一文读懂各种分布式机器学习框架的区别与联系
创作不易,欢迎关注,点赞,收藏!
本文主要对比各种常见的分布式机器学习框架原理,包括数据分布式,参数服务器,Ring-Allreduce 架构和数据流图。
1.数据分布式机器学习(例如spark-mllib):
Spark 是使用 scala 实现的基于内存计算的大数据开源集群计算环境.提供了 java,scala, python,R 等语言的调用接口.
Spark 的主要特点还包括:
- (1)提供 Cache 机制来支持需要反复迭代计算或者多次数据共享,减少数据读取的 IO 开销;
- (2)提供了一套支持 DAG 图的分布式并行计算的编程框架,减少多次计算之间中间结果写到 Hdfs 的开销;
- (3)使用多线程池模型减少 Task 启动开稍, shuffle 过程中避免不必要的 sort 操作并减少磁盘 IO 操作。(Hadoop 的 Map 和 reduce 之间的 shuffle 需要 sort)
Spark 系统架构: - 应用程序(Application): 基于Spark的用户程序,包含了一个Driver Program 和集群中多个的Executor; - 驱动(Driver): 运行Application的main()函数并且创建SparkContext; - 执行单元(Executor): 是为某Application运行在Worker Node上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立的Executors; - 集群管理程序(Cluster Manager): 在集群上获取资源的外部服务(例如:Local、Standalone、Mesos或Yarn等集群管理系统); - 操作(Operation): 作用于RDD的各种操作分为Transformation和Action.
整个 Spark 集群中,分为 Master 节点与 worker 节点,,其中 Master 节点上常驻 Master 守护进程和 Driver 进程, Master 负责将串行任务变成可并行执行的任务集Tasks, 同时还负责出错问题处理等,而 Worker 节点上常驻 Worker 守护进程, Master 节点与 Worker 节点分工不同, Master 负载管理全部的 Worker 节点,而 Worker 节点负责执行任务. Driver 的功能是创建 SparkContext, 负责执行用户写的 Application 的 main 函数进程,Application 就是用户写的程序. Spark 支持不同的运行模式,包括Local, Standalone,Mesoses,Yarn 模式.不同的模式可能会将 Driver 调度到不同的节点上执行.集群管理模式里, local 一般用于本地调试. 每个 Worker 上存在一个或多个 Executor 进程,该对象拥有一个线程池,每个线程负责一个 Task 任务的执行.根据 Executor 上 CPU-core 的数量,其每个时间可以并行多个 跟 core 一样数量的 Task.Task 任务即为具体执行的 Spark 程序的任务.
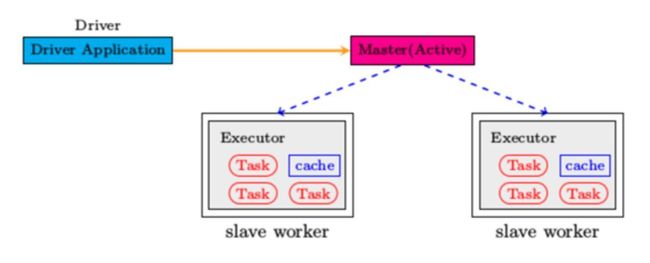

根据上述spark架构可知,spark采用数据分布式+同步的模式,优点是社区完善,配套方案完善,缺点是对异步和模型分布式不支持,很多前沿的算法spark不支持,而且spark的本质-数据分布式对很多算法的性能有天然上限。
2.基于参数服务器架构的Multiverso。
PS架构包括内功和外功两个部分,所谓的外功,就是把计算资源分为两个部分,参数服务器节点和工作节点:
参数服务器节点用来存储参数,工作节点部分用来做算法的训练。内功就是对应的,把机器学习算法也分成两个方面,即参数和训练。
参数部分即模型本身,有一致性的要求,参数服务器也可以是一个集群,对于大型的算法,比如DNN,CNN,参数上亿的时候,自然需要一个集群来存储这么多的参数,因而,参数服务器也是需要调度的。
训练部分自然是并行的,不然无法体现分布式机器学习的优势。因为参数服务器的存在,每个计算节点在拿到新的batch数据之后,都要从参数服务器上取下最新的参数,然后计算梯度,再将梯度更新回参数服务器。
参数服务器既可实现数据分布式,也可实现模型分布式,同时支持异步和同步,也可实现大规模的参数更新。

但是传统线性表架构的参数服务器在参数更新和通信上也存在很多问题,比如大规模数据训练的时候突然机器宕机,会造成整个系统宕机,通信卡顿等,此时可以引入环状结构。
3. Ring-Allreduce 架构
Ring-Allreduce 算法最早由 Baidu Silicon Valley AI Lab (SVAIL) 在2017年2月提出,并应用在其PaddlePaddle平台上,同年8月,SVAIL将其提交到tensorflow的contrib package中。
也是在同年8月,Uber发布了基于Ring-Allreduce算法和OpenMPI通信的Horovod架构。
Ring-Allreduce 的命名中Ring意味着设备之间的拓扑结构为环形,Allreduce则代表着没有中心节点,架构中的每个节点都是梯度的汇总计算节点。
此种算法各个节点之间只与相邻的两个节点通信,并不需要参数服务器。因此,所有节点都参与计算也参与存储。

使用 Ring-Allreduce 算法进行分布式训练基本过程如下:
-
每个设备根据各自的训练数据分别进行梯度的计算,得到梯度
-
将每个设备上的梯度向量切分成长度大致相等的 N 个分片(其中分片数N与设备数量相等)
-
ScatterReduce 阶段:通过 N-1 轮梯度传输和梯度相加,在每个设备上的梯度向量都有一小部分为所有设备中该分片梯度之和 (图③)
-
AllGather 阶段:通过 N-1 轮梯度传输,将上个阶段计算出的每个梯度向量分片之和广播到其他设备(图④)
-
在每个设备上合并分片梯度,并根据梯度更新每个设备上的模型
大致计算一下Ring-Allreduce的通信消耗时间, 同样假设:
-
假设模型的总参数量为 X
-
PS的数量为1, Worker的数量为 N
-
设备间数据最大传输速度为 B
其中每个设备需要传输 2(N-1) 次信息,并且每次发送 X/N 数据,因此完成一个batch iteration数据传输所需要的耗时为 2(N-1)*X/NB = 2X(N-1)/NB,可以看到当N逐渐增加时,数据传输所消耗的时间趋近于常数 2X/B。相比PS架构,Ring Allreduce架构是带宽优化的,因为集群中每个节点的带宽都被充分利用。对比于PS-Worker架构的耗时2(X·N)/B, Ring-Allreduce的参数传递耗时并不会随着设备的增加而线性增长,这是该架构性能优于PS-Worker的最大原因。
此外,在深度学习训练过程中,计算梯度采用BP算法,其特点是后面层的梯度先被计算,而前面层的梯度慢于前面层,Ring-allreduce架构可以充分利用这个特点,在前面层梯度计算的同时进行后面层梯度的传递,从而进一步减少训练时间。
后来,TensorFlow官方也在1.11版本中支持了allreduce的分布式训练策略CollectiveAllReduceStrategy,可以与tf.estimator配合使用。
Horovod的实际性能对比测试可以看下图:

可以看出Horovod在分布式训练的GPU设备的拓展能力对比TensorFlow有着很大的提高,在GPU设备达到一定规模的后其效率将是TensorFlow原生PS-Worker架构的两倍以上。
4.基于数据流图的tensorflow:
TensorFlow™是一个基于数据流编程(dataflow programming)的符号数学系统,被广泛应用于各类机器学习(machine learning)算法的编程实现,其前身是谷歌的神经网络算法库DistBelief [1] 。
Tensorflow拥有多层级结构,可部署于各类服务器、PC终端和网页并支持GPU和TPU高性能数值计算,被广泛应用于谷歌内部的产品开发和各领域的科学研究 [1-2] 。
TensorFlow由谷歌人工智能团队谷歌大脑(Google Brain)开发和维护,拥有包括TensorFlow Hub、TensorFlow Lite、TensorFlow Research Cloud在内的多个项目以及各类应用程序接口(Application Programming Interface, API) [2] 。自2015年11月9日起,TensorFlow依据阿帕奇授权协议(Apache 2.0 open source license)开放源代码 [2] 。


什么是数据流图(Data Flow Graph)?

数据流图由点(node)和边(edge)组成。
其中,节点通常以圆、椭圆或方框表示,代表对数据的运算或某种操作。边是节点之间的连接,用带箭头的线表示,指向节点的边表示输入,从节点引出的边表示输出。输入可以是来自其他数据流图,也可以表示文件读取、用户输入。所以在本质上,TensorFlow的数据流图就是一系列链接在一起的函数构成,每个函数都会输出若干个值(0个或多个),以供其它函数使用。
除了上面两个概念,以下几个也很重要:
图(Graph):图描述了计算的过程,TensorFlow使用图来表示计算任务。
张量(Tensor):TensorFlow使用tensor表示数据。每个Tensor就是一个多维的数组。
操作(op):operation的缩写,一个op就是某节点上的一个操作,输入0个或多个Tensor,执行计算,产生输出0个或多个Tensor。
会话(Session):图必须在称之为“会话”的上下文中执行。会话将图的op分发到诸如CPU或GPU之类的设备上执行。
变量(Variable):运行过程中可以被改变,用于维护状态。
基于数据流图架构的tensorflow能够根据巧妙结合数据分布式,模型分布式,并结合进了环状分布式架构,可以根据不同的算法自己设计数据流图进行训练测试。但是tensorflow作为一个开源架构有些笨重,开发者可以借鉴其设计理念自己定制开发轻量级版本。
5.几种模式的区别:

各种框架对比图, angel是腾讯开源的参数服务器框架,spark是mapreduce流派的代表,tensorflow和pytorch是数据流图的代表。

参考:《分布式机器学习:算法,理论与实践》刘铁岩