【迁移网络学习实战】- Kaggle猫狗分类大赛 - 多模型融合 - 前1.7%
【迁移网络学习实战】- Kaggle猫狗分类大赛 - 前1.7%
数据集下载:
链接:https://pan.baidu.com/s/1AIj0FhdCQPeAWg4Sw7DEOQ
提取码:aejj
一、内容
想要将深度学习应用于小型图像数据集,一种常用且非常高效的方法是使用预训练网络。预训练网络是一个保存好的网络,之前已在大型数据集(比如在ImageNet数据集140万张标记图像)上训练好。如果这个原始数据集足够大且足够通用,那么预训练网络学到的特征的空间层次结构可以有效地作为视觉世界的通用模型。比如VGG、ResNet、Inception、Inception-ResNet、Xception这些通用网络都已经训练好,我们只需要进行迁移就行。
上次分享的是单模型,这次融合多个模型进行提高。思路是将每种模型最后卷积层跑出的特征抽取出来,然后将两个特征进行叠加,融合成一个新的特征。再构建一个全新的分类器,将新的融合特征丢进去训练。
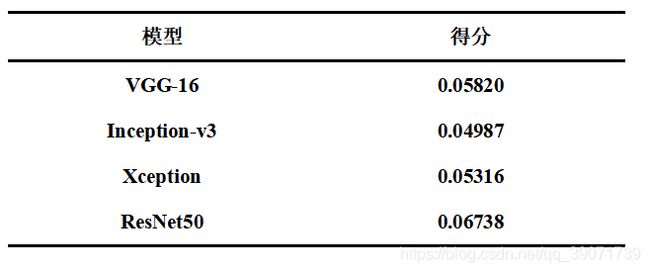
要进行模型融合的话必须得知道哪些模型在这个数据集上表现是好的,没有办法,只能挨个跑模型测试,时间精力还是有限的,我一共尝试了4个模型Inception-v3、Xception、VGG、ResNet50。经过结果分析,那么选择Inception-v3、Xception两种网络去做一个融合是最好的,强强联合。
二、代码
1.训练部分
import cv2
import numpy as np
from tqdm import tqdm
from sklearn.model_selection import train_test_split
from keras.layers import *
from keras.models import *
from keras.applications import *
from keras.optimizers import *
from keras.applications.inception_v3 import preprocess_input
from keras.callbacks import ModelCheckpoint
import matplotlib.pyplot as plt
import h5py
n = 25000
width = 299
# 张量
X = np.zeros((n, width, width, 3), dtype=np.uint8)
y = np.zeros((n,), dtype=np.uint8)
# 读取图片设置标签
for i in tqdm(range(12500)):
X[i] = cv2.resize(cv2.imread('D:/DeepLearning/cat_dog/kaggle/train/cat.%d.jpg' % i), (width, width))
X[i+12500] = cv2.resize(cv2.imread('D:/DeepLearning/cat_dog/kaggle/train/dog.%d.jpg' % i), (width, width))
y[12500:] = 1
# 进行特征抽取
def get_features(MODEL, data=X):
cnn_model = MODEL(include_top=False, input_shape=(width, width, 3), weights='imagenet')
inputs = Input((width, width, 3))
x = inputs
x = Lambda(preprocess_input, name='preprocessing')(x)
x = cnn_model(x)
x = GlobalAveragePooling2D()(x)
cnn_model = Model(inputs, x)
features = cnn_model.predict(data, batch_size=12, verbose=1)
return features
inception_features = get_features(InceptionV3, X)
xception_features = get_features(Xception, X)
features = np.concatenate([inception_features, xception_features], axis=-1)
# 建议保存h5,此处可直接读取特征
# with h5py.File('features','r')as d:
# features = np.array(d['features'])
# 构建网络
inputs = Input(features.shape[1:])
x = inputs
x = Dropout(0.5)(x)
x = Dense(1, activation='sigmoid')(x)
model = Model(inputs, x)
# 训练设置
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])
best = ModelCheckpoint('model_2.h5',monitor='val_loss',verbose=1,save_best_only=True)
history = model.fit(features, y, batch_size=8, epochs=30, validation_split=0.2,callbacks=[best])
# 绘图
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
2.测试部分
import cv2
import numpy as np
from tqdm import tqdm
import pandas as pd
from keras.applications import *
from keras.applications.inception_v3 import preprocess_input
from keras.layers import *
from keras.models import *
# 测试图片
m = 12500
width = 299
model = load_model('model_2.h5')
X_test = np.zeros((m, width, width, 3), dtype=np.uint8)
# 读取
for i in tqdm(range(m)):
X_test[i] = cv2.resize(cv2.imread('D:/DeepLearning/cat_dog/kaggle/test/%d.jpg' % (i+1)), (width, width))
# 获取特征
def get_features(MODEL, data=X_test):
cnn_model = MODEL(include_top=False, input_shape=(width, width, 3), weights='imagenet')
inputs = Input((width, width, 3))
x = inputs
x = Lambda(preprocess_input, name='preprocessing')(x)
x = cnn_model(x)
x = GlobalAveragePooling2D()(x)
cnn_model = Model(inputs, x)
features = cnn_model.predict(data, batch_size=12, verbose=1)
return features
inception_features = get_features(InceptionV3, X_test)
xception_features = get_features(Xception, X_test)
features_test = np.concatenate([inception_features, xception_features], axis=-1)
# 模型预测
y_pred = model.predict(features_test, batch_size=8, verbose=1)
# 写进csv
df = pd.read_csv('sample_submission.csv')
df['label'] = y_pred.clip(min=0.005, max=0.995)
df.to_csv('pred.csv', index=None)三、结果
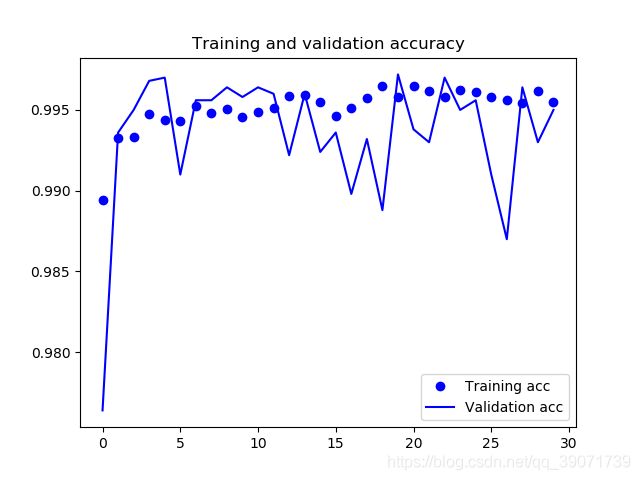
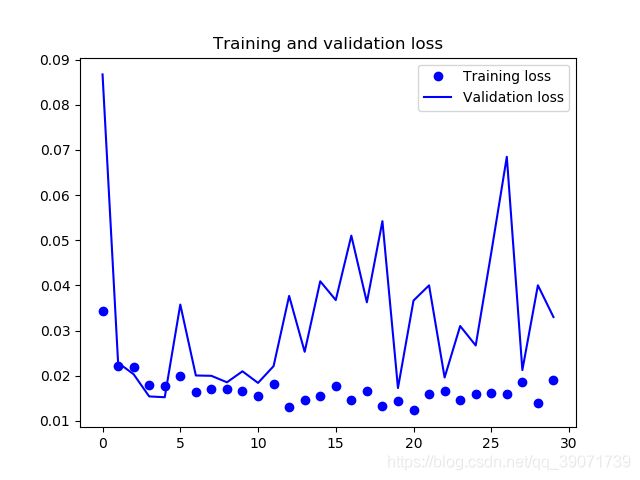
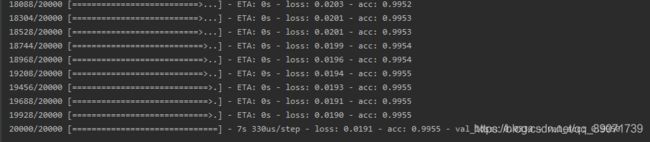
从结果来看,是获得了一个巨大的提升。训练集的正确率达到了99.76%,验证集的正确率达到99.55%,获得了预期的效果。进一步对其上传官方指定的测试集进行测试,上传至官方进行评估。提交了结果,得分在0.04308,由于该排行榜停止了更新,大概看了下,理论上目前成绩应该在23名左右,前1.7%(23/1314)可以说进阶迁移学习实战是成功的。
迁移学习确实展现了巨大的能力,但是目前不知道迁移到医学影像上会怎样,之后会尝试。我目前从事医学图像分析,所以同时有个强烈的希望,科研界如果谁能公布一个(类似ImageNet)这样的大型医学影像预训练数据库就好了,例如涉及各种器官、各种影像模态,这样会使得各种模型都会释放出更强大的性能,我觉得会极大推动医学领域的发展,无论是分类、检测、分割、合成等。