该分类器应用于未知多示例包的预测。困难之处在于,每个多示例包含有若干个示例(向量),只有多示例包(图像)的label是已知的,多示例包中的示例(分割区域)的label是未知的 |
1 Introduction
精确边界框标注训练的物体检测器虽然很受好评,但是非常消耗人力。为此,**弱监督对象检测(WSOD)**使用了低成本的图像级注释替换边界框注释。但是由于缺乏关键的位置信息和难以区分密集的目标,WSOD方法在复杂场景下的表现很差。
1-0 WSOD:weakly supervised object detection(弱监督对象检测)
| WSOD:weakly supervised object detection(弱监督对象检测) |
|---|
| ***弱监督学习:***数据集仅带有数据类别的标签,不包含坐标信息 |
| 目的:在仅有图像类别的标注情况下,训练一个目标检测器 |
点监督方法与边界盒监督方法的性能差距仍然很大,我们不认为”边界框提供的位置信息更丰富“是唯一原因,我们认为大多数的PSOD方法并没有去充分利用基于点的注释的潜力。
曾经的OSTP方法存在着以下的缺点:
- 包中的背景建议太多。OSTP方法生成了太多与前置物体没有交集的proposal
- 每个对象的正proposal不平衡,有些太多,有些太少
- 包中的大部分proposal的IoU非常低,表示proposal的质量非常差
- 以往的PSOD方法只构造图像级的包,在MIL训练时无法利用点注释,导致不同的对象混合在一个包中
因此,我们提出了P2BNet作为OTSP方法的替代方案,用以生成高质量的object proposals。P2BNet生成的proposal数量对每个对象进行了平衡,他们涵盖了不同的规模和纵横比。此外,the proposal bags是实例级的而不是图像级的。为了进一步提升包的质量,P2BNet采用了级联方式设计了粗-细工序。改进阶段包括粗伪盒预测(CBP)和精确伪盒改进(PBR)两个部分。其中,CBP阶段预测物体的粗尺度(宽度和高度),PBR阶段迭代微调尺度和位置。我们的P2BNet生成高质量、平衡的建议包,并确保在所有阶段(MIL训练前、时、后)的点注释的贡献。
2 Contributions
2-0 P2BNet
是为预测伪盒而设计的。它是一个生成的、无OTSP的网络。他生成对象间平衡的实例级包,有利于更好地优化MIL训练。P2BNet比OTSP更节约时间。
2-1 A coarse-to-fine fashion
基于CBP和PBR阶段,以获得更高质量的建议包和更好的预测
2-2 Performance
检测性能大大提高
3 Point-to-Box Network
P2BNet-FR框架由P2BNet和Faster R-CNN(FR)组成。P2BNet把点标注转化为伪框标注,并使用预测出的伪框监督训练检测器FR。我们使用Faster R-CNN的标准设定,因此下文中我们详细描述P2BNet的细节。
3-0 Architecture
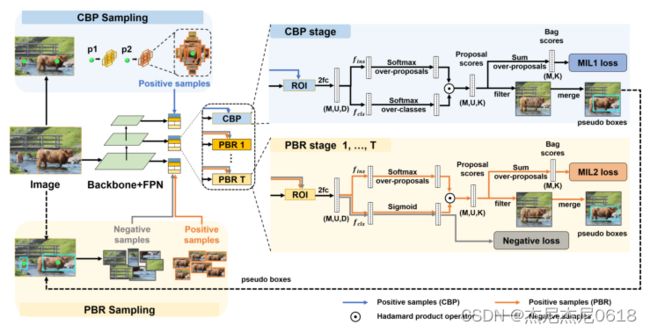
3-1 Loss
3-1-0 the loss of P2BNet
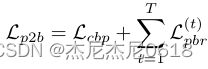
其中,PBR包含T次迭代,![]()
是第T次迭代的损失。
3-2 Coarse Pseudo Box Prediction
在CBP阶段,
- 以标注点作为框中心,以锚式的方式为每个对象生成不同宽度和高度的建议框。
- 提取样本建议框的体征,训练MIL分类器用于选择最适合object的建议框。
- 利用top-k归并策略估计粗伪盒
3-2-0 CBP Sampling
在标注点周围进行固定采样,以点注释p=(px,py),为中心,s为大小,v为纵横比,生成建议框b=(bx,by,bw,bh),即b=(px,py,v * s,1/v * s)
![]()
,其中 δ=min(W, H)/100,需要根据数据集进行动态调整,W,H分别为图片的宽和高。
![]()

通过调整s和v,每个点注释pj将生成一袋具有不同尺度和纵横比的建议框。s和v的设置将在后续补充说明。所有的建议包都将用于训练CBP模块中的MIL分类器,并以点的类别标签作为监督。
有时候,s太大会导致大部分的b在图像之外,会引入太多无意义的填充值。在这种情况下,我们剪辑b以确保其在图像之内(如上图所示)
3-2-1 CBP Module
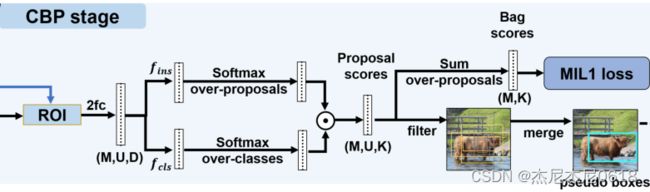
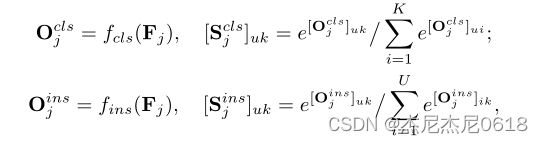

其中,cls为分类分支,ins为实例分支(如上图),特征![]()
是从7*7的RoIAlign和两个全连接层(fc)中提取出来的(如上图),其中U是包中建议框的数量,D是特征的维度。我们使用了WSDDN并设计了一个双流结构作为一个分类器来找到最好的边界框。如上图的第一个公式,我们先将Fj应用到分类分支中得到![]()
,其中K为实例类别的数量,然后将其通过一个激活函数得到分类分数![]()
,第二个公式也是如此,其中[-]uk表示矩阵的第u行,第k列。第三个公式的Sj是通过两个分数的哈达玛乘积(矩阵对应位置相乘)得到的。
3-2-2 CBP Loss
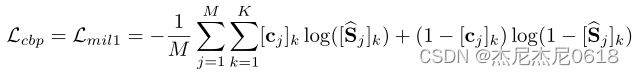
上述损失的定义方法采用的是交叉熵损失定义的形式。其中![]()
是点Pj的one-hot类别标签。CBP的损失是让每个proposal正确预测他所属的类别和实例。最终,对每个对象中建议得分最高的前k个盒子进行加权,得到粗伪盒子用于下面的PBR采样。
3-2-3 one-hot(独热编码)
又称一位有效编码。用N位状态寄存器对N个状态进行编码,每个状态都有自己独立的寄存器,并且在任意时候,其中只有一位有效。

3-2-4 Anchor
在图像上预设好的不同大小,不同长宽比的参照框。一个Anchor Box可以由:边框的纵横比和边框的面积(尺度)来定义,相当于一系列预设边框的生成规则
3-2-5 top-k归并策略
简单说明就是,在得分最高的前k个框中,只要有一个是ground truth,我们就认为这个框分类成功了
3-3 Pseudo Box Refinement
PBR阶段的目的是对伪盒的位置、宽度和高度进行微调,可以采用级联方式进行执行,以获得更好的性能。
因为正建议包是在局部区域生成的,所以可以在远离建议包的地方采样负样本来抑制背景。
PBR模块还对预测得分最高的前k个建议进行加权,得到改进后的伪盒,即P2BNet的最终输出。
3-3-0 PBR Sampling
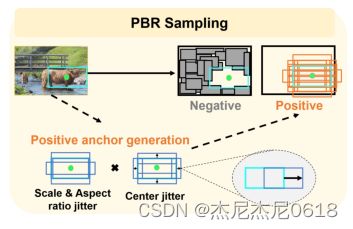
在估计的盒子周围进行自适应采样。

调整伪框
![]()
,![]()
,所以共有5*5=25种组合。
![]()
被用作去抖动伪框
这些较好的建议将被用做正建议包Bj去训练PBR模块。
为了更好的抑制样本,我们随机抽取许多建议盒,这些建议盒与所有包中的所有正面建议都有较小的IOU值(通常默认小于0.3),为PBR模块组成负样本集N。通过伪盒分布对建议盒进行抽样,可以得到更好优化的高质量建议盒。如下图所示:
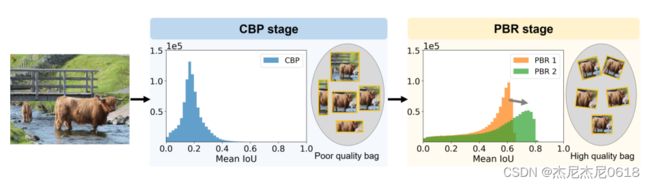
可以看到,mIoU在PBR阶段逐渐增加,说明建议包的质量在迭代细化中得到了提高。
3-3-1 PBR Module

3-3-2 PBR Loss

3-3-3 backbone
主干网络大多时候指的是提取特征的网络,其作用就是提取图片中的信息,共后面的网络使用。这些网络经常使用的是resnet,VGG等,而不是我们自己设计的网络,因为这些网络已经证明了在分类等问题上的特征提取能力是很强的。在用这些网络作为backbone的时候,都是直接加载官方已经训练好的模型参数,后面接着我们自己的网络。让网络的这两个部分同时进行训练,因为加载的backbone模型已经具有提取特征的能力了,在我们的训练过程中,会对他进行微调,使得其更适合于我们自己的任务。
4 Experiments
4-0 Experiment Settings
4-0-0 Datasets and Evaluate Metrics
该实验采用了MS COCO数据集。mIoUpred由训练集中所有对象的预测伪盒与其对应的的真值盒之间的平均IoU计算,它可以直接评估P2BNet将标注的点转换为准确的伪盒的能力。
4-0-1 Implementation Details
我们的P2BNet-FR代码是基于MMDetection的。采用随机梯度下降算法对1×训练计划进行优化。学习率设置为0.02,在第8个和第11个epochs分别衰减0.1,在P2BNet中,我们在训练时使用多尺度(480,576,688,864,1000,1200)作为短边来调整图像的大小,在推理时使用单尺度(1200)。我们选择经典的Faster R-CNN FPN(骨干为ResNet-50)作为默认设置的检测器,在训练和推断过程中使用单尺度(800)图像。
4-0-2 Quasi-Center Point Annotation *
我们提出了一种准中心(QC)点标注方法,该方法对目标检测任务友好且成本低。在实际场景中,我们要求标注者使用宽松规则在非高限制中心区域标注对象。由于实验中的数据集已经用边界框或掩码进行了标注,因此手工标注的点在中心区域遵循高斯分布是合理的。对于b=(bx,by,bw,bh)的边界框,其中心椭圆可定义为椭圆k,取(bx,by)为椭圆的圆心,
![]()
为椭圆的两轴。此外,考虑到在上述规则下,大物体的绝对位置偏移量太大,我们将两个轴限制在不超过96像素。如果物体的掩膜Mask与中心椭圆k重叠,则用V表示交集。如果没有相交区域,V代表整个Mask。从边界框注释生成时,盒被视为掩膜。RG的定义如下:

其中,µ和σ为RG的均值和标准差,p为点注释。本文采用RG(p;0,1/4,1/4)去生成QC点注释。
4-0-3 Box Merging Policy
我们使用前k分的平均权重作为合并策略。我们发现超参数k有点敏感,可以很容易地推广到其他数据集,并且只有top-1或top-f的建议框在框合并中起主导作用。当k = 4时,最佳性能为22.1 AP和47.3 AP50
4-1 Performance Comparsions
我们的P2BNet- fr框架的默认组件是P2BNet和Faster R-CNN。我们将P2BNet-FR与现有的PSOD方法进行比较,同时选择最先进的UFO2框架作为综合比较的基线。此外,为了演示PSOD方法的性能优势,我们将其与最先进的WSOD方法进行比较。同时,我们比较了盒监督目标检测器的性能,以反映它们的性能上限。
Table 1
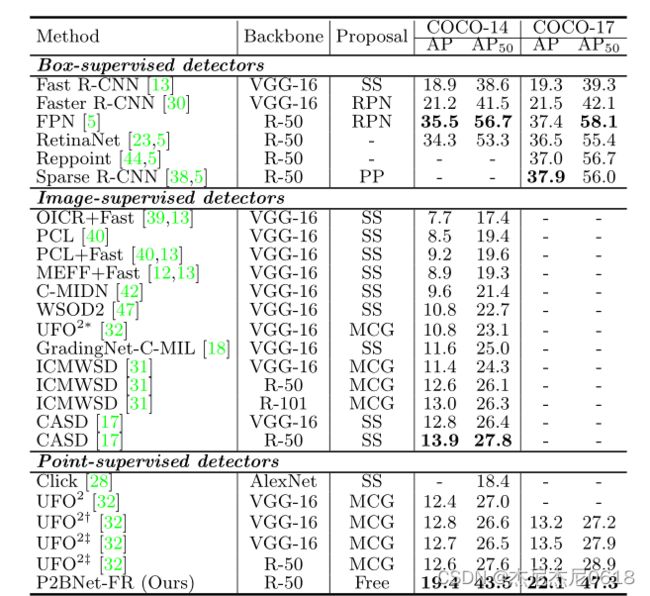
盒监督、图像监督和点监督检测器在COCO数据集上的性能比较。 *表示带有图像级注释的UFO2,†是指我们用原始设定重现的表现,‡意味着我们用QC点注释重新实现UFO2。SS为选择性搜索,PP为建议框,Free为基于OTSP-free的方法。
Comparison with PSOD Methods
本部分主要使用在COCO上使用了已知的Click和UFO2方法,如tab1所示。Click和UFO2都使用基于otsp的方法(SS或MCG)来生成建议框。由于UFO2使用的点注释与本文提出的QC点不同,为了进行公平的比较,我们使用我们的QC点注释在公共代码上重新训练UFO2。此外,以往的方法主要基于VGG-16或AlexNet。为了一致性,我们将UFO2扩展到ResNet-50 FPN主干,并将其与我们的框架进行比较。与Click和UFO2相比,我们的P2BNet-FR框架的性能大大优于它们。在COCO-14上,P2BNet-FR使AP和AP50分别提高6.8和15.9。此外,我们的框架在COCO-17上的性能显著优于最先进的8.9 AP和18.4 AP50。

如上图为P2BNet-FR和UFO2的可视化的探测结果。我们的P2BNet-FR能够很好地区分密集的物体,并在复杂的场景中表现良好。
Comparison with WSOD Methods
我们将提出的框架与表1中关于COCO-14的最新WSOD方法进行比较。P2BNet-FR的性能证明,与WSOD相比,PSOD在注释成本几乎没有增加的情况下,显著提高了检测性能,表明PSOD任务具有很大的发展前景。
Comparison with Box-Supervised Methods
为了验证P2BNet-FR在实际应用中的可行性,并显示这种监督方式下的上界,我们比较了表1中的盒监督检测器。
在AP50下,P2BNet-FR-R50 (47.3 AP50)比以往的WSOD和PSOD方法更接近盒监督检测器FPN-R50 (58.1 AP50)。研究表明,PSOD可应用于对盒的质量要求较低、更倾向于寻找对象的行业,大大降低标注成本。
4-2 Ablation Study
top-k中默认k=7
4-2-0 Training Loss in P2BNet
**1)CBP Loss:**为了进行比较,我们进行Lpos,将袋子中的所有提案盒视为阳性样本。我们发现它很难优化,性能很差,证明了我们提出的Lmil1对伪盒预测的有效性。粗建议包可以覆盖大多数高IoU的对象,丢失率低。但是由于尺度和纵横比比较粗,中心位置需要调整,因此还具有优化的潜力。
**2)PBR Loss:**仅Lmil2,性能仅为12.7 AP,性能下降的主要原因是级联方式的误差积累和缺乏焦损耗负样本。Sigmoid激活函数没有显式的负样本抑制背景,引入负采样和负损失Lneg。性能提高了9.0 AP和10.7 AP50,说明它是必不可少的,有效地提高了优化。我们还对mIoUpred进行了评估,讨论了预测伪盒的质量。在有Lmil2和Lneg的PBR阶段,mIoU从50.2增加到57.4,表明伪盒的质量更好。如果我们去掉策略路由阶段提案盒的抖动策略,性能下降到14.2 AP。如下图所示:
Table 3:
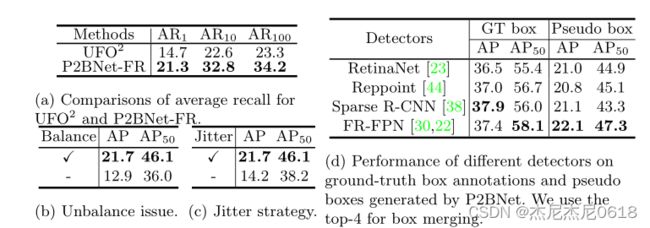
3)Average Recall:在表3(a)中,UFO2的AR为23.3,说明缺失率较高。而P2BNet-FR的AR值为34.2,远高于UFO2。这表明我们的无otsp方法在查找对象方面更好。
**4)Unbalance Sampling Analysis:**为了证明不平衡抽样的效果,我们对每个对象采样不同数量的建议框,表3(b)中的性能下降表明了不平衡采样的负面影响
**5)Different Detectors:**我们为完整性实验训练了不同的检测器,所有的实验都在R-50上进行。我们的框架在所有检测器上表现出具有竞争力的性能。列出了框监督性能以演示我们框架的上限。
5 Conclusion
本文深入分析了基于otsp的PSOD框架的不足,提出了一种新的无otsp网络P2BNet,以获得对象间平衡、高质量的提案包。由粗到细的策略将伪盒的预测分为CBP和PBR两个阶段。CBP阶段在标注点周围进行固定采样,通过实例级MIL对粗伪盒进行预测。PBR阶段在估计盒周围进行自适应采样,以级联方式对预测盒进行微调。如前所述,P2BNet充分利用点信息生成高质量的建议包,更有利于优化检测器(FR)。值得注意的是,概念上简单的P2BNet-FR框架通过单点注释获得了最先进的性能。
6 Appendix
P2BNet的可视化。绿色、黄色、橙色和蓝色分别代表注释点、CBP结果、PBR结果和ground-truth。
通过CBP阶段和PBR阶段,得到高质量的伪盒。在密集场景中的性能也很好。
,P2BNet充分利用点信息生成高质量的建议包,更有利于优化检测器(FR)。值得注意的是,概念上简单的P2BNet-FR框架通过单点注释获得了最先进的性能。