YOLOv5 - 游戏本 GTX1070 和 RTX3070 的 AI 性能对比
目录
一、YOLOv5四个模型效果
二、GTX1070 和 RTX3070显卡参数对比
三、GTX1070,HP OMEN Laptop 17-an0xx
1. weights yolov5s.pt
2. 从摄像头采集图像
3. weights yolov5m.pt
4. Train性能
四、RTX3070,ASUS 天选 AIR
1. weights yolov5s.pt
2. weights yolov5m.pt
3. 查看显卡信息
4. 安装CUDA11.2后查看显卡信息
5. Train性能
6. RTX3070性能显示
五、小结
游戏本是做AI学习、训练的一个不错的选择,既可以名正言顺的买来作为生产力工具,也可以顺便玩玩游戏。RTX30系列的显卡一度抢购中,被誉为空气卡,笑称:看得见,买不着!
比起动辄上万的显卡和一万好几的游戏本,华硕天选系列是一款性价比不错的游戏本。春节的时候抢购了一台。
既然作为生产力工具,就要测试一下AI的性能,拿目前比较火的YOLOv5为例,顺便拿几年前的HP OMEN 17游戏本做一个参照。
一、YOLOv5四个模型效果
yolov5按大小分为四个模型yolov5s、yolov5m、yolov5l、yolov5x,这四个模型的表现见下图:
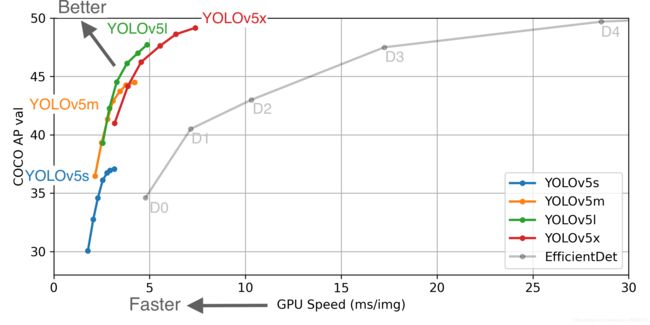
上图为基于5000张COCO val2017图像进行推理时,每张图像的平均端到端时间,batch size = 32, GPU:Tesla V100(计算能力7.0,拥有 640个Tensor Cores 和 5120个CUDA核心,16GB HBM2以及15TFLOPS的单精度性能),这个时间包括图像预处理,FP16推理,后处理和NMS(非极大值抑制)。 EfficientDet的数据是从 google/automl 仓库得到的(batch size = 8)。
| Model | size | APval | APtest | AP50 | SpeedV100 | FPSV100 | params | GFLOPS |
|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 640 | 36.8 | 36.8 | 55.6 | 2.2ms | 455 | 7.3M | 17.0 |
| YOLOv5m | 640 | 44.5 | 44.5 | 63.1 | 2.9ms | 345 | 21.4M | 51.3 |
| YOLOv5l | 640 | 48.1 | 48.1 | 66.4 | 3.8ms | 264 | 47.0M | 115.4 |
| YOLOv5x | 640 | 50.1 | 50.1 | 68.7 | 6.0ms | 167 | 87.7M | 218.8 |
| YOLOv5x + TTA | 832 | 51.9 | 51.9 | 69.6 | 24.9ms | 40 | 87.7M | 1005.3 |
二、GTX1070 和 RTX3070显卡参数对比
RTX3070的计算能力是8.6,使用目前最新版的GPU-Z 2.37.0版本,才能正确识别RTX3070的Laptop GPU。
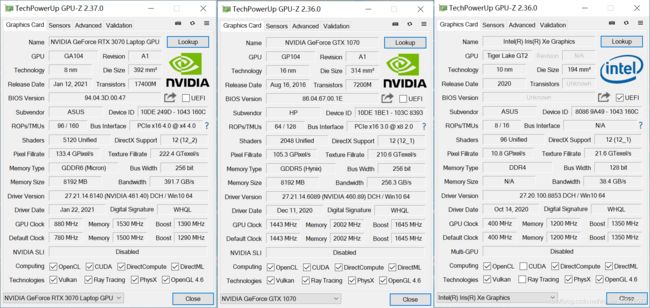
从CUDA核心数来看,ASUS 天选 air 的 RTX3070 Laptop GPU是5120个CUDA核,HP OMEN 17 的 GTX1070并不是Laptop 版本,应该是标准版,是2048核心,RTX3070采用新一代 Ampere 构架,RTX3070的性能应该至少在GTX1070的两倍以上,但是,考虑到GPU的运行频率、所用显存的频率,以及厂家对散热的处理和功率的限制等,性能会有较大出入。
Intel 11代酷睿的集成 Iris Xe 显卡有96个EU,全新的EU集成了8-wide FP/INT ALU8和2-wide extended math ALU。相当于96 * 8=768 个CUDA核心? 从核心数目上来说,跟GeForce MX 350 的 768 个CUDA 核心一样多, 比GeForce MX 450 的 896 个CUDA 核心少。(感觉GPU-Z的数据有点低,不确定是不是新出的GPU还不认识?)
Tflops理论峰值
单精度理论峰值= GPU芯片数量*GPU Boost主频*核心数量*单个时钟周期内能处理的浮点计算次数,
单精度理论峰值 = FP32 cores * GPU Boost Clock * 2
Intel 11代酷睿 Iris Xe: 96 * 8 * 1.35GHz * 2 = 2.07 TFlops ?
GeForce MX 450: 896 * 1.575GHz * 2 = 2.8 TFlops
GeForce GTX 1070: 2048 * 1.645GHz * 2 = 6.7 TFlops(惠普OMEN)
GeForce RTX 3060: 3840 * 1.525GHz * 2 = 11.7 TFlops(ASUS天选air,8499元)
GeForce RTX 3070: 5120 * 1.390GHz * 2 = 14.2 TFlops(ASUS天选air,9999元)
详细一点的对比,请参看链接:
RTX30系列游戏本与台式机、云服务器显卡AI计算力对比
三、GTX1070,HP OMEN Laptop 17-an0xx,17寸,3.5Kg,
1. weights yolov5s.pt
(yolov5) C:\yolo\yolov5>python detect.py --source data/images --weights weights/yolov5s.pt --conf 0.25
Namespace(agnostic_nms=False, augment=False, classes=None, conf_thres=0.25, device='', exist_ok=False, img_size=640, iou_thres=0.45, name='exp', project='runs/detect', save_conf=False, save_txt=False, source='data/images', update=False, view_img=False, weights=['weights/yolov5s.pt'])
Using torch 1.7.0+cu101 CUDA:0 (GeForce GTX 1070, 8192.0MB)
Fusing layers...
Model Summary: 224 layers, 7266973 parameters, 0 gradients, 17.0 GFLOPS
image 1/3 C:\yolo\yolov5\data\images\bus.jpg: 640x480 4 persons, 1 buss, Done. (0.014s)
image 2/3 C:\yolo\yolov5\data\images\gj.jpg: 480x640 Done. (0.010s)
image 3/3 C:\yolo\yolov5\data\images\zidane.jpg: 384x640 2 persons, 1 ties, Done. (0.010s)
Results saved to runs\detect\exp4
Done. (0.345s)
图1: bus.jpg

图2:zidane.jpg
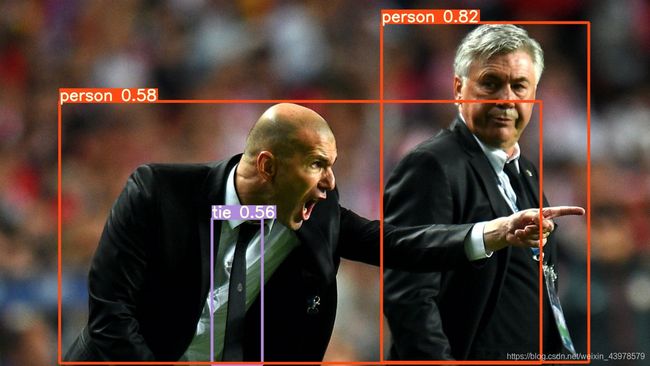
2. 从摄像头采集图像
(yolov5) C:\yolo\yolov5>python detect.py --source 0 --weights weights/yolov5s.pt --conf 0.25
Namespace(agnostic_nms=False, augment=False, classes=None, conf_thres=0.25, device='', exist_ok=False, img_size=640, iou_thres=0.45, name='exp', project='runs/detect', save_conf=False, save_txt=False, source='0', update=False, view_img=False, weights=['weights/yolov5s.pt'])
Using torch 1.7.0+cu101 CUDA:0 (GeForce GTX 1070, 8192.0MB)
Fusing layers...
Model Summary: 224 layers, 7266973 parameters, 0 gradients, 17.0 GFLOPS
1/1: 0... success (640x480 at 30.00 FPS).
0: 480x640 1 persons, Done. (0.585s)
0: 480x640 1 persons, Done. (0.016s)
0: 480x640 1 persons, Done. (0.010s)
3. weights yolov5m.pt
(yolov5) C:\yolo\yolov5>python detect.py --source data/images --weights weights/yolov5m.pt --conf 0.25
Namespace(agnostic_nms=False, augment=False, classes=None, conf_thres=0.25, device='', exist_ok=False, img_size=640, iou_thres=0.45, name='exp', project='runs/detect', save_conf=False, save_txt=False, source='data/images', update=False, view_img=False, weights=['weights/yolov5m.pt'])
Using torch 1.7.0+cu101 CUDA:0 (GeForce GTX 1070, 8192.0MB)
Fusing layers...
Model Summary: 308 layers, 21356877 parameters, 0 gradients, 51.3 GFLOPS
image 1/3 C:\yolo\yolov5\data\images\bus.jpg: 640x480 4 persons, 1 buss, Done. (0.023s)
image 2/3 C:\yolo\yolov5\data\images\gj.jpg: 480x640 Done. (0.019s)
image 3/3 C:\yolo\yolov5\data\images\zidane.jpg: 384x640 2 persons, 1 ties, Done. (0.017s)
Results saved to runs\detect\exp7
Done. (0.375s)
4. Train性能
(yolov5) C:\yolo\yolov5>python train.py --img 640 --batch 1 --epochs 16 --data data/coco128.yaml --weights weights/yolov5s.pt --nosave --cache
Using torch 1.7.0+cu101 CUDA:0 (GeForce GTX 1070, 8192.0MB)
Optimizer stripped from runs\train\exp13\weights\last.pt, 14.8MB
Optimizer stripped from runs\train\exp13\weights\best.pt, 14.8MB
16 epochs completed in 0.088 hours.
(yolov5) C:\yolo\yolov5>python train.py --img 640 --batch 2 --epochs 16 --data data/coco128.yaml --weights weights/yolov5s.pt --nosave --cache
Using torch 1.7.0+cu101 CUDA:0 (GeForce GTX 1070, 8192.0MB)
Optimizer stripped from runs\train\exp15\weights\last.pt, 14.8MB
16 epochs completed in 0.050 hours.
--batch 3 以上会报错(显存不够?),所以只能测试--batch 2 以下。
四、RTX3070,ASUS 天选 AIR,15.6寸,2.1Kg
1. weights yolov5s.pt
(yolov5) C:\yolo\yolov5>python detect.py --source data/images --weights weights/yolov5s.pt --conf 0.25
Namespace(agnostic_nms=False, augment=False, classes=None, conf_thres=0.25, device='', exist_ok=False, img_size=640, iou_thres=0.45, name='exp', project='runs/detect', save_conf=False, save_txt=False, source='data/images', update=False, view_img=False, weights=['weights/yolov5s.pt'])
YOLOv5 torch 1.7.1 CUDA:0 (GeForce RTX 3070 Laptop GPU, 8192.0MB)
Fusing layers...
Model Summary: 224 layers, 7266973 parameters, 0 gradients, 17.0 GFLOPS
image 1/3 C:\yolo\yolov5\data\images\bus.jpg: 640x480 4 persons, 1 bus, Done. (0.036s)
image 2/3 C:\yolo\yolov5\data\images\gj.jpg: 480x640 Done. (0.018s)
image 3/3 C:\yolo\yolov5\data\images\zidane.jpg: 384x640 2 persons, 1 tie, Done. (0.014s)
Results saved to runs\detect\exp24
Done. (0.291s)
2. weights yolov5m.pt
(yolov5) C:\yolo\yolov5>python detect.py --source data/images --weights weights/yolov5m.pt --conf 0.25
Namespace(agnostic_nms=False, augment=False, classes=None, conf_thres=0.25, device='', exist_ok=False, img_size=640, iou_thres=0.45, name='exp', project='runs/detect', save_conf=False, save_txt=False, source='data/images', update=False, view_img=False, weights=['weights/yolov5m.pt'])
YOLOv5 torch 1.7.1 CUDA:0 (GeForce RTX 3070 Laptop GPU, 8192.0MB)
Fusing layers...
Model Summary: 308 layers, 21356877 parameters, 0 gradients, 51.3 GFLOPS
image 1/3 C:\yolo\yolov5\data\images\bus.jpg: 640x480 4 persons, 1 bus, Done. (0.031s)
image 2/3 C:\yolo\yolov5\data\images\gj.jpg: 480x640 Done. (0.016s)
image 3/3 C:\yolo\yolov5\data\images\zidane.jpg: 384x640 2 persons, 1 tie, Done. (0.016s)
Results saved to runs\detect\exp25
Done. (0.234s)
3. 查看显卡信息
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.0\bin\win64\Release>deviceQuery.exe
deviceQuery.exe Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce RTX 3070 Laptop GPU"
CUDA Driver Version / Runtime Version 11.2 / 11.0
CUDA Capability Major/Minor version number: 8.6
Total amount of global memory: 8192 MBytes (8589934592 bytes)
MapSMtoCores for SM 8.6 is undefined. Default to use 64 Cores/SM
MapSMtoCores for SM 8.6 is undefined. Default to use 64 Cores/SM
(40) Multiprocessors, ( 64) CUDA Cores/MP: 2560 CUDA Cores
GPU Max Clock rate: 1290 MHz (1.29 GHz)
Memory Clock rate: 6001 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 4194304 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1536
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 5 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
CUDA Device Driver Mode (TCC or WDDM): WDDM (Windows Display Driver Model)
Device supports Unified Addressing (UVA): Yes
Device supports Managed Memory: Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.2, CUDA Runtime Version = 11.0, NumDevs = 1
Result = PASS
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.0\bin\win64\Release>bandwidthTest.exe
[CUDA Bandwidth Test] - Starting...
Running on...
Device 0: GeForce RTX 3070 Laptop GPU
Quick Mode
Host to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(GB/s)
32000000 5.9
Device to Host Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(GB/s)
32000000 6.6
Device to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(GB/s)
32000000 356.8
Result = PASS
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
4. 安装CUDA11.2后查看显卡信息
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.2\bin\win64\Release>deviceQuery.exe
deviceQuery.exe Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce RTX 3070 Laptop GPU"
CUDA Driver Version / Runtime Version 11.2 / 11.2
CUDA Capability Major/Minor version number: 8.6
Total amount of global memory: 8192 MBytes (8589934592 bytes)
(40) Multiprocessors, (128) CUDA Cores/MP: 5120 CUDA Cores
GPU Max Clock rate: 1290 MHz (1.29 GHz)
Memory Clock rate: 6001 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 4194304 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total shared memory per multiprocessor: 102400 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1536
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 5 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
CUDA Device Driver Mode (TCC or WDDM): WDDM (Windows Display Driver Model)
Device supports Unified Addressing (UVA): Yes
Device supports Managed Memory: Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.2, CUDA Runtime Version = 11.2, NumDevs = 1
Result = PASS
5. Train性能
(yolov5) C:\yolo\yolov5>python train.py --img 640 --batch 1 --epochs 16 --data data/coco128.yaml --weights weights/yolov5s.pt --nosave --cache
github: skipping check (not a git repository)
YOLOv5 torch 1.7.1 CUDA:0 (GeForce RTX 3070 Laptop GPU, 8192.0MB)
Optimizer stripped from runs\train\exp24\weights\last.pt, 14.8MB
Optimizer stripped from runs\train\exp24\weights\best.pt, 14.8MB
16 epochs completed in 0.050 hours.
(yolov5) C:\yolo\yolov5>python train.py --img 640 --batch 2 --epochs 16 --data data/coco128.yaml --weights weights/yolov5s.pt --nosave --cache
github: skipping check (not a git repository)
YOLOv5 torch 1.7.1 CUDA:0 (GeForce RTX 3070 Laptop GPU, 8192.0MB)
Optimizer stripped from runs\train\exp27\weights\last.pt, 14.8MB
Optimizer stripped from runs\train\exp27\weights\best.pt, 14.8MB
16 epochs completed in 0.029 hours.
(yolov5) C:\yolo\yolov5>python train.py --img 640 --batch 6 --epochs 16 --data data/coco128.yaml --weights weights/yolov5s.pt --nosave --cache
github: skipping check (not a git repository)
YOLOv5 torch 1.7.1 CUDA:0 (GeForce RTX 3070 Laptop GPU, 8192.0MB)
Optimizer stripped from runs\train\exp26\weights\last.pt, 14.8MB
16 epochs completed in 0.025 hours.
--batch 7 以上会报错(显存不够?),所以只能测试--batch 6 以下。
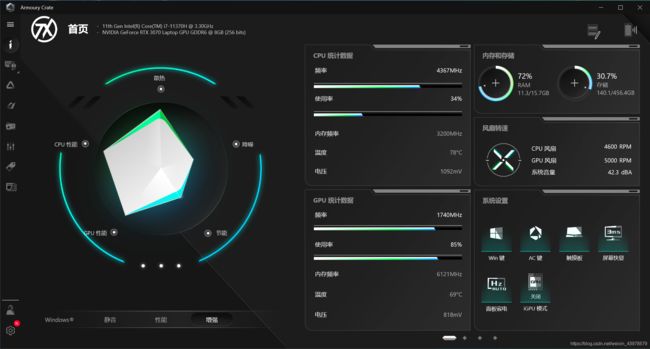
6. RTX3070性能显示
将显卡的性能调整为“增强”模式,以期发挥RTX的最大性能。可以看到,ASUS 天选 air 的GPU频率与使用率随时在变化,导致深度学习算法的计算时间也不是固定的,计时结果仅供参考:
五、小结
开始仅从Detect 的结果来看,RTX3070好像干不过GTX1070,仔细检查发现,CUDA11.0版本不能够正确识别RTX3070。
重新安装CUDA11.2,并测试。安装过程请见:YOLOv5 - Win10 + RTX3070 的 PyTorch 安装指南(ASUS 天选 air)
从Train的结果来看:
对于 --batch 1参数,GTX 1070 用时:0.088h,RTX 3070 用时:0.050h,RTX 3070 用时是 GTX 1070 的57%左右。
对于 --batch 2参数,GTX 1070 用时:0.050h,RTX 3070 用时:0.029h,RTX 3070 用时是 GTX 1070 的58%左右。
对于 --batch 6参数,GTX 1070 报错:测不出,RTX 3070 用时:0.025h。
所以,就测试的两台电脑而言,RTX 3070 的 AI 训练能力大约是 GTX 1070 的 1.7 倍。
老徐 2021/2/19