Win10下YOLOv3配置、制作数据集与训练检验
文章目录
- 前言
- 1、YOLO项目
- 2、电脑配置与环境
-
- 2.1 安装Cuda
-
- 2.1.1 查看本机驱动版本
- 2.1.2 安装过程
- 2.2 安装Cudnn
- 2.3 安装OpenCV
- 2.4 安装VS2017
- 3、编译
-
- 3.1 下载darknet
- 3.2 darknet.vcxproj文件的修改
- 3.3 darknet.sln文件的设置与编译
- 3.4 测试YOLOv3
- 3.5 总结一下常见错误
- 4、基于自己的数据创建YOLO数据集
-
- 4.1 labelimg标记数据集
- 4.2 数据集的搭建
-
- 4.2.1 下载VOC2007数据集
- 4.2.2 按照VOC2007的格式创建数据集
- 5、结果分析
-
- 5.1 Yolov3批量测试
- 5.2 AP / MAP / recall。
前言
近期做目标检测的实验,基于win10系统配置YOLOv3环境,因搭建过程多舛,故作此记录。此次记录一是为了做备份,加强对YOLO框架的了解与使用,在下次配置使用YOLO时能够有条不紊;二是给大家做一点参考,笔记中记录了搭建过程中的各种小插曲。因为本人之前没做过目标检测方面的实验,凭借查资料一步一步走通,花费了很长时间,绕了不少弯路,着实体会到了其对新人的不友好。在这篇手记里,我主要介绍的是配置流程与步骤,其中参考了许多前人的经验,均列出出处,感谢分享。
本文主要以配置使用YOLO检测为目的,文中多有引用前人的笔记与插图,以供大家参阅查看。其多是我已经借鉴过的文章,是可以解决问题的好笔记。如因借鉴冒犯,指出即删。
本文涉及到的所有文件,官方数据等,我会将网址指出。若是在文件或网址后有(见链接),其文件已经上传到微云。本文记录使用YOLOv3做目标检测的整个过程,包括环境配置,数据集制作以及查看训练结果,篇幅较长,对于一些细节可能会有遗忘,欢迎大家提出,我会在后面加以完善。由于课题组成员各个研究方向不一,缺乏交流探讨,搭建过程难免出现疏忽纰漏甚至错误,若大家发现,请指正!
微云链接:https://share.weiyun.com/1UhbIkRh
1、YOLO项目
官网:
https://pjreddie.com/darknet/
YOLO检测darknet安装教程:
https://pjreddie.com/darknet/install/
作者完整项目:
https://github.com/AlexeyAB/darknet
Tip:实践完两次才知道官网的重要性,计划了解更深入一点的话,建议直接原文,起码通篇过一遍,Trust me,磨刀不误砍柴工。
2、电脑配置与环境
主要参考文章:https://blog.csdn.net/KID_yuan/article/details/88380269
Win10
NVIDIA RTX 2060
VisualStudio2017community
OpenCV3.4 version(OpenCV-3.4.2-vc14_vc15.exe)
Cuda10.1 version(Cuda_10.1.105_418.96_win10.exe)
Cudnn-10.1-windows10-x64-v7.5.0.56(Cudnn-10.1-windows10-x64-v7.5.0.56.zip)
Tip:
① NVIDIA RTX 2060貌似不支持Cuda9.1,我尝试安装过Cuda9.1/9.2,均失败。目前显卡更新比较快,使用之前查查你的显卡与计划安装的Cuda版本是否兼容。
② Tensorflow、Cuda 和Cudnn的版本具有对应关系。
③有人说安装顺序很重要,先Cuda,再VS2017。我的安装顺序忘了,应该没有遵守,但是可以用,建议遵守,万一呢。
④ 以上配置支持YOLOv3,但是如果要配置YOLOv4的话,OpenCV version 可以用4.4.0版本(OpenCV-4.4.0-vc14_vc15.exe),4.4.0版本的OpenCV编译步骤是一样的,我已经测试可用,安装包以及YOLOv4权重文件(见链接)。
2.1 安装Cuda
主要参考文章: https://blog.csdn.net/bingo_liu/article/details/103224730
2.1.1 查看本机驱动版本
(1)桌面右击,点击NVIDIA控制面板(首先电脑得有显卡);
(2)打开面板,选择系统信息;

(3)选择组件按钮,查看显卡支持的最高版本,这儿并不是你电脑目前所装的Cuda版本,实际安装版本通过命令行nvcc -V查看;

2.1.2 安装过程
Cuda安装地址:https://developer.nvidia.com/cuda-toolkit-archive
(1)按照相应的版本进行选择下载;

(2)将下载的Cuda双击安装,这里的安装路径是临时解压路径,安装时会自动删除。

(3)选择自定义安装,可以选择安装驱动(网图);

(4)不要选Visual Studio Integration(网图);
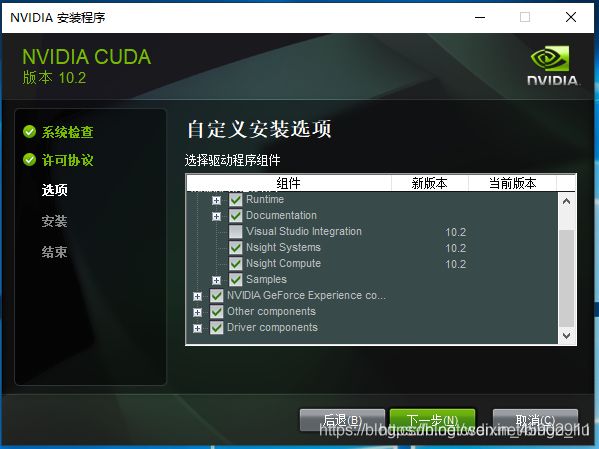
(5)记住安装位置,配置环境用。如果不想后期找路径的话,建议默认路径,后期出现问题在网上找答案大多也是基于默认路径给的处理过程(这是我之前装的9.2版本,应该是10.1);

(6)安装完成后配置环境,Path需要手动添加如下路径,对应上一步的安装路径(如果是默认安装路径,可以将版本号改了直接复制粘贴)。
- C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\lib\x64
- C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\include
- C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\extras\CUPTI\lib64
- C:\ProgramData\NVIDIA Corporation\CUDA Samples\v10.1\bin\win64
- C:\ProgramData\NVIDIA Corporation\CUDA Samples\v10.1\common\lib\x64


2.2 安装Cudnn
Cudnn安装地址(需注册):https://developer.nvidia.com/cudnn
Tip:选择Cudnn的时候,7.1.x后面跟着的是Cuda 版本号。
(1)对于Cudnn直接将其解开压缩包,然后需要将以下bin,include,lib文件复制粘贴到cuda的文件夹下;
- C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1

(2)测试Cuda是否安装成功,打开cmd命令窗口,输入:nvcc -V;

至此,Cuda 和 Cudnn安装成功!
2.3 安装OpenCV
OpenCV网址:https://opencv.org/releases/
Tip:不要使用3.4.1版本,官网说有bug。

![]()
双击解压安装,之后添加环境变量即可。

2.4 安装VS2017
主要参考:https://blog.csdn.net/qq_38737790/article/details/92797119
VS2017网址:https://docs.microsoft.com/zh-cn/visualstudio/releasenotes/vs2017-relnotes
安装版本(见链接),这个比较简单,上图:



到此,VS安装完毕!
3、编译
使用VS2017对YOLOv3中的darknet文件进行编译。
主要参考:(https://blog.csdn.net/qq_38737790/article/details/92797119)
编译之前,确保上述准备工作做好:
Win10+Cuda+Cudnn+Visual Studio 2017 Community+OpenCV3.4
编译过程难免遇到Error,可以先浏览一下3.5节中常见的错误,解决方法已经备好。
3.1 下载darknet
darknet网址:https://github.com/AlexeyAB/darknet
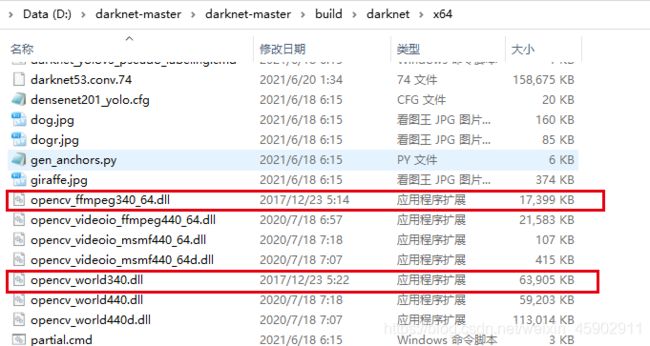
下载好之后,先进入darknet-master\darknet-master\build\darknet\x64文件夹下,将OpenCV3.4中的两个dll文件:OpenCV_ffmpeg340_64.dll和OpenCV_world340.dll复制到该文件夹下,不然后面运行会报错找不到dll。
3.2 darknet.vcxproj文件的修改
用文本编辑器、或记事本打开…\darknet-master\build\darknet下面的darknet.vcxproj。分别在55行和309行的CUDA 10.0=>CUDA 10.1(对应安装的CUDA版本,建议全文搜索CUDA)。


3.3 darknet.sln文件的设置与编译
(1)先打开vs2017,然后依次点击文件=>打开=>项目选中darknet.sln打开,打开后,vs会显示如下;
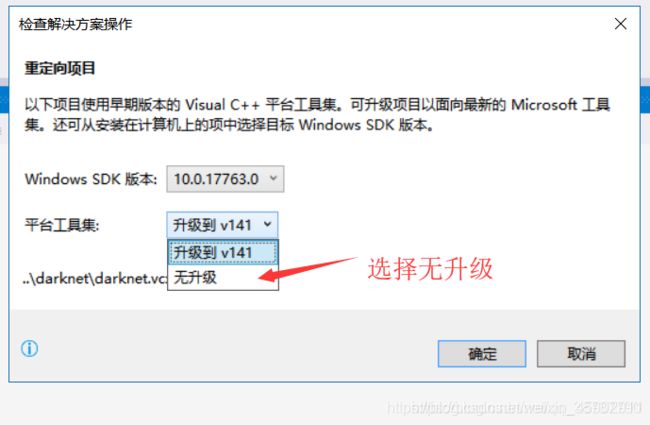
(2)一定要选择无升级,之后将项目改成Release x64,然后右键项目=>属性;
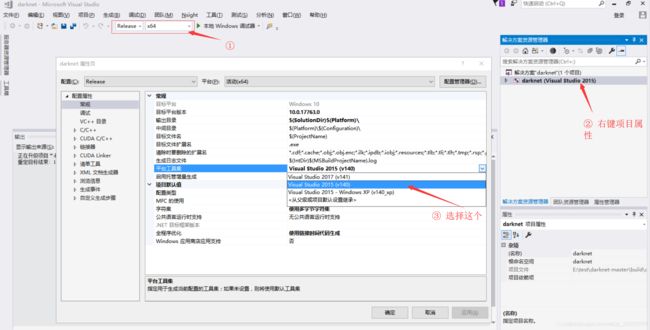
(3)选择VC++目录=>包含目录=>编辑添加目录:…\OpenCV\build\inclde(…表示各位OpenCV的安装路径,以下同理);

(4)配置库目录,添加:…\OpenCV\build\x64\vc14\lib;
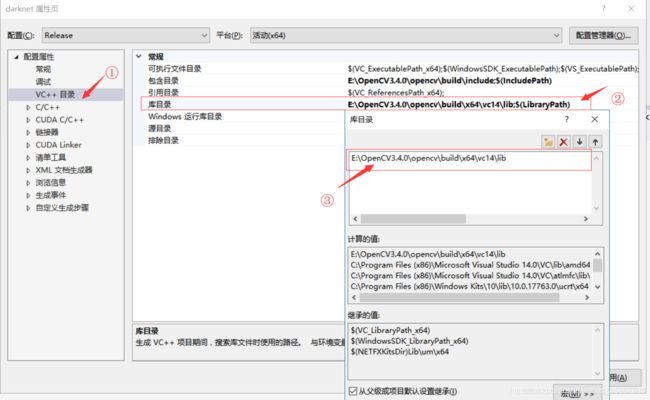
(5)选择C/C++=>常规=>附加包含目录=>编辑添加目录:…\OpenCV\build\include;
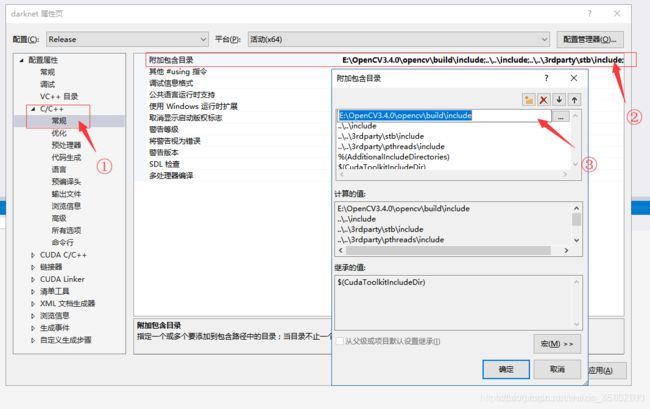
(6)选择链接器=>输入=>附加依赖项=>添加目录:…\OpenCV\build\x64\vc14\lib下库的名字:OpenCV_world340.lib;

(7)接着,需要拷贝安装好的CUDA 9.0.props等文件: CUDA 9.0.props等文件就在cuda的安装目录下,本人的路径是:
- C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\extras\visual_studio_integration\MSBuildExtensions

将里面的所有的文件拷贝到
- C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\Common7\IDE\VC\VCTargets\BuildCustomizations
中,这是vs2017安装后的路径。
注意注意,如果你没有该文件夹,不慌,我就遇到了。
主要参考:https://blog.csdn.net/weixin_44868057/article/details/106524786
1)打开cuda10.1的安装包;
2)把cuda临时解压包的路径改了(默认的如下图,现在要改到自己好找的地方);

3)解压完成之后,找到上述文件并把文件复制到
-C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\Common7\IDE\VC\VCTargets\BuildCustomizations
里面(网图)。


(8)最后,还需要确认电脑显卡的算力,我的电脑显卡是NVIDIA RTX 2060(根据自己的显卡),算力是75,修改darknet.vcxproj的compute值。

(9)完成上述之后,就可以在darknet工程上右键=>生成,就会发现在工程目录下x64下多了darknet.exe等文件啦,到这里就完成了darknet编译了。

你是小白的话,如果编译一次成功,建议跪下磕个响头,感谢上天待你不薄。
其实,VS的作用就是编译出darknet.exe,如果有别人编译好的darknet.exe直接拷贝来也是可以直接用的(见链接),可以跳过编译这一步。
3.4 测试YOLOv3
下载yolo3.weights,网址:https://pjreddie.com/media/files/yolov3.weights
下载后放在…\darknet-master\build\darknet\x64目录下;
然后进行测试,在当前目录下cmd打开命令窗口(也可以打开cmd,cd到darknet.exe的目录下),然后输入命令:
darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
到此,YOLO基本框架搭建完成!
3.5 总结一下常见错误
(1)编译失败,错误 MSB3721 命令。出现该问题就回到3.3节(8)步骤重新设置算力,该错误就是没有设置合适自己显卡的算力,如果改了还是不行,并且掺杂其他的错误命令,可能就是版本不匹配,怕是要重新搭配安装正确的版本。
(2)CUDA Error: out of memory 。电脑内存不够,解决方案见(参考)。
4、基于自己的数据创建YOLO数据集
4.1 labelimg标记数据集
主要参考:https://blog.csdn.net/yuejich/article/details/116653964
这一篇就写的很详细,按照步骤就可以标记数据,感谢分享。
这一步相对来讲比较简单,就简单做个总结。
小记:labelimg有许多版本,有的是.exe格式的,可以直接打开,有的需要cmd命令运行,这两类labelimg标记数据的程序我都用过,比较推荐cmd运行的版本,就是以上博主推荐使用的版本(见链接),其相较于打包成.exe格式的有两点优势:其一,打包成.exe格式的labelimg图片标记工具只能保存xml格式的文件,而cmd命令行运行的具有xml、txt(YOLO使用)、json三种保存格式。其二,虽说做YOLO数据集时,图片标记时可以保存成YOLO的.txt模式,但是xml和txt文件之间可以相互转换,后面有xml转txt文件的详细步骤,所以保存时建议保存成xml格式。推荐使用cmd运行版本的主要原因是,在最初使用exe格式的图片标注工具会出现采集图片长宽数据为零的问题,导致xml转txt时出现问题,所以这里也提醒大家,做数据集时先采取小样本测试一下标记的数据集是否运行顺利,以防跳楼。
还有一个小Tip:因为数据量大,我一开始将数据存储在U盘中,在U盘中进行数据标记的工作,标记的时候就比较卡顿,将数据转到电脑存盘就不会了。
4.2 数据集的搭建
不要浪费时间自己搭建结构,听我的,直接下载原始文件夹,然后将原始数据替换掉,这是搭建YOLO数据的一个重要的环节,搭建错了事倍倍功半半,听话。
4.2.1 下载VOC2007数据集
VOC2007下载地址:https://pjreddie.com/projects/pascal-voc-dataset-mirror/
(1)数据下载好应该是三个文件夹(见链接),如下:

(2)解压的时候记得一起解压,最终会解压到一个文件夹下VOCdeckit。
![]()
trainval和test数据集是从一个完整数据集划分来的,所以目录结构一样,且不存在冲突的图片命名。所以解压完成后相当于将两个子数据集合并成一个完整的有train,val,trainval,test的大数据集。
(3)将VOCdevkit文件夹放到darknet-master\build\darknet\x64\data\下;

(4)其数据结构基本如下,该图清楚显示了VOCdeckit文件夹放置的位置以及VOC2007的内部文件结构。

4.2.2 按照VOC2007的格式创建数据集
主要参考:https://blog.csdn.net/matt45m/article/details/104329350
好了,结构说明后,后面就是使用自己的数据替换官方数据。先前使用labelimg图片标记工具根据jpg图片已经得到xml文件,下面就是将VOC2007里的数据替换成自己的数据(把以下涉及到存储数据的文件夹里的原始的数据都可以删掉,替换成自己的)。
(1)标注好的xml文件对应存在VOC2007目录Annotations里面,被标注的jpg图像放在JPEGImages里面。标注好的数据是一一对应的,有了这两个数据,其它使用的数据都可以根据这两个数据产生;
xml数据:

jpg数据:
(2)ImageSets下面有一个Main目录,里面的原始数据可删,因为用不到,文件多了扰乱视听;
(3)用python创建Main目录里面的train.txt,val.txt,test.txt和trainval.txt这四个文件。
在VOC2007目录下创建一个python代码,命名Main.py,该程序可在pycharm中运行,也可以直接在当前目录下打开cmd运行该程序(建议),很快哈。

Main.py的代码如下:
import os
import random
trainval_percent = 0.1 #训练的验证集比例
train_percent = 0.9 #训练的训练集比例
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
运行之后,在Main文件夹下生成了四个txt文件,文件内容如下:

文件内容如下:

其实就是随机分配的图片名,按照设定比例被随机分成了训练集,验证集和测试集。
(4)xml数据转YOLOv3的txt数据
1)在工程目录下darknet\build\darknet\x64\data\voc位置下找到voc_label.py这个文件,复制到darknet\build\darknet\x64\data下;

2)更改的代码,有两个位置,一个是数据文件夹,一个是标注数据的标签名;
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
# sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
#修改一:删掉"('2012', 'train'), ('2012', 'val')," 因为没有用到该数据集
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
#修改二:将classes[***] 中的类别换成自己的
classes = ["void", "cavity"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
3)保存之后cmd运行,会在当前的目录下多出三个文件以及在VOC2007目录下生成一个labels文件夹。


4)挑一个2007_train.txt,打开如下(就是图片的存储路径):

5)生成的labels文件夹以及文件夹下的txt文件;
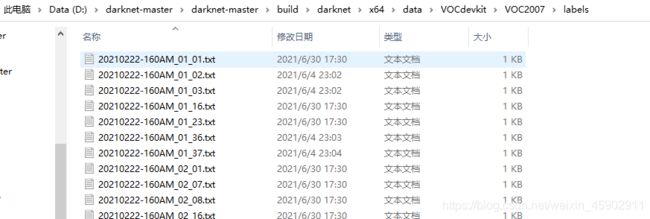
6)挑一个.txt,打开如下(就是YOLO训练用格式数据)。

(5)根据自己的数据修改配置文件
1)在darknet\build\darknet\x64\data目录下找到voc.data文件;
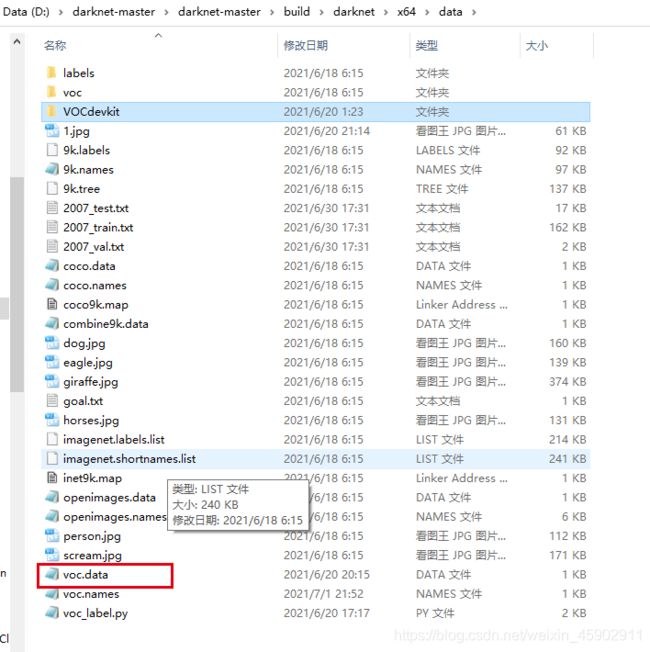
2)打开voc.data,根据自己的实际更改;
classes= 2 #类别数量
train = data/2007_train.txt #如果按照上述结构配置,不必更改
valid = data/2007_test.txt #如果按照上述结构配置,不必更改
#difficult = data/difficult_2007_test.txt
names = data/voc.names #这里对应的是下一步更改的文件
backup = backup/ #存储训练权重的文件夹
3)找到voc.names文件,也在darknet\build\darknet\x64\data目录下;

改成自己标注的名字;

4)在darknet\build\darknet\x64目录在找到yoloV3.cfg文件,打开该文件,找到max_batches,更改迭代次数,改成自己想要迭代的次数;

5)修改classes和filters这两个地方(各三处)。
三个yolo层都要改:yolo层中的class为类别数,每一个yolo层前的conv层中的filters =(classes+5)* 3。
例如:
yolo层 classes=1,conv层 filters=18
yolo层 classes=2,conv层 filters=21
yolo层 classes=4,conv层 filters=27
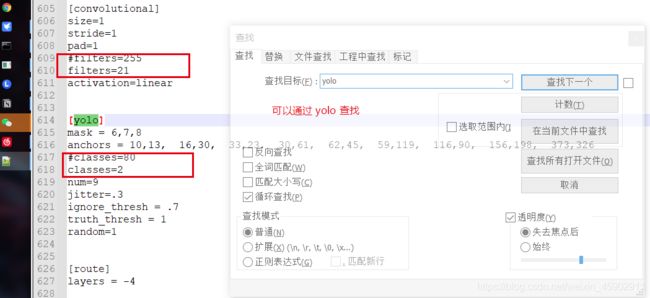
(5)训练模型;
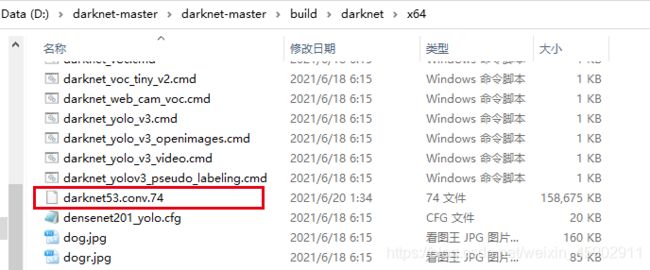
1)下载权重文件darknet53.conv.74(见链接)。
网址:http://pjreddie.com/media/files/darknet53.conv.74
权重文件darknet53.conv.74放到darknet\build\darknet\x64下。
2)当前x64目录下打开cmd,输入训练命令:
darknet.exe detector train data/voc.data yolov3.cfg darknet53.conv.74

3)开始训练。


5、结果分析
主要参考:https://blog.csdn.net/clover_my/article/details/90522201
5.1 Yolov3批量测试
Tip:这一步是需要重新编译的(在之前配置好的VS2017的基础上),如果前面能够编译成功,这一步问题不大。但是要把之前的darknet.exe换地方保存,因为会替换掉,这一步编译的好像不支持训练,好像是这样,反正记得保存,没坏处。
(1)用VS打开darknet的工程文件darknet.sln;

(2)找到detector.c进行修改;
1)头文件添加;
#include 2)添加GetFilename函数(这个函数是另外添加的);
char *GetFilename(char *p)
{
static char name[20] = { "" };
char *q = strrchr(p, '/') + 1;
strncpy(name, q, 6);//注意后面的6,如果你的测试集的图片的名字字符(不包括后缀)是其他长度,请改为你需要的长度(官方的默认的长度是6)
return name;
}
3)找到test_detector函数进行如下修改(约第1615行);
void test_detector(char *datacfg, char *cfgfile, char *weightfile, char *filename, float thresh,
float hier_thresh, int dont_show, int ext_output, int save_labels, char *outfile)
{
list *options = read_data_cfg(datacfg);
char *name_list = option_find_str(options, "names", "data/names.list");
int names_size = 0;
char **names = get_labels_custom(name_list, &names_size); //get_labels(name_list);
image **alphabet = load_alphabet();
network net = parse_network_cfg_custom(cfgfile, 1, 1); // set batch=1
if (weightfile) {
load_weights(&net, weightfile);
}
fuse_conv_batchnorm(net);
calculate_binary_weights(net);
if (net.layers[net.n - 1].classes != names_size) {
printf(" Error: in the file %s number of names %d that isn't equal to classes=%d in the file %s \n",
name_list, names_size, net.layers[net.n - 1].classes, cfgfile);
if (net.layers[net.n - 1].classes > names_size) getchar();
}
srand(2222222);
double time;
char buff[256];
char *input = buff;
int j, i;
float nms = .45; // 0.4F
if (filename) {
strncpy(input, filename, 256);
list *plist = get_paths(input);
char **paths = (char **)list_to_array(plist);
printf("Start Testing!\n");
int m = plist->size;
for (i = 0; i < m; ++i) {
char *path = paths[i];
image im = load_image(path, 0, 0, net.c);
int letterbox = 0;
image sized = resize_image(im, net.w, net.h);
//image sized = letterbox_image(im, net.w, net.h); letterbox = 1;
layer l = net.layers[net.n - 1];
float *X = sized.data;
double time = get_time_point();
network_predict(net, X);
printf("%s: Predicted in %lf milli-seconds.\n", input, ((double)get_time_point() - time) / 1000);
printf("Try Very Hard:");
printf("%s: Predicted in %lf milli-seconds.\n", path, ((double)get_time_point() - time) / 1000);
int nboxes = 0;
detection *dets = get_network_boxes(&net, im.w, im.h, thresh, hier_thresh, 0, 1, &nboxes, letterbox);
if (nms) do_nms_sort(dets, nboxes, l.classes, nms);
draw_detections_v3(im, dets, nboxes, thresh, names, alphabet, l.classes, ext_output);
char b[2048];
sprintf(b, "test_pics/%s", GetFilename(path)); //图片保存的位置,或可用绝对路径“E:\\xxxxxx\\build\\darknet\\x64\\test_pics”
save_image(im, b);
printf("save %s successfully!\n", b);
if (save_labels)
{
char labelpath[4096];
replace_image_to_label(input, labelpath);
FILE* fw = fopen(labelpath, "wb");
int i;
for (i = 0; i < nboxes; ++i) {
char buff[1024];
int class_id = -1;
float prob = 0;
for (j = 0; j < l.classes; ++j) {
if (dets[i].prob[j] > thresh && dets[i].prob[j] > prob) {
prob = dets[i].prob[j];
class_id = j;
}
}
if (class_id >= 0) {
sprintf(buff, "%d %2.4f %2.4f %2.4f %2.4f\n", class_id, dets[i].bbox.x, dets[i].bbox.y, dets[i].bbox.w, dets[i].bbox.h);
fwrite(buff, sizeof(char), strlen(buff), fw);
}
}
fclose(fw);
}
free_detections(dets, nboxes);
free_image(im);
free_image(sized);
//free(boxes);
//free_ptrs((void **)probs, l.w*l.h*l.n);
}
}
printf("All Done!\n");
system("pause");
exit(0);
free_ptrs(names, net.layers[net.n - 1].classes);
free_list_contents_kvp(options);
free_list(options);
const int nsize = 8;
for (j = 0; j < nsize; ++j) {
for (i = 32; i < 127; ++i) {
free_image(alphabet[j][i]);
}
free(alphabet[j]);
}
free(alphabet);
free_network(net);
printf("All Done!\n");
system("pause");
}
这里改的时候还是要注意一下的,具体的完整代码我会放在链接里(detector.c测试精度用.txt),如果上面没讲明白就对照整体代码修改,可替换。
4)右键darknet重新生成;

(3)批量测试并保存结果;
1)在…\darknet-master\build\darknet\x64目录下新建test_pics文件夹存放测试后的图片结果。
2)在当前x64目录下cmd打开命令窗口,输入:
darknet.exe detector test data\\voc.data yolov3.cfg backup\\yolov3_final.weights D:\\darknet-master\\darknet-master\\build\\darknet\\x64\\data\\2007_test.txt
其中“D:\darknet-master\darknet-master\build\darknet\x64\data\2007_test.txt”是测试文件保存路径,2007_test.txt就是之前用voc_label.py生成的文件,打开为测试图片的绝对路径。
运行即可(在…\darknet-master\build\darknet\x64目录下新建的test_pics文件夹已生成测试后的图片结果)。
5.2 AP / MAP / recall。
(1)AP / MAP
在当前x64目录下cmd打开命令窗口,输入:
darknet.exe detector map data\\voc.data yolov3.cfg backup\\yolov3_final.weights
运行即可;

(2)recall
在当前x64目录下cmd打开命令窗口,输入:
darknet.exe detector recall data\\voc.data yolov3.cfg backup\\yolov3_final.weights
运行结果如下:
