Diffusion model理论推导
直观理解Diffusion model
生成式模型本质上是一组概率分布。如下图所示,左边是一个训练数据集,里面所有的数据 p d a t a p_{data} pdata都是从某个数据中独立同分布取出的随机样本。右边就是其生成式模型(概率分布),在这种概率分布中,找出一个分布 p θ p_θ pθ使得它离 p d a t a p_{data} pdata的距离最近。接着在上采新的样本,可以获得源源不断的新数据。

但是往往 p d a t a p_{data} pdata的形式是非常复杂的,而且图像的维度很高,我们很难遍历整个空间,同时我们能观测到的数据样本也有限。
Diffusion做的是什么事呢?
我们可以将任意分布,当然也包括我们感兴趣的 p d a t a p_{data} pdata,不断加噪声,使得他最终变成一个纯噪声分布 N ( 0 , I ) N(0,I) N(0,I)。怎么理解呢?
从概率分布的角度来看,考虑下图瑞士卷形状的二维联合概率分布 p ( x , y ) p(x,y) p(x,y),扩散过程q非常直观,本来集中有序的样本点,受到噪声的扰动,向外扩散,最终变成一个完全无序的噪声分布。

而diffusion model其实是图上的这个逆过程,将一个噪声分布 N ( 0 , I ) N(0,I) N(0,I)逐步地去噪以映射到 p d a t a p_{data} pdata,有了这样的映射,我们从噪声分布中采样,最终可以得到一张想要的图像,也就是可以做生成了。
而从单个图像样本来看这个过程,扩散过程 q q q就是不断往图像上加噪声直到图像变成一个纯噪声,逆扩散过程就是从纯噪声生成一张图像的过程。
形式化解析Diffusion model
Diffusion Models 既然叫生成模型,这意味着 Diffusion Models 用于生成与训练数据相似的数据。从根本上说,Diffusion Models 的工作原理,是通过连续添加高斯噪声来破坏训练数据,然后通过反转这个噪声过程,来学习恢复数据。
训练后,可以使用 Diffusion Models 将随机采样的噪声传入模型中,通过学习去噪过程来生成数据。也就是下面图中所对应的基本原理,不过这里面的图仍然有点粗。

更具体地说,扩散模型是一种隐变量模型(latent variable model),使用马尔可夫链(Markov Chain, MC)映射到 latent space。通过马尔可夫链,在每一个时间步 t 中逐渐将噪声添加到数据 x i x_{i} xi中以获得后验概率 q ( x 1 : T ∣ x 0 ) q(x_{1:T} | x_0) q(x1:T∣x0),其中 x 1 , . . . , x T x_1,...,x_T x1,...,xT 代表输入的数据同时也是 latent space。也就是说 Diffusion Models 的 latent space与输入数据具有相同维度。
补充: 后验概率:在贝叶斯统计中,一个随机事件或者一个不确定事件的后验概率(Posterior probability)是在考虑和给出相关证据或数据后所得到的条件概率。
马尔可夫链为状态空间中经过从一个状态到另一个状态的转换的随机过程。该过程要求具备“无记忆”的性质:下一状态的概率分布只能由当前状态决定,在时间序列中它前面的事件均与之无关。这种特定类型的“无记忆性”称作马可夫性质。
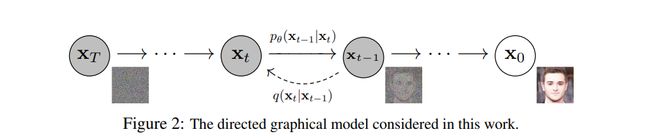
Diffusion Models 分为正向的扩散过程和反向的逆扩散过程。下图为扩散过程,从 x T x_T xT到最后的 就是一个马尔可夫链,表示状态空间中经过从一个状态到另一个状态的转换的随机过程。而下标则是 Diffusion Models 对应的图像扩散过程。
最终,从 x 0 x_0 x0输入的真实图像,经过 Diffusion Models 后被渐近变换为纯高斯噪声的图片 x T x_T xT。
模型训练主要集中在逆扩散过程。训练扩散模型的目标是,学习正向的反过程:即训练概率分布 p θ ( x t − 1 ∣ x t ) p_θ(x_{t-1}|x_t) pθ(xt−1∣xt)。通过沿着马尔可夫链向后遍历,可以重新生成新的数据 x 0 x_0 x0 。
读到这里就有点意思啦,Diffusion Models 跟 GAN 或者 VAE 的最大区别在于不是通过一个模型来进行生成的,而是基于马尔可夫链,通过学习噪声来生成数据。
除了生成很好玩的高质量图片之外呢,Diffusion Models 还具有许多其他好处,其中最重要的是训练过程中没有对抗了,对于 GAN 网络模型来说,对抗性训练其实是很不好调试的,因为对抗训练过程互相博弈的两个模型,对我们来说是个黑盒子。另外在训练效率方面,扩散模型还具有可扩展性和可并行性,那这里面如何加速训练过程,如何添加更多数学规则和约束,扩展到语音、文本、三维领域就很好玩了,可以出很多新文章。
详解 Diffusion Model
上面已经清晰表示了 Diffusion Models 由正向过程(或扩散过程)和反向过程(或逆扩散过程)组成,其中输入数据逐渐被噪声化,然后噪声被转换回源目标分布的样本。
接下来会是一点点数学,只能说我尽量讲得简单一点,就是个马尔可夫链 + 条件概率分布。核心在于如何使用神经网络模型,来求解马尔可夫过程的概率分布。
Diffusion 前向过程(扩散过程)
所谓前向过程,即往图片上加噪声的过程。虽然这个步骤无法做到图片生成,但是这是理解 diffusion model 以及构建训练样本 GT 至关重要的一步。
给定真实图片样本 x 0 ∼ q ( x ) x_0 \sim q(x) x0∼q(x) ,diffusion 前向过程通过 T T T次累计对其添加高斯噪声,得 x 1 , x 2 , . . . , x T x_1,x_2,...,x_T x1,x2,...,xT,如下图的 q q q过程。每一步的大小是由一系列的高斯分布方差的超参数 { β t ∈ ( 0 , 1 ) } t = 1 T \{\beta_t \in (0,1)\}_{t=1}^{T} {βt∈(0,1)}t=1T来控制的。 前向过程由于每个时刻 t t t只与 t − 1 t-1 t−1时刻有关,所以也可以看做马尔科夫过程:
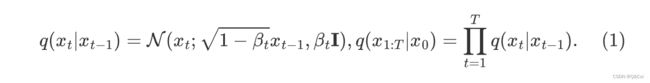
这个过程中,随着 t t t的增大, x t x_t xt越来越接近纯噪声。当 T → ∞ T\to \infty T→∞, x t x_t xt是完全的高斯噪声(下面会证明,且与均值系数的选择 1 − β t \sqrt{1-\beta_t} 1−βt有关。
前向过程介绍结束前,需要讲述一下 diffusion 在实现和推导过程中要用到的两个重要特性。
特性 1:重参数(reparameterization trick)
重参数技巧在很多工作(gumbel softmax, VAE)中有所引用。如果我们要从某个分布中随机采样 (高斯分布) 一个样本,这个过程是无法反传梯度的。而这个通过高斯噪声采样得到$x_t $ 的过程在 diffusion 中到处都是,因此我们需要通过重参数技巧来使得他可微。
最通常的做法是把随机性通过一个独立的随机变量 ( ϵ \epsilon ϵ) 引导过去。即如果要从高斯分布 z ∼ N ( z ; μ θ , δ θ 2 I ) z \sim N(z;\mu_{\theta},\delta^{2}_{\theta}I) z∼N(z;μθ,δθ2I)采样一个 ,我们可以写成:
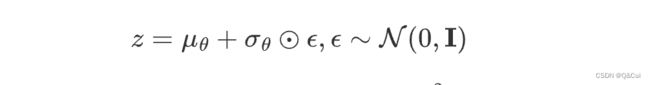
上式的 z z z依旧是有随机性的, 且满足均值为 μ θ \mu_{\theta} μθ 方差为 δ θ 2 \delta^{2}_{\theta} δθ2的高斯分布。这里的 μ θ \mu_{\theta} μθ , δ θ 2 \delta^{2}_{\theta} δθ2可以是由参数 θ \theta θ的神经网络推断得到的。整个 “采样” 过程依旧梯度可导,随机性被转嫁到了上 ϵ \epsilon ϵ。
特性 2:任意时刻的 x t x_t xt可以由 x 0 x_0 x0和 β t \beta_t βt表示
在前向过程中,有一个性质非常棒,就是我们其实可以通过 x 0 x_0 x0和 β \beta β直接得到 x t x_t xt。
x t = α t x t − 1 + 1 − α t ϵ t − 1 ;where ϵ t − 1 , ϵ t − 2 , ⋯ ∼ N ( 0 , I ) = α t α t − 1 x t − 2 + 1 − α t α t − 1 ϵ ˉ t − 2 ;where ϵ ˉ t − 2 merges two Gaussians (*). = … = α ˉ t x 0 + 1 − α ˉ t ϵ q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) \begin{aligned} \mathbf{x}_t &= \sqrt{\alpha_t}\mathbf{x}_{t-1} + \sqrt{1 - \alpha_t}\boldsymbol{\epsilon}_{t-1} & \text{ ;where } \boldsymbol{\epsilon}_{t-1}, \boldsymbol{\epsilon}_{t-2}, \dots \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) \\ &= \sqrt{\alpha_t \alpha_{t-1}} \mathbf{x}_{t-2} + \sqrt{1 - \alpha_t \alpha_{t-1}} \bar{\boldsymbol{\epsilon}}_{t-2} & \text{ ;where } \bar{\boldsymbol{\epsilon}}_{t-2} \text{ merges two Gaussians (*).} \\ &= \dots \\ &= \sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon} \\ q(\mathbf{x}_t \vert \mathbf{x}_0) &= \mathcal{N}(\mathbf{x}_t; \sqrt{\bar{\alpha}_t} \mathbf{x}_0, (1 - \bar{\alpha}_t)\mathbf{I}) \end{aligned} xtq(xt∣x0)=αtxt−1+1−αtϵt−1=αtαt−1xt−2+1−αtαt−1ϵˉt−2=…=αˉtx0+1−αˉtϵ=N(xt;αˉtx0,(1−αˉt)I) ;where ϵt−1,ϵt−2,⋯∼N(0,I) ;where ϵˉt−2 merges two Gaussians (*).
由于两个独立高斯分布可加性,即 N ( 0 , σ 1 2 I ) \mathcal{N}(\mathbf{0}, \sigma_1^2\mathbf{I}) N(0,σ12I)和 N ( 0 , σ 1 2 I ) \mathcal{N}(\mathbf{0}, \sigma_1^2\mathbf{I}) N(0,σ12I) ,所以因此在推导的第二行,我们混合两个高斯分布得到标准差为 ( 1 − α t ) + α t ( 1 − α t − 1 ) = 1 − α t α t − 1 \sqrt{(1 - \alpha_t) + \alpha_t (1-\alpha_{t-1})} = \sqrt{1 - \alpha_t\alpha_{t-1}} (1−αt)+αt(1−αt−1)=1−αtαt−1。的混合高斯分布。因此任意时刻的 x t x_t xt满足:
q ( x t − 1 ∣ x t , x 0 ) = N ( x t − 1 ; μ ~ ( x t , x 0 ) , β ~ t I ) q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0) = \mathcal{N}(\mathbf{x}_{t-1}; \color{blue}{\tilde{\boldsymbol{\mu}}}(\mathbf{x}_t, \mathbf{x}_0), \color{red}{\tilde{\beta}_t} \mathbf{I}) q(xt−1∣xt,x0)=N(xt−1;μ~(xt,x0),β~tI) 。
实际上 β t \beta_t βt随着 t t t增大是递增的,即 β 1 < β 2 < ⋯ < β T \beta_1 < \beta_2 < \dots < \beta_T β1<β2<⋯<βT 。在 GLIDE 的 code 中, 是由 0.0001 到 0.02 线性插值(以 为基准, 增加, 对应增大)。因此 α ˉ 1 > ⋯ > α ˉ T \bar{\alpha}_1 > \dots > \bar{\alpha}_T αˉ1>⋯>αˉT。
Diffusion 逆扩散过程
如果说前向过程 (forward) 是加噪的过程,那么逆向过程(reverse) 就是diffusion 的去噪推断过程。
如果我们能够逆转上述过程并从 p ( x t − 1 ∣ x t ) p(x_{t-1}|x_t) p(xt−1∣xt)采样,就可以从高斯噪声 N ( 0 , I ) \mathcal{N}(\mathbf{0}, \mathbf{I}) N(0,I)还原出原图分布 。在文献7中证明了如果p(x_t|x_{t-1})$满足高斯分布且 β t \beta_t βt足够小, p ( x t − 1 ∣ x t ) p(x_{t-1}|x_t) p(xt−1∣xt)仍然是一个高斯分布。然而我们无法简单推断 ,因此我们使用深度学习模型(参数为 θ \theta θ,目前主流是 U-Net+attention 的结构)去预测这样的一个逆向的分布 (类似 VAE):
p θ ( x 0 : T ) = p ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) p_\theta(\mathbf{x}_{0:T}) = p(\mathbf{x}_T) \prod^T_{t=1} p_\theta(\mathbf{x}_{t-1} \vert \mathbf{x}_t) \quad p_\theta(\mathbf{x}_{t-1} \vert \mathbf{x}_t) = \mathcal{N}(\mathbf{x}_{t-1}; \boldsymbol{\mu}_\theta(\mathbf{x}_t, t), \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t)) pθ(x0:T)=p(xT)∏t=1Tpθ(xt−1∣xt)pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
然而在论文中,作者把条件概率 p θ ( x t − 1 ∣ x t ) p_{\theta}(x_{t-1}|x_t) pθ(xt−1∣xt)的方差直接取了 β t \beta_t βt,而不是上面说的需要网络去估计的 Σ θ ( x t , t ) \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t) Σθ(xt,t),所以说实际上只有均值需要网络去估计(后续论文也有将其变为网络预测的做法.
讲到这里我们就发现其实正向扩散和逆扩散过程都是一个骨架对吧,都是马尔可夫,然后正态分布,然后一步一步的条件概率,唯一的区别就是正向扩散里每一个条件概率的高斯分布的均值和方差都是已经确定的(依赖于 β t \beta_t βt和 x 0 x_0 x0 ),而逆扩散过程里面的均值和方差是我们网络要学出来。
逆扩散条件概率推导
虽然我们无法得到逆转过程的概率分布 q ( x t − 1 ∣ x t ) q(x_{t-1}|x_t) q(xt−1∣xt),但是如果知道 x 0 x_0 x0, q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0)就可以直接写出,这个玩意儿大概是这么个形式:
q ( x t − 1 ∣ x t , x 0 ) = N ( x t − 1 ; μ ~ ( x t , x 0 ) , β ~ t I ) q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0) = \mathcal{N}(\mathbf{x}_{t-1}; \color{blue}{\tilde{\boldsymbol{\mu}}}(\mathbf{x}_t, \mathbf{x}_0), \color{red}{\tilde{\beta}_t} \mathbf{I}) q(xt−1∣xt,x0)=N(xt−1;μ~(xt,x0),β~tI)。
由贝叶斯公式: P ( A ∣ B ) = P ( A ) P ( B ∣ A ) P ( B P(A|B)=\frac{P(A)P(B|A)}{P(B} P(A∣B)=P(BP(A)P(B∣A)
基本的条件概率定理:
乘法定理:若 P ( A ) > 0 P(A)>0 P(A)>0,则:
P ( A B = P ( B ∣ A ) P ( A ) P(AB=P(B|A)P(A) P(AB=P(B∣A)P(A)
P ( A B C ) = P ( A ) P ( B ∣ A ) P ( C ∣ A B ) P(ABC)=P(A)P(B|A)P(C|AB) P(ABC)=P(A)P(B∣A)P(C∣AB)
带入贝叶斯公式: P ( A ∣ B ) = P ( A B ) B P(A|B)=\frac{P(AB)}{B} P(A∣B)=BP(AB)
可以通过贝叶斯公式推导如下:
q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 , x 0 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) ∝ exp ( − 1 2 ( ( x t − α t x t − 1 ) 2 β t + ( x t − 1 − α ˉ t − 1 x 0 ) 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) ) = exp ( − 1 2 ( x t 2 − 2 α t x t x t − 1 + α t x t − 1 2 β t + x t − 1 2 − 2 α ˉ t − 1 x 0 x t − 1 + α ˉ t − 1 x 0 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) ) = exp ( − 1 2 ( ( α t β t + 1 1 − α ˉ t − 1 ) x t − 1 2 − ( 2 α t β t x t + 2 α ˉ t − 1 1 − α ˉ t − 1 x 0 ) x t − 1 + C ( x t , x 0 ) ) ) \begin{aligned} q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0) &= q(\mathbf{x}_t \vert \mathbf{x}_{t-1}, \mathbf{x}_0) \frac{ q(\mathbf{x}_{t-1} \vert \mathbf{x}_0) }{ q(\mathbf{x}_t \vert \mathbf{x}_0) } \\ &\propto \exp \Big(-\frac{1}{2} \big(\frac{(\mathbf{x}_t - \sqrt{\alpha_t} \mathbf{x}_{t-1})^2}{\beta_t} + \frac{(\mathbf{x}_{t-1} - \sqrt{\bar{\alpha}_{t-1}} \mathbf{x}_0)^2}{1-\bar{\alpha}_{t-1}} - \frac{(\mathbf{x}_t - \sqrt{\bar{\alpha}_t} \mathbf{x}_0)^2}{1-\bar{\alpha}_t} \big) \Big) \\ &= \exp \Big(-\frac{1}{2} \big(\frac{\mathbf{x}_t^2 - 2\sqrt{\alpha_t} \mathbf{x}_t \color{blue}{\mathbf{x}_{t-1}} \color{black}{+ \alpha_t} \color{red}{\mathbf{x}_{t-1}^2} }{\beta_t} + \frac{ \color{red}{\mathbf{x}_{t-1}^2} \color{black}{- 2 \sqrt{\bar{\alpha}_{t-1}} \mathbf{x}_0} \color{blue}{\mathbf{x}_{t-1}} \color{black}{+ \bar{\alpha}_{t-1} \mathbf{x}_0^2} }{1-\bar{\alpha}_{t-1}} - \frac{(\mathbf{x}_t - \sqrt{\bar{\alpha}_t} \mathbf{x}_0)^2}{1-\bar{\alpha}_t} \big) \Big) \\ &= \exp\Big( -\frac{1}{2} \big( \color{red}{(\frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}})} \mathbf{x}_{t-1}^2 - \color{blue}{(\frac{2\sqrt{\alpha_t}}{\beta_t} \mathbf{x}_t + \frac{2\sqrt{\bar{\alpha}_{t-1}}}{1 - \bar{\alpha}_{t-1}} \mathbf{x}_0)} \mathbf{x}_{t-1} \color{black}{ + C(\mathbf{x}_t, \mathbf{x}_0) \big) \Big)} \end{aligned} q(xt−1∣xt,x0)=q(xt∣xt−1,x0)q(xt∣x0)q(xt−1∣x0)∝exp(−21(βt(xt−αtxt−1)2+1−αˉt−1(xt−1−αˉt−1x0)2−1−αˉt(xt−αˉtx0)2))=exp(−21(βtxt2−2αtxtxt−1+αtxt−12+1−αˉt−1xt−12−2αˉt−1x0xt−1+αˉt−1x02−1−αˉt(xt−αˉtx0)2))=exp(−21((βtαt+1−αˉt−11)xt−12−(βt2αtxt+1−αˉt−12αˉt−1x0)xt−1+C(xt,x0)))
巧妙地将逆向过程全部变回了前向,即: ( x t − 1 , x 0 ) → x t ; x 0 → x t ; x 0 → x t − 1 (x_{t-1},x_0)\rightarrow x_t; x_0 \rightarrow x_t; x_0 \rightarrow x_{t-1} (xt−1,x0)→xt;x0→xt;x0→xt−1。
请注意,由于前向过程具有 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0)马尔可夫性质实际上等价于
q ( x t − 1 ∣ x t ) q(x_{t-1}|x_t) q(xt−1∣xt)。
由于一般的高斯概率密度函数的指数部分应该写为:
e x p ( − ( x − μ ) 2 ) 2 σ 2 ) = e x p ( − 1 2 ( 1 σ 2 x 2 − 2 μ σ 2 x + μ 2 σ 2 ) ) exp(-\frac{(x-\mu)^2)}{2 \sigma^2}) = exp( -\frac{1}{2} (\frac{1}{\sigma^2} x^2- \frac{2 \mu}{\sigma^2}x+\frac{\mu^2}{\sigma^2})) exp(−2σ2(x−μ)2))=exp(−21(σ21x2−σ22μx+σ2μ2))。
因此稍加整理我们可以得到上面式子中的方差和均值为:
β ~ t = 1 / ( α t β t + 1 1 − α ˉ t − 1 ) = 1 / ( α t − α ˉ t + β t β t ( 1 − α ˉ t − 1 ) ) = 1 − α ˉ t − 1 1 − α ˉ t ⋅ β t μ ~ t ( x t , x 0 ) = ( α t β t x t + α ˉ t − 1 1 − α ˉ t − 1 x 0 ) / ( α t β t + 1 1 − α ˉ t − 1 ) = ( α t β t x t + α ˉ t − 1 1 − α ˉ t − 1 x 0 ) 1 − α ˉ t − 1 1 − α ˉ t ⋅ β t = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 β t 1 − α ˉ t x 0 \begin{aligned} \tilde{\beta}_t &= 1/(\frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}}) = 1/(\frac{\alpha_t - \bar{\alpha}_t + \beta_t}{\beta_t(1 - \bar{\alpha}_{t-1})}) = \color{green}{\frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \cdot \beta_t} \\ \tilde{\boldsymbol{\mu}}_t (\mathbf{x}_t, \mathbf{x}_0) &= (\frac{\sqrt{\alpha_t}}{\beta_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1} }}{1 - \bar{\alpha}_{t-1}} \mathbf{x}_0)/(\frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}}) \\ &= (\frac{\sqrt{\alpha_t}}{\beta_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1} }}{1 - \bar{\alpha}_{t-1}} \mathbf{x}_0) \color{green}{\frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \cdot \beta_t} \\ &= \frac{\sqrt{\alpha_t}(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1 - \bar{\alpha}_t} \mathbf{x}_0\\ \end{aligned} β~tμ~t(xt,x0)=1/(βtαt+1−αˉt−11)=1/(βt(1−αˉt−1)αt−αˉt+βt)=1−αˉt1−αˉt−1⋅βt=(βtαtxt+1−αˉt−1αˉt−1x0)/(βtαt+1−αˉt−11)=(βtαtxt+1−αˉt−1αˉt−1x0)1−αˉt1−αˉt−1⋅βt=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtx0
方差 β ~ t \tilde{\beta}_t β~t放着就不用管了可以拿来用了。
关于均值的话,我们得知 x 0 = 1 α ˉ t ( x t − 1 − α ˉ t ϵ t ) \mathbf{x}_0 = \frac{1}{\sqrt{\bar{\alpha}_t}}(\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon}_t) x0=αˉt1(xt−1−αˉtϵt),因此带入上式可以得到:
μ ~ t = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 β t 1 − α ˉ t 1 α ˉ t ( x t − 1 − α ˉ t ϵ t ) = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ t ) \begin{aligned} \tilde{\boldsymbol{\mu}}_t &= \frac{\sqrt{\alpha_t}(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1 - \bar{\alpha}_t} \frac{1}{\sqrt{\bar{\alpha}_t}}(\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon}_t) \\ &= \color{cyan}{\frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\epsilon}_t \Big)} \end{aligned} μ~t=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtαˉt1(xt−1−αˉtϵt)=αt1(xt−1−αˉt1−αtϵt)
可以看出,在给定 x 0 x_0 x0的条件下,后验条件高斯分布的的均值只和超参数, x t x_t xt,、 ϵ t \epsilon_t ϵt有关,方差只与超参数有关。于是我们得到了我们就得到了 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0)的解析形式。
训练损失
搞清楚逆扩散过程之后,现在算是搞清楚去噪推断过程。但是如何训练 Diffusion Models 以求得公式 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0)的均值 μ θ ( x t , t ) ) \boldsymbol{\mu}_\theta(\mathbf{x}_t, t)) μθ(xt,t))和方差 Σ θ ( x t , t ) ) \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t)) Σθ(xt,t))。
在 VAE 中我们学过极大似然估计的作用:对于真实的训练样本数据已知,要求模型的参数,可以使用极大似然估计。
统计学中,似然函数是一种关于统计模型参数的函数。给定输出 x x x时,关于参数 θ θ θ的似然函数 L ( θ ∣ x ) L(θ|x) L(θ∣x)(在数值上)等于给定参数θ后变量 X X X的概率: L ( θ ∣ x ) = P ( X = x ∣ θ ) L(θ|x)=P(X=x|θ) L(θ∣x)=P(X=x∣θ)。
Diffusion Models 通过极大似然估计,来找到逆扩散过程中马尔可夫链转换的概率分布,这就是 Diffusion Models 的训练目的。即最大化模型预测分布的对数似然,从Loss下降的角度就是最小化负对数似然:
L = E q ( x 0 ) log p θ ( x 0 ) \begin{aligned} L = \mathbb{E}_{q(\mathbf{x}_0)} \log p_\theta(\mathbf{x}_0) \end{aligned} L=Eq(x0)logpθ(x0)
这个过程很像VAE,即可以使用变分下界(VLB)来优化负对数似然。
我们回顾一下, KL 散度是一种不对称统计距离度量,用于衡量一个概率分布 P P P与另外一个概率分布 Q Q Q的差异程度。
连续分布的 KL 散度的数学形式是:
D K L ( P ∣ ∣ Q ) = ∫ − ∞ ∞ p ( x ) l o g ( p ( x ) q ( x ) ) d x \begin{aligned} D_{KL}(P||Q)= \int_{-\infty}^{\infty}p(x) log(\frac{p(x)}{q(x)})\, {\rm d} x \end{aligned} DKL(P∣∣Q)=∫−∞∞p(x)log(q(x)p(x))dx。
KL散度的性质:
1、非对称性: D K L ( P ∣ ∣ Q ) ≠ D K L ( Q ∣ ∣ P ) D_{KL}(P||Q) \neq D_{KL}(Q||P) DKL(P∣∣Q)=DKL(Q∣∣P)。
2、 D K L ( P ∣ ∣ Q ) ≥ 0 D_{KL}(P||Q) \geq0 DKL(P∣∣Q)≥0 ,仅 p = Q p=Q p=Q在时等于0。
由于KL散度非负,可得到:
− log p θ ( x 0 ) ≤ − log p θ ( x 0 ) + D KL ( q ( x 1 : T ∣ x 0 ) ∥ p θ ( x 1 : T ∣ x 0 ) ) = − log p θ ( x 0 ) + E x 1 : T ∼ q ( x 1 : T ∣ x 0 ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) / p θ ( x 0 ) ] = − log p θ ( x 0 ) + E q [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) + log p θ ( x 0 ) ] = E q [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] Let L VLB = E q ( x 0 : T ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] ≥ − E q ( x 0 ) log p θ ( x 0 ) \begin{aligned}- \log p_\theta(\mathbf{x}_0) &\leq - \log p_\theta(\mathbf{x}_0) + D_\text{KL}(q(\mathbf{x}_{1:T}\vert\mathbf{x}_0) \| p_\theta(\mathbf{x}_{1:T}\vert\mathbf{x}_0) ) \\ &= -\log p_\theta(\mathbf{x}_0) + \mathbb{E}_{\mathbf{x}_{1:T}\sim q(\mathbf{x}_{1:T} \vert \mathbf{x}_0)} \Big[ \log\frac{q(\mathbf{x}_{1:T}\vert\mathbf{x}_0)}{p_\theta(\mathbf{x}_{0:T}) / p_\theta(\mathbf{x}_0)} \Big] \\ &= -\log p_\theta(\mathbf{x}_0) + \mathbb{E}_q \Big[ \log\frac{q(\mathbf{x}_{1:T}\vert\mathbf{x}_0)}{p_\theta(\mathbf{x}_{0:T})} + \log p_\theta(\mathbf{x}_0) \Big] \\ &= \mathbb{E}_q \Big[ \log \frac{q(\mathbf{x}_{1:T}\vert\mathbf{x}_0)}{p_\theta(\mathbf{x}_{0:T})} \Big] \\ \text{Let }L_\text{VLB} &= \mathbb{E}_{q(\mathbf{x}_{0:T})} \Big[ \log \frac{q(\mathbf{x}_{1:T}\vert\mathbf{x}_0)}{p_\theta(\mathbf{x}_{0:T})} \Big] \geq - \mathbb{E}_{q(\mathbf{x}_0)} \log p_\theta(\mathbf{x}_0) \end{aligned} −logpθ(x0)Let LVLB≤−logpθ(x0)+DKL(q(x1:T∣x0)∥pθ(x1:T∣x0))=−logpθ(x0)+Ex1:T∼q(x1:T∣x0)[logpθ(x0:T)/pθ(x0)q(x1:T∣x0)]=−logpθ(x0)+Eq[logpθ(x0:T)q(x1:T∣x0)+logpθ(x0)]=Eq[logpθ(x0:T)q(x1:T∣x0)]=Eq(x0:T)[logpθ(x0:T)q(x1:T∣x0)]≥−Eq(x0)logpθ(x0)
进一步对推导 L V L B L_{VLB} LVLB,可以得到熵与多个 KL 散度的累加,具体可见文献 [8]. 这里我就复制一波 Lil 的博客中的推导过程:
使用 Jensen 不等式也很容易得到相同的结果。 假设我们想最小化交叉熵作为学习目的:
L CE = − E q ( x 0 ) log p θ ( x 0 ) = − E q ( x 0 ) log ( ∫ p θ ( x 0 : T ) d x 1 : T ) = − E q ( x 0 ) log ( ∫ q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) q ( x 1 : T ∣ x 0 ) d x 1 : T ) = − E q ( x 0 ) log ( E q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) q ( x 1 : T ∣ x 0 ) ) ≤ − E q ( x 0 : T ) log p θ ( x 0 : T ) q ( x 1 : T ∣ x 0 ) = E q ( x 0 : T ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] = L VLB \begin{aligned} L_\text{CE} &= - \mathbb{E}_{q(\mathbf{x}_0)} \log p_\theta(\mathbf{x}_0) \\ &= - \mathbb{E}_{q(\mathbf{x}_0)} \log \Big( \int p_\theta(\mathbf{x}_{0:T}) d\mathbf{x}_{1:T} \Big) \\ &= - \mathbb{E}_{q(\mathbf{x}_0)} \log \Big( \int q(\mathbf{x}_{1:T} \vert \mathbf{x}_0) \frac{p_\theta(\mathbf{x}_{0:T})}{q(\mathbf{x}_{1:T} \vert \mathbf{x}_{0})} d\mathbf{x}_{1:T} \Big) \\ &= - \mathbb{E}_{q(\mathbf{x}_0)} \log \Big( \mathbb{E}_{q(\mathbf{x}_{1:T} \vert \mathbf{x}_0)} \frac{p_\theta(\mathbf{x}_{0:T})}{q(\mathbf{x}_{1:T} \vert \mathbf{x}_{0})} \Big) \\ &\leq - \mathbb{E}_{q(\mathbf{x}_{0:T})} \log \frac{p_\theta(\mathbf{x}_{0:T})}{q(\mathbf{x}_{1:T} \vert \mathbf{x}_{0})} \\ &= \mathbb{E}_{q(\mathbf{x}_{0:T})}\Big[\log \frac{q(\mathbf{x}_{1:T} \vert \mathbf{x}_{0})}{p_\theta(\mathbf{x}_{0:T})} \Big] = L_\text{VLB} \end{aligned} LCE=−Eq(x0)logpθ(x0)=−Eq(x0)log(∫pθ(x0:T)dx1:T)=−Eq(x0)log(∫q(x1:T∣x0)q(x1:T∣x0)pθ(x0:T)dx1:T)=−Eq(x0)log(Eq(x1:T∣x0)q(x1:T∣x0)pθ(x0:T))≤−Eq(x0:T)logq(x1:T∣x0)pθ(x0:T)=Eq(x0:T)[logpθ(x0:T)q(x1:T∣x0)]=LVLB
为了将方程中的每个项转换为可分析计算的,可以将目标进一步重写为几个 KL 散度和熵项的组合(参见 Sohl-Dickstein 等人的附录 B 中的详细分步过程):
L VLB = E q ( x 0 : T ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] = E q [ log ∏ t = 1 T q ( x t ∣ x t − 1 ) p θ ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) ] = E q [ − log p θ ( x T ) + ∑ t = 1 T log q ( x t ∣ x t − 1 ) p θ ( x t − 1 ∣ x t ) ] = E q [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t ∣ x t − 1 ) p θ ( x t − 1 ∣ x t ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = E q [ − log p θ ( x T ) + ∑ t = 2 T log ( q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) ⋅ q ( x t ∣ x 0 ) q ( x t − 1 ∣ x 0 ) ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = E q [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) + ∑ t = 2 T log q ( x t ∣ x 0 ) q ( x t − 1 ∣ x 0 ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = E q [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) + log q ( x T ∣ x 0 ) q ( x 1 ∣ x 0 ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = E q [ log q ( x T ∣ x 0 ) p θ ( x T ) + ∑ t = 2 T log q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) − log p θ ( x 0 ∣ x 1 ) ] = E q [ D KL ( q ( x T ∣ x 0 ) ∥ p θ ( x T ) ) ⏟ L T + ∑ t = 2 T D KL ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) ⏟ L t − 1 − log p θ ( x 0 ∣ x 1 ) ⏟ L 0 ] \begin{aligned} L_\text{VLB} &= \mathbb{E}_{q(\mathbf{x}_{0:T})} \Big[ \log\frac{q(\mathbf{x}_{1:T}\vert\mathbf{x}_0)}{p_\theta(\mathbf{x}_{0:T})} \Big] \\ &= \mathbb{E}_q \Big[ \log\frac{\prod_{t=1}^T q(\mathbf{x}_t\vert\mathbf{x}_{t-1})}{ p_\theta(\mathbf{x}_T) \prod_{t=1}^T p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t) } \Big] \\ &= \mathbb{E}_q \Big[ -\log p_\theta(\mathbf{x}_T) + \sum_{t=1}^T \log \frac{q(\mathbf{x}_t\vert\mathbf{x}_{t-1})}{p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t)} \Big] \\ &= \mathbb{E}_q \Big[ -\log p_\theta(\mathbf{x}_T) + \sum_{t=2}^T \log \frac{q(\mathbf{x}_t\vert\mathbf{x}_{t-1})}{p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t)} + \log\frac{q(\mathbf{x}_1 \vert \mathbf{x}_0)}{p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1)} \Big] \\ &= \mathbb{E}_q \Big[ -\log p_\theta(\mathbf{x}_T) + \sum_{t=2}^T \log \Big( \frac{q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0)}{p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t)}\cdot \frac{q(\mathbf{x}_t \vert \mathbf{x}_0)}{q(\mathbf{x}_{t-1}\vert\mathbf{x}_0)} \Big) + \log \frac{q(\mathbf{x}_1 \vert \mathbf{x}_0)}{p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1)} \Big] \\ &= \mathbb{E}_q \Big[ -\log p_\theta(\mathbf{x}_T) + \sum_{t=2}^T \log \frac{q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0)}{p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t)} + \sum_{t=2}^T \log \frac{q(\mathbf{x}_t \vert \mathbf{x}_0)}{q(\mathbf{x}_{t-1} \vert \mathbf{x}_0)} + \log\frac{q(\mathbf{x}_1 \vert \mathbf{x}_0)}{p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1)} \Big] \\ &= \mathbb{E}_q \Big[ -\log p_\theta(\mathbf{x}_T) + \sum_{t=2}^T \log \frac{q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0)}{p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t)} + \log\frac{q(\mathbf{x}_T \vert \mathbf{x}_0)}{q(\mathbf{x}_1 \vert \mathbf{x}_0)} + \log \frac{q(\mathbf{x}_1 \vert \mathbf{x}_0)}{p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1)} \Big]\\ &= \mathbb{E}_q \Big[ \log\frac{q(\mathbf{x}_T \vert \mathbf{x}_0)}{p_\theta(\mathbf{x}_T)} + \sum_{t=2}^T \log \frac{q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0)}{p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t)} - \log p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1) \Big] \\ &= \mathbb{E}_q [\underbrace{D_\text{KL}(q(\mathbf{x}_T \vert \mathbf{x}_0) \parallel p_\theta(\mathbf{x}_T))}_{L_T} + \sum_{t=2}^T \underbrace{D_\text{KL}(q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0) \parallel p_\theta(\mathbf{x}_{t-1} \vert\mathbf{x}_t))}_{L_{t-1}} \underbrace{- \log p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1)}_{L_0} ] \end{aligned} LVLB=Eq(x0:T)[logpθ(x0:T)q(x1:T∣x0)]=Eq[logpθ(xT)∏t=1Tpθ(xt−1∣xt)∏t=1Tq(xt∣xt−1)]=Eq[−logpθ(xT)+t=1∑Tlogpθ(xt−1∣xt)q(xt∣xt−1)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt∣xt−1)+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlog(pθ(xt−1∣xt)q(xt−1∣xt,x0)⋅q(xt−1∣x0)q(xt∣x0))+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)+t=2∑Tlogq(xt−1∣x0)q(xt∣x0)+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)+logq(x1∣x0)q(xT∣x0)+logpθ(x0∣x1)q(x1∣x0)]=Eq[logpθ(xT)q(xT∣x0)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)−logpθ(x0∣x1)]=Eq[LT DKL(q(xT∣x0)∥pθ(xT))+t=2∑TLt−1 DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))L0 −logpθ(x0∣x1)]
让我们把这堆东西简化一下:
L VLB = L T + L T − 1 + ⋯ + L 0 where L T = D KL ( q ( x T ∣ x 0 ) ∥ p θ ( x T ) ) L t = D KL ( q ( x t ∣ x t + 1 , x 0 ) ∥ p θ ( x t ∣ x t + 1 ) ) for 1 ≤ t ≤ T − 1 L 0 = − log p θ ( x 0 ∣ x 1 ) \begin{aligned} L_\text{VLB} &= L_T + L_{T-1} + \dots + L_0 \\ \text{where } L_T &= D_\text{KL}(q(\mathbf{x}_T \vert \mathbf{x}_0) \parallel p_\theta(\mathbf{x}_T)) \\ L_t &= D_\text{KL}(q(\mathbf{x}_t \vert \mathbf{x}_{t+1}, \mathbf{x}_0) \parallel p_\theta(\mathbf{x}_t \vert\mathbf{x}_{t+1})) \text{ for }1 \leq t \leq T-1 \\ L_0 &= - \log p_\theta(\mathbf{x}_0 \vert \mathbf{x}_1) \end{aligned} LVLBwhere LTLtL0=LT+LT−1+⋯+L0=DKL(q(xT∣x0)∥pθ(xT))=DKL(q(xt∣xt+1,x0)∥pθ(xt∣xt+1)) for 1≤t≤T−1=−logpθ(x0∣x1)
接下来我们对 L T 、 L T 、 L 0 L_T、L_T、L_0 LT、LT、L0这三种情况进行分类讨论:
首先,由于前向过程 q q q没有可学习参数,而 x T x_T xT则是纯高斯噪声,因此 L T L_T LT可以当做常量忽略。
然后, L t L_t Lt 是KL散度,则可以看做拉近 2 个分布的距离:
1、第一个 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0)分布我们已经在上一节推导出其解析形式,这是一个高斯分布,其均值和方差为:
μ ~ t = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ t ) , β ~ t = 1 − α ˉ t − 1 1 − α ˉ t ⋅ β t \tilde{\boldsymbol{\mu}}_t = \frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\epsilon}_t \Big), \tilde{\beta}_t = {\frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \cdot \beta_t} μ~t=αt1(xt−1−αˉt1−αtϵt),β~t=1−αˉt1−αˉt−1⋅βt
2、第二个分布 p θ ( x t − 1 ∣ x t ) p_{\theta}(x_{t-1}|x_t) pθ(xt−1∣xt)是我们网络期望拟合的目标分布,也是一个高斯分布,均值用网络估计,方差被设置为了一个和 β t \beta_t βt有关的常数。
p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) \begin{aligned} p_\theta(\mathbf{x}_{t-1} \vert \mathbf{x}_t) = \mathcal{N}(\mathbf{x}_{t-1}; \boldsymbol{\mu}_\theta(\mathbf{x}_t, t), \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t)) \end{aligned} pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
我们知道如果有两个分布 p p p, q q q都是高斯分布,则他们的KL散度为:
K L ( p , q ) = l o g θ 2 θ 1 + θ 1 2 + ( μ 1 − μ 2 ) 2 2 θ 2 2 − 1 2 \begin{aligned} KL(p,q)=log\frac{\theta_2}{\theta_1}+\frac{\theta_1^2+(\mu_1-\mu_2)^2}{2\theta_2^2}-\frac{1}{2} \end{aligned} KL(p,q)=logθ1θ2+2θ22θ12+(μ1−μ2)2−21。
然后因为这两个分布的方差全是常数,和优化无关,所以其实优化目标就是两个分布均值的二范数:
L t = E x 0 , ϵ [ 1 2 ∥ Σ θ ( x t , t ) ∥ 2 2 ∥ μ ~ t ( x t , x 0 ) − μ θ ( x t , t ) ∥ 2 ] = E x 0 , ϵ [ 1 2 ∥ Σ θ ∥ 2 2 ∥ 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ t ) − 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ θ ( x t , t ) ) ∥ 2 ] = E x 0 , ϵ [ ( 1 − α t ) 2 2 α t ( 1 − α ˉ t ) ∥ Σ θ ∥ 2 2 ∥ ϵ t − ϵ θ ( x t , t ) ∥ 2 ] = E x 0 , ϵ [ ( 1 − α t ) 2 2 α t ( 1 − α ˉ t ) ∥ Σ θ ∥ 2 2 ∥ ϵ t − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ t , t ) ∥ 2 ] \begin{aligned} L_t &= \mathbb{E}_{\mathbf{x}_0, \boldsymbol{\epsilon}} \Big[\frac{1}{2 \| \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t) \|^2_2} \| \color{blue}{\tilde{\boldsymbol{\mu}}_t(\mathbf{x}_t, \mathbf{x}_0)} - \color{green}{\boldsymbol{\mu}_\theta(\mathbf{x}_t, t)} \|^2 \Big] \\ &= \mathbb{E}_{\mathbf{x}_0, \boldsymbol{\epsilon}} \Big[\frac{1}{2 \|\boldsymbol{\Sigma}_\theta \|^2_2} \| \color{blue}{\frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\epsilon}_t \Big)} - \color{green}{\frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\boldsymbol{\epsilon}}_\theta(\mathbf{x}_t, t) \Big)} \|^2 \Big] \\ &= \mathbb{E}_{\mathbf{x}_0, \boldsymbol{\epsilon}} \Big[\frac{ (1 - \alpha_t)^2 }{2 \alpha_t (1 - \bar{\alpha}_t) \| \boldsymbol{\Sigma}_\theta \|^2_2} \|\boldsymbol{\epsilon}_t - \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t)\|^2 \Big] \\ &= \mathbb{E}_{\mathbf{x}_0, \boldsymbol{\epsilon}} \Big[\frac{ (1 - \alpha_t)^2 }{2 \alpha_t (1 - \bar{\alpha}_t) \| \boldsymbol{\Sigma}_\theta \|^2_2} \|\boldsymbol{\epsilon}_t - \boldsymbol{\epsilon}_\theta(\sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon}_t, t)\|^2 \Big] \end{aligned} Lt=Ex0,ϵ[2∥Σθ(xt,t)∥221∥μ~t(xt,x0)−μθ(xt,t)∥2]=Ex0,ϵ[2∥Σθ∥221∥αt1(xt−1−αˉt1−αtϵt)−αt1(xt−1−αˉt1−αtϵθ(xt,t))∥2]=Ex0,ϵ[2αt(1−αˉt)∥Σθ∥22(1−αt)2∥ϵt−ϵθ(xt,t)∥2]=Ex0,ϵ[2αt(1−αˉt)∥Σθ∥22(1−αt)2∥ϵt−ϵθ(αˉtx0+1−αˉtϵt,t)∥2]
这个时候我们应该也是可以用网络直接预测 μ θ ( x t , t ) ) \boldsymbol{\mu}_\theta(\mathbf{x}_t, t)) μθ(xt,t)),但是,可以看出来 μ θ ( x t , t ) ) \boldsymbol{\mu}_\theta(\mathbf{x}_t, t)) μθ(xt,t))是要尽可能的去预测 μ ~ t = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ t ) \tilde{\boldsymbol{\mu}}_t = \frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\epsilon}_t \Big) μ~t=αt1(xt−1−αˉt1−αtϵt)。
因为 x o x_o xo是 μ θ \mu_{\theta} μθ的输入,其他的量都是常数 ϵ \epsilon ϵ,所以其中的未知量其实只有,所以我们干脆把 μ θ ( x t , t ) ) \boldsymbol{\mu}_\theta(\mathbf{x}_t, t)) μθ(xt,t))定义为:
μ θ ( x t , t ) ) = = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ t ( x t , t ) ) \boldsymbol{\mu}_\theta(\mathbf{x}_t, t))= = \frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\epsilon}_t (x_t,t) \Big) μθ(xt,t))==αt1(xt−1−αˉt1−αtϵt(xt,t))
也就是说不用网络直接预测 μ ~ θ ( x t , t ) ) \tilde{\boldsymbol{\mu}}_\theta(\mathbf{x}_t, t)) μ~θ(xt,t)),而是用网络先预测 ϵ t ( x t , t ) \boldsymbol{\epsilon}_t (x_t,t) ϵt(xt,t)噪声,然后把预测出来的噪声带入到定义好的表达式去计算出预测的均值,其实是一样的。
经过这样一番推导之后就是个 L2 loss。网络的输入是一张和噪声线性组合的图片,然后要估计出来这个噪声:
L t simple = E t ∼ [ 1 , T ] , x 0 , ϵ t [ ∥ ϵ t − ϵ θ ( x t , t ) ∥ 2 ] = E t ∼ [ 1 , T ] , x 0 , ϵ t [ ∥ ϵ t − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ t , t ) ∥ 2 ] \begin{aligned} L_t^\text{simple} &= \mathbb{E}_{t \sim [1, T], \mathbf{x}_0, \boldsymbol{\epsilon}_t} \Big[\|\boldsymbol{\epsilon}_t - \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t)\|^2 \Big] \\ &= \mathbb{E}_{t \sim [1, T], \mathbf{x}_0, \boldsymbol{\epsilon}_t} \Big[\|\boldsymbol{\epsilon}_t - \boldsymbol{\epsilon}_\theta(\sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon}_t, t)\|^2 \Big] \end{aligned} Ltsimple=Et∼[1,T],x0,ϵt[∥ϵt−ϵθ(xt,t)∥2]=Et∼[1,T],x0,ϵt[∥ϵt−ϵθ(αˉtx0+1−αˉtϵt,t)∥2]
训练过程
训练过程如图左边 Algorithm 1 Training 部分:
1、从标准高斯分布采样一个噪声 ϵ t ∼ N ( 0 , I ) \boldsymbol{\epsilon}_t \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) ϵt∼N(0,I) ;
2、通过梯度下降最小化损失 ∣ ∣ ϵ t − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ t , t ) ∥ 2 || \boldsymbol{\epsilon}_t - \boldsymbol{\epsilon}_\theta(\sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon}_t, t)\|^2 ∣∣ϵt−ϵθ(αˉtx0+1−αˉtϵt,t)∥2 ;
3、训练到收敛为止(训练时间比较长,T 代码中设置为 1000)。
测试(采样)如图右边 Algorithm 2 Sampling 部分:
1、从标准高斯分布采样一个噪声 x T ∼ N ( 0 , I ) \boldsymbol{x_T} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) xT∼N(0,I);
2、从时间步 T 开始正向扩散迭代到时间步 1;
3、如果时间步不为 1,则从标准高斯分布采样一个噪声 z ∼ N ( 0 , I ) \boldsymbol{z} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) z∼N(0,I),否则 z = 0 z=0 z=0;
4、根据高斯分布计算每个时间步 t 的噪声图;

快速回顾

正向 / 扩散过程
正向过程或者说是扩散过程,采用的是一个固定的 Markov chain 形式,即逐步地向图片添加高斯噪声:
q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q ( x 1 : T ∣ x 0 ) = ∏ t = 1 T q ( x t ∣ x t − 1 ) q(\mathbf{x}_t \vert \mathbf{x}_{t-1}) = \mathcal{N}(\mathbf{x}_t; \sqrt{1 - \beta_t} \mathbf{x}_{t-1}, \beta_t\mathbf{I}) \quad q(\mathbf{x}_{1:T} \vert \mathbf{x}_0) = \prod^T_{t=1} q(\mathbf{x}_t \vert \mathbf{x}_{t-1}) q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)q(x1:T∣x0)=∏t=1Tq(xt∣xt−1)
在 DDPM 中, β t \beta_t βt是预先设置的定值参数。
扩散过程有一个重要的特性,我们可以直接采样任意时刻 t t t下的加噪结果 。将 α t = 1 − β t \alpha_t = 1 - \beta_t αt=1−βt, α ˉ t = ∏ i = 1 t α i \bar{\alpha}_t = \prod_{i=1}^t \alpha_i αˉt=∏i=1tαi,则我们可以得到:
x t = α t x t − 1 + 1 − α t ϵ t − 1 ;where ϵ t − 1 , ϵ t − 2 , ⋯ ∼ N ( 0 , I ) = α t α t