李沐《动手学深度学习》课程笔记:12 权重衰退
目录
12 权重衰退
1.权重衰退
2.代码实现
12 权重衰退
1.权重衰退
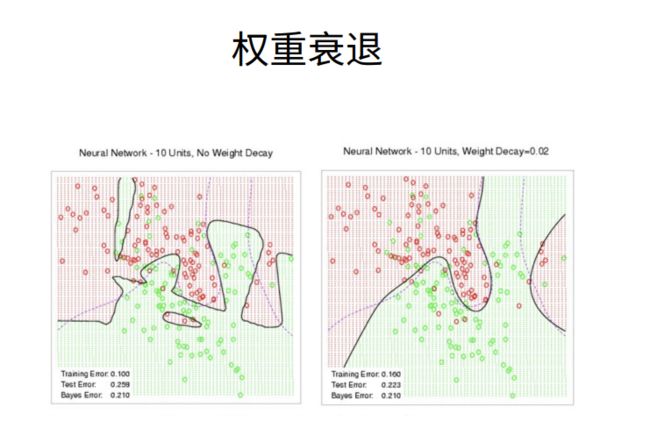


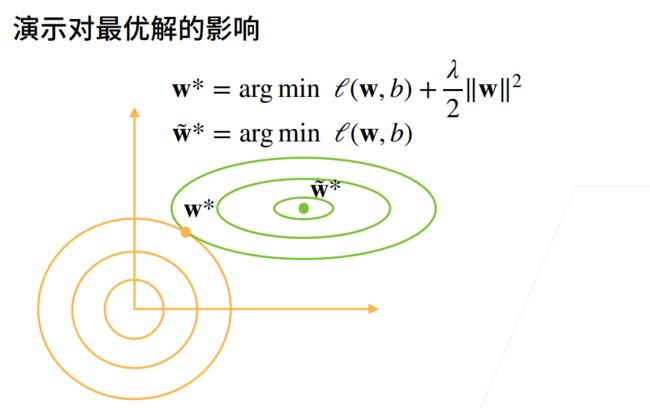


2.代码实现
# 权重衰减,权重衰减是最广泛使用的正则化的技术之一
import torch
import os
import matplotlib.pyplot as plt
from torch import nn
from d2l import torch as d2l
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05
train_data = d2l.synthetic_data(true_w, true_b, n_train)
train_iter = d2l.load_array(train_data, batch_size)
test_data = d2l.synthetic_data(true_w, true_b, n_test)
test_iter = d2l.load_array(test_data, batch_size, is_train=False)
# 初始化模型参数
def init_params():
w = torch.normal(0, 1, size=(num_inputs, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
return [w, b]
# 定义L2范数惩罚
def l2_penalty(w):
return torch.sum(w.pow(2)) / 2
# 定义训练代码实现
def train(lambd):
w, b = init_params()
net, loss = lambda X: d2l.linreg(X, w, b), d2l.squared_loss
num_epochs, lr = 100, 0.003
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log', xlim=[5, num_epochs],
legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
# with torch.enable_grad():
l = loss(net(X), y) + lambd * l2_penalty(w)
l.sum().backward()
d2l.sgd([w, b], lr, batch_size)
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
print('w的L2范数是:', torch.norm(w).item())
plt.show()
train(lambd=0)
w的L2范数是: 14.082565307617188 