EXCEL与PYTHON系列第一篇---Pandas(1)read_excel详解
引言
excel搭配python这个话题在楼主看来有点别扭,其实excel本身已经非常强大了,可以这么说,excel+python能实现的,excel单独也能实现。
excel单独就能连接sql server数据库,发送sql语句获取数据,驾驭海量数据;
excel单独就能设计出自定义的可视化用户交互界面(userform);
excel甚至可以做爬虫。。。
楼主自己的实际工作,快10年了,在做了的四、五十个项目中,真正用上excel+python的就两个项目
不过,有些事情单独使用excel确实费时费力,用vb写代码,还真没用python写来的舒服省力。
那废话就不多说了,开一个系列来讲excel+python,涉及到的两个主要的库就是pandas和xlwings。
先来讲pandas,主要会围绕pandas与excel相关的知识点来讲
本篇文章呢我们来详细的了解一下read_excel,这个pandas的数据读取函数
正文
一、基础知识
pandas可以读取多种的数据格式,针对excel来说,读取的方法为read_excel,假设我有一个名为”test.xlsx“的文件,那么如果要读取我们可以这样写:
import pandas as pd
df = pd.read_excel("test.xlsx")简单吧?非常简单
但有一个隐藏的细节要注意,就是pandas在读取excel文件的时候需要调用读取文件的第三方库(称为引擎)。
举个不太恰当的例子,张三买车得到了一次砸金蛋的机会,他当然不能用手砸,于是他顺手抄起旁边的锤子就砸了一个金蛋。
这个例子里面的张三相当于pandas,金蛋就是excel文件,锤子就是读取文件的引擎。
我们来看一下pandas的API文档中对读取引擎的描述:
Supported engines: “xlrd”, “openpyxl”, “odf”, “pyxlsb”. Engine compatibility :
“xlrd” supports old-style Excel files (.xls).
“openpyxl” supports newer Excel file formats.
“odf” supports OpenDocument file formats (.odf, .ods, .odt).
“pyxlsb” supports Binary Excel files.
也就是说,pandas支持4种excel文件的读取引擎,我们用的最多的是"xlrd"和"openpyxl"
其中"xlrd"是用来读取".xls"文件的,而"openpyxl"是用来读取".xlsx"及其他07版以后的新格式
其实"xlrd"和"openpyxl"都是python的库,可以单独的安装使用
不同的库对于一些细节上的处理会有不同的表现,比如日期格式的处理等,如果要指定使用哪个引擎的化可以用入参:engine,比如engine="xlrd"
当然作为使用者我们在大部分情况下不需要指定引擎,pandas会帮我们判断
除了引擎以外read_excel还有很多入参,完整的如下:
pandas.read_excel( io, sheet_name=0, header=0, names=None, index_col=None, usecols=None, squeeze=None, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, parse_dates=False, date_parser=None, thousands=None, decimal='.', comment=None, skipfooter=0, convert_float=None, mangle_dupe_cols=True, storage_options=None)
这么多东西,不用全记,几个比较重要的是:
- sheet_name:如果有多张表,这个参数可以用来指定要读取的表,如果不指定,但有多张表,那么就会读取活动的表(active worksheet)
- dtype:如果需要指定列的数据类型,则需要用到这个参数。读取文件时每列都会有默认的推断数据类型,但有时推断的会有问题;比如员工的工号如果是纯数字的,就会被推断成int,这样那些0开头的工号就会读取的有问题,这时我们就需要强制将工号列定义为str类型
- index_col:行索引所在列,详见下面的例子
- header:列名所在的行,详见后面的例子
- usecols:指定需要的列,默认所有的列都读取,如果指定其他的列就不读取
有了基本了解后我们就来通过一些例子来详细的讲解一下上面提到的几个参数
二、参数详解-index_col
我们先来看index_col这个参数,直接看图:

图1
代码中的df.head()是用来查看数据的前5行的。
pandas读取到数据后会在数据前加一行索引(index),也就是图右边代码块中"姓名"前面的那一列。这个行索引很重要,是我们定位数据的一个必备条件。这个索引的建立由上面提到的index_col这个来定义,默认情况下,index_col=None,也就是说默认会添加一列自增的行索引。
如果数据本身已经有索引列了,那我们可以指定,如果索引在第一列那我们就写index_col=0,第二列就写index_col=1。。。
比如:
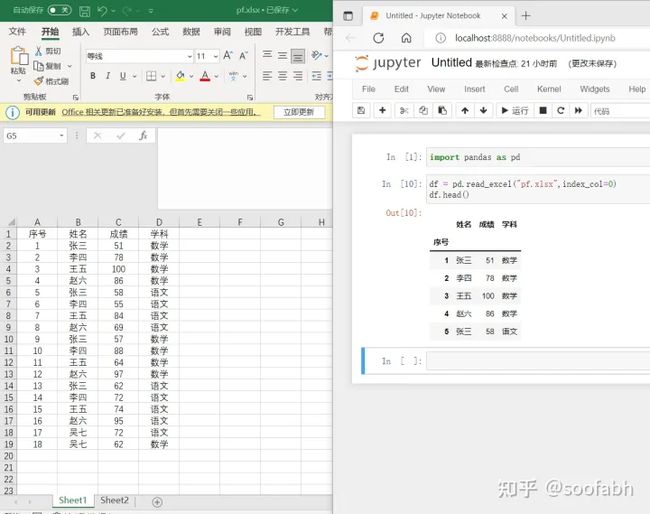
图2
索引可以不唯一,也可以有多层索引(MultiIndex)
如果有多层索引,那么index_col需要传入一个数组,我们看下面的例子:
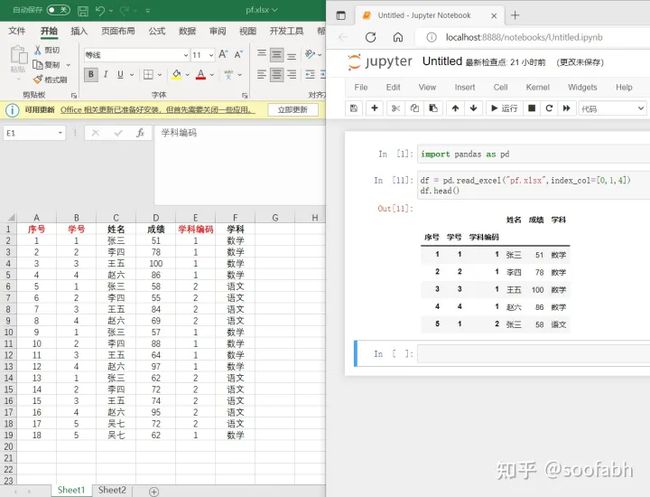
图3
这里定义了三个索引,分别是a,b,e这三列
不过一般来说楼主不建议定义多个行索引,用自增列就行,后面可以用groupby来实现索引分组
三、参数详解-header
我们再修改一下数据来讲解另一个参数,header,看图:
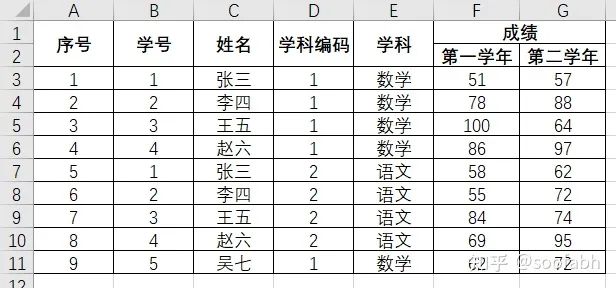
图4
这个数据我们该怎么导入呢?这里就要用到上面说的另一个入参,header
本来不指定的话默认第一行为列索引,那现在有两层列索引,那我们就需要写header=[0,1],也就告诉pandas第一行和第二行是列索引,我们来看:
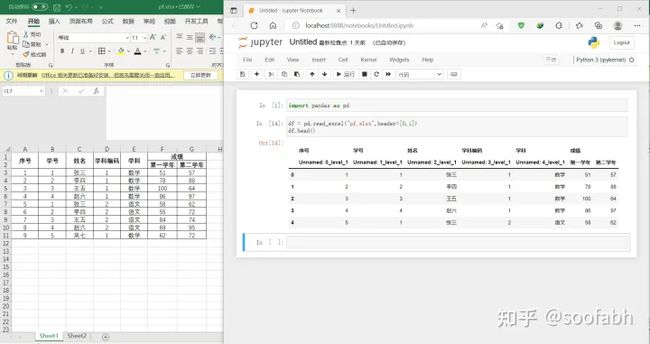
图5
这导入结果在楼主这种强迫症看来就是不忍直视,太难看了,告诉大家两点:
- 不要用合并单元格,pandas可以处理,但是不要给自己找麻烦
- 原始数据先整理一下,尽量不要用多层行索引和多层列索引
上面的数据排版在excel里面是比较好看,但不实用,建议修改一下数据格式然后导入,可以改成这样:
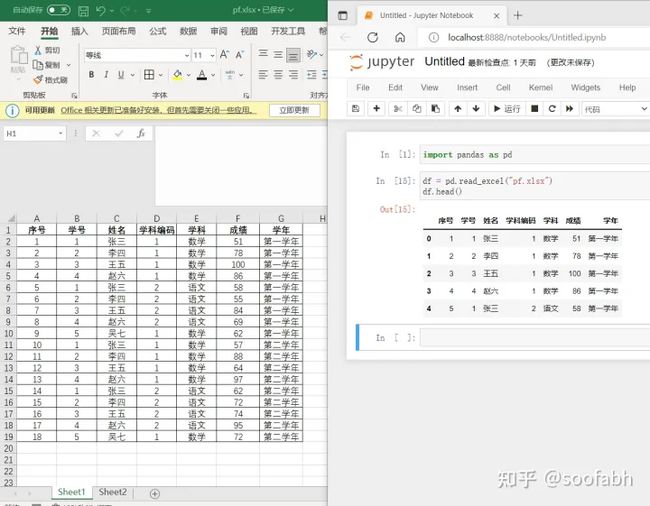
图6
四、参数详解-usecols
如果还是图6里面的数据,我们不想要序号和学科编号那两列了,那我们就可以用usecols参数。代码有三张写法
- 使用列字母
- 使用列的位置序号
- 使用列名称
代码分别是:
df = pd.read_excel("pf.xlsx",usecols=["B,C,E:G"])
df = pd.read_excel("pf.xlsx",usecols=[1,2,4,5,6])
df = pd.read_excel("pf.xlsx",usecols=["学号,姓名,学科,成绩,学年"])上面三个读取方式是等效的
不过楼主觉得大部分情况直接读取所有的列就行。真要去掉一定不要的列,读取完成后再去掉也可以
五、参数详解-dtype
这个参数还是比较重要的,如果我们的数据中学号是从001开始的,那我们直接读取的话会怎么样呢,我们来看一下:
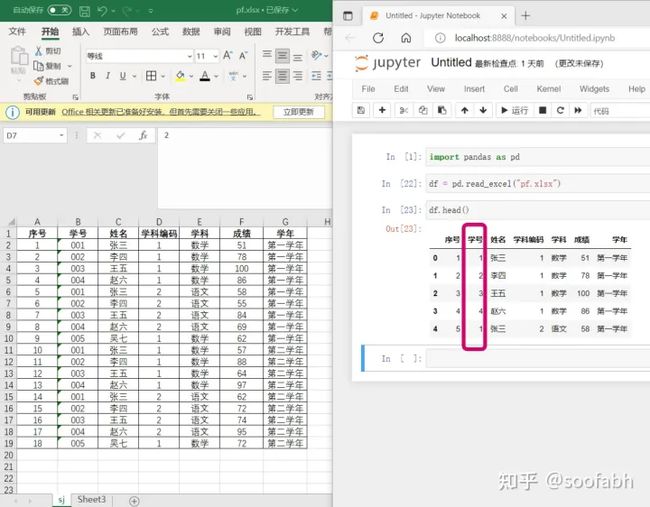
图7
可以看到,读取之后,学号被推断成了int类型
这时候我们就要用到dtype这个参数了,我们直接来看结果:
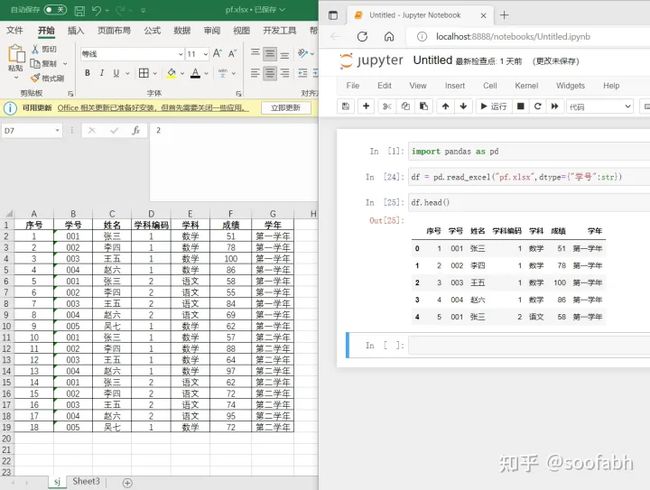
图8
六、其他参数
还有几个不常用但有些用处的参数,我们简单的来讲一下
- na_values:自定义的空值,比如说张三第一学期的语文考试因为某些原因没有靠,成绩那边填写的是“缺考”。那我们就可以设置na_values=["缺考"],这样导入后张三第一学期的成绩就会自动被识别为pandas的默认空占位符NaN
- parse_dates:如果excel表里面的日期列填写的不太规范,可以使用这个参数,告诉pandas哪一列是日期,保证日期格式读取的准确性
- true_values:指定真值,比如true_values=["是"],那么,数据中的”是“就会被识别为True
- false_values:指定假值,比如false_values=["否"],那么,数据中的”否“就会被识别为False
七、多表读取
接下来让我们来看另一种情况,如果第一学年和第二学年的数据被分别放在两张表面,我们该怎么读取数据呢?首先,笨办法我们可以写两遍read_excel,搭配sheet_name参数。但还有一种更加简单也节约时间的方法:
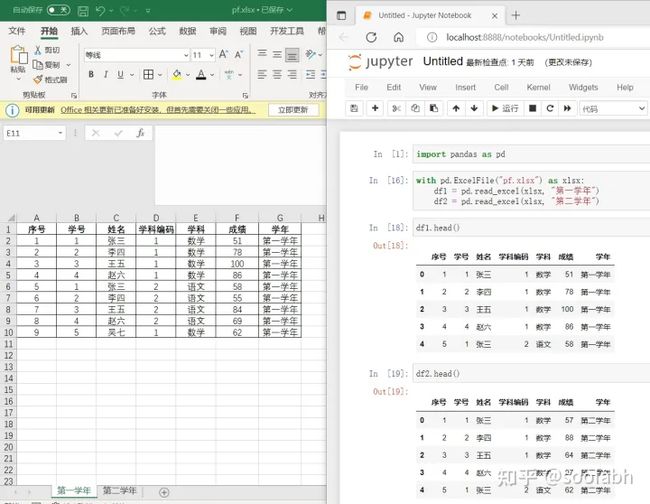
图7
这个例子里面使用了ExcelFile这个方法,打开一次,读取多张表
另外还有一种方法,就是直接在read_excel里面直接传入表名的列表,代码如下:
data = pd.read_excel("pf.xlsx", ["第一学年", "第二学年"])但还是推荐用ExcelFile方法,因为直接用read_excel的话无法对两张表就行不同的操作。比如,如果第一表的行索引在第一列,第二张表的行索引在第二列,那直接用read_excel就无法处理。
结语
关于read_excel就先讲这么多了,如果有什么遗漏或者不清楚的大家可以私信楼主
下一篇我们来讲to_excel,也就是pandas导出excel文件