深度聚类算法叙谈
目录
前言
1 基于自标签的协同聚类和表示学习(ICLR, 2020)
1.1 动机
1.2 贡献
1.3 实验分析
1.4 我的想法
2 无标签的图像分类学习 (ECCV, 2020)
2.1 动机
2.2 贡献
2.3 实验分析
2.4 我的想法
3 基于语义伪标签的图像聚类 (arXiv, 2021)
3.1 动机
3.2 贡献
3.3 实验分析
3.4 我的想法
4 对比聚类 (AAAI, 2021)
4.1 动机
4.2 贡献
5 通过分区最大化信度的深度语义聚类 (CVPR, 2020)
5.1 动机
5.2 贡献
参考文献
前言
优惠券网 www.cps3.cn传统的K-means聚类算法,对于维度高、数量级大的数据集不能很好地执行聚类,甚至无法得到有效的聚类效果,在实际场景中难以应用。针对上述问题,2016年Deep Embedding Clustering (DEC)[1]深度聚类算法被提出,从而引领了深度聚类算法研究的热潮。
DEC本质上可以看作是一个自动编码器预训练获取低维的特征表示+无监督学习微调的一个过程。其中,预训练模型的设计和选择对下游聚类任务的性能影响很大(PS:关于DEC的细节,以及前期的相关研究动态,建议参考:深度聚类算法浅谈)。针对该问题,近两年的研究采用了自监督的学习策略,即采用聚类得到的伪标签来指导深度学习网络学习一个更加具有判别性的特征表示,从而摆脱模型对预训练模型的过度依赖。此外,楼主通过已有的论文阅读,发现在深度聚类算法的研究领域,其发展趋势由时间段可以简单地划分为以下三点:
1) 以DEC[1]为代表的预训练+微调的模型
2) 以聚类算法得到伪代码指导深度神经网络进行学习的自监督学习[2] (ECCV, 2018, Deep Cluster)的模型
3) 借助预训练表示聚类获取伪代码,采用设计的交叉熵损失执行自监督聚类选取确定性标签,最后依据确定性标签指导自监督分类器执行半自监督学习[3][4]的模型
此外,在图像领域的深度聚类算法,深度神经网络的模型选择,数据增强策略的选取,都会对下游的聚类任务性能产生较大的影响[5]。如果简单地将深度聚类算法迁移到一般化的数据集上执行聚类,需要结合具体问题做具体的策略优化,否则其聚类性能并不能胜任K-means。
本文主要记录自己最近阅读的五篇有关深度聚类文章,每篇文章都有提供源码,如有同学感兴趣, 可以自行去下载相关源码分析。
1 基于自标签的协同聚类和表示学习(ICLR, 2020)
原文链接
代码
文章审稿打分:3分(Weak Reject),8分(Accept),8分(Accept)
文章审稿意见
1.1 动机
基于深度神经网络的聚类和表示学习是当前的主流方法。然而,简单地联合聚类和表示学习会导致最终产生退化的结果。
本文研究的基础主要是2018年发表在ECCV上的Deep Cluster模型[2]。该模型最小化分类交叉熵并结合K-means算法提供的伪标签进行联合表示和聚类,然而该过程由于K-means提供的伪标签存在较多错误标签的问题,会导致模型最终产生一个退化的解决方案,并且很多数据点容易被划分到同一个簇中。
1.2 贡献
为了解决简单地采用联合聚类和表示学习导致下游任务性能退化的问题,本文提出了最大化标签和输入数据指引之间信息的方法(下面给给出论文的理论证明和说明)。该方法的主要贡献:
1) 证明了将最大化标签和输入数据指引之间信息引入到标准交叉熵最小化问题中,可以被视为一个最优运输问题,并且能够在百万级图像数据中高效地运行;
2) 与ECCV2018文章中单独最小化交叉熵相比,本文通过最大化标签和输入数据指引之间信息,能够避免下游任务产生退化解;
3) 相比ECCV2018同时执行无监督分类和K-means聚类, 导致没有一个明确定义的优化目标,本文方法通过同时优化自标签和交叉熵损失为下游任务服务,能够保证模型收敛到(局部)最优解。
该方法本质是采用最优运输来实现伪标签的提取(PS:而ECCV2018则是采用K-means对学习的表示执行聚类获取伪标签),并结合标准的交叉熵损失函数指导深度神经网络实现对原始图像数据的表示学习。
关于最优运输理论的介绍建议参考:最优运输(Optimal Transfort):从理论到填补的应用
自监督学习的标签概率,以及其最小化的交叉熵损失函数定义如下:

然而,在完全无监督的情况下,采用公式(1)容易导致退化的解决方案,其容易将所有数据点分配给单个或者任意的标签进行最小化处理。为了解决该问题,本条提出对伪标签采用一个后验分布q设定,并且为了避免在优化q的过程中出现退化的解决方案,对伪标签进行了依据簇个数和样本总数进行平均初始化的约束处理,具体公式和定义如下:

交叉熵损失结合伪标签的后验分布q执行优化时,很难进行算法的优化处理。然而,该问题可以被视为一个最优运输问题,并且能够被高效地解决。拟定的标签伪分布Q,和模型执行无监督分类得到的预测结果P,我们的目标是使之无限接近,那么在这样的情形下可以将其视为一个最优运输问题(PS:这里的思想,有点类似DEC微调中的P和Q的分布处理)。本文通过最优运输理论,对两个分布P和Q的定义与推导,将上述公式3可以转为以下公式5和6,从而变为一个纯粹的最优运输问题:

对于公式(5)的推导,细节可以看下图的转换:
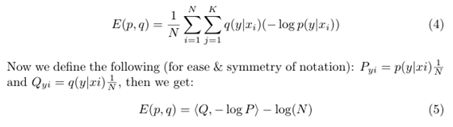
最优运输问题的解可以视为一个线性规划问题,也可以在多项式时间内被解决。然而,本文的实验对象达到了百万计的图像数据集。针对该问题,本文参考NIPS2013年提出的熵正则化思想,采用了一种快速的Sinkhorn-Knopp算法,从而来求取合理的后验伪标签分布Q。结合最优运输求取Q的问题定义如下:

通过以上的公式推导,本文通过把定义的后验分布Q和backbone学习的交叉熵中的预测分布P联合一起的策略,从而达到表示学习和自标签优化的同步过程。具体步骤如下:

对上述的公式进行进一步的推导,可以得出以下结论:最大化标签和输入数据指引之间信息。

![]()
与单独最小化熵相比,最大化信息避免了退化解,因为后者在标签y和索引i之间没有互信息。
另外,本文的主要目标是使用聚类来学习良好的数据表示Φ,所以本文还考虑一个多任务设置,其中相同的表示在几个不同的聚类任务之间共享,这可能会捕获不同的和互补的聚类轴。
1.3 实验分析
本文模型的主要目的是采用聚类的手段学习一个更好的数据表示,但是其最终的下游任务并不一定是用于做聚类。由于本篇博客探讨和分析聚类问题,所以此处只放出文章中做聚类的无监督分类结果,具体实验结果如下:
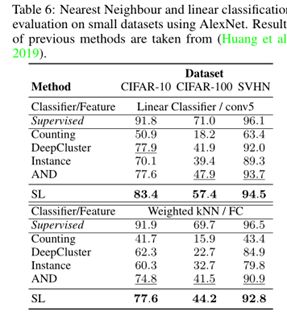

由上述的实验结果,本文提出采用最优运输实现对定义的伪标签分布Q和交叉熵损失中P进行优化,其在聚类性能上药明显优于K-means。
1.4 我的想法
本文最大的亮点在于把拟定的伪标签分布Q和最小化无监督分类交叉熵结合了起来,并证明其为一个基本的最优运输问题,这为深度聚类方向提供一个新的思考方向。另外,通过本文的处理,能够有效解决简单地采用K-means算法提供的伪标签指导深度神经网络执行自监督分类容易导致下游任务出现退化解的问题。
2 无标签的图像分类学习 (ECCV, 2020)
原文链接
代码
2.1 动机
在有监督分类任务中,通过真实标签能够指导CNN等backbone学习到更加具有判别性的表示。然而,在现实场景中存在大量无标记的数据。那么,我们能否在没有真实标签的情况下,依据图像的语义信息进行自动分组呢?
同时,当前已有的基于端到端的深度聚类算法,通常采用预训练+微调的思想。然而,这些方法难以避免在微调过程中受到低质量特征的影响,容易出现不平衡的簇,导致最终出现次优的聚类结果。
2.2 贡献
为了解决当前端到端深度聚类算法容易出现次优结果的问题,本文提出了一种两步法的无监督图像分类算法。该方法利用了表示方法和端到端学习方法的优点,同时也解决了它们的缺点:
1) 采用一个自监督的pretext任务来获取一个有意义的语义特征,并基于特征相似性挖掘每幅图像的最近邻,使得提取的语义特征更加适合语义聚类。相比之下,表征学习方法要求在学习特征表示后进行K-means聚类,这被认为会导致聚类退化。
2) 采用质量高的特征来指导聚类的学习,通过这样处理,能够使得聚类过程中避免基于低质量特征来只需聚类,而这样的问题是在end-to-end方法中常见的问题。
3) 另外,本文定义一种基于软标签分配的交叉熵损失函数,本文将其称为SCAN-loss,能够有效地对每幅图像及其邻居数据进行分类,从而使得网络能够产生一致或者具有辨别性的预测结果。
SCAN-loss的定义如下:

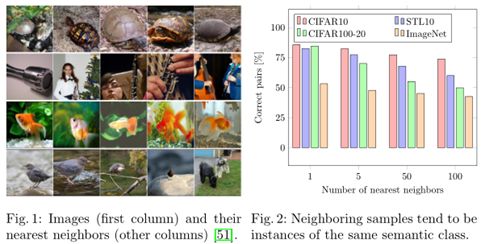
其中X表示数据集中的样本,k表示该样本的最近邻集合中的样本。上述公式第二项的目的是为了避免Φη将所有样本分配给单个集群。如果概率分布在集群C中是提前知道的,该项就可以被KL-divergence所替代。关于最近邻的示例如下图所示:
本文的算法主要分为三个步骤:
1) 采用一个pretext任务,寻找对于数据的最近邻
2) 依据最近邻,结合SCAN-loss执行聚类
3) 采用聚类获取的伪标签,选取确定性或者可信度较高的标签执行自监督学习,从而进一步提高最终的聚类效果
具体算法的伪代码如下:

2.3 实验分析
采用K-means对原始的预训练表示执行聚类,会出现簇中心不稳定的情况,表1的实验结果可以反映出该假设:聚类的ACC标准差最大,并且为5.7。
另外,可以发现,通过采用SimCLR数据增强手段并结合SCAN-Loss能够有效提高聚类效果。此外,虽然SCAN-Loss在某些方面和K-means有较大关联,比如都是采用预训练后得到的特征执行聚类。但是,本文提出的SCAN-Loss能够避免聚类退化,即聚类可能会很不稳定的问题,如果采用K-means的簇中心进行初始化就会导致该问题。另外,本文还探讨了在训练过程中,采用不同的增强策略执行聚类的效果,实验结果表明,采用RA执行样本增强,能够有效提高聚类的效果,最高可以达到87.6的ACC。另外,通过伪标签来对聚类结果进行微调,能够有效地进一步提高最终的聚类效果。此外,本文通过图6表明,伪标签指导的自训练过程对设定的阈值参数不敏感,图7可以最近邻K设定为5即可达到较稳定的准确率。

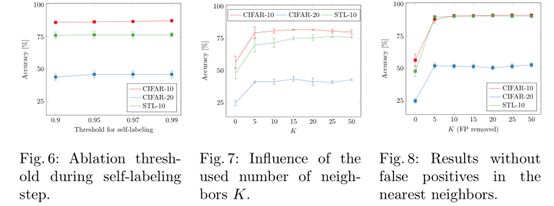
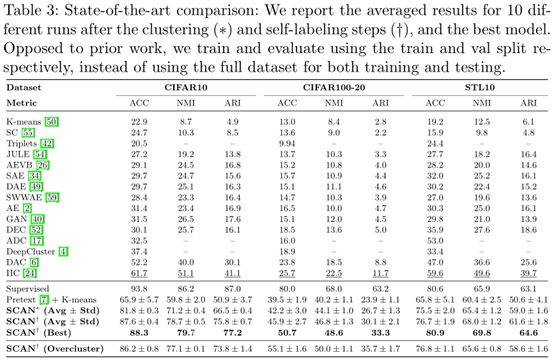
此外,本文将簇的个数设定为20而不是10的时候,本文的聚类准确率仍然较高,体现出了本文聚类算法模型的稳定性。即证明了一点:本文的聚类算法模型并不需要以来原始聚类簇个数的真实信息。本文算法在CIFAR100-20采用过于聚类的簇个数,其性能提高的一个原因在于高的类内方差。(关于超类的聚类性能评价,是一个多对一的映射,其计算的细节,本文有单独考虑和处理)
本文采用两部法:预训练+聚类+伪标签执行自监督训练,的两阶段方法,与当前的SOTA的端到端方法不一样。
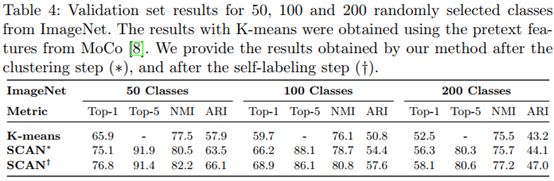
上表的结果表明,采用SCAN-loss执行聚类,其在图像上面的聚类效果要明显优于采用K-means执行聚类的结果。此外,通过Self-label的自监督学习能够进一步提高最终的聚类效果。
2.4 我的想法
本文最大的亮点在于没有一味地追求端到端的深度聚类模型,并指出了当前的端到端深度聚类模型存在无法摆脱低质量特征依赖导致最终容易出现次优结果的问题。针对上述问题,本文通过最近邻的思想提出了SCAN-loss执行聚类,能够有效避免直接采用K-means执行聚类导致最终出现退化解的问题。此外,通过添加Self-Labeling的自监督学习步骤,对聚类步骤中的自监督分类器执行进一步的学习优化,能够有效提高最终的聚类效果。
3 基于语义伪标签的图像聚类 (arXiv, 2021)
原文链接
代码
3.1 动机
上述SCAN聚类算法中采用样本的最近邻来计算SCAN-loss存在以下问题:在实际的样本空间中,并不是所有样本的最近邻都具有相同的语义,比如当样本位于不同簇的边界时,这样的问题会变得更加严重,从而导致最终的聚类结果产生误差累积。具体的局部样本空间的语义不一致可以参考下图:

此外,SCAN算法的性能随着交替的运行,导致边界的最近邻样本在聚类的交替过程中产生误差累积的问题,并且其在大型数据的在线聚类过程中会受到性能的限制。
3.2 贡献
针对SCAN算法容易出现语义不一致的最近邻样本,导致聚类结果产生误差累积的问题,本文提出了一种基于图像语义伪标签的图像聚类框架(SPICE)。该框架的主要贡献如下:
1) 设计了一种级联softmax交叉熵损失函数,能够有效增强模型选取伪标签的可信度,从而提高模型的聚类性能;
2) 结合图像的弱增强和强增强处理,结合分类交叉熵损失函数来训练分类网络,并通过伪标签来协调样本语义在聚类过程中的差异以及实例样本之间的相似性;
3) 设计了一种伪标签获取方法,在网络模型的训练过程中能够利用语义相似度度量来减少样本在边界附近的语义不一致性;
4) 设计的局部一致性原则通过将原聚类问题转化为半监督学习范式,能够有效减少语义的不一致性,从而提高最终的聚类性能。

拟议的SPICE框架包括三个培训阶段。
首先,训练了一个无监督的表征学习模型,该模型是在SCAN中使用的;
然后,冻结预训练模型的CNN主干,分别进行SPICE-Self和SPICE-Semi两个阶段提取嵌入特征,如上图所示。
SPICE-Self有三个分支:第一个分支以原始图像为输入输出嵌入特征,第二个分支以弱变换图像为输入输出语义标签,第三个分支以强变换图像为输入预测聚类标签。给定前两个分支的结果,基于语义相似度的伪标记算法生成伪标记来监督第三个分支。在实践中,SPICE-Self只需要训练第三分支的轻量级分类头。
SPICE-Semi首先判断一组可靠的基于本地语义一致性伪标签,比如SPICE-Self得到的聚类结果, 然后采用半监督学习重新训练分类模型cls Model。
最后,训练后的分类模型能够预测含标签图像和不含标签图像样本的聚类标签。
相比SCAN简单地选取每个样本的最近邻语义样本处理方法,本文提出在一个batchsize里面选取其中大于给定阈值的最自信的前i个样本作为伪标签。其处理原理如下:


注意,在不同的集群之间可能存在重叠的样本(PS:具体可以见上图的c中的toy example),所以有两种方法来处理这些标签:
1) 一个是重叠分配,一个样本可能有一个以上的类标签,如图中黄色和红色的圆圈所示。
2) 另一种是非重叠分配,即所有样本只有一个簇标签,如盘子红色圆圈所示。
本文实验表明,如第4.5.2小节所分析,发现重叠赋值更好。
本文提出的级联softmax交叉熵损失函数其出发点是鼓励模型输出有信心的预测,从而有助于对未标记的数据学习,具体定义如下:

这个级联softmax交叉熵损失函数的定义和第一篇ICLR中定义的后验分布P结合交叉熵损失函数的公式很像,具体区别待探究(PS:本文并没有应用和分析第一篇ICLR2020文章)。
此外,本文通过选取局部中部分可靠的伪标签样本的最近邻,来缓解局部样本语义不一致的问题。其中局部一致性的定义如下:

在半自监督的学习模型中,采用SPICE-self步骤中获取的可信度高的伪标签,结合未提供伪标签的数据进行半监督学习,并结合数据增强和分类交叉熵损失函数,实现对clshead的学习。其中采用的半监督交叉熵损失函数定义如下:

3.3 实验分析
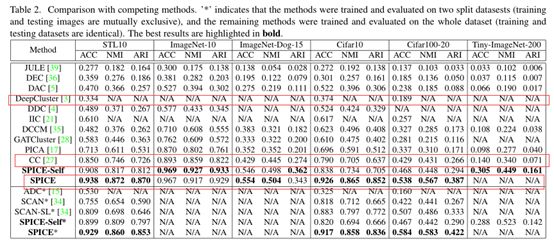
通过上述的实验结果可以发现,本文结合确定性高的最近邻样本选取策略以及半自监督学习策略,可以有效提高模型的聚类效果,能够比SCAN聚类方法高大约20%,比最新的AAAI2021文章的CC模型高10%。
3.4 我的想法
本文是arXiv上发布的最新论文,目前应该还没有被相关会议或者期刊接收。本文主要是解决SCAN算法中最近邻样本容易出现不一致语义的问题,并且在实验效果上要比SCAN算法强很多。然而,本文的写作不是很清晰,特别是摘要的写作感觉有点长,关键的问题分析有点模糊不清,特别是创新点的表述不清晰。此外,本文的模型看上去好复杂,具体的可移植性待探究。
最后,本文的确定性标签的选择思路可以参考和借鉴,另外其级联softmax交叉熵损失函数可以借鉴和学习。
4 对比聚类 (AAAI, 2021)
原文
代码
4.1 动机
Deep Cluster (ECCV, 2018)采用K-means对每次epoch结束后的表述执行聚类,然后利用聚类得到的伪标签来指导深度神经网络的参数更新。这种交替学习方法会在表示学习和聚类之间的交替过程中积累误差,导致聚类性能次优。此外,上述方法只能处理离线任务,即聚类是基于整个数据集的,这限制了它们在大规模在线学习场景中的应用。
4.2 贡献
针对Deep Cluster模型交替优化导致聚类性能次优的问题,本文提出了名为对比聚类(CC)的单阶段在线聚类方法,它明确地执行实例级和集群级的对比学习。具体地说,对于给定的数据集,通过数据扩充来构造正实例对和负实例对,然后投影到特征空间中。通过同时优化实例级和集群级的对比损失,该模型以端到端方式联合学习表示和集群分配。本文的具体贡献可以分为以下三点:
1) 我们为当前的深度聚类研究提供了一种新的见解,即实例表示和聚类类别预测分别对应于可学习特征矩阵的行和列。因此,深度聚类可以优雅地统一到表示学习的框架中;
2) 据我们所知,这可能是聚类特定对比学习的第一个工作。与现有的对比学习研究不同,本文提出的方法不仅在实例层次上进行对比学习,而且在聚类层次上进行对比学习。实验证明,这种双重对比学习框架可以产生聚类偏好表征;
3) 该模型采用单阶段、端到端方式,只需要批量优化,可应用于大规模在线场景。
本文的模型的对比思想如下图1所示:

本文模型的整体架构图如下:

实例级的对比损失计算原理如下:

聚类层次的对比损失计算方式和实例级差不多,区别在于把行数据换成了列数据,并添加了熵偏项策略,具体细节可以参考原文。
个人思考:本文最大参考价值在于说明了在深度聚类研究领域,图像的数据增强和获取表示的backbone对下游的聚类任务性能会有很大的影响。此外,对比学习首次应用到深度聚类领域,也说明了对比学习思想在积极交替优化聚类模型中能够有效缓解误差累积的问题。
5 通过分区最大化信度的深度语义聚类 (CVPR, 2020)
原文
代码
5.1 动机
现有的深度聚类方法通常依赖于基于样本间关系或自估计伪标记的局部学习约束方法,
这不可避免地受到的分布在邻域的误差影响,并在训练过程中产生误差传播的累积问题。虽然使用可学习表示进行聚类分析可能有利于对无标记数据进行聚类,但如何提高这些聚类的语义合理性仍然是一个挑战(PS:此处的动机和第三篇arXiv2021的动机类似,但是本文是2020年发表,另外发现arXiv2021文章引用了该篇文章,并且在实验中重点对比了该文提出的模型)。具体的领域误差问题如下图:
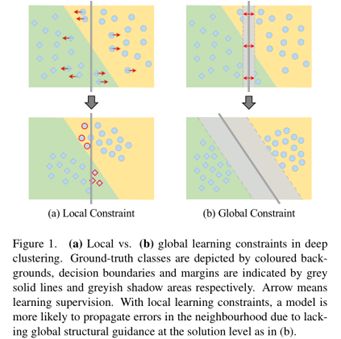
如上图所示,DEC这些方法面临着训练过程中由于邻域估计不一致而导致的更严重的误差传播累积问题。此外,由于训练监督和聚类目标之间的模糊联系,当缺乏全局解决方案级指导时,这类方法往往产生语义上不太可信的聚类解决方案。
5.2 贡献
为了避免领域不确定性导致聚类的误差累积问题,引入了一种新的深度聚类方法,称为分区置信度最大化(PICA),通过从所有可能的簇分离方案中学习最可靠的聚类方案来解决这个问题。本文的贡献主要分为以下三点:
1) 提出了通过最大分割置信来学习语义上最合理的聚类解的思想,将经典的最大边际聚类思想扩展到深度学习范式。该方法对局部样本间关系和聚类簇结果作为标记没有很强的假设,这通常会导致误差传播和次优的聚类解。
2) 引入了一种新的深度聚类方法,称为分区置信度最大化(PICA)。PICA是建立在一个新引入的划分不确定性指标的基础上,该指标设计得很优雅,可以量化聚类解决方案的全局置信度。
3)引入分割不确定性指数的随机近似,将其与目标图像的整个集合解耦,从而可以方便地采用标准的小批量模型训练。
本文的模型如下图:

理想情况下,集群的所有样本将共享相同的目标类标签。也就是说,本文模型的目标是直接从原始数据样本中发现潜在的语义类决策边界(PS:即簇中心)。
另外,在聚类中,通常出现将大部分样本分配到少数的聚类中。为了避免这种情况,本文引入了一个额外的约束,使簇大小分布的负熵最小化。该策略本人在好几篇文章中都有看到这样的处理机制,应该可以作为聚类优化挑战的一个策略。具体的负熵最小化的策略如下:

个人思考:本文采用余弦相似度计算ASV和PUI的代码和思想,以及其在聚类过程中的应用可以借鉴和学习。另外,可以尝试采用本文的思想,结合采用余弦相似度来衡量和计算的思路,去思考如何选取确定性较大的标签。另外,本文的写作真的是有点费解,并且摘要写的太过专业具体化,很难让读者看懂。
参考文献
[1] J. Xie, R. Girshick, and A. Farhadi, “Unsupervised Deep Embedding for Clustering Analysis,” arXiv:1511.06335 [cs], May 2016, Accessed: May 18, 2021. [Online]. Available: http://arxiv.org/abs/1511.06335
[2] M. Caron, P. Bojanowski, A. Joulin, and M. Douze, “Deep Clustering for Unsupervised Learning of Visual Features,” arXiv:1807.05520 [cs], Mar. 2019, Accessed: May 18, 2021. [Online]. Available: http://arxiv.org/abs/1807.05520
[3] W. Van Gansbeke, S. Vandenhende, S. Georgoulis, M. Proesmans, and L. Van Gool, “SCAN: Learning to Classify Images without Labels,” arXiv:2005.12320 [cs], Jul. 2020, Accessed: May 16, 2021. [Online]. Available: http://arxiv.org/abs/2005.12320
[4] C. Niu and G. Wang, “SPICE: Semantic Pseudo-labeling for Image Clustering,” arXiv:2103.09382 [cs], Mar. 2021, Accessed: May 16, 2021. [Online]. Available: http://arxiv.org/abs/2103.09382
[5] Y. Li, P. Hu, Z. Liu, D. Peng, J. T. Zhou, and X. Peng, “Contrastive Clustering,” arXiv:2009.09687 [cs, stat], Sep. 2020, Accessed: May 16, 2021. [Online]. Available: http://arxiv.org/abs/2009.09687