特征选择——Matrix Projection算法研究与实现
内容提要
- 引言
- MP特征选择思想
- MP特征选择算法
- MP特征选择分析
- 实验结果
- 分析总结
引言
一般选择文本的词组作为分类器输入向量的特征语义单元,而作为单词或词语的词组,在任何一种语言中都有数万或数十万个。另外,对于Web文本检索应用来说,互联网每天可能都会产生各种各样的新词汇。这样文本分类问题就面临着特征向量的维数灾难问题。有许多理由要求必须将特征的数量减少到尽可能的小,其中时间和空间复杂度就是很重要的理由。另一方面,虽然两个特征可能具有很好的分类信息,但是当把它们合并成一个特征时,由于相关性,分类信息可能丢失。设计分类器不仅要保证分类正确率,还要保证其分类性能。特征选择的任务就是:在给定的词组中,选择具有重要分类信息而又能减少特征的词组作为分类文本的特征。特征选择的过程也是特征压缩的过程,如果选择的特征不具有分类识别能力,那么将会设计出得到分类效果很差的分类器。另一方面,如果选择的特征能够很好的保留分类信息,除去那些几乎不能识别类别的词组,将在很大程度上简化分类器的设计。
MP特征选择思想
对于删除标点符号和停用的词组表示的文本,其中的词组具有不同的类别识别能力。本文提出一种基于矩阵投影(Matrix Projection,MP)运算的特征选择方法。矩阵投影特征选择方法是基于概率模型,综合考虑词组的文档频率以及词组在单个类别下的平均词频进行特征选择。这里的文档频率不是整个训练数据集的文档频率,而是一个词组在摸个类别下的文档频率,即该词组在一个类别下出现的文本数量比上该类别文本总数。词频为一篇文本中某词出现的次数比上该文本的总词数。平均词频是一个词在该类别下每一篇文本中的词频的算术平均。特征提取的过程:对已标注的训练语料,统计词组在类别中的文档频率 ,以及特征项在类别中每一个文档的词频 。通过投影函数计算词组在类别中的矩阵投影结果。根据运算结果的大小进行特征选择,最终选取那些结果值比较大的词组作为分类的特征。
MP特征选择算法
下面通过定义矩阵投影运算逐步引出MP特征选择过程。首先给出矩阵投影的一般定义如下。
定义 :矩阵投影:设 A 是一个mxn 的矩阵,即 AmXn=(aij)mXn,矩阵中各元素间相互独立。投影运算过程如图1所示:
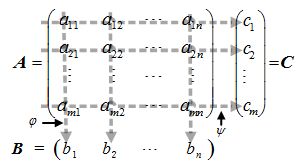
矩阵 A 通过投影运算得到 1Xn 的矩阵 B 和 的矩阵 C :
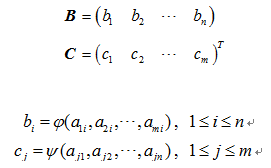
矩阵 B 和矩阵 C 称为矩阵 A 的投影。其中矩阵B是矩阵A的垂直投影, φ(a1i,a2i,…,ami) 叫做垂直投影函数;矩阵 C 是矩阵 A 的水平投影, ψ(aj1,aj2,…,ajn) 叫做水平投影函数。
上述运算得到的投影具有如下性质。
性质:矩阵 A 中的每一行与每一列元素组成的向量都是不相关的。考虑垂直投影,矩阵 B 与矩阵 A 中的每一行元素组成的向量是相关的。通过垂直投影函数φ(a1i,a2i,…,ami) 建立了矩阵 A 的每一列元素的相关性。水平投影具有类似性质,通过水平投影函数 ψ(aj1,aj2,…,ajn) 建立了矩阵 A 的每行元素的相关性。
投影运算是本文提出的一种特征选择矩阵压缩算法。通过垂直投影,将矩阵的一列元素(同一个词组在不同文档中的词频)携带的词组相关的频率信息压缩到投影向量的一个元素中,建立一类文档向量空间中词组之间的联系。水平投影的意义是将一篇文档中的不同词组的信息压缩到行向量的一个元素中。本文主要应用垂直投影运算进行特征选择。
本文描述的文本分类特征选择算法就是利用上述矩阵的垂直投影运算建立类别ci 中各文档词组之间的关联性,构建投影特征向量。通过计算投影矩阵中作为元素的词组的投影运算结果大小,决定词组的去留,进行特征的选择。考虑已标注训练数据集类别ci 下,各文档的词组词频的向量空间表示形式如下式所示:

其中: tfijk 表示词组tk 在类别ci 中某个文档j中的词频;
1≤i≤p,p 表示训练集类别的数量;
1≤j≤m,m 表示训练集类别ci 中文本的数量;
1≤k≤n,n 表示训练集类别ci 中文本含有词组的总数量;
矩阵 Di 中每一行表示一篇文档,每一列表示一个词组在不同文档中的词频。矩阵 Di 通过垂直投影函数 φ ,运算得到矩阵 Vi = (vi1,vi2,…,vin),其中 vik=φ(tfi1k,tfi2k,…,tfimk) ,我们称其为投影值。 Vi 是 1Xn 的矩阵,即 n 维向量。
投影值的计算是考虑词组在数据集中单一类别中的文档频率和词频率的平均值。垂直投影函数 φ 形式化表示如式:
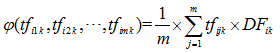
计算 φ(tfi1k,tfi2k,…,tfimk) 文档频率 DFik 是类别 ci 中词组 tk 的文档频率,表示形式如下式所示:
其中:
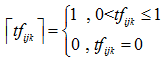
将下述两式带入 φ 函数得到最终求解投影值如式所示:
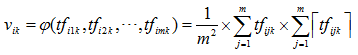
计算出所有词组的投影值 vik,就可以从投影值所表示的向量 Vi = (vi1,vi2,…,vin) 中进行特征选择。特征选择选取那些投影值 vik 最大的N项词组作为分类特征。
MP特征选择分析
为了形象的描述MP特征选择与卡方校验、信息增益、文档频率和互信息特征选择结果的不同,本文做一个小实验进行说明。
实验数据集为TanCorpV1.0中抽取的两个类别,分别是“汽车”和“电脑”,每个类别下选取100篇文档。通中文过分词之后,选取其中有两个汉字组成的词作为特征选择的备选词组,其中共有3322个不同的词组。分别采用上述五种特征选择方法进行特征选择,都选择100个词组作为特征。特征选择的结果如表1和图2所示。在图或表中u 表示“汽车”类,v表示“电脑”类。

表1中数量代表选出的100个特征在相应类别下面出现的个数,比例为所占的特征比例,即选出的相应类别下选出的特征站总特征的比例。例如文档频率(DF)选择的100个特征中,其中有91个在“汽车”类(u)中出现,占总特征的比例为0.91;87个特征在“电脑”类(v)中出现,占总特征的比例为0.87。

图2横轴表示词组的编号,将3322个词分别按照出现的次数从1开始编号到3322。例如出现最多的词“公司”,在200篇文本中共出现了97次,因此“公司”被编号为1,以此类推。编号前5的词其余四个分别是“病毒”出现83次、“中国”出现82次、“手机”出现71次、“交通”出现62次。词的序号越大词频越低,也就是出现的次数越少,其中仅出现1次的词就有1532项。纵轴分别表示五种特征选择选出的两个类别下的特征,符号即代表相应特征的出现。以DF说明,DF-u对应的是DF特征选择选出的词出现的情况,某词出现就在词组序号对应位置用符号标示出来。我们只关注图中特征的整体分布,不去关注具体的某一个特征。
从表1中可以看出DF选择的特征在类别之间最没有差别,两个类别中重复词数高达78个。MI选择的特征在类别之间最有差别,两个类之间没有重复出现的词。CHI和IG选择的特征差异性也较大,重复的词分别只有26个和21个。MP选择的特征差异性也较小,重复词数为67个。
从图2中可以观察到,DF选择的都是高频词。CHI和IG选择的特征分布比较广,并且在低频词类别之间的特征几乎没有重复的,也就是区分度较好;并且二者选择的特征很相近。MI选择的特征在中频段分布比较均匀,但是相对低频的词被选为特征的较多,这也验证了互信息“依赖低频词”的弊端。MP选择的特征不仅差异性比DF好,而且更接近高频词,这样分类更容易命中词,不像MI,很容易造成难命中低频词问题,造成分类效果不理想。
MP特征选择算法,不考虑类别之间的词的差异,只考虑单个类别中出现的最普遍的词。我们的假设:在不同类别内部同时出现的高频词都提供相同的分类信息,或低效类别区分能力,不影响分类。
实验结果
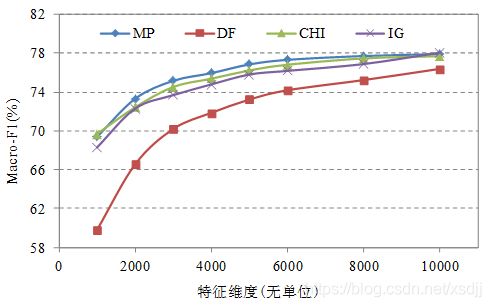
- 四种特征选择方法在kNN算法上的分类精度如图3所示:
- 四种特征选择方法在贝叶斯(MNNB)算法上的分类精度如图4所示:

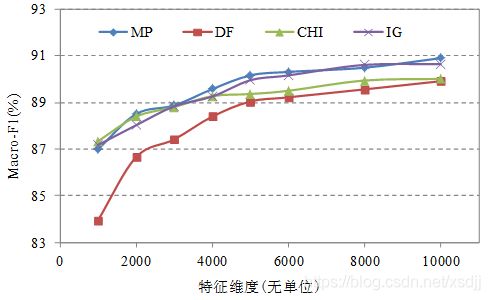
- 四种特征选择方法在SVM算法上的分类精度如图5所示:
分析总结
通过上述实验结果可见,MP特征选择算法应用于各种分类算法都能取得比较好的分类效果。MP方法比DF方法优势明显,并且略优于或等于CHI与IG特征选择方法的分类效果。
| 知更鸟博文推荐 | |
|---|---|
| 上一篇 | 文本分类——算法性能评估 |
| 下一篇 | 文本分类——NLV算法研究与实现 |
| 推荐篇 | 基于Kubernetes、Docker的机器学习微服务系统设计——完整版 |
| 研究篇 | RS中文分词 | MP特征选择 | NLV文本分类 | 快速kNN |
| 作者简介 | |
| 兴趣爱好 | 机器学习、云计算、自然语言处理、文本分类、深度学习 |
| [email protected] (欢迎交流) | |
参考文献:
[1] Sebastiani,F. Machine learning in automated text categorization [J]. ACM Comput. Surv. 34(1): 1-47.
[2] 郝秀兰,陶晓鹏,王述云,徐和祥,胡运发.基于特征选择及Condensing技术的文本取样[J].模式识别与人工智能,22(5):709-717.
[3] Jain,A.K.,Zongker,D. Feature selection: Evaluation, application, and small sample performance [J]. IEEE Trans. on Pattern Analysis and Machine Intelligence,19(2):153−158.
[4] 朱靖波,王会珍,张希娟.面向文本分类的混淆类判别技术[J].软件学报,2008,19(3):630-639.