《自然语言处理入门》笔记
目录
第一章 新手上路
1.1自然语言与编程语言
1.1.1词汇量
1.1.2结构化
1.1.3歧义性
1.1.4容错性
1.1.5易变性
1.1.6简略性
1.2自然语言处理的层次
1.2.1语音、图像和文本(第一层)
1.2.2中文分词、词性标注和命名实体识别(第二层)
1.2.3信息抽取(第三层)
1.2.4文本分类和文本聚类(第三层)
1.2.5句法分析(第三层)
1.2.6语义分析和篇章分析(第四层)
1.2.7其他高级任务
1.3自然语言处理的流派
1.3.1基于规则的专家系统
1.3.2基于统计的学习方法
1.3.3历史
1.3.4规则和统计
1.3.5传统方法与深度学习
1.4机器学习
1.4.1什么是机器学习
1.4.2模型
1.4.3特征
1.4.4数据集
1.4.5监督学习
1.4.6无监督学习
1.4.7其他类型的机器学习算法
1.5语料库
1.5.1中文分词语料库
1.5.2词性标注语料库
1.5.3命名实体识别语料库
1.5.4句法分析语料库
1.5.6语料库建设
第2章 词典分词
2.1什么是词
2.1.1词的定义
2.1.2词的性质——齐夫定律
2.3切分算法
2.3.1完全切分
2.3.2正向最长匹配
2.3.3逆向最长匹配
2.3.4双向最长匹配
2.3.5速度评测
2.4字典树
2.4.1什么是字典树
2.9准确率评测
2.9.1准确率
2.9.2混淆矩阵与TP/FN/FP/TN
2.9.3精确率
2.9.4召回率
2.9.5 F1值
2.9.6中文分词中的P、R、F1值
2.9.9 OOV Recall Rate与IV Recall Rate
第3章 二元语法与中文分词
3.1语言模型
3.1.1什么是语言模型
3.1.2马尔可夫链与二元语法
3.1.3 n元语法
3.1.4数据稀疏与平滑策略
3.2中文分词语料库
3.2.1 1998年《人民日报》语料库PKU
3.2.2微软亚洲研究院语料库MSR
3.2.3繁体中文分词语料库
3.2.4语料库统计
3.3训练
3.3.2统计一元语法
3.3.3统计二元语法
3.4预测
3.4.2构建词网
3.4.3节点间的距离计算
3.4.4词图上的维特比算法
3.5评测
3.5.1标准化评测
3.5.2误差分析
第4章 隐马尔可夫模型与序列标注
4.1序列标注问题
4.1.1序列标注与中文分词
4.1.2序列标注与词性标注
4.1.3序列标注与命名实体识别
4.2隐马尔可夫模型
4.2.1从马尔可夫假设到隐马尔可夫模型
4.2.2初始状态概率向量
4.2.3状态转移概率矩阵
4.2.4发射概率矩阵
4.2.5隐马尔可夫模型的三个基本用法
4.4隐马尔可夫模型的训练
4.4.1初始状态概率向量的估计
4.4.2转移概率矩阵的估计
4.4.3发射概率矩阵的估计
4.5隐马尔可夫模型的预测
4.5.1概率计算的前向算法
4.5.2搜索状态序列的维特比算法
4.6隐马尔可夫模型应用于中文分词
4.6.1标注集
4.6.2字符映射
4.6.3语料转换
4.6.4训练
4.6.5预测
4.6.6评测
4.6.7误差分析
第5章 感知机分类与序列标注
5.1分类问题
5.1.1定义:
5.1.2应用
5.2线性模型和感知机算法
5.2.1特征向量与样本空间
5.2.2决策边界与分离超平面
5.2.3感知机算法
5.2.5投票感知机和平均感知机
5.4结构化预测
5.4.1定义
5.4.2结构化预测与学习的流程
5.5线性模型的结构化感知机算法
5.5.1结构化感知机算法
5.5.2结构化感知机与序列标注
5.5.3结构化感知机的维特比解码算法
5.6基于结构化感知机的中文分词
5.6.1特征提取
5.6.4创建感知机分词器
5.6.5准确率与性能
5.6.7中文分词特征工程
第6章 条件随机场与序列标注
6.1机器学习的模型谱系
6.1.1生成式模型与判别式模型
6.1.2 有向与无向概率图模型
6.2条件随机场
6.2.1线性链条件随机场
6.2.3条件随机场与结构化感知机的对比
第7章 词性标注
7.1词性标注概述
7.1.1什么是词性
7.1.2词性的用处
7.1.3词性标注
7.1.4词性标注模型
7.2词性标注语料库与标注集
7.2.1《人民日报》语料库与PKU标注集
7.2.2国家语委语料库与863标注集
7.2.3《诛仙》语料库与CTB标注集
7.3序列标注模型应用于词性标注
7.3.1基于隐马尔可夫模型的词性标注
7.3.2基于感知机的词性标注
7.3.3基于条件随机场的词性标注
7.3.4词性标注评测
第8章 命名实体识别
8.1概述
8.1.1命名实体
8.1.2命名实体识别
8.3命名实体识别语料库
8.3.1 1998年《人民日报》语料库
8.3.2微软命名实体识别语料库(MSRA Named Entity Corpus,MSRA-NE)
8.5基于序列标注的命名实体识别
8.5.1特征提取
8.5.2基于隐马尔可夫模型序列标注的命名实体识别
8.5.3基于感知机序列标注的命名实体识别
8.5.5命名实体识别标准化评测
第9章 信息抽取
9.1新词提取
9.1.1概述
9.1.2基本原理
9.1.3信息熵
9.1.4互信息
9.1.5实现
9.2关键词提取
9.2.1词频统计
9.2.2 TF-IDF
9.2.3TextRank
9.3短语提取
9.4关键句提取
9.4.1 BM25
9.4.2 TextRank
第10章 文本聚类
10.1概述
10.1.1聚类
10.1.2聚类的应用
10.1.3文本聚类
10.2文档的特征提取
10.2.1词袋模型
10.2.2词袋的统计指标
10.3 k均值算法
10.5标准化评测
10.5.1 P、R和F1值
第12章 依存句法分析
12.2依存句法树
12.2.1依存句法理论
12.2.2中文依存句法树库
12.2.3依存句法树库的可视化
12.3依存句法分析
12.4基于转移的依存句法分析
12.4.1 Arc-Eager转移系统
12.4.2特征提取
12.4.3 Static和Dynamic Oracle
12.5依存句法树分析API
12.5.2标准化评测
12.6案例:基于依存句法树的意见抽取
第一章 新手上路
自然语言处理(Natural Language Processing,NLP)研究的是如何通过机器学习等技术让计算机学会处理人类语言,乃至实现终极目标——理解人类语言或人工智能
1.1自然语言与编程语言
1.1.1词汇量
自然语言中的词汇量比编程语言中的关键词丰富
1.1.2结构化
自然语言是非结构化的,而编程语言是结构化的。所谓结构化,指的是信息具有明确的结构关系
1.1.3歧义性
自然语言含有大量歧义,但在编程语言中,则不存在歧义性
1.1.4容错性
自然语言哪怕错得再离谱,人们还是可以猜出它大概的意思。而在编程语言中,必须保证拼写绝对正确、语法绝对规范
1.1.5易变性
编程语言的变化要缓慢温和得多,而自然语言则相对迅速嘈杂一些
1.1.6简略性
自然语言往往简洁、干练。
1.2自然语言处理的层次

1.2.1语音、图像和文本(第一层)
自然语言处理的输入源一共有3个,即语音、图像和文本
1.2.2中文分词、词性标注和命名实体识别(第二层)
统称词法分析
1、中文分词:将文本分隔为有意义的词语
2、词性标注:确定每个词语的类别和浅层的歧义消除
3、命名实体识别:识别出一些较长的专有名词
1.2.3信息抽取(第三层)
词法分析之后,根据这些单词和标签,抽取出一部分有用的信息
1.2.4文本分类和文本聚类(第三层)
在词法分析之后进行
1、文本分类:把许多文档分门别类地整理一下
2、文本聚类:把相似地文本归档到一起,或者排除重复的文档,而不关心具体类别
1.2.5句法分析(第三层)
词性分析之后,再获取句子的主谓宾结构等
1.2.6语义分析和篇章分析(第四层)
句法分析之后,进行词义消歧、语义角色标注和语义依存分析
1.2.7其他高级任务
综合性任务
1.3自然语言处理的流派
1.3.1基于规则的专家系统
1、规则,指的是由专家手工制定的确定性流程。
2、规则系统比较成功的案例:波特词干算法(Porter stemming algorithm)
3、规则系统显得僵硬、死板和不稳定
1.3.2基于统计的学习方法
1、统计:在语料库上进行的统计
2、语料库:人工标注的结构化文本
3、以举例子的方式让机器自动学习这些规律。然后机器将这些规律应用到新的、未知的例子上去
1.3.3历史
基础研究→规则系统→统计方法→深度学习
1.3.4规则和统计
语言学知识的作用有两方面:
1、帮助我们设计更简洁、高效的特征模板
2、在语料库建设中发挥作用
实际运行的系统在预处理和后处理的部分依然会用到一些手写规则
1.3.5传统方法与深度学习
深度学习在自然语言处理领域中的基础任务上发力并不大。另一方面,深度学习涉及大量矩阵运算,需要特殊计算硬件的加速,因此性价比不高
1.4机器学习
1.4.1什么是机器学习
机器学习就是让机器学会算法的算法。称被学习的算法为模型
1.4.2模型
模型是对现实问题的数学抽象,由一个假设函数以及一系列参数构成
1.4.3特征
1、特征:事物的特点转化的数值
2、特征模板:自动提取特征的模板
3、特征工程:挑选特征和设计特征模板
1.4.4数据集
1、样本:例子
2、数据集:例子组成的习题集,在自然语言处理领域称为语料库
1.4.5监督学习
附带标准答案,让机器先做一遍题,然后与标准答案作比较,最后根据误差纠正模型的错误。每一遍学习称作一次迭代。迭代学习的过程称为训练。机器得出结论的过程称为预测
1.4.6无监督学习
只给机器学习,却不告诉其参考答案。其中不含标准答案的习题集被称为无标注(unlabeled)的数据集。无监督学习一般用于聚类和降维
降维:将样本点从高维空间变换到低维空间的过程。如果样本具有n个特征,则样本对应着n+1维空间中的一个点,多出来的维度是给假设函数的因变量用的。如果我们想要让这些样本点可视化,则必须将其降维到二维或者三维。
有一些降维算法的中心思想是,降维后尽量不损失信息,或者说让样本在低维空间中每个维度上的方差都尽量大(其实就是考虑剔除无用或者影响不大的特征)
1.4.7其他类型的机器学习算法
1、半监督学习:如果我们训练多个模型,然后对同一个实例执行预测,会得到多个结果。如果这些结果多数一致,则可以将该实例和结果放到一起作为新的训练样本,用来扩充训练集
2、强化学习:一边预测,一边根据环境的反馈规划下次决策
1.5语料库
1.5.1中文分词语料库
由人工正确切分后的句子集合
1.5.2词性标注语料库
切分并为每个词语指定一个词性的语料
1.5.3命名实体识别语料库
人工标注了文本内部制作者关心的实体名词以及实体类别
1.5.4句法分析语料库
汉语中常用的句法分析语料库有CTB(Chinese Treebank,中文树库)。每个句子都经过了分词、词性标注和句法分析
1.5.6语料库建设
语料库建设:构建一份语料库的过程,分为规范制定、人员培训和人工标注三个阶段
第2章 词典分词
中文分词:将一段文本拆分为一系列单词的过程,这些单词顺序拼接后等于原文
词典分词:最简单、最常见的分词算法。仅需一部词典和一套查词典的规则即可
2.1什么是词
2.1.1词的定义
在语言学中,词语的定义是具有独立意义的最小单位,然而该定义过于模糊
在基于词典的中文分词中,词典中的字符串就是词
2.1.2词的性质——齐夫定律
一个单词的词频与它的词频排名成反比
2.3切分算法
词典确定后,句子可能含有很多词典中的词语。它们可能互相重叠,到底输出哪一个由规则决定。这时需要制定一些规则查字典,常用的规则有正向最长匹配、逆向最长匹配和双向最长匹配,它们都基于完全切分
2.3.1完全切分
完全切分:找出一段文本中的所有单词。这并不是标准意义上的分词
2.3.2正向最长匹配
最长匹配算法:在以某个下标为起点递增查词的过程中,优先输出更长的单词
正向最长匹配:该下标的扫描顺序从前往后
2.3.3逆向最长匹配
与正向最长匹配扫描的方向相反
2.3.4双向最长匹配
1、同时执行正向和逆向最长匹配,若两者的词数不同,则返回词数更少的那一个
2、否则,返回两者中单字更少的那一个。当单字数也相同时,优先返回逆向最长匹配的结果
启发式算法:汉语中单字词的数量远远小于非单字词。因此,算法应当尽量减少结果中的单字,保留更多的完整词语
2.3.5速度评测
词典分词的消歧效果不好,但其速度快
(1)同等条件下,python的运行速度比java慢,效率只有java的一半不到
(2)正向匹配和逆向匹配的速度差不多,是双向的两倍。这在意料之中,因为双向匹配做了两倍的工作
(3)java实现的正向匹配比逆向匹配快,可能是内存回收的原因
2.4字典树
2.4.1什么是字典树
字符串集合常用字典树(trie树、前缀树)存储,这是一种字符串上的树形数据结构。
字典树中每条边都对应一个字,从根节点往下的路径构成一个个字符串。字典树并不直接在节点上存储字符串,而是将词语视作根节点到某节点之间的一条路径,并在终点节点上做个标记“该节点对应词语的结尾”。
字符串就是一条路径,要查询一个单词,只需顺着这条路径从根节点往下走。如果能走到特殊标记的节点,则说明该字符串在集合中,否则说明不存在。
2.9准确率评测
2.9.1准确率
准确率(accuracy)是用来衡量一个系统的准确程度(accurate)的值,可以理解为一系列评测指标
在中文分词任务中,一般使用在标准数据集上词语级别的精确率、召回率与F1值来衡量分词器的准确程度
2.9.2混淆矩阵与TP/FN/FP/TN

“纵坐标”(行)为预测结果,“横坐标“(列)为标准答案”
(1)TP(true positive,真阳):预测是P,答案果然是真的P
(2)FP(false positive,假阳):预测是P,答案是N,因此的假的P
(3)TN(ture negative,真阴):预测是N,答案果然是N
(4)FN(false negative,假阴):预测是N,答案是P,因此是假的N
这种图表在机器学习中也称为混淆矩阵(confusion matrix),用来衡量分类结果的混淆程度。其中样本全集等于TP、FP、FN、TN的并集。且TP、FP、FN、TN没有交集
2.9.3精确率
精确率(precision,简称P值)指的是预测结果中正类数量占全部结果的比率,即P=TP/(TP+FP)
2.9.4召回率
召回率(recall,简称R值)指的是正类样本被找出来的比率,即R=TP/(TP+FN)
2.9.5 F1值
精确率和召回率的调和平均F1值:F1=(2*P*R)/(P+R)。这样P和R必须同时较高,才能得到较高的F1值
2.9.6中文分词中的P、R、F1值
在中文分词中,标准答案和分词结果的单词数不一定相等。而且混淆矩阵针对的是分类问题,而中文分词却是一个分块(chunking)问题。因此我们需要将分块问题转化为分类问题
将标准答案的所有区间构成一个集合A,作为正类。集合A之外的所有区间构成另一个集合(A的补集),作为负类。记分词结果所有单词区间构成集合B,则有:
TP并FN等于A(即A为标准答案);TP并FP等于B(即B为预测结果);TP等于A和B的交集;则P值和R值即可计算,注意加上绝对值
2.9.9 OOV Recall Rate与IV Recall Rate
OOV:“未登录词“(Out Of Vocabulary),或者俗称的”新词“,也即词典未收录的词汇
IV:“登录词“(In Vocabulary), IV Recall Rate指的是词典中的词汇被正确召回的概率
第3章 二元语法与中文分词
3.1语言模型
3.1.1什么是语言模型
1、语言模型(Language Model,LM):对语言现象的数学抽象。给定一个句子w,语言模型就能计算出句子的出现概率p(w)
2、语料库:一个小型的样本空间
3、数据稀疏:实际遇到的句子大部分都在语料库之外——意味着它们的概率都被当作0
4、语言模型模拟人说话的顺序:给定已经说出口的词语序列,预测下一个词语的后验概率,一个单词一个单词地乘上后验概率,我们就能估计任意一句话的概率

7、然而随着句子长度的增大,语言模型会遇到两个问题:
(1)数据稀疏:语料库中极有可能统计不到长句子的频次,导致后验概率为零
(2)计算代价大
3.1.2马尔可夫链与二元语法
马尔可夫链:给定时间线上有一串事件顺序发生,假设每个事件的发生概率只取决于前一个事件,那么这串事件构成的因果链被称作马尔可夫链(Markov Chain)
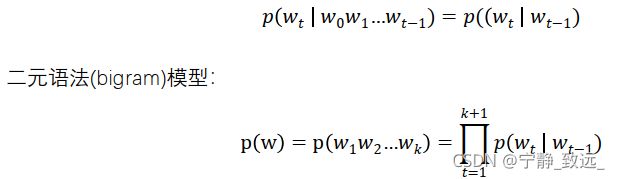
由于语料库中二元接续的重复程度要高于整个句子的重要程度,所以缓解了数据稀疏的问题。另外,二元接续的总数量远远小于句子的数量,长度也更短,存储和查询也得到了解决
3.1.3 n元语法
每个单词的概率仅取决于该单词之前的n-1个单词
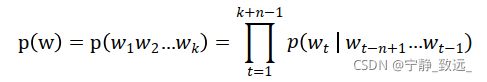
当n=1时的n元语法称为一元语法(unigram);当n=3时的n元语法称为三元语法(trigram);n>=4时数据稀疏和计算代价又变得显著起来;深度学习带了一种递归神经网络语言模型(RNN Language Model),理论上可以记忆无限个单词,可看作“无穷元语法”
3.1.4数据稀疏与平滑策略
对于n元语法模型,n越大,数据稀疏问题越严峻。解决方案是用低阶n元语法去平滑高阶n元语法

3.2中文分词语料库
3.2.1 1998年《人民日报》语料库PKU
(1)前后标注不一致
(2)切分颗粒度太小
(3)存在明显标注错误
(4)所有姓名都被拆分为姓氏和名字,不符合习惯
无论何种算法,PKU语料库上的准确率普遍低于其他语料库
3.2.2微软亚洲研究院语料库MSR
(1)标注一致性上MSR要优于PKU
(2)切分颗粒度上MSR要大于PKU
(3)MSR中姓名作为一个整体,更符合习惯
(4)MSR量级是PKU的两倍
(5)但PKU比MSR更流行
3.2.3繁体中文分词语料库
SIGHAN05中剩下的两份都是繁体中文语料库,分别是香港大学提供的CITYU和台湾中央研究院提供的AS。短平快的解决方案则是将繁体字符转换为简体字符,追求精致的话则需要本地语料库
3.2.4语料库统计
统计语料库字数、词语种数和总词频等。
1、词语种数:语料库中有多少个不重复的词语,用来衡量语料库用语的丰富程度
2、总词频:所有词语的词频之和,用来衡量语料库用语的规模大小
(1)语料库规模:AS>MSR>CITYU>PKU
(2)从OOV的角度讲,语料库的难度:CITYU>PKU>AS>MSR
(3)由齐夫定律得出,长词都是低频词,对平均词长的影响很小
(4)汉语常用词汇约在10万这个量级
3.3训练
训练(train)指的是,给定样本集(dataset,训练所用的样本集称为训练集)估计模型参数的过程。训练也称为编码(encoding),因为学习算法将知识以参数的形式编码(encode)到模型中
3.3.2统计一元语法
一元语法其实就是单词
3.3.3统计二元语法
3.4预测
预测(predict)指的是利用模型对样本(句子)进行推断的过程,在中文分词任务中也就是利用模型推断分词序列。有时候预测也称为解码(decode)
3.4.2构建词网
1、词网:句子中所有一元语法构成的网状结构。
2、词网必须保证从起点出发的所有路径都会连通到终点。
3、从起点到终点的每条路径代表句子的一种分词方式,二元语法语言模型的解码任务就是找出其中最合理的那条路径
3.4.3节点间的距离计算

3.4.4词图上的维特比算法
由马尔可夫链构成的网状图,该特例上的最短路径算法称为维特比算法(Viterbi Algorithm)。维特比算法分为前向(forward)和后向(backward)两个步骤。
(1)前向:由起点出发从前往后遍历节点,更新从起点到该节点的最小花费以及前驱指针
(2)后向:由终点出发从后往前回溯前驱指针,取得最短路径
3.5评测
3.5.1标准化评测
评测分为训练、预测、计算准确率3步
3.5.2误差分析
二元语法消歧能力尚可,OOV召回能力太低。这是因为词网中几乎所有的中文词语都来自于训练集词典,自然无法召回新词
第4章 隐马尔可夫模型与序列标注
由字构词是“序列标注”模型的一种应用。在所有序列标注模型中,隐马尔可夫模型是最基础的一种
4.1序列标注问题

4.1.1序列标注与中文分词
中文分词标注集并非只有一种。其中最流行的标注集为{B,M,E,S}
其中B:词首(Begin);M:词中(Middle);E:词尾(End);S:单字(Single)
4.1.2序列标注与词性标注
X是单词序列,y是相应的词性序列
词性标注集也不是唯一的,其中最著名的是863标注集和北大标注集,前者的词性数量要少一些,颗粒度要大一些
4.1.3序列标注与命名实体识别
命名实体:现实存在的实体,是OOV的主要组成部分
命名实体识别可以复用BMES标注集,并沿用中文分词的逻辑,只不过标注的对象由字符变为单词,同时还需要确定实体所属的类别
4.2隐马尔可夫模型
隐马尔可夫模型(Hidden Markov Model,HMM):描述两个时序序列联合分布p(x,y)的概率模型。X序列外界可见,称为观测序列(obserbation sequence);y序列外界不可见,称为状态序列(state sequence)
隐马尔可夫模型之所以“隐”,是因为状态序列不可见,是待求得因变量。因此也称状态为隐状态(hidden state),称观测为显状态(visible state)。隐马尔可夫模型之所以称为“马尔可夫模型”,是因为它满足马尔可夫假设
4.2.1从马尔可夫假设到隐马尔可夫模型

4.2.2初始状态概率向量

4.2.3状态转移概率矩阵

4.2.4发射概率矩阵

4.2.5隐马尔可夫模型的三个基本用法
(1)样本生成问题
(2)模型训练问题
(3)序列预测问题
4.4隐马尔可夫模型的训练
![]()
4.4.1初始状态概率向量的估计
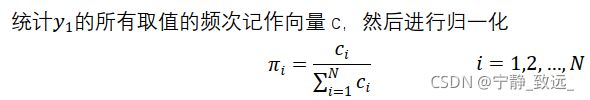
4.4.2转移概率矩阵的估计

4.4.3发射概率矩阵的估计

4.5隐马尔可夫模型的预测
求解序列标注问题:给定观测序列,求解最可能的状态序列及其概率
4.5.1概率计算的前向算法

4.5.2搜索状态序列的维特比算法
由联合概率可知,寻找最大概率所对应的状态序列是一个搜索问题。则将每个状态作为有向图中的一个节点,节点间的距离由转移概率决定,节点本身的花费由发射概率决定。那么所有备选状态构成一幅有向无环图,待求的概率最大的状态序列就说图中最长的路径,此时的搜索算法称为维特比算法
维特比算法步骤:
(1)初始化,t=1时初始最优路径的备选由N个状态组成,它们的前驱为空
(2)递推,t>=2时每条备选路径吃入一个新状态,长度增加1个单位,根据转移概率和发射概率计算花费。找出新的局部最优路径,更新两个数组
(3)终止,找出最终时刻备选状态数组的最大概率,以及相应的结尾状态下标
(4)回溯,根据前驱数组回溯到前驱状态,取得最优路径下标
4.6隐马尔可夫模型应用于中文分词
4.6.1标注集
标注集(tagset):也称为词表(vocabulary),将标注集{B,M,E,S}映射到连续的整型id,将字符映射为另一套连续id
4.6.2字符映射
字符作为观测变量,必须是整型才可被隐马尔可夫模型接受
4.6.3语料转换
必须转换为(x,y)二元组才能训练隐马尔可夫模型
4.6.4训练
4.6.5预测
训练完隐马尔可夫模型后,模型的预测结果是{B,M,E,S}标签序列。分词器必须根据标签序列的指示,将字符序列转换为单词序列。由于任何模型的输出都不可能完全合法(即存在分词错误情况),所以一个健壮的分词器必须兼容这些非法的序列
4.6.6评测
4.6.7误差分析
隐马尔可夫模型的OOV召回率提升了,但IV却记不住,存在欠拟合现象,可以考虑提升模型复杂度。但单靠提升转移概率矩阵的复杂度并不能提高模型的拟合能力
第5章 感知机分类与序列标注
隐马尔可夫模型假设人们说的话仅仅取决于一个隐藏的{B,M,E,S}序列,能捕捉到的特征仅限于两种:前一个标签和当前标签
线性模型(linear model):用一条线性的直线或平面将数据一分为二。它由两部分构成:一系列用来提取特征的特征函数,以及相应的权重向量
5.1分类问题
5.1.1定义:
分类(classification)指的是预测样本所属类别的一类问题。分类问题的目标就说给定输入样本x,将其分配给k种类别中的一种,其中k=1, … , k。如果k=2,则称为二分类(binary classification),否则称为多分类(multiclass classification)
二进制可以解决任意类别数的多分类问题,具体方法:
(1)one-vs-one:进行多轮二分类,每次区分两种类别
(2)one-vs-rest(one-vs-all):进行多轮二分类,每次区分当前类别和非当前类别。计算成本低,但当正负样本数量不均匀时会降低分类准确率
5.1.2应用
在NLP领域,绝大部分任务可以用分类解决
5.2线性模型和感知机算法
5.2.1特征向量与样本空间
特征向量:描述样本特征的向量
特征提取:构造特征向量的过程
5.2.2决策边界与分离超平面

线性可分:数据集中所有样本都可以被分离超平面分割。相应的存在线性不可分的数据集,此时的决策边界为曲线(曲面)
对于线性不可分的数据,依然可以利用线性模型分类。要么定义更多特征,要么使用支持向量机(SVM)中的基函数(basis function)将数据映射到高维空间。两种方法都增加了样本空间的维度,一般而言,维度越高,数据越容易呈现线性可分性
5.2.3感知机算法
感知机算法(Perceptron Algorithm)是一种迭代式算法:在训练集上运行多个迭代,每次读入一个样本,执行预测,将预测结果与正确答案进行对比,计算误差,根据误差更新模型参数

5.2.5投票感知机和平均感知机
产生原因:感知机每次迭代都会产生一个新模型,不知道哪个更好
投票感知机:在感知机算法的基础上,每次迭代的模型都保留,准确率也保留。预测时每个模型都给出自己的结果,乘以它的准确率加权平均值作为最终结果。因为每正确预测一个样本,该模型就得一票,票数最多的模型对结果的影响最大。因为要存储多个模型及加权,计算开销较大
平均感知机:取多个模型权重的平均。其优势在于预测时不再需要保存多个模型,而是在训练结束后将所有模型平均,只保留平均后的模型。在实现上,也不保留多个模型,而是记录模型中每个参数在所有迭代时刻的总和,将总和除以迭代次数,就能得到该参数的平均值。

5.4结构化预测
自然语言处理问题大致可分为两类:分类问题、结构化预测问题(例如序列标注)
对感知机作拓展,分类器也能支持结构化预测
5.4.1定义
1、结构化:信息的层次结构特点
2、结构化预测(structured prediction):预测对象结构的一类监督学习问题
3、结构化学习(structured learning):相应的模型训练过程
分类问题的预测结果是一个决策边界;回归问题的预测结果是一个实际标量;结构化预测的结果是一个完整的结构。因此,结构化预测难度更高
5.4.2结构化预测与学习的流程

5.5线性模型的结构化感知机算法
5.5.1结构化感知机算法


5.5.2结构化感知机与序列标注



5.5.3结构化感知机的维特比解码算法
在解空间中搜索分数最高的结构。具体到序列标注中,结构特化为序列。对序列的搜索算法,就说维特比算法


5.6基于结构化感知机的中文分词
感知机序列标注框架的基础是线性模型,根据训练算法派生了两个子类:结构化感知机和平均感知机
5.6.1特征提取
无论是训练还是预测,第一道工序都是特征提取
5.6.4创建感知机分词器
5.6.5准确率与性能
任何NLP任务的最后一步都是标准化评测。任何准确率都与语料库规模、算法模型相关
结构化感知机准确率稍高于平均感知机,并且训练速度更快,但结构化感知机的成绩波动很大,不如平均感知机稳定
5.6.7中文分词特征工程
如果反复在线学习依然无法正确分词,可以重载感知机分词器的特征提取部分,进行特征工程。

学院派的分词器使用的特征:叠字、四元词语、词典特征和偏旁部首
第6章 条件随机场与序列标注
条件随机场与感知机同属结构化学习大家族,但性能比感知机还要强大
6.1机器学习的模型谱系
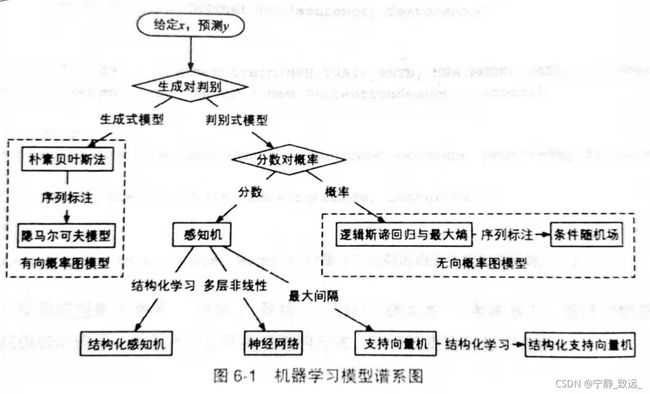
6.1.1生成式模型与判别式模型


6.1.2 有向与无向概率图模型
概率图模型(Probabilistic Graphical Model,PGM)是用来表示与推断多维随机变量联合分布p(x,y)的强大框架,它利用节点V来表示随机变量,用边E连接有关联的随机变量,将多维随机变量分布表示为图G=(V,E)。这样可以使整个图分解为子图再进行分析。子图中的随机变量更少,建模更加简单。而有向图模型和无向图模型就是分解图的方法
有向图模型(Directed Graphical Model,DGM)按事件的先后因果顺序将节点连接为有向图。如果事件A导致事件B,则用箭头连接两个事件A→B

无向图模型则不探究每个事件的因果关系,不涉及条件概率分解。无向图模型的边没有方向,仅仅代表两个事件有关联。
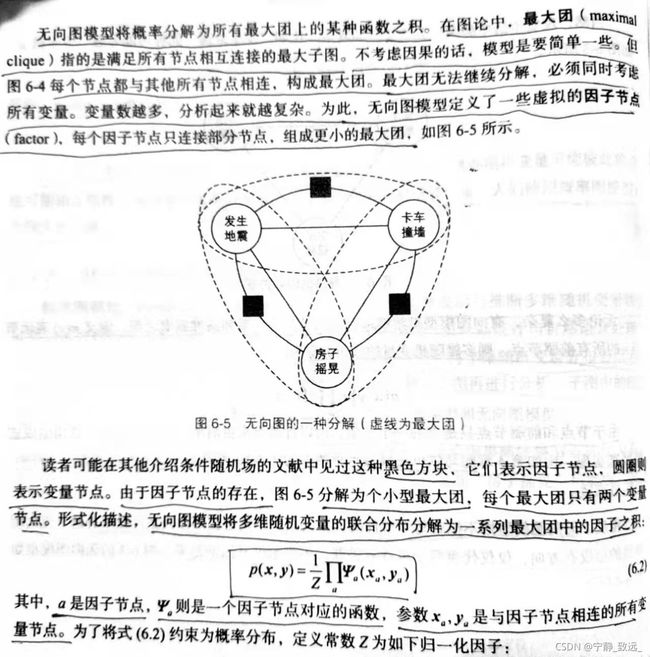

6.2条件随机场
条件随机场(conditional Random Field,CRF)是一种给定输入随机变量x,求解条件概率p(y | x)的概率无向图模型。用于序列标注时,特例化为线性链(linear-chain)条件随机场。此时,输入输出随机变量为等长的两个序列
6.2.1线性链条件随机场

(1)条件随机场和结构化感知机的特征函数完全一致
(2)结构化感知机对某预测打分越高,条件随机场给予该预测的概率也越大
(3)条件随机场和结构化感知机的预测算法一致,都是维特比算法
6.2.3条件随机场与结构化感知机的对比
相同点:特征函数多;权重向量相同;打分函数相同;预测算法相同;同属结构化学习
不同点:训练算法不同,这是两者准确率差异的唯一原因
感知机算法属于在线学习,每次参数更新只使用一个训练实例。而没有考虑整个数据集,所以在线学习会顾此失彼。
条件随机场对数似然函数及其梯度则定义在整个数据集之上,每次参数更新都是全盘考虑
第7章 词性标注
7.1词性标注概述
7.1.1什么是词性
词性(Part-Of-Speech,POS):单词的语法分类,也称为词类。提供词语的抽象表示
词性标注集:所有词性的集合
7.1.2词性的用处
可以通过OOV的词性猜测用法,而不至于将所有OOV混为一谈(当成同一特殊标记UNK)
7.1.3词性标注
词性标注:为句子中每个单词预测一个词性标签
7.1.4词性标注模型
1、序列标注模型可用来做词性标注
2、词性标注既可以看作中文分词的后续任务,也可以与中文分词集成为同一任务
3、联合模型(joint model):同时进行多个任务的模型
由于综合了多种监督信号,联合模型在几乎所有问题上都优于独立模型,但实际应用中并不理想。原因:中文分词语料库远远多于词性标注语料库;联合模型特征数量一般是独立模型的数十倍
7.2词性标注语料库与标注集
7.2.1《人民日报》语料库与PKU标注集
7.2.2国家语委语料库与863标注集
7.2.3《诛仙》语料库与CTB标注集
7.3序列标注模型应用于词性标注
7.3.1基于隐马尔可夫模型的词性标注
隐马尔可夫模型可以应对词性标注中的兼类词问题,但无法应对OOV词性标注问题
7.3.2基于感知机的词性标注
具备识别OOV词性的能力
7.3.3基于条件随机场的词性标注
7.3.4词性标注评测

第8章 命名实体识别
8.1概述
8.1.1命名实体
命名实体(named entity):文本中描述实体的词汇。
特点:数量无穷;构词灵活;类别模糊
8.1.2命名实体识别
命名实体识别(Named Entity Recognition,NER):识别出句子中命名实体的边界与类别。是一个统计为主,规则为辅的任务
8.3命名实体识别语料库
8.3.1 1998年《人民日报》语料库
因为1998年《人民日报》语料库颗粒度小,适合作为命名实体识别语料库。
并非所有复合词都是命名实体
8.3.2微软命名实体识别语料库(MSRA Named Entity Corpus,MSRA-NE)
8.5基于序列标注的命名实体识别
命名实体识别可以看作分词与词性标注任务的集合
8.5.1特征提取
特征模板确定后,就可以训练序列标注模型了
8.5.2基于隐马尔可夫模型序列标注的命名实体识别
隐马尔可夫模型无法利用词性特征
8.5.3基于感知机序列标注的命名实体识别
8.5.4基于条件随机场序列标注的命名实体识别
8.5.5命名实体识别标准化评测
准确率与评测策略、特征模板、语料库规模相关
第9章 信息抽取
9.1新词提取
9.1.1概述
新词:OOV
9.1.2基本原理
新词提取:首先提取出大量文本(生语料)中的词语,无论新旧。然后用词典过滤掉已有的词语,于是得到新词
9.1.3信息熵
信息熵(entropy):某条消息所含的信息量。反映的是听说某个消息后该事件的不确定性的减少量
对于离散型随机变量X,信息熵的公式为:(对数函数的底为2是单位为比特)
具体到新词提取中,给定字符串S作为词语备选,X定义为该字符串左边可能出现的字符(简称左邻字),则称H(x)为S的左信息熵,类似的,定义右信息熵H(Y)
左右信息熵越大,说明字符串可能的搭配就越丰富,该字符串就是一个词的可能性就越大。但还要考虑词语内部片段的凝聚程度,这种凝聚程度由互信息衡量
9.1.4互信息


总词频并不影响互信息大小的排名
有了左右信息熵和互信息之后,将两个指标低于一定阈值的片段过滤掉,剩下的片段按频次降序排列,截取最高频次的N个片段
9.1.5实现
9.2关键词提取
提取文章中重要的单词,而不限于词语的新鲜程度
1、无监督关键词提取算法:词频、TF-IDF和TextRank
2、单文档算法:词频、TextRank
3、多文档算法:TF-IDF。利用了其他文档中的信息辅助决定当前文档的关键词,同时容易受到噪声干扰
9.2.1词频统计
文章中反复出现的词语并不一定是关键词,在进行词频统计之前要进行停用词过滤
词频统计流程:分词、停用词过滤、按词频取前n个
9.2.2 TF-IDF


TF-IDF适用于大型语料库中,当我们没有大型的语料库或者存储IDF的内存,同时又想改善词频统计的效果,则可以使用TextRank算法
9.2.3TextRank
TextRank是PageRank在文本上的应用


9.3短语提取
利用互信息和左右信息熵,可以将新词提取算法拓展到短语提取。将新词提取中的字符替换为单词,字符串替换为单词列表
(即新词提取考虑的是提取单词,而短语提取考虑的是提取单词组合)
9.4关键句提取
9.4.1 BM25
BM25是TF-IDF的一种改进变种。TF-IDF衡量的是单个词语在文档中的重要程度。而BM25衡量的是多个词语与文档的关联程度

9.4.2 TextRank

第10章 文本聚类
10.1概述
10.1.1聚类
聚类(cluster analysis):将给定对象的集合划分为不同子集的过程。目标是使得每个子集内部的元素尽量相似,不同子集间的元素尽量不相似。这些子集被称为簇(cluster),一般没有交集
1、硬聚类(hard clustering):每个元素被确定地归入一个簇(使用更频繁)
2、软聚类(soft clustering):每个元素与每个簇都存在一定地从属程度(隶属度),只不过该程度有大有小
硬聚类中从属关系是离散地,非常强硬。而软聚类中的从属关系则用一个连续值来衡量,比较灵活
3、划分(partitional)聚类:聚类结果是一系列不相交的子集
4、层次(hierarchical)聚类:聚类结果是一棵树,叶子节点是元素,父节点是簇
10.1.2聚类的应用
聚类通常用于数据的预处理,或归档相似的数据
数据量很大、标注成本过高时,聚类常常是唯一可行的方案
10.1.3文本聚类
1、文本聚类或文档聚类(text clustering或document clustering):对文档进行聚类分析
2、基本流程:特征提取、向量聚类
3、聚类的对象:抽象的向量(一维数据点)。
4、特征提取:将文档表示为向量
10.2文档的特征提取
10.2.1词袋模型
词袋(bag-of-words):将文档想象为一个装有词语的袋子,通过袋子中每种词语的计数等统计量将文档表示为向量
由于词袋模型不考虑词序,损失了词序中蕴含的语义。但在实际工程中,词袋模型依然是一个和很难打败的基线模型
10.2.2词袋的统计指标
词袋模型除了选取词频作为统计指标外,常见的统计量还包括:
(1)布尔词频:词频非零则取值为1,否则为0
(2)TF-IDF
(3)词向量:如果词语本身也是某种向量的话,则将所有词语的词向量求和作为文档向量
词频向量适合主题较多的数据集;布尔词频适用于长度较短的数据集;TF-IDF适用于主题较少的数据集;词向量适用于处理OOV问题严重的数据集
神经网络模型也能无监督地生成文档向量,比如自动编码器和受限玻尔兹曼机等。且得到地文档向量一般优于词袋向量,但代价是计算开销大

10.3 k均值算法

10.5标准化评测
10.5.1 P、R和F1值
J:簇;i:类别;:簇j中类别i文档的数目;:簇j中的文档总数;:类别i中的文档总数

第12章 依存句法分析
语法分析(syntactic parsing):发生在词法分析之后,目标是分析句子的语法结构并将其表示为容易理解的结构(通常是树形结构)
12.2依存句法树
依存句法树关注的是句子中词语的语法联系,并将其约束为树形结构
12.2.1依存句法理论
1、从属词(dependent):如果一个词修饰另一个词,称修饰词为从属词
2、支配词(head):如果一个词修饰另一个词,称被修饰词为支配词
3、依存关系:(dependency relation):从属词和支配词之间的语法关系
4、依存句法树(dependency parse tree):将一个句子中所有词语的依存关系以有向边的形式表示出来,就会得到一棵树
5、依存句法树的特点:
(1)根节点唯一性:有且只有一个词语(ROOT,虚拟根节点,简称虚根)不依存于其他词语
(2)连通:除虚根外的所有单词必须依存于其他单词
(3)无环:每个单词不能依存多个单词
(4)投射性(projective):如果A依存于B,那么位置处于A和B之间的单词C只能依存于A、B或AB之间的单词
12.2.2中文依存句法树库
依存句法树库:由大量人工标注的依存句法树组成的语料库。最有名的是UD(Universal Dependencies)。另一份著名的语料库为CTB,不过需要额外利用一些工具将短语结构树转换为依存句法树
12.2.3依存句法树库的可视化
1、南京大学汤光超的Dependency Viewer,适用于windows用户
2、基于web的跨平台工具:brat标注工具
12.3依存句法分析
依存句法树(dependency parsing):输入词语和词性,输出一棵依存句法树
12.4基于转移的依存句法分析
12.4.1 Arc-Eager转移系统
转移系统(transition system):负责制定所有可执行的动作以及相应的条件


12.4.2特征提取


12.4.3 Static和Dynamic Oracle
对基于转移的依存句法分析器而言,它学习和预测的对象是一系列转移动作。然而依存句法树库是一棵树,并不是现成的转移动作序列。这时候就需要一个算法将语料库中的依存句法树转换为正确的(gold)转移动作序列,以供机器学习模块学习。这种正确的转移动作序列称为规范(oracle),其质量好坏直接影响到机器学习模块的学习效果
1、静态规范(static oracle):人工编写一些规则为每棵树生成一个规范
2、动态规范(dynamic oracle):不显式地输出唯一规范,而是让机器学习模型自由试错,一旦无法拼装出正确语法树,则惩罚模型
至于如何判断一个状态c执行某个动作后是否抵达正确句法树,只需根据该动作以及该状态的栈与队列进行判断即可
实现了动态规划的结构化感知机训练算法的流程如下:
(1)读入一个训练样本,提取特征。创建ArcEager的初始状态,记做c

通过在训练时故意让模型试错,可以提高模型的稳健性
虽然动态规划使得模型能够自由搜索一条可达正确句法树的转移路径,然而每次转移动作都是贪心地选取分数最高的备选动作,而没有考虑到全局转移动作构成序列的分数之和。
12.5依存句法树分析API
12.5.2标准化评测

12.6案例:基于依存句法树的意见抽取
即提取商品评论中的属性和买家评价
参考文献:《自然语言处理入门》 by 何晗(@hankcs)