Yolo模型部署的两种方法
目录
1 需求描述
第1种:封装darknet框架
第2种:weights模型转pb模型
2 weights模型转pb模型方法
3 重要备注
(1)关于预处理:
(2)关于模型输入输出的数据结构和节点名称:
(3)关于NMS
1 需求描述
工程部署使用的C++,模型用darknet(AB版)YoloV3训练的,格式为weights。目前已实测通过了两种方式调用yoloV3模型。
第1种:封装darknet框架
将darknet框架封装成dll,在C++中通过非常简单易懂的语法直接调用weights,cfg这两个原生文件。
优点:
编译非常简单:darknet(AB版)自带编译成dll的方法,操作过程也很简单,没有各种版本兼容性问题。
dll非常小:darknet框架编译出来的dll只有1.7MB。
C++语法非常精简易懂:完成模型调用和输出只有5行代码左右。
第2种:weights模型转pb模型
如果已经将tensorflow框架封装成dll,那么也可以将weights模型转成能供tensorflow直接使用的pb模型。
优点:使用tensorflow部署还是更可靠点,而且有时候一个项目不仅用一个算法,所有框架的模型都可以用tensorflow去实现。
2 weights模型转pb模型方法
darknet框架实现的yolo3有两个版本,一个是yolo3作者原版,还有一个是yolo4作者优化后的版本(AB版),虽然两者的cfg文件中内容一模一样,但是使用GitHub上找的不同版本的weights模型转pb轮子,将会出现异常。即,使用原版darknet yolo3的weights转pb的代码去转AB版yolo3 weights,虽然能转换成功,但是这个pb模型的精度几乎为0。
原因据查是AB版对yolo3算法做了模型结构之外的一些改进,这可能导致weights转pb的源代码不通用。
由于AB版darknet相对原版做了很多优化,而且为了能够在未来部署AB版的yolo4算法,这次仅记录下AB版yolo3的转换和部署方法。
weights转pb
转换代码在https://github.com/hunglc007/tensorflow-yolov4-tflite开源项目中,1100星,作者使用TF2.0框架将AB版darknet的yolo3和4复现了,里面有yolo3,yolo4转pb,转tensorflow lite(移动部署),转tensorRT模型的轮子。
步骤1:下载上述项目。(TF2.3版以上)
步骤2:CMD中执行如下指令即可转换成功:(修改你的weights模型位置,和你的输入大小)
python save_model.py --weights ./data/yolov3.weights --output ./checkpoints/yolov3-608 --input_size 608 --model yolov3
程序将会在当前项目路径内,生成一个./checkpoints/yolov3-608/文件夹,里面存放了如下转换结果:

步骤3:将saved_model.pb和variables两个东西放到你C++项目工程中就行了。
步骤4:C++中的模型调用和结果解析语法,可以参考如下博主的完整代码:
tensorflow C++接口调用 目标检测 pb模型代码 :https://www.cnblogs.com/cnugis/p/11506767.html
tensorflow C++接口调用 图像分类 pb模型代码:https://www.cnblogs.com/cnugis/p/11507872.html
3 重要备注
(1)关于预处理:
上述转换项目,仅仅是将yolo3模型原封不动的转成pb模型,这就表示,在C++工程中,还需要将输入pb模型的Mat图像先归一化,然后resize成608*608,最后才去调用pb模型进行预测。这些步骤,如果不想在C++中写,可以修改转换代码,即在python中先加一道预处理,修改模型输入的数据结构,然后再将weights转成pb。
(2)关于模型输入输出的数据结构和节点名称:
在save_model.py中,作者定义的pb模型输出是:“pred = tf.concat([boxes, pred_conf], axis=-1)”,即所有检测框坐标和预测值全部由一个输出变量表示。所以,C++那边就只要定义一个输出节点的名称。
pb模型输入输出节点的名称,以及输入输出的数据结构,可以在save_model.py中去寻找踪迹,也可用使用Netron软件打开pb模型去找到,比如:
例子1:yolo3一个输入(float32,表示接受float格式图像,大概率是要提前归一化后才能输入!),2个输出节点:


例子2:yolo3一个输入(uint8,表示图像是0-255,接受非归一化图像!),4个输出节点:
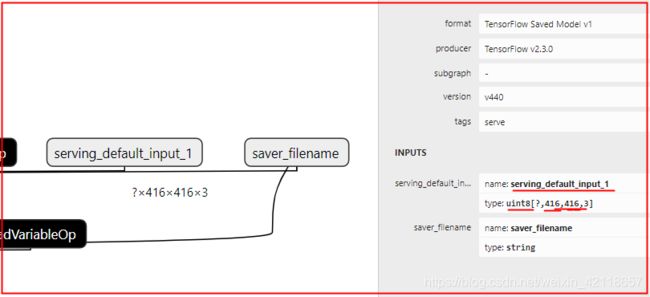

关于模型输入输出为什么是这个英文名,应该是程序默认的,除非自己定义了。
关于节点名称后面新增的“:0, :1”什么的,就是模型给予的默认的防止同名的输入输出节点。
(3)关于NMS
使用上述项目转换,模型的预测结果并没有经过NMS处理,这导致输出里面有很多近乎重叠的检测框。在C++中写NMS算法来筛选pb模型的检测结果可能比较麻烦,我们可以在转换模型过程中,将NMS也写进去,这样pb模型的输出就直接是经过NMS操作后的结果。
方法:
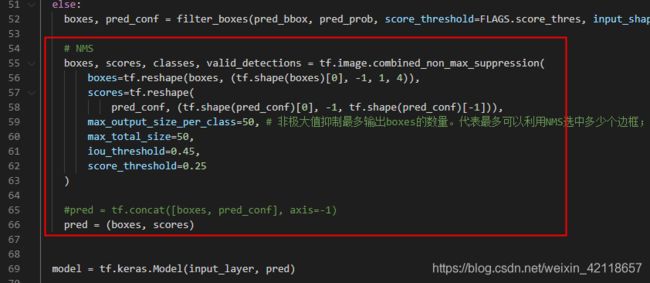
①在上述开源项目中,打开detect.py文件。
②复制其中的:boxes, scores, classes, valid_detections = tf.image.combined_non_max_suppression(......)这行代码。
③将上述代码粘贴在save_model.py中的“pred = tf.concat([boxes, pred_conf], axis=-1)”之前,并注释“pred = tf.concat([boxes, pred_conf], axis=-1)”,替换成“pred = (boxes, scores) ”,如下所示:
1