【读论文】DIVFusion: Darkness-free infrared and visible image fusion
【读论文】DIVFusion: Darkness-free infrared and visible image fusion
- 介绍
- 网络结构
-
- SIDNet
-
- 损失函数
- TCEFNet
-
- GRM(梯度保持模块)
- CEM(对比度增强模块)
- 损失函数
- 总结
- 参考
论文:https://www.sciencedirect.com/science/article/abs/pii/S156625352200210X
如有侵权请联系博主
介绍
博主之前读过的论文中几乎都没有谈到怎么提高夜视图照明强度的问题,这篇论文则是在这个方向也做了工作。
先看下文章中提到的之前融合算法未考虑的内容
在低光照条件下,先前的融合方法仅使用红外信息来填充由可见图像的照明退化导致的场景缺陷。结果,夜间可见光图像中丰富的场景信息无法在融合图像中表达,这偏离了红外和可见光图像融合任务的初衷。第二,直观的解决方案是使用先进的低光增强算法预增强可见图像,然后通过融合方法合并源图像。然而,将图像增强和图像融合视为单独的任务通常会导致不兼容的问题,这导致如图所示的较差的融合结果。具体来说,由于夜景光线较弱,夜间可见图像有轻微的颜色失真。低光增强算法改变了光源的颜色分布,并在某种程度上进一步放大了整个图像中的颜色失真。此外,在融合过程中,由于Y通道中应用的融合策略改变了源图像中的饱和度分布,融合图像中也会出现颜色失真。
针对以上问题,文章提出的算法包含两个部分,第一部分是场景照明解纠缠网络(SIDNet),第二部分是纹理对比度增强融合网络(TCEFNet)。简单来说,第一部分用于生成照明效果提升的特征,第二部分则是使得融合结果有更好的对比度和纹理信息,接下来一步步介绍这些内容。
网络结构
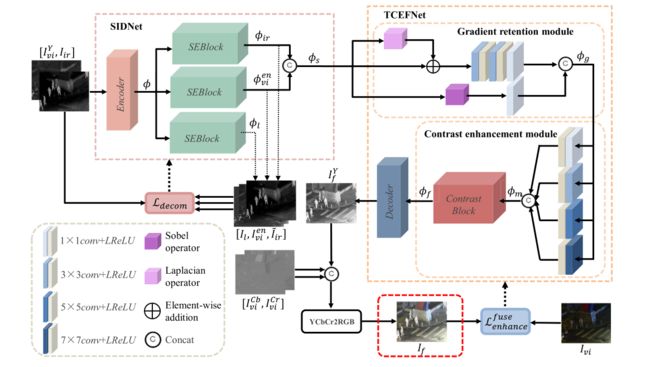
先来个整体的网络架构,不要被吓到,咱们慢慢往下看,现在看着很复杂,其实并没有那么复杂。
SIDNet

SIDNet网络相对来说比较简单,可以说由三部分组成,分别是编码器,注意力块和解码器。
这里编码器(Encoder)有四层网络,每一层网络都采用LRelu激活函数,每一层的卷积核数都是3x3
注意力块(SEBlock)由一个最大池化层,两个全连接层组成,最后一个全连接层输出一个向量,与原来解码器输出的结果进行相乘,从而实现注意力的效果。
三个解码器(Dl,Dvi,Dir)分别对前面提取的特征进行解码,还原成对应的图像。这里注意,当使用模型融合图像时,是不需要再生成重建的图像的,这里的解码器只是在训练的时候迫使SIDNet可以生成更好的特征。
损失函数
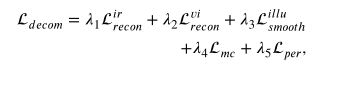
上面是整体的损失函数,看着挺复杂的,其实还真挺复杂的

虽复杂,该读咱还得接着读,继续往下搞。
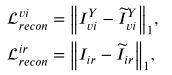
先看下前两项的损失函数,分别是可视图像和红外图像重建损失函数。这俩还相对好理解点,你可以发现,就是直接求生成的红外图像和生成的只有Y通道的可视图像与原图像的差异,使用这个损失从而迫使SIDNet恢复原图像,和生成更好的特征。
读到这里,细心的你有没有发现个问题,这个增强后的Y通道可视图像信息哪来的?是那个输出的增强图像吗?如果是的话,那我在这个网络里是要干啥来着,不是增强可视的亮度信息,怎么最后重构的图像还要和原图进行比较,那我增强亮度还有啥意义????

如果你也发现这个小问题,别着急,咱么接着往下看,原来下面还有个公式,是将增强亮度的图像还原到原图,这样就可以理解了,公式如下
![]()
这样我们就理解了,为啥还需要再计算一个照明分量了。
那么怎么约束这个照明分量呢,公式如下,这里博主不是很理解,后面再来添加我的理解,具体可参考原文。
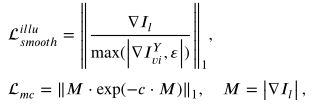
最后就是关于增强可视图像的生成了,怎么可以保证生成图像是增强亮度之后的结果呢,这里是使用直方图均衡增强后的图像作为对比,从而使得可以生成增强的可视图像。
![]()
看到这,你是不是又有疑惑了,咋着,我为啥不直接用直方图均衡化生成目标图像呢,非要用神经网络生成的目标图像的特征去和均衡化后的图像的图标进行比对?
那么答案是什么呢,庆幸的是,作者在前面告诉我们了,再引用一下子
直观的解决方案是使用先进的低光增强算法预增强可见图像,然后通过融合方法合并源图像。然而,将图像增强和图像融合视为单独的任务通常会导致不兼容的问题,这导致如图所示的较差的融合结果。具体来说,由于夜景光线较弱,夜间可见图像有轻微的颜色失真。低光增强算法改变了光源的颜色分布,并在某种程度上进一步放大了整个图像中的颜色失真。此外,在融合过程中,由于Y通道中应用的融合策略改变了源图像中的饱和度分布,融合图像中也会出现颜色失真。
到此SIDNet所有的损失函数都介绍完毕了。
TCEFNet
GRM(梯度保持模块)
首先先清除该部分的功能,即保持梯度。
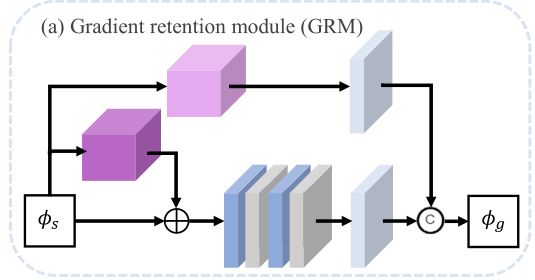
这里从上往下看,最上面的一条通路中,第一个块是sobel算子操作,为了保留强纹理信息,然后在进行卷积核为1的卷积操作,然后得到输出(这里做卷积核为1的原因是什么,不是很清楚,原文中解释说是消除通道维度的差异,不是很理解)。
再往下看,从上向下第二个通路,只有一个块,是拉普拉斯算子操作,目的是为了保留弱纹理信息,然后再与输入的ϕs(SIDNet的输出)进行相加操作,然后再经历一系列的卷积和激活,最终得到的结果与上一个通道的结果进行通道级别的相连作为最后的输出ϕg。
CEM(对比度增强模块)
该模块用于对比度的增强。
下图红色框中的是CEM的网络结构
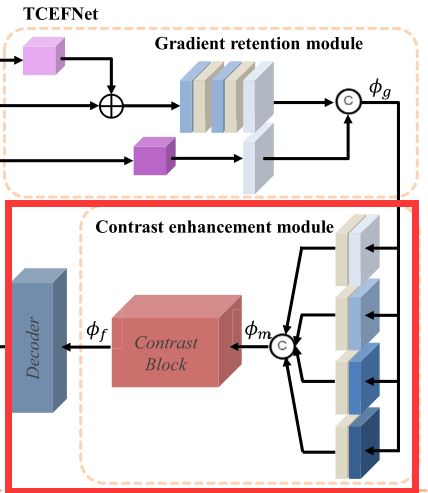
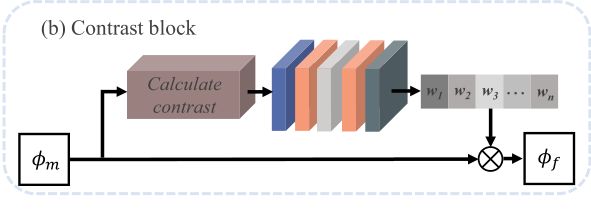
CEM的结构结合这两个图来理解比较简单一下。
看论文中的过程中,关于这部分的介绍提到了多尺度的问题,但是单看第二张图可能很难理解,因此我觉得第一张图和第二张图结合起来比较好理解。
可见,第一张图红框中的右边有四个卷积层,四个卷积层的卷积核分别是1×1、3×3、5×5、7×7。使用这四个不同大小的卷积核从而达到多尺度的目的。多尺度信息连接之后形成ϕm,随后ϕm被输入到Contrast Block中,Contrast Block的结构如第二张图所示。可见该结构也是实现了注意力机制,首先对ϕm进行处理,处理公式如下
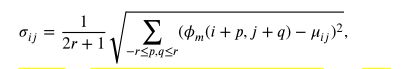
这里r是窗口的半径,μ是该窗口内数据的均值,σ是该窗口内数据的标准差。
按我个人的理解,这里的标准差代表窗口数据的差异性,差异性越大,标准差就会越大,反映到后面的注意力块的话,即标准差整体越大的通道,最终与之的权重就越大,从而达到了增强对比度的作用。
损失函数
![]()
从左至右,分别是纹理损失,强度损失和颜色一致性损失,a1到a3分别是超参数,协调这三个损失的参数。
![]()
先来看下纹理损失函数的定义,设计的蛮妙的,和其他论文不同的是,这里不再只将融合图像和可视图像梯度进行对比,而是与两类图像中梯度较大的进行比较,从而保留高频信息,使得融合图像的纹理保留的更加丰富。
![]()
该损失函数使得融合图像拥有更多的红外目标信息,即通过融合图像和红外图像之间像素的差异来促进保留更多的红外目标信息。
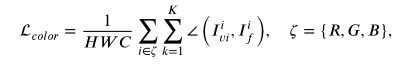
最后就是减少颜色失真的损失函数,这里采用离散余弦距离来约束融合图像的颜色分布,从而使得融合图像的颜色分布尽可能接近原始图像。
总结
整个论文读下来,很惊艳,这里说说我觉得很好的几个点
- 在博主读过的论文中,这是第一个对图像亮度进行增强的文章
- 将sobel算子,拉普拉斯算子运用到融合中,与神经网络相结合,从而保留图像的纹理细节
- 融合时采用Y通道与红外图像进行融合,与DDcGAN中提到的对MRI图像和PET图像融合有异曲同工之妙
- 采用多尺度特征+SE实现对比度增强
- 纹理信息的损失函数考虑到了红外图像目标信息,保留更多的高频部分,纹理细节更加丰富了
论文读的有点糙,欢迎大佬们指正
其他融合图像论文解读
【读论文】RFN-Nest: An end-to-end residual fusion network for infrared and visible images
【读论文】DDcGAN
【读论文】Self-supervised feature adaption for infrared and visible image fusion
【读论文】FusionGAN: A generative adversarial network for infrared and visible image fusion
【读论文】DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pairs
【读论文】DenseFuse: A Fusion Approach to Infrared and Visible Images
参考
[1] DIVFusion: Darkness-free infrared and visible image fusion