解读72篇DeepMind深度强化学习论文
来源:王小惟的知乎https://zhuanlan.zhihu.com/p/70127847
编辑:DeepRL
论文下载方法:pdf合集下载见文章末尾
DRL领域交流与讨论加微信:NeuronDance
关于DeepMind:
DeepMind,位于英国伦敦,是由人工智能程序师兼神经科学家戴密斯·哈萨比斯(Demis Hassabis)等人联合创立,是前沿的人工智能企业,其将机器学习和系统神经科学的最先进技术结合起来,建立强大的通用学习算法。最初成果主要应用于模拟、电子商务、游戏开发等商业领域。
目前,Google 旗下的 DeepMind 已经成为 AI 领域的明星,据外媒 2016年6月8日,DeepMind 欲将其算法应用到医疗保健行业,包括计划在 5年内使用机器学习处理英国国家医疗服务体系。
本文对DeepMind公司几年以来的72篇文章做了简短的解读,对涉及到的知识点进行了汇总,并且为各位爱好者提供了论文的pdf合集(72篇论文合集,通过文章末尾下载地址直接获取)
1
2015-ICML-workshop-Massively Parallel Methods for Deep Reinforcement Learning
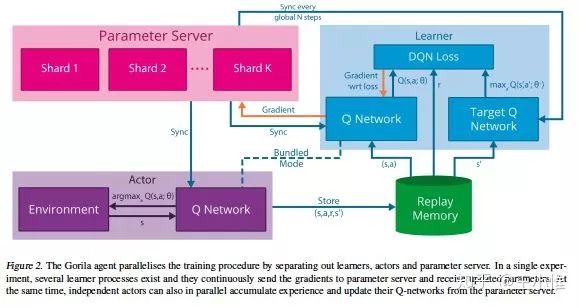
提出第一个用于深度强化学习的大规模分布式架构(Gorila),只是简单地将DQN结合PS(Parameter server)来进行分布式地训练。不停地用当前的DQN与环境进行交互,获得experience(s,a,r,s'),然后存在buffer中;learner部分sample buffer中的experience,进行学习,并将参数update到parameter server中。
2
2015-NIPS-Variational Information Maximisation for Intrinsically Motivated Reinforcement Learning
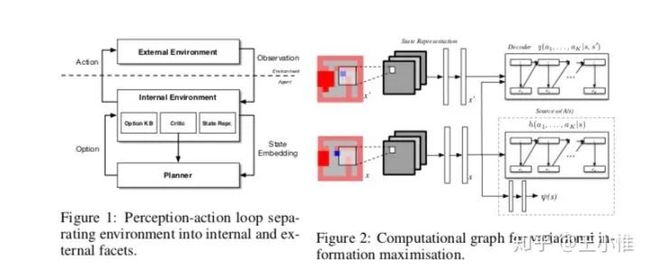
利用mutual information来帮助agent进行探索,但是以前常用的方法(Blahut-Arimoto algorithm)不适用,于是提出变分推理和DL,提供了一种可扩展优化互信息的新方法(一样是转化为lower bound然后再优化的)。(stochastic optimisation algorithm that allows for scalable information maximisation and empowerment-based reasoning directly from pixels to actions.)

3
2015-NIPS-Learning Continuous Control Policies by Stochastic Value Gradients

相比普通的基于sampling returns from the real environment然后采用likelihood ratio的policy gradient。这边考虑的是如果我们可以获得一个可差分的环境模型,那么我们可以结合policy, model, and reward function to compute an analytic policy gradient by backpropagation of reward along a trajectory。(这样的方式被称为:Value gradient methods)。然后为了解决之前的Value gradient只能用来训练deterministic policies,这边可以结合 experience database来做调整,进而训练stochastic policy。然后利用“re-parameterization”,扩展到随机环境中随机策略的优化。
4
2015-AAAI-Deep Reinforcement Learning with Double Q-learning
将Double Q learning的思路与DQN相结合,缓解了Q value overestimate的问题。vanilla DQN的target value的计算为: ,而Double DQN采用: 。(更一般的,在Double Q learning中,其实是两个Q-table互相作为target,随机选择一者进行更新,而Double DQN是target network提供value的估计,online network来选择action)
5
2016-arXiv-POLICY DISTILLATION
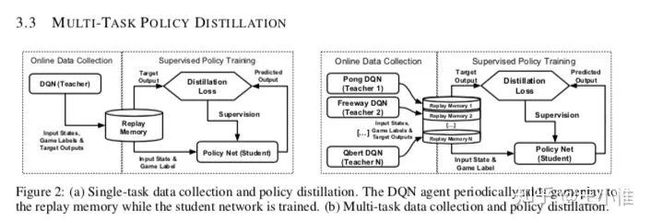
这篇论文从训练一个满足多个task的网络出发,设计一个框架(上图)和几个loss来满足目标。(这边虽然写的是DQN,但是在transfer的时候,为了能够transfer概率,对于Q value做了softmax来做桥梁。)第一个loss是类似监督学习,利用当前最优的(s,a)来训练策略,即,采用negative log likelihood loss (NLL), 。第二个loss是直接在Q value的数值大小直接做mean-squared-error loss (MSE) 。第三个是采用KL divergence 。
这篇文章另外说到的一点是:可以通过留存较好的经验来训练更稳定的policy。
6
2015-AAAI-Compress and Control

提出一种 information-theoretic policy evaluation的方法(Compress and Control, CNC)。进一步值函数可以用压缩表征或者density model来表示。
8
2016-arXiv-Learning and Transfer of Modulated Locomotor Controllers
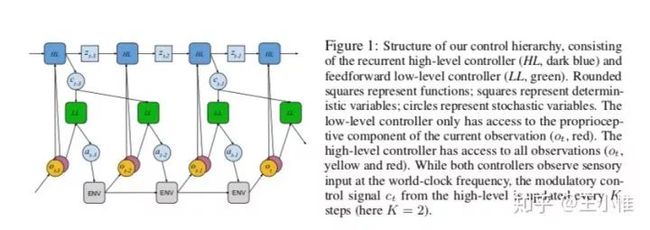
如果所示,分为low-level(LL) controller和high-level(HL) controller。LL的policy采用非循环神经网络: 与 ,其中o为observation,c为HL的输出。通过LL网络输出 ,如果方差确定的话,可以直接输出 即可,然后采用Gaussian policy来sample出实际的action:。HL采用循环神经网络, 。此外,LL可以采用预训练过的policy作为基准,然后只训练顶层policy即可。
9
2016-arXiv-Iterative Hierarchical Optimization for Misspecified Problems (IHOMP)
研究Misspecified Problems (MP)中采用hierarchical policy来缓解MP问题。Misspecified Problems (MP)可以简单理解成对于问题的建模出现错误,导致policy无法学的好,或者无法学到。
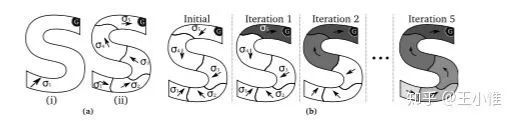
以(a)中(i)为例,agent需要在s区域能从起点(左下角)到达右上角的G。如果我们建模错误,让agent只能选择直线行走,那么这个问题是没有解的。这边的思路其实是引入option的思路,将一个MDP拆分成local-MDP,然后在local-MDP中求解。

10
2016-arXiv-Model-Free Episodic Control
偏向从生物的视角来做,研究hippocampal episodic control是否能够有效的学习到sequential decision-making task。

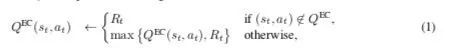
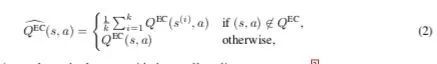
简而言之,就是采样 ,然后统计return ,留存每个 下最大的 ,然后在需要决策时候,先判断这个需要做决策的state 对应的 是否被采用过,如果有采用的过的话,就利用之前存下的最大的 来作为这个 的估值,如果没有的话,那么就就是其他action的均值。(那篇 faster and slower,也是用的这个思路)
11
2016-arXiv-Progressive Neural Networks

如图所示,每个output代表一个task,所以是从左到右进行训练。举例,在训练 代表的task时,最右侧的网络的每一层的输入分为两个部分组成(假设为第i层):1. 自己网络本身的上一层的输入,即 ,2. 之前task训练过后的网络的上一层输入: 。
12
2016-ICLR-Continuous control with deep reinforcement learning

deep deterministic policy gradient(DDPG),将DPG的思想扩展到NN下。与PG不同在于:对于 中的 进行求导,然后利用链式法则得到对应的更新梯度 。采用Ornstein-Uhlenbeck process来增加noise辅助探索,同时采用 “soft” target updates来平稳target network的参数更新。
13
2016-ICLR-PRIORITIZED EXPERIENCE REPLAY

对于Buffer中的sample进行改进,简而言之:如果online Q network和target Q network在某些(s,a,r,s')的 pair上的误差不高时(即相应的loss不高),那么利用这个pair的loss来做online Q network的更新,相应的parameter的改变可能微乎其微,所以在更新的时候,我们更多的是需要考虑loss较大的(s,a,r,s'),来引导相应parameter的更新与调整。另外就是考虑到sample的bias,可以用IS修正。这边提了一下实现:可以采用sum-tree data structure来组织buffer
14
2016-ICML-Continuous Deep Q-Learning with Model-based Acceleration
DQN与传统Q-learning一样,因为存在argmax的操作,所以很难扩展到连续控制的环境中。这里是提出Normalized Advantage Functions的设置,在 的基础上,通过假设 可以写成 , 那么很明显 为非正数,那么对应的 的argmax则是对应的 为0即可,那么max对应的 。
另外一点就是:专家的经验可以利用领域中的一些规则或者模型来获取,比如:我们可以先用数据fitted一个局部线性模型来预测环境的动态性,然后用卡尔曼滤波来找出如何到达某个state,进而进行学习。

15
2016-ICML-Dueling Network Architectures for Deep Reinforcement Learning

借鉴 的思路来进行网络结构的设计,在最后一层Q value的输出采用两个stream来做合并: 。这样的话,一部分关注的是当前state的好坏,另外一个部分是考虑在这个state下采用哪个action更好。
16
2016-ICML-Asynchronous Methods for Deep Reinforcement Learning

相比采用buffer的DQN,这篇论文提出采用多个并行环境同时采样来缓解数据之间的相关性对于网络更新带来的影响。实际上这篇文章是提出一个并行采样的思路,然后并将其运用在了q-learning,sarsa,ac上,代表性的就是A3C(Asynchronous advantage actor-critic)。其实后来openai有报告说Asynchronous没有什么用,A2C效果就够好了。
17
2016-NIPS-Unifying Count-Based Exploration and Intrinsic Motivation
采用density models来进行pseudo-count,之后利用count的结果来给予额外的探索的bound,进而鼓励探索。这里有意思的做法就是:1. 怎么利用density models来进行pseudo-count,就是section 3,主要就是相应的密度怎么更新,怎么知道每个state下的count的个数;2. 解释了一波与Intrinsic Motivation的关系,在section 4中。
18
2016-NIPS-Strategic Attentive Writer for Learning Macro-Actions
提出STRategic Attentive Writer (STRAW) architecture 来做隐式的plan,从而implicitly learn useful temporally abstracted macro-actions in an end-to-end manner。简而言之,就是输入input(比如图像),然后输出后续 中每个step可能采取的action的概率,还有每个time step下,重新规划的概率。
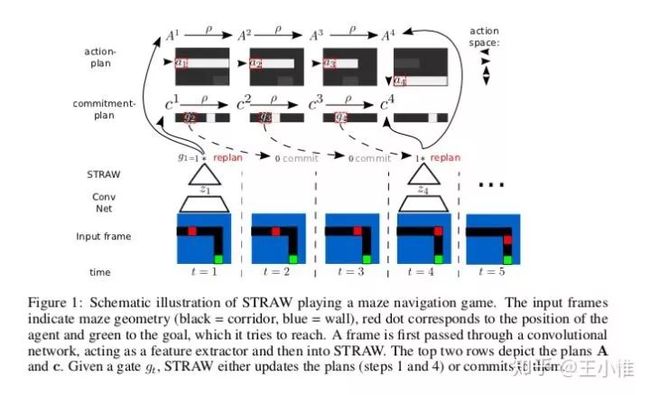

19
2016-NIPS-Learning to Communicate with Deep Multi-Agent Reinforcement Learning
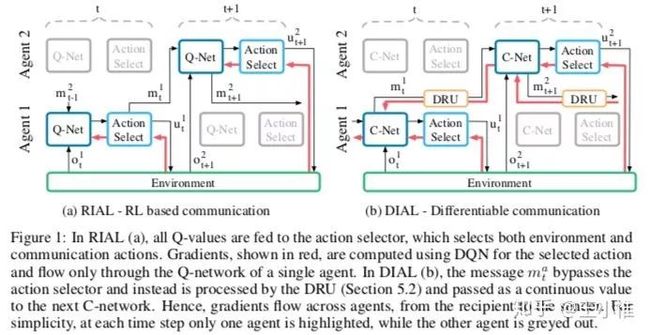
如果所示,就是提出两种不同的组织方式,然后解释成end-to-end地在学习通讯
20
2016-NIPS-Deep Exploration via Bootstrapped DQN
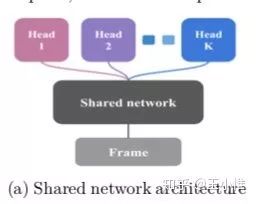

其实Bootstrapped的目的就是为了模拟一个s下每个action对应的Q的distribution,当这个distribution越确定时,则这个s下每个a的Q变化不大,这意味着,这个s下的这个a(及其后续的影响)很确定,没有必要做探索。如果这个distribution变化大时,就代表对于这个action采样可能不够(或者环境本身具有一定随机,需要进一步采样)。算法中的mask是指说产生的 可以由哪几个head来学习,这其实是需要调参的地方。
21
2016-NIPS-Learning values across many orders of magnitude

之前的DQN在Atari为了能够训练稳定,会对reward进行预处理,比如全部都clip到[-1,1]之类的做法,这样的做法其实是需要事先知道reward的范围的,同时采用不同的clip方法会严重影响agent训练后性能。这里是提出采用adaptive normalization。
22
2016-AAAI-Increasing the Action Gap: New Operators for Reinforcement Learning
提出 family of optimality-preserving operators, of which the consistent Bellman operator is a dis- tinguished member.
23
2017-arXiv-Structure Learning in Motor Control: A Deep Reinforcement Learning Model
传统的model-base方法中有一大类是利用env model来进行planning的,然后这篇文章是考虑了meta-learning的那种setting,就是存在一系列的Task T。这边的改进就是通过实际环境的(r,o)来调整规划使用的model。
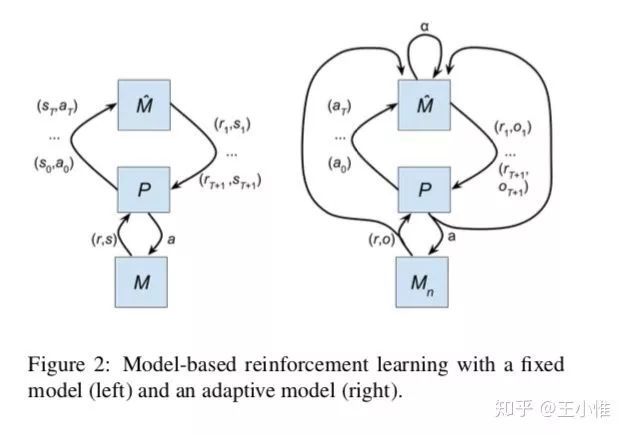
24
2017-arXiv-LEARNING TO REINFORCEMENT LEARN
简而言之,将上一时刻采用的action,reward也输入到网络中,因为这里的网络采用的RNN(LSTM)之类的,所以agent其实能够有能力感知到 ,所以有一定能力以此推断出是属于那个task的。具体结果见图:
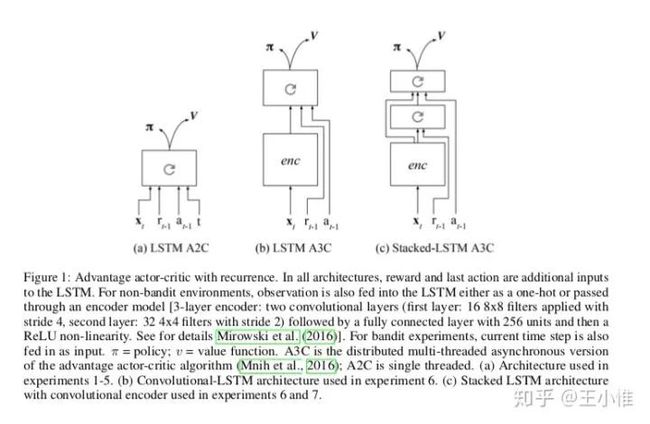
25
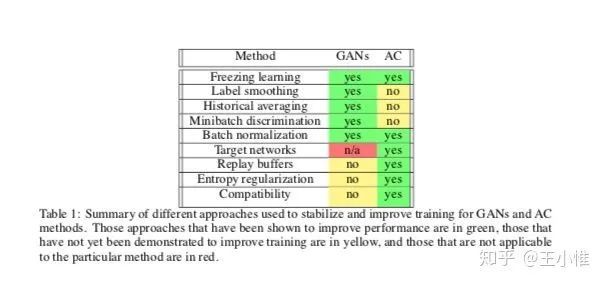
2017-arXiv-Connecting Generative Adversarial Networks and Actor-Critic Methods
分析了一下Actor-Critic与GAN的异同点。

26
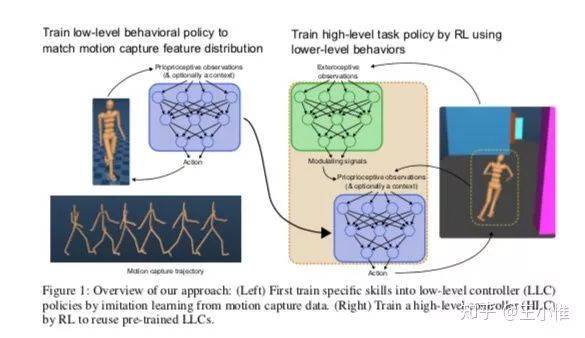
2017-arXiv-Learning human behaviors from motion capture by adversarial imitation
简而言之,就是直接从reward来做learning容易出现一些奇奇怪怪(鬼畜)的action,同时一些更复杂的任务可能无法学习到,比如:对于控制一个人型机器人走到某个goal,同时躲避障碍的任务。在这样的任务中,其实是需要控制人形机器人的各个关节来站立,行走,然后才是满足相应的goal,而控制关节站立和行走其实蛮难的了(如果你的reward就是考虑goal给予reward,我觉得agent最后说不定和大蛇丸,伏地魔一样,在地板上扭动地‘游’过去)
然后这边的想法是能不能从人类的一些demonstrations来学习出一些sub-skill,然后利用这些skill来做进一步的learning。这里是采用gail的思想来进行learning,首先是对数据打上标签,比如向左走的一类,向右走的一类,然后用gail来产生reward(discriminator),之后利用这个reward来训练底层的policy(sub-skill),注意这边是有context variable的(类似label),然后high level在利用环境的reward,learning出一个输出context variable的策略。
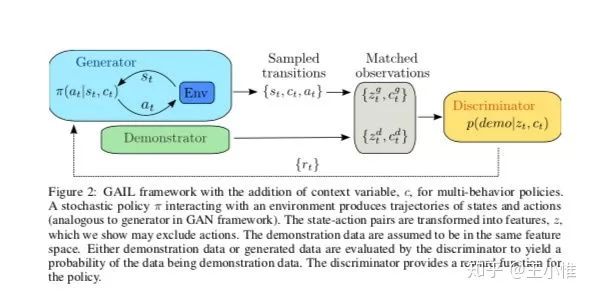

27
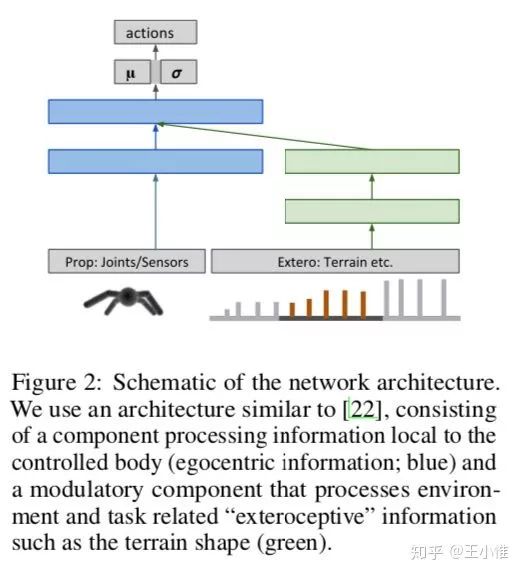
2017-arXiv-Emergence of Locomotion Behaviours in Rich Environments
这篇论文提出另外一种形式的PPO(Proximal Policy Optimization。八卦:这篇文章比正主John Schulman的PPO写的还早,听了别人在NIPS2016的Tutorials,然后就搞了一下,所以这个是与John Schulman不同的形式的PPO)
因为TRPO要算Hessian-vector太慢了,所以这边是直接将KL当成一个优化的部分,当前KL比较大时(也就是前后policy差异大时)主要关注约束KL不要太大(通过在loss中调高KL的权重),反之亦然。此外,这边也提出分布式的PPO,即见下图的算法部分。
另外就是有一个网路结构,将agent自身信息与环境信息分别过网络,再合并。


28
2017-arXiv-Leveraging Demonstrations for Deep Reinforcement Learning on Robotics Problems with Sparse Rewards
RL通常在密集的反馈(reward)中能够有比较好的表现,在稀疏的反馈的环境中(Sparse Rewards)就可能表现差一些。所以人们会设计一些辅助的reward或者shapping来进行learning。这篇文章没有这么做,而是通过Demonstrations来引导agent进行学习:将Demonstrations和实际的data放在buffer中,prioritized replay mechanism来控制sample的比例,从而在Sparse Rewards中进行有效的learning。

29
2017-arXiv-Learning model-based planning from scratch
简而言之:将未来可能的n-step动态性也作为policy的一部分输入,从而进行更好的决策。提出的框架是采用Manager来控制进行几步的Imagination的,然后将Imagination相关的内容结合实际真实的state来让底层的controller作出更好的决策。
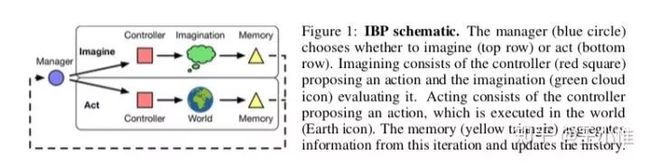


30
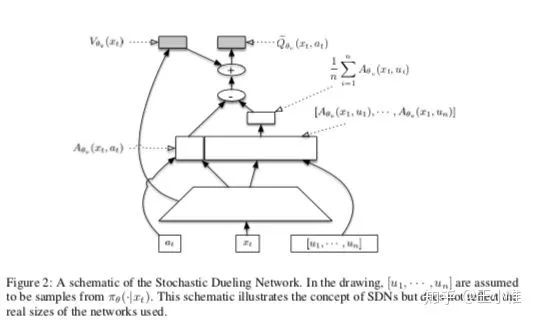
2017-ICLR-SAMPLE EFFICIENT ACTOR-CRITIC WITH EXPERIENCE REPLAY
即actor critic with experience replay (ACER)。即借鉴了Retrace estimator的方法,同时考虑了IMPORTANCE WEIGHT TRUNCATION WITH BIAS CORRECTION。另外就是提了一个EFFICIENT TRUST REGION POLICY OPTIMIZATION。内容有点多,建议细读论文。


31
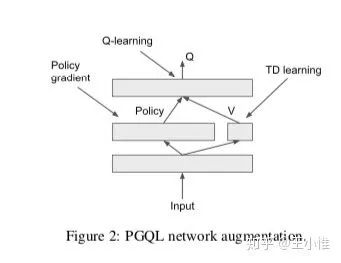
2017-ICLR-COMBINING POLICY GRADIENT AND Q-LEARNING
提出PGQ来结合Q-learning和policy gradient的好处。通过1.策略梯度的熵正则化 和2.贝尔曼方程的不动点来将policy还有Q结合在一起,推导过程不展开,直接说结论: 和 。然后结合贝尔曼残差和熵正则化的策略梯度更新进行加权即可。具体可以看天津包子馅儿师兄的知乎文章。
32
2017—ICLR-LEARNING TO PERFORM PHYSICS EXPERIMENTS VIA DEEP REINFORCEMENT LEARNING
一篇偏向运用的文章,问题的设定为:需要agent在交互式模拟环境中估计对象的一些属性,比如such as mass and cohesion of objects。在这些环境中,agent可以操纵对象并观察后果。然后实验表明DRL具有估计的能力。
33
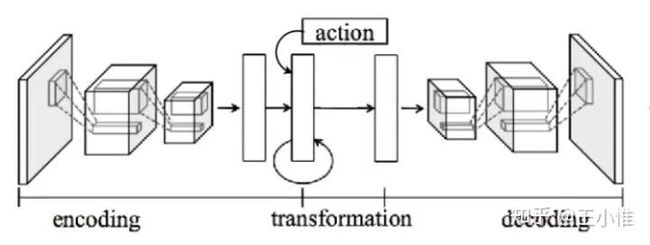
2017-ICLR-RECURRENT ENVIRONMENT SIMULATORS
目的是为了更好地预测下一帧,这篇文章提出下面的网络结构,将action和hidden state representation结合在一起,然后提出action-conditioned LSTM来进行更新。
34
2017—ICLR-REINFORCEMENT LEARNING WITH UNSUPERVISED AUXILIARY TASKS
本文针对迷宫类型的环境设置了一系列的辅助loss,来帮助spare reward的设置下进行learning。从大的视角来看,就是告诉我们,可以通过设置辅助的任务(UNSUPERVISED AUXILIARY TASKS)来帮助agent进行学习。
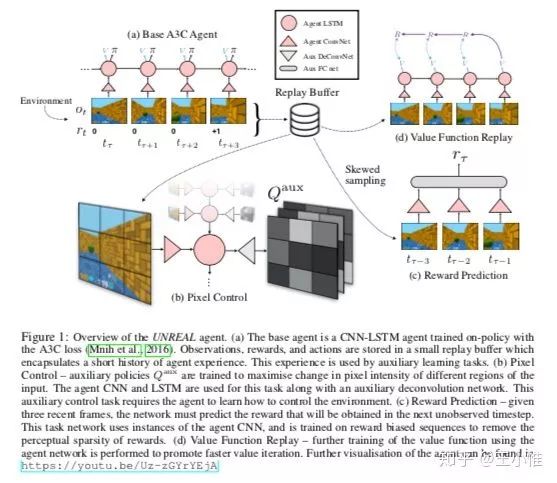
35
2017-ICML-DARLA/ Improving Zero-Shot Transfer in Reinforcement Learning
简而言之,分三步走:(1)学习state的embedding,(2)学习policy,(3)transfer,进行迁移。
这边的假设是:两个任务(MDP)之间除了state space不同外,action space一样,transition函数和reward函数结构接近(比如一个是仿真机器人,一个是真实机器人)。
所以如果能学习到一个MDP之间的state mapping的话,那么策略其实就能够复用了,这边采用 来学习state的embedding。然后直接用这个embedding来作为policy的输入,学习相应的行为。所以对于一个新的MDP,如果也符合上述假设,那么policy就可以复用了。
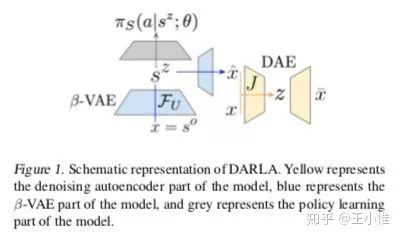
36
2017-ICML-A Distributional Perspective on Reinforcement Learning
定义了一下Distributional Bellman Operators,从原来学习mean Q变成学习Q的distribution 。(另外比较出名的就是:51-atom agent (from here onwards, C51) )

37
2017-ICML-FeUdal Networks for Hierarchical Reinforcement Learning
如下图所示,一个分层结构,Manager给出一个向量形式的goal,然后交给底层worker,worker的目的就是一方面在c step后达到影响的goal指引的方向:z + w,(这里的w是goal做完处理之后的向量,相当于goal在z的隐空间中给予了一个方向的目标指导)。训练时:manager就是学习出一个最大化外部c step的reward的goal,然后worker一方面满足这个goal,另外一方面最大化外部reward。

38
2017-ICML-Count-Based Exploration with Neural Density Models
在Unifying Count-Based Exploration and Intrinsic Motivation的基础上,采用PixelCNN来作为Density Model,说明一个更好的density model能够辅助更好的exploration
39
2017-NIPS-Successor Features for Transfer in Reinforcement Learning
即利用 successor representation (SR)的概念,即 ,进一步提出Successor features来对Q值进行分解:
进一步就是可以online地学习 。迁移到同样环境动态的另外task上,只需要学习特定task的 即可。比如:在同一个迷宫中,环境动态性 + policy 是一样的,那么这个policy对于新目标的好坏,就只需要learning出 就可以评价。
40
2017-NIPS-Programmable Agents
简而言之,想让agent执行用形式语言表达的描述性程序。这边的实际做法就是构造出形式语言所对应的矩阵表示形式,还有环境的矩阵表示形式。之后利用特定的操作来获得对应的action。这样的做法比较少见,还是建议看论文,比较难描述。
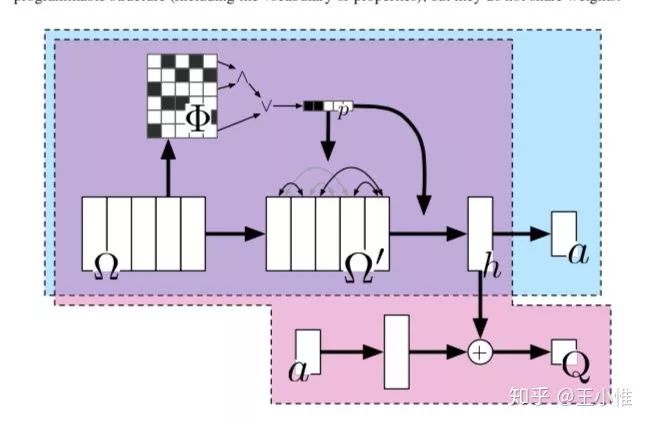
41
2017-NIPS-Deep Reinforcement Learning from Human Preferences
简单而言之,就是agent与环境做交互,产生一系列的trajectory,然后由人类对其中的一部分trajectory(sample出来的)来标记偏好的label,比如 trajectory 比 trajectory 好。接下去就是利用偏好的label来learning相应的reward的序关系: ,相应训练 比 好的loss为: ,反之亦然,就可以训练出相应的reward funciton了。
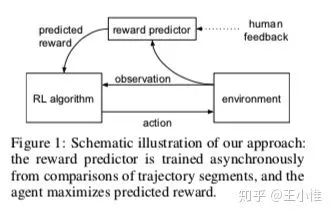
42
2017-NIPS-A multi-agent reinforcement learning model of common-pool resource appropriation
将DQN运用在common-pool resource的问题上,来做更深入的仿真与分析,同时定义了一些指标:Utilitarian metric,Sustainability metric,Equality metric,Peace metric。然后分析不同因素对于最终learning出来结果的影响。
43
2017-NIPS-Imagination-Augmented Agents for Deep Reinforcement Learning
提出了imagination core(IC),如下图所示,在policy(与value)network中,明显地向前做N-step的Imagination来辅助更好的决策。
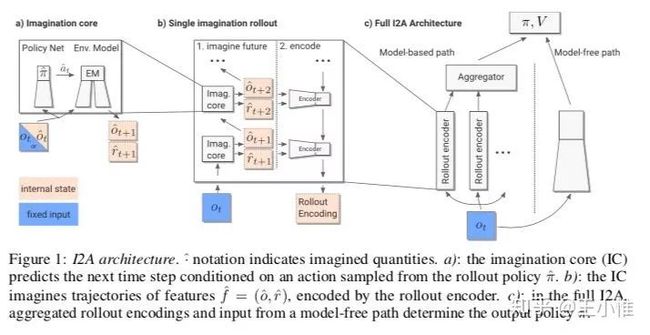

44
2017-NIPS-Robust Imitation of Diverse Behaviors
简而言之:用一个(bi-directional LSTM)VAE Encoder来做embedding vector的提取(即 z),然后policy利用embedding vector和state来做出action的选择。这样的好处是,虽然在一些state下有不同的行为(Diverse Behaviors),但是从T step的角度来看,就是比较好区分的(这些信息编码在z中)。
这边policy的训练时,采用GAIL来learning出discriminator来作为reward的signal。

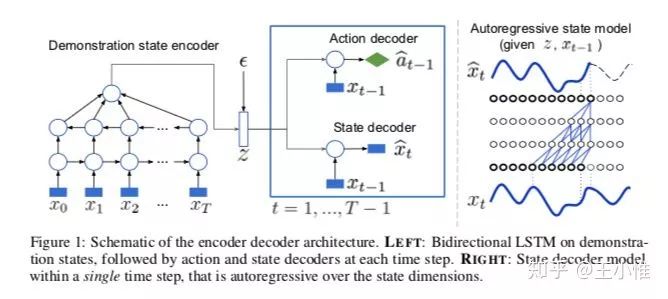
45
2017-NIPS-A Unified Game-Theoretic Approach to Multiagent Reinforcement Learning
本文说independent reinforcement learning (InRL)容易对其他人采用的policy过拟合,所以没有办法泛化。这里提出采用joint-policy correlation(JPC)来衡量这种过拟合:其实就是训练policy后,agent分别采用不同的策略在环境中做交互,然后统计n次episode的return,然后计算 , 是指一起训练的reward(return), 是指agent采用不是同时训练的policy的reward(return)。然后提出一种混合了之前一列技术的方法(InRL, iterated best response, double oracle, and fictitious play)。

46
2017-NIPS-Distral: Robust Multitask Reinforcement Learning
Distral (Distill & transfer learning)。简而言之,之前的multitask或多或少都是希望通过参数共享来加快学习(比如对于图片的特征提取层)。但是在实际中,由于任务之间的梯度方向可能会互相干扰,同时不同任务的reward尺度(observation的数值尺度)会不一样大,这就进一步限制了parameter weight的大小,同样也会出现梯度大小等不同的情况等等。既然共享参数会存在这样一系列的问题,这里采用了另外的一套框架,即在每个任务中学习特定的policy,然后在学习过程中进行knowledge的共享。即:将这些policy都蒸馏到一个中心的policy 中,同时也利用这个 来对特定的任务下的policy做正则化来进行约束(感觉就是knowledge transfer过去)。
在训练特定任务时,policy最大化环境的累积收益,同时加上对于 的KL散度来做约束,还有相应的entropy正则来鼓励探索。
在训练中心式的policy,就是对于其他所有特定任务的策略的KL散度的最小化。
更近一步,这边提了一下不同的训练方式,比如一起训练,间隔训练等,具体就去看paper即可。

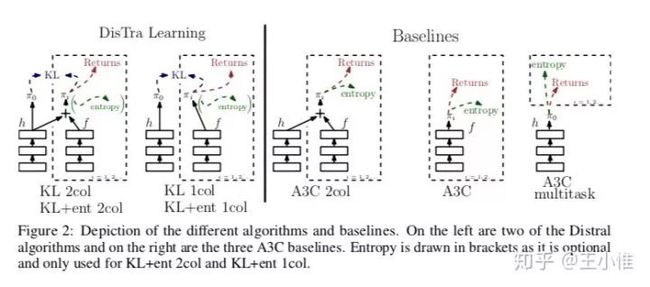
47
2017-ICRA-Deep Reinforcement Learning for Robotic Manipulation with Asynchronous Off-Policy Updates
将上述提到的NAF在真实的机器人上进行实验,同时结合异步(�并行)的思想,验证了有效性。
48
2017-CoRL-The Intentional Unintentional Agent: Learning to Solve Many Continuous Control Tasks Simultaneously
简而言之:见下图,同时学习多个任务,然后共用一部分底层的网络。这边的说法是:比单任务快,甚至有些单任务不能学到的,这里也有机会学到。
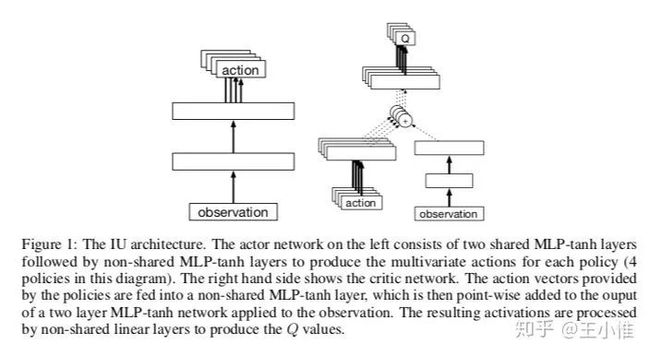
49
2018-arXiv-Unicorn: Continual learning with a universal, off-policy agent
Unicorn stands for “UNIversal Continual Off-policy Reinforcement learNing”.
关注continual learning的设置,这边采用了Universal Value Function Approximators (UVFAs)来做multi-task的训练。UVFA与普通的Q不同在于:不同的Q采用s,a作为输入(index),而UVFA多了一个goal。即: 与 。然后进行multi-task的联合优化。
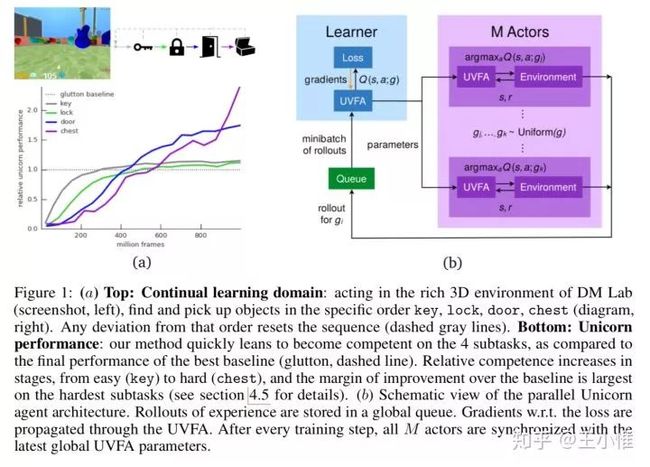
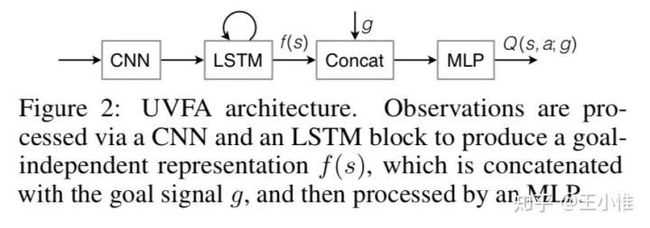
50
2018-arXiv-Kickstarting Deep Reinforcement Learning
结合policy distillation和PBT(population based training)来进行训练。简而言之,就是对于teacher的knowledge采用cross-entropy loss(或者其他也行吧)来做knowledge的transfer。由于存在多个teacher(task),所以在加loss的时候存在多个权重,权重的设置至关重要,这边才有PBT来调整权重,搜索出最好的training效果来。
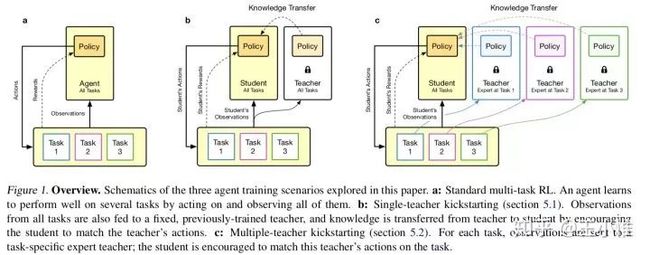
51
2018-arXiv-Observe and Look Further: Achieving Consistent Performance on Atari
为了缓解 diverse reward distributions, reasoning over long time horizons 和 exploring efficiently,提出一系列的操作:Transformed Bellman Operator(处理learn stably independent of the reward distribution),temporal consistency (TC) loss(避免the network from prematurely generalizing to unseen states )和Ape-X DQfD 来加速RL agent的学习速度。
Transformed Bellman Operator:之前的操作是将reward的distribution reduce到[-1, 1]之间,这边采用对于Q来做reduce。 ,这边的h即是用来做reduce的函数(比如线性压缩),具体的文章说:如果h是linear or the MDP is deterministic,那就会有unique fixed point。
Temporal Consistency (TC) loss:约束前后两次网络参数更新后,Q value的变化不要太大(同一state,action的Q)。
Ape-X DQfD:如图,就是sample的时候sample出一部分的demonstration
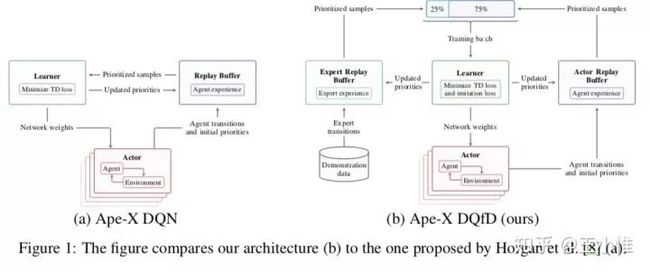

52
2018-arXiv-Safe Exploration in Continuous Action Spaces
简而言之,这边文章是希望解决一些带约束的优化问题(比如,温度控制希望维持温度在一定范围内,机器人的动作不能太大),具体的做法是:提出一个Linear Safety-Signal Model,在每个state下进行矫正action,从而满足约束。

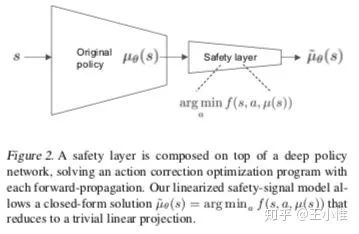
53
2018-ICML-Machine Theory of Mind
设计了一个Theory of Mind(感觉可以翻译成心智)neural network(ToMnet),ToMNet是采用meta-learning来可以刻画那种少见的行为的。能够模拟来自不同populations的随机,算法和DRL agent。
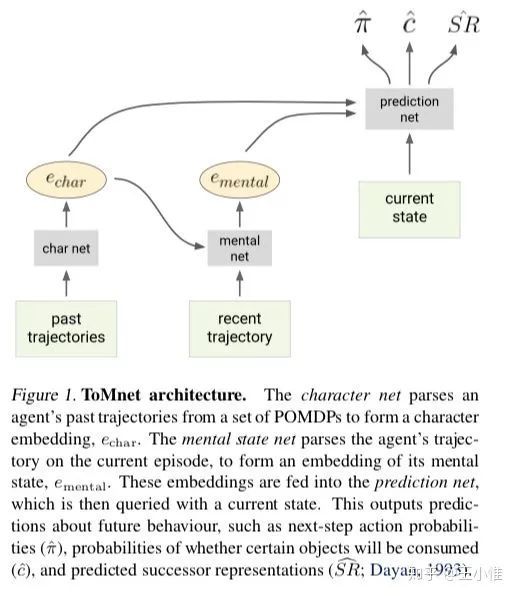
54
2018-ICML-More Robust Doubly Robust Off-policy Evaluation
偏理论的研究,提出more robust doubly robust (MRDR),is to learn the parameters of the DM(Direct Method) model by minimizing the variance of the DR(doubly robust) estimator.
55
2018-ICML-Path Consistency Learning in Tsallis Entropy Regularized MDPs
偏理论的研究,We first derive a sparse consistency equation that specifies a relationship between the optimal value function and policy of the sparse ERL along any system trajectory. Crucially, a weak form of the converse is also true, and we quantify the sub-optimality of a policy which satisfies sparse consistency, and show that as we increase the number of actions, this sub-optimality is better than that of the soft ERL optimal policy. We then use this result to derive the sparse PCL algorithms. We empirically compare sparse PCL with its soft counterpart, and show its advantage, especially in problems with a large number of actions.
56
2018-ICML-Mix & Match – Agent Curricula for Reinforcement Learning
这个我写过详细的知乎文章,看具体的文章即可。

57
2018-ICML-Learning to Search with MCTSnets
在MCTS的基础上,learn where, what and how to search。结构与算法如下:



58
2018-ICML-Progress & Compress/ A scalable framework for continual learning
简而言之,因为continual learning中存在两个问题:遗忘 + 快速学习。所以这边提出两个方法来解决这些挑战:
为了避免遗忘,这里采用:knowledge base来进行知识的存储。在每次学习一个新task后,采用the active column is distilled into the knowledge base, taking care to protect any previously acquired skills.
为了快速学习,这边采用:利用knowledge base来connected to an active column that is employed to efficiently learn the current task
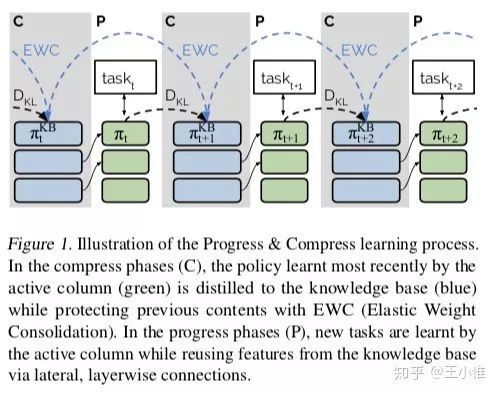
59
2018-ICML-The Uncertainty Bellman Equation and Exploration
提出uncertainty Bellman equation (UBE),进行不确定性的传递,从而更好的探索。具体内容建议看下论文。

60
2018-NIPS-Relational recurrent neural networks
首先说明:confirm our intuitions that standard memory architectures may struggle at tasks that heavily involve an understanding of the ways in which entities are connected。然后提出Relational Memory Core (RMC) ,就是多head的attention改善缺陷。(实验有部分是RL的)

61
2018-NIPS-Inequity aversion improves cooperation in intertemporal social dilemmas
利用了inequity-averse individuals are personally pro-social and punish defectors的idea,扩展到SSD(sequential social dilemma),来促进合作。

62
2018-NIPS-Meta-Gradient Reinforcement Learning
关注的问题:what would be the best form of return for the agent to maximise? RL最终的目的是最大化平均的return,有两种常见的learning的setting:MC和TD(或者n-step)。这边的做法就是在一步TD的target和n-step(MC)的target做加权和,然后动态进行调整来进行快速学习。
63
2018-NIPS-Playing hard exploration games by watching YouTube
用demonstrations能够加速RL的学习过程,但是在现实世界中完美demonstrations很难产生。比如不同版本(山寨)的游戏的state,transition可能有略微的不同,那么如果只是略微不同的话,那么还是有机会进行利用的。
这边实际就在做demonstrations的微调(mapping到可以用的空间 或者 叫对其),使得略微不同的demonstrations能够进行复用。
第一步:对demonstrations进行mapping(利用video和声音),然后mapping到同一个表示上,这样就可以用其他的demonstrations的了。第二步:用一个YouTube video来做嵌入,来encourages an agent to imitate human gameplay。
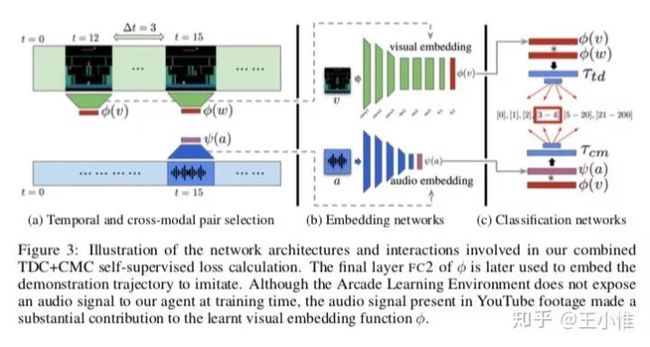
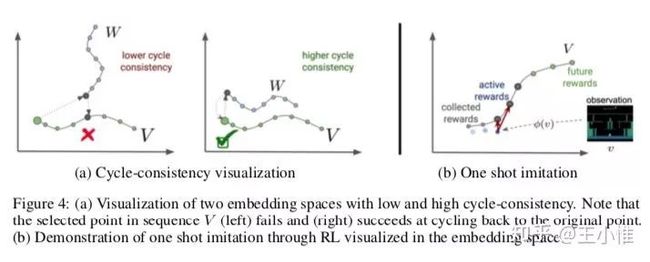
64
2018-ICLR-NOISY NETWORKS FOR EXPLORATION
常见的探索方式,比如e-greedy是在action space的维度加入noise来帮助探索的,这边是另辟蹊径,在网络的参数中加入noise来帮助探索,并验证了在A3C与DQN中,在参数中加入noise比entropy 和e-greedy更好。这边的具体实现如下图所示,就是将网络中layer的参数写成几部分组成:均值 + noise(方差),然后这个noise的大小可以通过leanring对应的权重来控制。
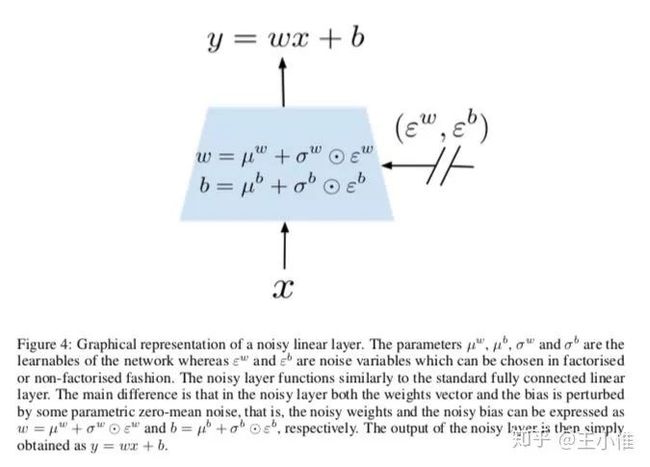
65
2018-AAAI-Rainbow: Combining Improvements in Deep Reinforcement Learning
将下图中的方法结合在一起,叫做Rainbow。(一图胜千言)
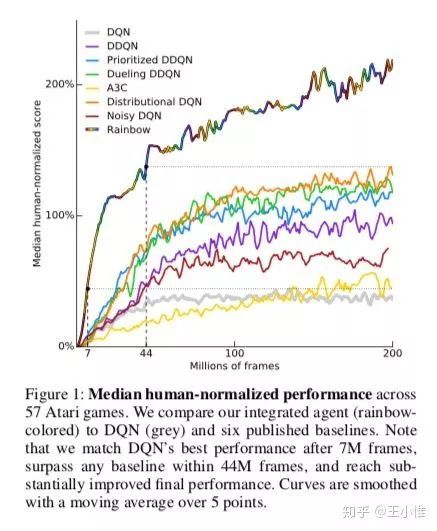
66
2018-AAMAS-Value-Decomposition Networks For Cooperative Multi-Agent Learning
这里的setting是:有一组合作的agent,他们共享一个reward signal,但是不知道是由谁来影响(提升)了这个共享的reward。如下图所示,左边是一般形式的multiagent中每个agent independent学习(执行)的过程,右边就是提出来的VDN(Value-Decomposition Networks),通过在最后一层对所有的agent的 做求和,视为 ,然后希望通过训练 来自动对每个agent做信度分配,来知道是那个agent引起了 的变化。这里的最基本假设是: ,即共享的reward signal本质上是由多个agent的实际reward的累积和。
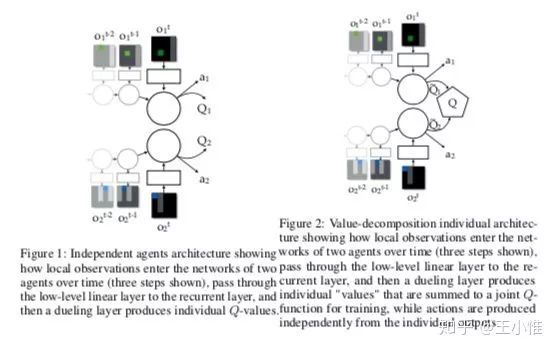
67
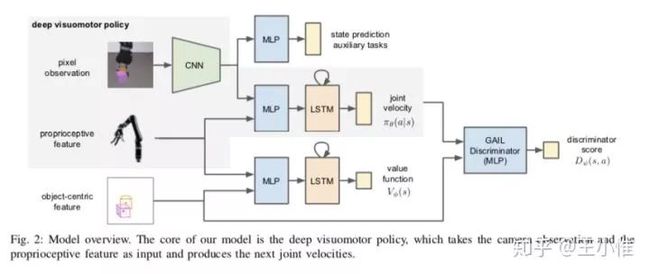
2018-RSS-Reinforcement and Imitation Learning for Diverse Visuomotor Skills
就是机器人上的运用:1.设计辅助任务帮助CNN提取特征,2. 用GAIL来learning出reward的signal辅助训练。

68
2018-RSS-Learning by Playing – Solving Sparse Reward Tasks from Scratch
提出:Scheduled Auxiliary Control (SAC- X), 利用辅助的任务来帮助学习(探索)主任务。通过上次的scheduler来选择相应的task,然后底层的目标学习:最大化主任务reward + 相应辅助任务的reward。



69
2019-02-12-ArXiv-SUCCESS AT ANY COST: VALUE CONSTRAINED MODEL-FREE CONTINUOUS CONTROL

直接将RL用在机器人的环境中容易导致高振幅,高频率控制信号的策略(bang-bang控制)。虽然这样的策略可以在模拟系统中实现最佳解决方案,但它们通常不适用于现实世界,因为bang-bang控制可能导致磨损和能量消耗增加,并且倾向于激发不期望的二阶动态。所以本文提出一种新的基于约束的方法,该方法定义了收益的下限,同时最小化了一个或多个cost(例如control effort),并使用拉格朗日松弛来学习:满足期望约束的控制策略的参数和用于优化的拉格朗日乘数。
70
2019-ICLR-EMERGENT COORDINATION THROUGH COMPETITION

Multiagent, 提出distributed population-based-training with continuous control的框架,结合automatic optimization of shaping reward channels,在连续控制的环境中进行end-to-end的学习。同时引入了automatically optimizing separate discount factors for the shaping rewards来促进sparse long-horizon team rewards and corresponding cooperative behavior。并采用counterfactual policy divergence来分析agent的行为.
71
2019-ICLR-Value Propagation Networks
利用Value Propagation (VProp),扩展了VIN(Value Iteration Networks ),分为:Value-Propagation Module与Max-Propagation Module。
其中Value-Propagation Module是先用embedding function来提取出相应的r和p,然后直接做多次迭代。然后Max-Propagation module (MVProp), in which only positive rewards are propagated.
72
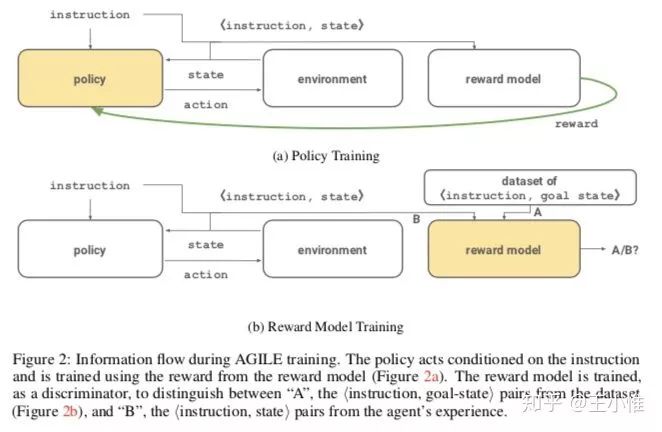
2019-ICLR-LEARNING TO UNDERSTAND GOAL SPECIFICATIONS BY MODELLING REWARD
希望设计出一种遵循instruction-conditional的RL agent。看下图,其实就是在state外,额外多拼接一个指令。然后reward model是来判别是否完成指令(通过state),然后给reward的。

关于作者:

(论文合集pdf获取)
后台回复关键字回复:DM72