非线性最小二乘, BA(Bundle Adjustment)
在看高翔博士的《视觉slam十四讲》,把看到的BA相关的东西记录一下,方便自己之后复习,有理解不对的地方,还请指正!
一、非线性最小二乘
1.1 总体思路, 一阶法和二阶法
最小二乘问题  ,我们称F(x)是代价函数, f(x)是误差函数;
,我们称F(x)是代价函数, f(x)是误差函数;
直接求 再比较各个极值点/鞍点的大小一般是比较难的。因此, 一般采取迭代的方法: 即从某个初值x0开始,每一次寻找一个可以使F(x)取得极小值的增量delta_x, 当增量delta_x比较小的时候,我们就认为认为达到了极值。
再比较各个极值点/鞍点的大小一般是比较难的。因此, 一般采取迭代的方法: 即从某个初值x0开始,每一次寻找一个可以使F(x)取得极小值的增量delta_x, 当增量delta_x比较小的时候,我们就认为认为达到了极值。
一阶法寻找delta_x: 将F(x)做一阶泰勒展开: ,并取
,并取 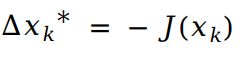 ;这样一定能够保证代价函数值下降,一阶法也叫最速下降法;
;这样一定能够保证代价函数值下降,一阶法也叫最速下降法;
二阶法寻找delta_x: 将F(x)做二阶泰勒展开: 且令
且令 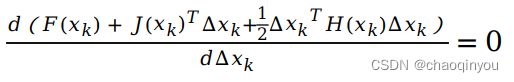 ,可得
,可得![]() , 求解这个线性方程,就可以得到每一步的delta_x, 二阶法也叫做牛顿法; H矩阵不好求,所以经常用高斯牛顿法等近似方法;
, 求解这个线性方程,就可以得到每一步的delta_x, 二阶法也叫做牛顿法; H矩阵不好求,所以经常用高斯牛顿法等近似方法;
1.2 高斯牛顿法
对误差f(x)做泰勒展开: , 每一次迭代时, 优化问题变为:
, 每一次迭代时, 优化问题变为:
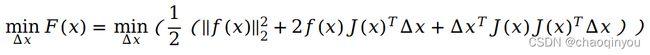
此时, 求增量delta_x,可以 直接令 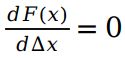 ,得到
,得到  ,求解这个线性方程,就可以得到每一步的delta_x。这里可以认为, 高斯牛顿法用误差函数的Jacobian相乘,近似了牛顿法中的代价函数的Hessian
,求解这个线性方程,就可以得到每一步的delta_x。这里可以认为, 高斯牛顿法用误差函数的Jacobian相乘,近似了牛顿法中的代价函数的Hessian
高斯法的不一定收敛,主要原因是:1)![]() 不一定有逆矩阵, delta_x不太稳定;2)求出的delta_x太大, 导致一阶泰勒近似失效;
不一定有逆矩阵, delta_x不太稳定;2)求出的delta_x太大, 导致一阶泰勒近似失效;
1.3 LM法(Levenberg-Marquart)
LM法在一定程度的缓解了高斯牛顿法的问题,能够提供更加稳定和准确的增量delta_x:1)给增量delta_x增加一个信赖区间,变成一个带约束的优化问题;2)定义一个指标 p 刻画误差函数一阶近似的好坏程度, 并据此动态改变信赖区间的大小。LM具体算法是:
a. 给定初始值x0, 初始优化半径u;
b. 对于每一次迭代, 在高斯牛顿法的基础上增加信赖区间, 求解:
![]()
c. 计算误差函数一阶近似的好坏程度: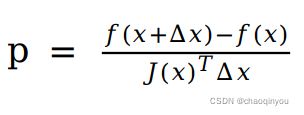
d. 如果p太小, 说明当前位置梯度太大,信赖区间需要保守一些,则设置: u = 0.5u
e. 如果p太大, 说明当前位置梯度比较小, 信赖区间可以激进一些, 则设置: u = 2u
f. 如果p大于某个阈值, 则可以认为近似可行, 可以进行下一次迭代: x_k+1 = x_k+delta_x
g. 判断算法是否收敛;如果没有收敛, 则用 f 中计算得到的x_k+1作为初值, 返回b开始新一轮迭代
b中带约束的优化问题可以用拉格朗日乘数法求解上述 (学过SVM的同学请举手~~):
![]()
其核心仍然是解线性方程: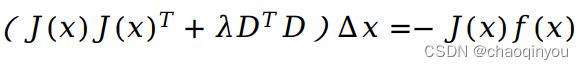 ,当λ较小时,说明二阶近似比较好,基本等效于高斯牛顿法,当λ比较大的时候,说明二阶近似不好,基本等效于一阶法(最速下降法)
,当λ较小时,说明二阶近似比较好,基本等效于高斯牛顿法,当λ比较大的时候,说明二阶近似不好,基本等效于一阶法(最速下降法)
二、特征点法的BA(Bundle Adjustment, 光束法平差)
2.1 误差函数和代价函数
特征点法认为路标点在图片中投影的像素坐标已知, 因此可以最小化重投影误差,来求解相机位姿和路标点位置,具体是:
定义自变量x包含了所有带求解的多帧位姿和多个路标点 ,位姿T在前,路标点p在后;
,位姿T在前,路标点p在后;
定义第j个路标在第i帧的误差函数是: ; 其中
; 其中![]() 代表重投影误差,
代表重投影误差, ![]() 代表第i帧相机位姿;
代表第i帧相机位姿;![]() 代表第j个路标的位置;
代表第j个路标的位置;![]() 代表第j个路标在第i帧中投影的像素坐标;
代表第j个路标在第i帧中投影的像素坐标;
代价函数可以定义为多个路标在多帧中的重投影误差的平方:  。我们要求解的最优化问题定义为:
。我们要求解的最优化问题定义为: , 即求取一组位姿和路标点,使得代价函数最小;
, 即求取一组位姿和路标点,使得代价函数最小;
我们一般用迭代法求解上述最优化问题,因此我们实际关心的是求得每一步迭代时的增量delta_x, 即: , 其中
, 其中 ,
, ![]() 是位姿的增量,
是位姿的增量, ![]() 是地图点的增量;
是地图点的增量;
2.2 获得每次迭代增量delta_x的线性方程
我们对误差函数进行一阶近似:
![]()
其中:  , 是每个误差函数对于x的jacobian;
, 是每个误差函数对于x的jacobian;
令  , 得到关于增量delta_x的线性方程:
, 得到关于增量delta_x的线性方程:
取 就是高斯法, 取
就是高斯法, 取 就是LM法;
就是LM法;
J_ij只与第i帧和第j个路标点有关, 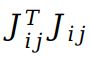 只在ii, ij, ji, jj四块处取值;累加而成的H矩阵因此具有如下的稀疏结构:
只在ii, ij, ji, jj四块处取值;累加而成的H矩阵因此具有如下的稀疏结构:
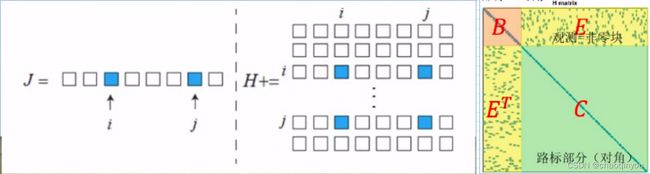 B块只与相机位姿有关,是对角阵; C块只与路标点有关,是对角阵; E块非零的地方表示对应的相机位置有对对应路标点的观测;
B块只与相机位姿有关,是对角阵; C块只与路标点有关,是对角阵; E块非零的地方表示对应的相机位置有对对应路标点的观测;
2.3 边缘化(Schur消元)
增量方程可利用H矩阵的特点快速求解:
对增量方程进行划分: , 并消去地图点增量:
, 并消去地图点增量:
 , 整理得到:
, 整理得到:
可以得到只有位姿的方程: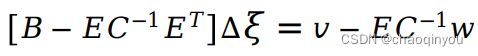 ,C是对角矩阵,C的逆比较好求,这个方程比较好解;
,C是对角矩阵,C的逆比较好求,这个方程比较好解;
再解出路标增量: , 同样利用了C的逆比较好求;
, 同样利用了C的逆比较好求;
以上消元的方法,先固定了路标点增量,求出位姿增量,再求出路标点的增量,从概率论的角度说先求了固定路标点下的条件概率, 再求路标点的边缘概率,因此称为边缘化;
SLAM中的marginalization 和 Schur complement_白巧克力亦唯心的博客-CSDN博客_schur消元