Python 词云图:wordcloud库的使用

✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。
个人主页:小嗷犬的博客
个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。
本文内容:Python 词云图:wordcloud库的使用
Python 词云图:wordcloud库的使用
- 1.wordcloud库的安装
- 2.wordcloud库的使用
-
- 2.1 常用函数方法
- 2.2 WordCloud对象常用配置参数
- 2.3 配色集
- 3.生成词云图
1.wordcloud库的安装
wordcloud库是 Python 中一个优秀的第三方词云展示函数库,它可以通过文本来生成词云图,需要通过pip指令安装:
pip install wordcloud
wordcloud库把词云当作一个WordCloud对象
- wordcloud.WordCloud()代表一个文本对应的词云
- 可以根据文本中词语出现的频率等参数绘制词云
- 绘制词云的形状、尺寸和颜色都可以设定
2.wordcloud库的使用
2.1 常用函数方法
wordcloud中的常用函数方法见下表,其中w为WordCloud对象:
| 函数 | 描述 |
|---|---|
| wordcloud.WordCloud() | 根据参数配置词云图对象 |
| w.generate(txt) | 向WordCloud对象中加载文本txt(会根据空格分词) |
| w.to_file(filename) | 将词云输出为图像文件,.png或.jpg格式 |
2.2 WordCloud对象常用配置参数
WordCloud对象常用配置参数如下:
| 参数 | 描述 |
|---|---|
| width | 指定词云对象生成图片的宽度,默认400像素 |
| height | 指定词云对象生成图片的高度,默认200像素 |
| min_font_size | 指定词云中字体的最小字号,默认4号 |
| max_font_size | 指定词云中字体的最大字号,根据高度自动调节 |
| font_step | 指定词云中字体字号的步进间隔,默认为1 |
| font_path | 指定字体文件的路径,默认None |
| max_words | 指定词云显示的最大单词数量,默认200 |
| stopwords | 指定词云的排除词列表,即不显示的单词列表 |
| mask | 指定词云形状,默认为长方形,需要引用imread()函数 |
| background_color | 指定词云图片的背景颜色,默认为黑色 |
| colormap | 指定词云文字的配色集,默认为’viridis’ |
2.3 配色集
常用配色集如下:
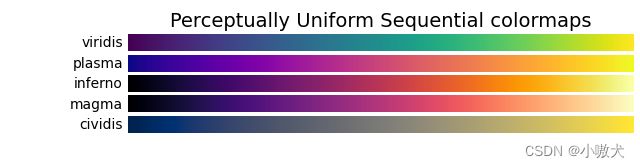

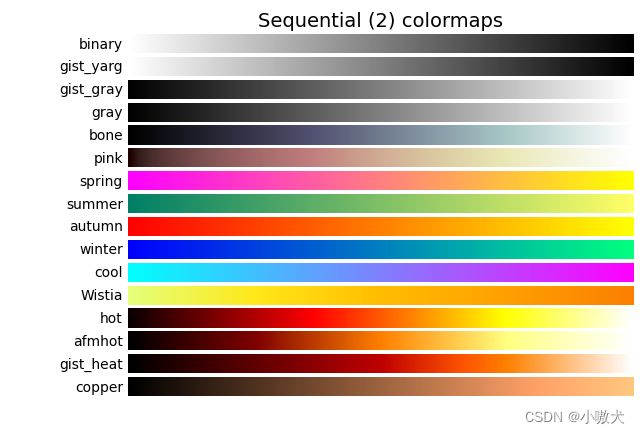
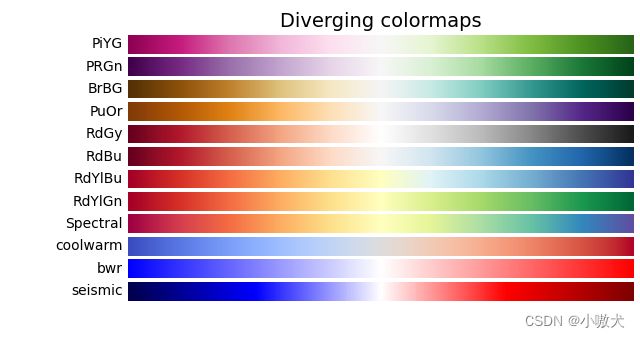

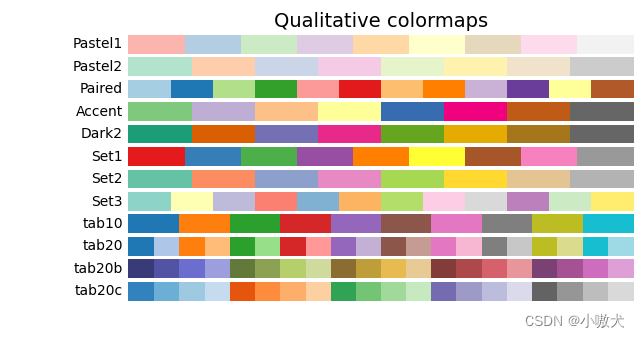
3.生成词云图
结合之前的博客:Python 中文分词:jieba库的使用,我们可以尝试生成第一张词云图了:
import jieba
import wordcloud
from imageio import imread
# 排除词库
excludes = {
'两个', '一个', '只见', '如何', '那里', '说道', '这里', '出来', '这个', '今日', '便是', '问道',
'起来', '甚么', '因此', '却是', '我们', '正是', '三个', '如此', '且说', '不知', '不是', '只是',
'次日', '不曾', '不得', '一面', '看时', '不敢', '如今', '来到', '当下', '原来', '喝道', '只得',
'里面', '大喜', '一齐', '商议', '那个', '公人', '将来', '前面', '那厮', '城中', '下山', '不见',
'怎地', '上山', '随即', '不要'
}
# 读入水浒传,分词,并以空格连接
txt = open("Documents/《水浒传》.txt", "r", encoding='utf-8').read()
words = jieba.lcut(txt)
txt0 = ''
for i in words:
if len(i) > 1:
txt0 += ' '
txt0 += i
txt0.replace('宋江道', '宋江') # 纠正错误分词
mk = imread('皮卡丘.jpg') # 设置蒙版为皮卡丘
w = wordcloud.WordCloud(
width=1920,
height=1080, # 设置图片长宽为1080p
background_color='white', # 设置背景颜色为白色
font_path='C://Windows//Fonts/msyh.ttc', # 设置字体为微软雅黑
max_words=300, # 设置词汇最大数量为300
stopwords=excludes, # 设置排除词库
mask=mk, # 设置蒙版
colormap='magma' # 设置配色集为magma
)
w.generate(txt0)
w.to_file('img.png')
生成结果:

借助
wordcloud库,我们可以绘制出很多各式各样的词云图,快去动手尝试一下吧!