机器学习算法(二十六):文本表示模型
目录
1 词袋模型
2 TF-IDF
2.1 TF(Term Frequency)
2.2 IDF(Inverse Document Frequency)
2.3 TF-IDF
2.4 用scikit-learn进行TF-IDF预处理
3 N-gram 模型
4 共现矩阵 (Cocurrence matrix)
5 点互信息
5.1 定义
5.2 例子
5.2.1 自然语言处理中使用PMI的例子
5.2.2 利用PMI预测对话的回复语句关键词
5.3 互信息(Mutual Information)
6 奇异值分解SVD
7 word2vec
8 LSA
8.1 LSA的优点
8.2 LSA的缺点
9 pLSA
9.1 模型
9.1.1 生成模型
9.1.2 共现模型
9.2 pLSA的优势
9.3 pLSA的不足
10 LDA
10.1 LDA的简单理解
10.2 LDA与PLSA的联系
10.3 LDA算法
10.4 概率图模型
10.5 总结
10.5.1 补充说明
10.5.2 常见疑惑
1 词袋模型
最基础的文本表示模型是词袋模型。 顾名思义, 就是将每篇文章看成一袋子词, 并忽略每个词出现的顺序。 具体地说, 就是将整段文本以词为单位切分开,然后每篇文章可以表示成一个长向量, 向量中的每一维代表一个单词, 而该维对应的权重则反映了这个词在原文章中的重要程度。常用TF-IDF来计算权重。
2 TF-IDF
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF-IDF是一种统计方法,用以评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。
TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency)。
2.1 TF(Term Frequency)
TF,词频,指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(分子一般小于分母区别于IDF),以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)

上式中分子为词 x 在第 j 个文件中出现的次数,分母是在第 j 个文件中所有字词的出现词数之和。
2.2 IDF(Inverse Document Frequency)
IDF,逆文本频率指数,是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
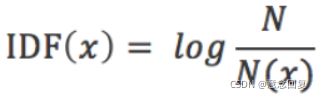
其中,N代表语料库中文本的总数,而N(x)代表语料库中包含词x的文本总数。
在一些特殊的情况下上面的公式会有一些问题,比如某一个生僻词在语料库中没有,则分母变为0,IDF就没有意义了,所以常用的IDF需要做一些平滑,使得语料库中没有出现的词也可以得到一个合适的IDF值,平滑的方法有很多种,最常见的IDF平滑公式之一为:
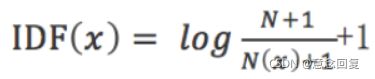
2.3 TF-IDF
某一个词的TF-IDF值:

TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
2.4 用scikit-learn进行TF-IDF预处理
from sklearn.feature_extraction.text import TfidfVectorizer
vector = TfidfVectorizer(input='content', encoding='utf-8', decode_error='strict', strip_accents=None, lowercase=True, preprocessor=None, tokenizer=None, analyzer='word', stop_words=None, token_pattern='(?u)\b\w\w+\b', ngram_range=(1, 1), max_df=1.0, min_df=1, max_features=None, vocabulary=None, binary=False, dtype=, norm='l2', use_idf=True, smooth_idf=True, sublinear_tf=False)
其中,ngram_range=(2, 2) 表示选用2个词进行前后的组合,构成新的标签值,例如一句话‘I like you‘,如果 ngram_range = (2, 2),表示只选取前后的两个词构造词组合:词向量组合为:’I like‘ 和 ’like you‘ ;如果ngram_range = (1, 3) ,表示选取1到3个词做为组合方式: 词向量组合为: ‘I‘, ‘like‘, ‘you‘, ‘I like‘, ‘like you‘, ‘I like you‘ 构成词频标签。
其余参数说明参见sklearn.feature_extraction.text.TfidfVectorizer — scikit-learn 1.0.1 documentation。
3 N-gram 模型
假设有一个由 n 个词组成的句子![]() ,假设每一个词
,假设每一个词![]() 都依赖于第一个单词
都依赖于第一个单词![]() 到它之前一个单词
到它之前一个单词![]() 的影响:
的影响:

但是这个衡量方法有 两个缺陷:1.参数空间过大 2.数据稀疏严重
为解决第一个问题,引入马尔可夫假设:一个词的出现仅与它之前的若干个词有关:

Bi-gram:如果一个词的出现仅依赖于它前面出现的一个词,就称之为Bi-gram:
![]()
Tri-gram:如果一个词的出现仅依赖于它前面出现的两个词,就称之为Tri-gram:
![]()
现实中一般用 Bi-gram和 tri-gram 就够了。
如何计算条件概率呢?答案是极大似然估计,说人话就是数频数:

可以根据 N-gram 计算分别计算两句话的概率判断那句话更像人话。应用比如搜索引擎的输入猜想。
4 共现矩阵 (Cocurrence matrix)
一个非常重要的思想是,我们认为某个词的意思跟它临近的单词是紧密相关的。这是我们可以设定一个窗口(大小一般是5~10),如下窗口大小是2,那么在这个窗口内,与rests 共同出现的单词就有life、he、in、peace。然后我们就利用这种共现关系来生成词向量。

例如,现在我们的语料库包括下面三份文档资料:
I like deep learning.
I like NLP.
I enjoy flying.
作为示例,我们设定的窗口大小为1,也就是只看某个单词周围紧邻着的那个单词。此时,将得到一个对称矩阵——共现矩阵。因为在我们的语料库中,I 和 like做为邻居同时出现在窗口中的次数是2,所以下表中I 和like相交的位置其值就是2。这样我们也实现了将word变成向量的设想,在共现矩阵每一行(或每一列)都是对应单词的一个向量表示。

虽然Cocurrence matrix一定程度上解决了单词间相对位置也应予以重视这个问题。但是它仍然面对维度灾难。也即是说一个word的向量表示长度太长了。这时,很自然地会想到SVD或者PCA等一些常用的降维方法。当然,这也会带来其他的一些问题,例如,我们的词汇表中有新词加入,那么就很难为他分配一个新的向量。
5 点互信息
5.1 定义
如何解决高频词误导计算结果的问题?最直接的想法是:如果一个词与很多词共现,则降低其权重;反之,如果一个只与个别词共现,则提高其权重。机器学习相关文献里面,经常会用到PMI(Pointwise Mutual Information)这个指标来衡量两个事物之间的相关性(比如两个词)。其原理很简单,公式如下:

在概率论中,我们知道,如果 x 跟 y 不相关,则 p(x,y)=p(x)p(y)。二者相关性越大,则 p(x,y)就相比于 p(x)p(y) 越大。用后面的式子可能更好理解,在 y 出现的情况下 x 出现的条件概率 p(x|y)除以 x 本身出现的概率 p(x),自然就表示 x 跟 y 的相关程度。
这里的log来自于信息论的理论,可以简单理解为,当对 p(x) 取log之后就将一个概率转换为了信息量(要再乘以-1将其变为正数),以2为底时可以简单理解为用多少个bits可以表示这个变量。
5.2 例子
5.2.1 自然语言处理中使用PMI的例子
比如,要衡量like这个词的极性(正向情感or负向情感)。先选一些正向情感词如good,计算like跟good的PMI,

其中p(like,good)表示like跟good在同一句话出现的概率(like跟good同时出现次数/总词数^2),p(like)表示like出现概率,p(good)表示good出现概率(good出现次数/总词数)。
PMI越大代表like正向情感倾向越明显。
5.2.2 利用PMI预测对话的回复语句关键词
先在比较大的训练预料中计算query每个词(wq)和reply每个词(wr)的PMI,
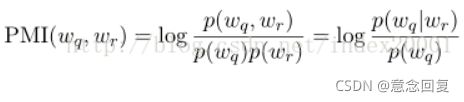
这里概率p(wq,wr)为wq和wr分别在一个对话pair的上下句同时出现的概率(wq和wr同时出现的对话pair数/训练语料q部分每个词和r部分每个词组成pair的总数),p(wq)是wq在q语句中出现的概率(wq在q语料中出现的语句数/q语料总数)。
计算出一个PMI矩阵,两个维度分别是query词表和reply词表,
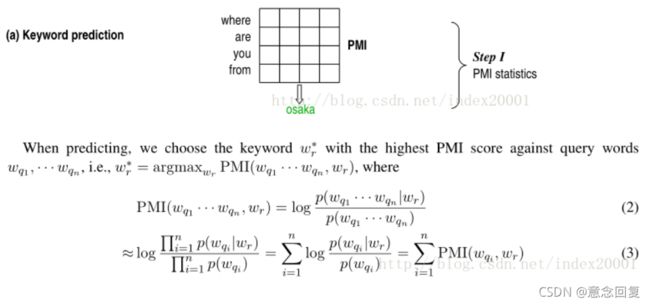
预测回复关键词时,计算候选词表中某个词和给定的query的n个词(wq1,...wqn)的PMI,对n求和,候选词表每个词都这样求个PMI和,选出最大的那个对应的候选词就是predict word。
文章中还对 keyword candidates 作了限制,规定它的范围是名词。
5.3 互信息(Mutual Information)
点互信息PMI其实就是从信息论里面的互信息这个概念里面衍生出来的。
互信息即:

其衡量的是两个随机变量之间的相关性,即一个随机变量中包含的关于另一个随机变量的信息量。所谓的随机变量,即随机试验结果的量的表示,可以简单理解为按照一个概率分布进行取值的变量,比如随机抽查的一个人的身高就是一个随机变量。
可以看出,互信息其实就是对X和Y的所有可能的取值情况的点互信息PMI的加权和。因此,点互信息这个名字还是很形象的。
6 奇异值分解SVD
机器学习算法(六):奇异值分解SVD_意念回复的博客-CSDN博客
7 word2vec
机器学习算法(十三):word2vec_意念回复的博客-CSDN博客
8 LSA
8.1 LSA的优点
1)低维空间表示可以刻画同义词,同义词会对应着相同或相似的主题。
2)降维可去除部分噪声,使特征更鲁棒。
3)充分利用冗余数据。
4)无监督/完全自动化。
5)与语言无关。
8.2 LSA的缺点
1)LSA可以处理向量空间模型无法解决的一义多词(synonymy)问题,但不能解决 一词多义(polysemy)问题。因为LSA将每一个词映射为潜在语义空间中的一个点,也就是说一个词的多个意思在空间中对于的是同一个点,并没有被区分。
2)SVD的优化目标基于L-2 norm 或者 Frobenius Norm 的,这相当于隐含了对数据的高斯分布假设。而 term 出现的次数是非负的,这明显不符合 Gaussian 假设,而更接近 Multi-nomial 分布。
3)特征向量的方向没有对应的物理解释。
4)SVD的计算复杂度很高,而且当有新的文档来到时,若要更新模型需重新训练。
5)没有刻画term出现次数的概率模型。
6)对于count vectors 而言,欧式距离表达是不合适的(重建时会产生负数)。
7)维数的选择是ad-hoc的(Ad-Hoc(点对点)模式)。
8)LSA具有词袋模型的缺点,即在一篇文章,或者一个句子中忽略词语的先后顺序。
9)LSA的概率模型假设文档和词的分布是服从联合正态分布的,但从观测数据来看是服从泊松分布的。因此LSA算法的一个改进PLSA使用了多项分布,其效果要好于LSA。
9 pLSA
为何提出PLSA?
- 在语义分析问题中,存在同义词和一词多义这两个严峻的问题,LSA可以很好的解决同义词问题,却无法妥善处理一词多义问题。
- PLSA则可以同时解决同义词和一词多义两个问题。
LSA和PLSA_LZXandTM的博客-CSDN博客_plsa
9.1 模型
9.1.1 生成模型

9.1.2 共现模型

9.2 pLSA的优势
1)定义了概率模型,而且每个变量以及相应的概率分布和条件概率分布都有明确的物理解释。
2)相比于LSA隐含了高斯分布假设,pLSA隐含的Multi-nomial分布(多项式分布)假设更符合文本特性。
3)pLSA的优化目标是是KL-divergence最小,而不是依赖于最小均方误差等准则。
4)可以利用各种model selection和complexity control准则来确定topic的维数。
9.3 pLSA的不足
1)概率模型不够完备:在document层面上没有提供合适的概率模型,使得pLSA并不是完备的生成式模型,而必须在确定document i的情况下才能对模型进行随机抽样。
2)随着document和term 个数的增加,pLSA模型也线性增加,变得越来越庞大。
3)EM算法需要反复的迭代,需要很大计算量。
LSA,pLSA原理及其代码实现_weixin_30617561的博客-CSDN博客
自然语言处理之PLSA | zhikaizhang's Blog
10 LDA
自然语言处理实验演示 - 59. 潜在狄利克雷分配_哔哩哔哩_bilibili
10.1 LDA的简单理解
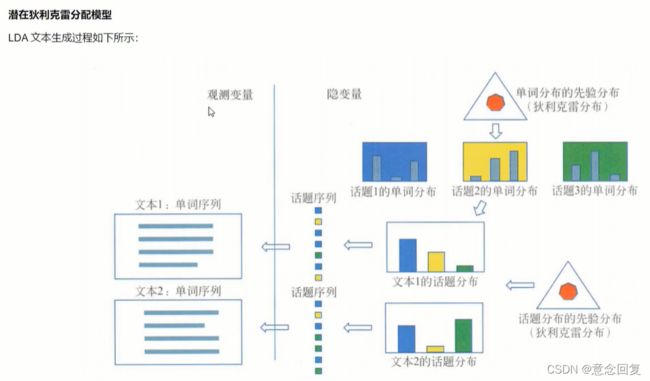
同一主题下,某个词出现的概率,以及同一文档下,某个主题出现的概率,两个概率的乘积,可以得到某篇文档出现某个词的概率,我们在训练的时候,只需要调整这两个分布。
10.2 LDA与PLSA的联系
LDA模型和PLSA的联系非常紧密,都是概率模型(LSA是非概率模型),是利用概率生成模型对文本集合进行主题分析的无监督学习方法。
不同在于,PLSA是用了频率学派的方法,用极大似然估计进行学习,而LDA是用了贝叶斯学派的方法,进行贝叶斯推断,所以LDA就是在pLSA的基础上加了⻉叶斯框架,即LDA就是pLSA的⻉叶斯版本 。
LDA和PLSA都假设存在两个多项分布:话题是单词的多项分布,文本是话题的多项分布。不同在于,LDA认为多项分布的参数也服从一个分布,而不是固定不变的,使用狄利克雷分布作为多项分布的先验分布,也就是多项分布的参数服从狄利克雷分布。
为啥引入先验分布呢?因为这样能防止过拟合。为啥选择狄利克雷分布呢作为先验分布呢?因为狄利克雷分布是多项分布的共轭先验分布,那么先验分布和后验分布的形式相同,便于由先验分布得到后验分布。
10.3 LDA算法



10.4 概率图模型




10.5 总结
LDA可以看作是由四个概率分布组成的(两个狄利克雷分布和多项式分布),也可以看作是两个狄利克雷-多项式共轭分布组成的。所以这四个概率分布如下:
- 第一个狄利克雷分布生成主题分布模型,且该主题分布模型服从多项式分布(相当于主题分布有多种)
- 第一个多项式分布用来生成某一个主题(获得某一个确定的主题分布之后就可以获得确定的主题)
- 第二个狄利克雷分布生成单词分布模型,且该词服从多项式分布(相当于词分布有多种)
- 第二个多项式分布用来生成某一个词(获得某一个确定的词分布之后就可以获得确定的词,该确定的词分布是和确定的主题有关的)
10.5.1 补充说明:
1) LDA后可以继续对不同文本进行基于隐含主题的分类,聚类等
2)文档-主题分布和主题-词分布是独立的,也就是说,主题-词分布并不依赖某一个具体的文档,而对应的是语料集中的主题词分布。所以这里没有表述成"这篇文档的主题词分布".
3)P(文档-主题)是狄利克雷分布,采样确定文档,得到P(主题)是多项式分布,对P(主题)进行采样得到确定的主题z;
P(主题-词)是狄利克雷分布,根据已经确定的z,得到P(词)是多项式分布,对P(词)进行采样得到确定的词w
4)对于任何一个文档d,在先验分布Dir(a)采样得到θd(这里是一个K维向量,代表每个主题的概率),由这些概率得到主题分布(多项式分布),再由这个多项式分布采样得到第n个词的主题编号Zd,n(这个主题编号为一个值,而不是向量形式)
对于任何一个主题t,而在先验分布Dir(η)中采样得到βt(一个V维度向量,代表每个词的概率),由这些概率得到词分布(多项式分布),这样假设一共K个主题,β就一共有K个。现在有了文档d的第n个词的主题编号Zd,n(他属于K个β中的一个)对应就可以生成文档d的第n个词
10.5.2 常见疑惑
1)"第d个文档中,第k个主题的词的个数为:n(k)d" 中n(k)d如何计算得到呢。
答:文档d中的主题分布符合Dirichlet分布,然后Gibbs采样得到各个主题的概率,进一步根据文档d中词的总数N,乘以概率得到每个主题的词的个数
2)可以把LDA理解为朴素贝叶斯模型的一种加强吗?能简要介绍下二者的区别和各自优缺点吗?
答:两个算法都用到了一些贝叶斯学派的理论。如果LDA是用Gibbs采样求解,那么只用到了很少的贝叶斯学派的理论,如果是LDA变分推断算法,那么就完全是贝叶斯学派的思路了。
两者的共性就是都用到了贝叶斯的先验分布,后验分布和似然的概念。两者都经常用于NLP文本分析。
不过一个用于监督学习的分类,另一个用于非监督学习的主题模型寻找,要解决的问题差异还是很大的。
3)现在语料里面有很多不同领域的语料,我想对语料进行分类,比如说政治领域 体育领域 社会领域 然后学习的过程中将这些个领域信息成为先验知识 我该如何去加这个约束呢?
答:LDA的主题模型是隐含的主题,并不能直接将主题映射成你自己定义的政治领域 体育领域 社会领域等。所以你是没有办法直接加这个LDA约束的,建议尝试标记数据,用分类模型来解决你的问题