深度学习图像语义分割网络总结:FCN与SegNet的Pytorch实现
图像语义分割网络系列博文索引
| FCN与SegNet | U-Net与V-Net | DeepLab系列 | DenseNet、PSPNet、与DenseASPP | Mask R-CNN |
|---|
(后四个在计划中,敬请期待)
图像语义网络分割之FCN与SegNet
- 图像语义分割网络系列博文索引
- 全卷积网络FCN
-
- FCN主要贡献
- FCN网络结构
- Pytorch框架下FCN实现
- SegNet
-
- SegNet主要贡献
- Pytorch框架下SegNet实现
全卷积网络FCN
FCN为深度学习在图像语义分割领域里程碑的一篇,实现了对任意大小输入图像进行像素级别的端到端的语义分割。原文链接:Fully Convolutional Networks for Semantic Segmentation
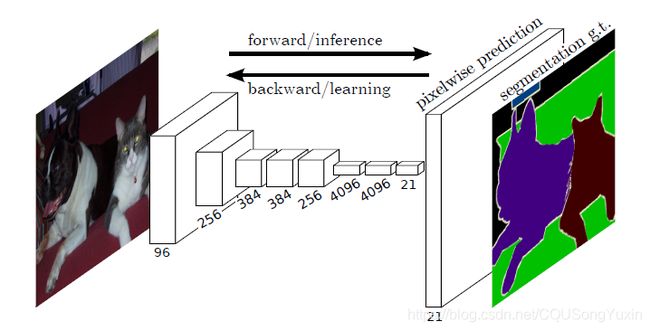
我们的关键观点是构建“全卷积”网络,它接受任意大小的输入,并通过有效的推理和学习产生相应大小的输出。我们定义并详述全卷积网络的空间,解释它们在空间密集预测任务中的应用,并与之前的模型建立联系。我们将当前的分类网络(AlexNet [19], VGG网[31],和GoogLeNet[32])改造为完全卷积网络,并通过微调来将其学习到的表示迁移到分割任务。然后,我们定义了一种新的架构,该架构结合了来自深、粗层的语义信息和来自浅、细层的表征信息,从而产生精确和详细的分割。我们的全卷积网络实现了最先进的NYUDv2,SIFT流和PASCAL VOC分割(相对2012年的结果提升了20%,达到了62.2%的平均IU),而对一个典型图像的推断只需要不到五分之一秒。
FCN主要贡献
- 使用迁移学习的方法对已有的分类网络(AlexNet,VGG,GoogLeNet)进行结构改造和参数微调(fine-tuning)用于图像的语义分割。
- 使用全卷积的方法替代分类网络中的全连接层,因为作者认为全连接层破坏了图像像素中的空间关系。图2中展示了使用全连接层与卷积层的对比图,全连接层输出的是一维概率分布,卷积层输出为二维热力图(heat map),较好的保留了像素之间的空间关系,为之后像素级别的图像分割提供了便利。同时采用全卷积相对全连接也大大提升了计算效率。
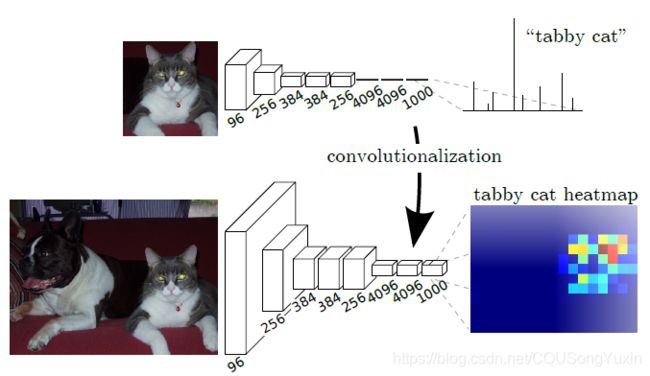
图2 全连接与全卷积对比图 - 为了稀疏的输出(卷积得到的heat map)与密集的像素建立联系,作者采用了反卷积的方式进行上采样,采用反卷积进行上采样是需要学习的,也可以直接采用双线性插值的方式进行上采样。这个密集和稀疏建立联系是由分多个阶段的跃迁实现的,一定程度上可以理解为多尺度图像融合,目的是实现精细的预测。
FCN网络结构
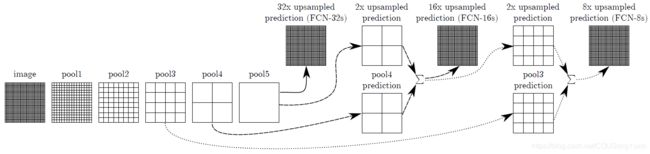
如图3所示FCN-32s是由pool5得到的特征图直接采用上采样得到的结果,FCN-16s是pool5经过二倍上采样与pool4求和之后再进行上采样,FCN-8s与此过程类似。可视化的FCN网络机构可以参考这里(http://ethereon.github.io/netscope/#/preset/fcn-8s-pascal)
Pytorch框架下FCN实现
这里使用的代码是在Github中guanfuchen/semseg原代码的基础上做了一些顺序上的调整及更多的标注帮助理解。
# -*- coding: utf-8 -*-
import time
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from torchvision import models
# fcn32s模型
def fcn_32s(n_classes=21, pretrained=True):
model = fcn(module_type='32s', n_classes=n_classes, pretrained=pretrained)
return model
def fcn_16s(n_classes=21, pretrained=True):
model = fcn(module_type='16s', n_classes=n_classes, pretrained=pretrained)
return model
def fcn_8s(n_classes=21, pretrained=True):
model = fcn(module_type='8s', n_classes=n_classes, pretrained=pretrained)
return model
def cross_entropy2d(input, target, weight=None, size_average=True):
n, c, h, w = input.size()
nt, ht, wt = target.size()
# Handle inconsistent size between input and target
if h > ht and w > wt: # upsample labels
target = target.unsequeeze(1)
target = F.upsample(target, size=(h, w), mode="nearest")
target = target.sequeeze(1)
elif h < ht and w < wt: # upsample images
input = F.upsample(input, size=(ht, wt), mode="bilinear")
elif h != ht and w != wt:
raise Exception("Only support upsampling")
input = input.transpose(1, 2).transpose(2, 3).contiguous().view(-1, c)
target = target.view(-1)
loss = F.cross_entropy(input, target, weight=weight, size_average=size_average, ignore_index=250)
return loss
class fcn(nn.Module):
def __init__(self, module_type='32s', n_classes=21, pretrained=True):
super(fcn, self).__init__()
self.n_classes = n_classes
self.module_type = module_type
# VGG16=2+2+3+3+3+3
# VGG16网络的第一个模块是两个out_channel=64的卷积块
self.conv1_block = nn.Sequential(
nn.Conv2d(3, 64, 3, padding=100), #输入3通道,输出64通道,卷积核大小为3,用100填充
nn.ReLU(inplace=True), #inplace=True,节省内存
nn.Conv2d(64, 64, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2, ceil_mode=True), #核的大小为2,步长为2,向上取整
)
# VGG16网络的第二个模块是两个out_channel=128的卷积块
self.conv2_block = nn.Sequential(
nn.Conv2d(64, 128, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2, ceil_mode=True),
)
# VGG16网络的第三个模块是三个out_channel=256的卷积块
self.conv3_block = nn.Sequential(
nn.Conv2d(128, 256, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2, ceil_mode=True),
)
# VGG16网络的第四个模块是三个out_channel=512的卷积块
self.conv4_block = nn.Sequential(
nn.Conv2d(256, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2, ceil_mode=True),
)
# VGG16网络的第五个模块是三个out_channel=512的卷积块
self.conv5_block = nn.Sequential(
nn.Conv2d(512, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, 3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=2, ceil_mode=True),
)
self.classifier = nn.Sequential(
nn.Conv2d(512, 4096, 7),
nn.ReLU(inplace=True),
nn.Dropout2d(),
nn.Conv2d(4096, 4096, 1),
nn.ReLU(inplace=True),
nn.Dropout2d(),
nn.Conv2d(4096, self.n_classes, 1),
)
if self.module_type=='16s' or self.module_type=='8s':
self.score_pool4 = nn.Conv2d(512, self.n_classes, 1)
if self.module_type=='8s':
self.score_pool3 = nn.Conv2d(256, self.n_classes, 1)
if pretrained:
self.init_vgg16()
def init_vgg16(self):
vgg16 = models.vgg16(pretrained=True) #获得已经训练好的模型
# -----------赋值前面2+2+3+3+3层feature的特征-------------
# 由于vgg16的特征是Sequential,获得其中的子类通过children()
vgg16_features = list(vgg16.features.children())
#print(vgg16_features)
conv_blocks = [self.conv1_block, self.conv2_block, self.conv3_block, self.conv4_block, self.conv5_block]
conv_ids_vgg = [[0, 4], [5, 9], [10, 16], [17, 23], [24, 30]] #对应VGG的五个块
for conv_block_id, conv_block in enumerate(conv_blocks):
#print(conv_block_id)
conv_id_vgg = conv_ids_vgg[conv_block_id]
#print(conv_id_vgg)
# zip函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,建立了FCN网络与VGG网络的对应关系。
for l1, l2 in zip(conv_block, vgg16_features[conv_id_vgg[0]:conv_id_vgg[1]]):
if isinstance(l1, nn.Conv2d) and isinstance(l2, nn.Conv2d):
assert l1.weight.size() == l2.weight.size()
assert l1.bias.size() == l2.bias.size()
# 将网络对应的权重由训练好的VGG赋值给FCN
l1.weight.data = l2.weight.data
l1.bias.data = l2.bias.data
# print(l1)
# print(l2)
# -----------赋值后面3层classifier的特征-------------
vgg16_classifier = list(vgg16.classifier.children())
for l1, l2 in zip(self.classifier, vgg16_classifier[0:3]):
if isinstance(l1, nn.Conv2d) and isinstance(l2, nn.Linear):
l1.weight.data = l2.weight.data.view(l1.weight.size())
l1.bias.data = l2.bias.data.view(l1.bias.size())
# -----赋值后面1层classifier的特征,由于类别不同,需要修改------
l1 = self.classifier[6]
l2 = vgg16_classifier[6]
if isinstance(l1, nn.Conv2d) and isinstance(l2, nn.Linear):
l1.weight.data = l2.weight.data[:self.n_classes, :].view(l1.weight.size())
l1.bias.data = l2.bias.data[:self.n_classes].view(l1.bias.size())
def forward(self, x):
'''
:param x: (1, 3, 360, 480)
:return:
'''
conv1 = self.conv1_block(x)
conv2 = self.conv2_block(conv1)
conv3 = self.conv3_block(conv2)
conv4 = self.conv4_block(conv3)
conv5 = self.conv5_block(conv4)
score = self.classifier(conv5)
#print('score', score.shape) #[1, 21, 12, 16]
if self.module_type=='16s' or self.module_type=='8s':
score_pool4 = self.score_pool4(conv4) #[1, 21, 35, 43]
#print('pool4',score_pool4.shape)
if self.module_type=='8s':
score_pool3 = self.score_pool3(conv3) #[1, 21, 70, 85]
#print('pool3', score_pool3.shape)
# print(conv1.data.size())
# print(conv2.data.size())
# print(conv4.data.size())
# print(conv5.data.size())
# print(score.data.size())
# print(x.data.size())
if self.module_type=='16s' or self.module_type=='8s':
# 双线性插值,由[1, 21, 12, 16]扩大到[1, 21, 35, 43]
score = F.interpolate(score, score_pool4.size()[2:], mode='bilinear', align_corners=True)
score += score_pool4
if self.module_type=='8s':
# 双线性插值,由[1, 21, 35, 43]扩大到[1, 21, 70, 85]
score = F.interpolate(score, score_pool3.size()[2:], mode='bilinear', align_corners=True)
score += score_pool3
# 双线性插值,由[1, 21, 35, 43]扩大到[1, 21, 360, 480]
out = F.interpolate(score, x.size()[2:], mode='bilinear', align_corners=True)
return out
if __name__ == '__main__':
n_classes = 21
model_fcn32s = fcn(module_type='32s', n_classes=n_classes, pretrained=True)
model_fcn16s = fcn(module_type='16s', n_classes=n_classes, pretrained=True)
model_fcn8s = fcn(module_type='8s', n_classes=n_classes, pretrained=True)
# model_fcn32s = add_flops_counting_methods(model_fcn32s)
# model_fcn32s = model_fcn32s.train()
# model_fcn32s.start_flops_count()
# model.init_vgg16()
x = Variable(torch.randn(1, 3, 360, 480))
y = Variable(torch.LongTensor(np.ones((1, 360, 480), dtype=np.int)))
# print(x.shape)
# ---------------------------fcn32s模型运行时间-----------------------
start = time.time()
pred = model_fcn32s(x)
end = time.time()
print(end-start)
# model_fcn32s_flops = model_fcn32s.compute_average_flops_cost() / 1e9 / 2
# print('model_fcn32s_flops:', model_fcn32s_flops)
# ---------------------------fcn16s模型运行时间-----------------------
start = time.time()
pred = model_fcn16s(x)
end = time.time()
print(end-start)
# ---------------------------fcn8s模型运行时间-----------------------
start = time.time()
pred = model_fcn8s(x)
end = time.time()
print(end-start)
# print(pred.shape)
loss = cross_entropy2d(pred, y)
# print(loss)
SegNet
SegNet是图像语义分割中另外一个重要的网络,它的主要贡献在于在图像分割领域引入了编码-解码(Encoder-Decoder)的结构。原文链接:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
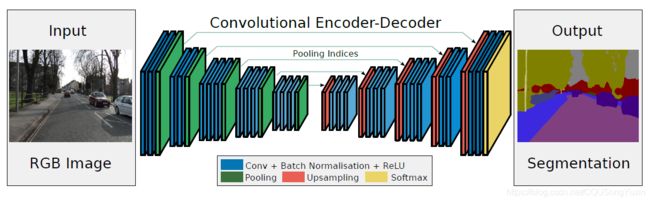
我们提出了一种新颖而实用的深度全卷积神经网络结构用于语义像素分割称为SegNet。这个核心的可训练分割引擎包括一个编码器网络,一个相应的解码器网络,以及一个像素级的分类层。该编码器网络的结构与VGG16网络中的13个卷积层拓扑结构相同。解码器网络的作用是将低分辨率的编码器特征映射到输入分辨率大小的特征,以便按像素分类。SegNet的创新点在于解码器对其低分辨率特征图进行上采样的方式。具体来说,解码器使用在对应编码器的最大池化步骤中计算的索引来执行非线性上采样,这样就省去了在采用反卷积进行上采样时需进行学习的过程。
SegNet主要贡献
- 采用了编码器-解码器(Encoder-Decoder) 的结构,编码器和FCN一样都是借鉴了VGG的结构,使用VGG的前13层作为编码器,从输入图像中提取低分辨率、高度抽象的特征。编码器之后有对应的解码器,作用是从低分辨率的特征图中恢复到输入图像的像素大小,从而实现像素级别的密集预测分类。在编码器之后的最后一层为Softmax层,作用是进行像素级别的分类。
- 提出了反池化操作,在编码过程中的每一个池化操作中记录下最大值所在的位置,在解码过程中上采样恢复原大小的过程中将特征图中数值置于池化操作中所记录的位置,用图像表示如下图2所示,图源
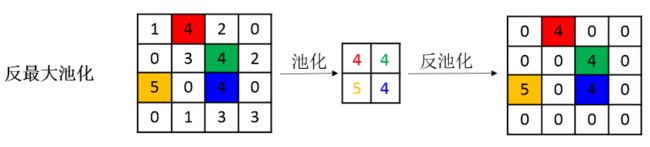
Pytorch框架下SegNet实现
这里使用的代码是在Github中guanfuchen/semseg原代码的基础上做了一些注释帮助理解。读懂FCN的实现之后SegNet的实现读起来就简单不少。
import time
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from torchvision import models
from torchvision.models.squeezenet import Fire
from semseg.modelloader.utils import segnetDown2, segnetDown3, segnetUp2, segnetUp3, conv2DBatchNormRelu, \
AlignedResInception, segnetDown4, segnetUp4
class conv2DBatchNorm(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding, bias=True):
super(conv2DBatchNorm, self).__init__()
self.cb_seq = nn.Sequential(
nn.Conv2d(int(in_channels), int(out_channels), kernel_size=kernel_size, padding=padding, stride=stride, bias=bias),
nn.BatchNorm2d(int(out_channels)),
)
def forward(self, inputs):
outputs = self.cb_seq(inputs)
return outputs
class conv2DBatchNormRelu(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding, bias=True, dilation=1):
super(conv2DBatchNormRelu, self).__init__()
self.cbr_seq = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=bias, dilation=dilation),
nn.BatchNorm2d(num_features=out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.cbr_seq(x)
return x
class segnetDown2(nn.Module):
def __init__(self, in_channels, out_channels):
super(segnetDown2, self).__init__()
self.conv1 = conv2DBatchNormRelu(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=1)
self.conv2 = conv2DBatchNormRelu(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=1)
self.max_pool = nn.MaxPool2d(kernel_size=2, stride=2, return_indices=True)
pass
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
unpool_shape = x.size()
# print(unpool_shape)
x, pool_indices = self.max_pool(x)
return x, pool_indices, unpool_shape
class segnetDown3(nn.Module):
def __init__(self, in_channels, out_channels):
super(segnetDown3, self).__init__()
self.conv1 = conv2DBatchNormRelu(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=1)
self.conv2 = conv2DBatchNormRelu(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=1)
self.conv3 = conv2DBatchNormRelu(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=1)
self.max_pool = nn.MaxPool2d(kernel_size=2, stride=2, return_indices=True)
pass
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
unpool_shape = x.size()
# print(unpool_shape)
x, pool_indices = self.max_pool(x)
return x, pool_indices, unpool_shape
class segnetUp2(nn.Module):
def __init__(self, in_channels, out_channels):
super(segnetUp2, self).__init__()
self.max_unpool = nn.MaxUnpool2d(kernel_size=2, stride=2)
self.conv1 = conv2DBatchNormRelu(in_channels=in_channels, out_channels=in_channels, kernel_size=3, stride=1, padding=1)
self.conv2 = conv2DBatchNormRelu(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=1)
pass
def forward(self, x, pool_indices, unpool_shape):
x = self.max_unpool(x, indices=pool_indices, output_size=unpool_shape)
x = self.conv1(x)
x = self.conv2(x)
return x
class segnetUp3(nn.Module):
def __init__(self, in_channels, out_channels):
super(segnetUp3, self).__init__()
self.max_unpool = nn.MaxUnpool2d(kernel_size=2, stride=2)
self.conv1 = conv2DBatchNormRelu(in_channels=in_channels, out_channels=in_channels, kernel_size=3, stride=1, padding=1)
self.conv2 = conv2DBatchNormRelu(in_channels=in_channels, out_channels=in_channels, kernel_size=3, stride=1, padding=1)
self.conv3 = conv2DBatchNormRelu(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=1)
pass
def forward(self, x, pool_indices, unpool_shape):
x = self.max_unpool(x, indices=pool_indices, output_size=unpool_shape)
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
return x
class segnet(nn.Module):
def __init__(self, n_classes=21, pretrained=False):
super(segnet, self).__init__()
self.down1 = segnetDown2(3, 64) #编码器阶段
self.down2 = segnetDown2(64, 128)
self.down3 = segnetDown3(128, 256)
self.down4 = segnetDown3(256, 512)
self.down5 = segnetDown3(512, 512)
self.up5 = segnetUp3(512, 512) #解码器阶段
self.up4 = segnetUp3(512, 256)
self.up3 = segnetUp3(256, 128)
self.up2 = segnetUp2(128, 64)
self.up1 = segnetUp2(64, n_classes)
self.init_weights(pretrained=pretrained)
def forward(self, x):
x, pool_indices1, unpool_shape1 = self.down1(x)
x, pool_indices2, unpool_shape2 = self.down2(x)
x, pool_indices3, unpool_shape3 = self.down3(x)
x, pool_indices4, unpool_shape4 = self.down4(x)
x, pool_indices5, unpool_shape5 = self.down5(x)
x = self.up5(x, pool_indices=pool_indices5, unpool_shape=unpool_shape5)
x = self.up4(x, pool_indices=pool_indices4, unpool_shape=unpool_shape4)
x = self.up3(x, pool_indices=pool_indices3, unpool_shape=unpool_shape3)
x = self.up2(x, pool_indices=pool_indices2, unpool_shape=unpool_shape2)
x = self.up1(x, pool_indices=pool_indices1, unpool_shape=unpool_shape1)
return x
def init_weights(self, pretrained=False):
# the model vgg16_bn is better than vgg16?
# vgg16 = models.vgg16(pretrained=pretrained)
vgg16 = models.vgg16_bn(pretrained=pretrained)
# -----------赋值前面2+2+3+3+3层feature的特征-------------
# 由于vgg16的特征是Sequential,获得其中的子类通过children()
vgg16_features = list(vgg16.features.children())
vgg16_conv_layers = []
for layer in vgg16_features:
if isinstance(layer, nn.Conv2d) or isinstance(layer, nn.BatchNorm2d):
# print(layer)
vgg16_conv_layers.append(layer)
conv_blocks = [self.down1, self.down2, self.down3, self.down4, self.down5]
segnet_down_conv_layers = []
for conv_block_id, conv_block in enumerate(conv_blocks):
print('id',conv_block_id)
print('block',conv_block)
conv_block_children = list(conv_block.children())
for conv_block_child in conv_block_children:
if isinstance(conv_block_child, conv2DBatchNormRelu):
print('child',conv_block_child)
if hasattr(conv_block_child, 'cbr_seq'): #hasattr() 函数用于判断对象是否包含对应的属性。
print('cbrseq',conv_block_child.cbr_seq)
layer_lists = list(conv_block_child.cbr_seq)
for layer in conv_block_child.cbr_seq:
# print(layer)
if isinstance(layer, nn.Conv2d) or isinstance(layer, nn.BatchNorm2d):
# print(layer)
segnet_down_conv_layers.append(layer)
# print('len(segnet_down_conv_layers):', len(segnet_down_conv_layers))
# print('len(vgg16_conv_layers)', len(vgg16_conv_layers))
for l1, l2 in zip(segnet_down_conv_layers, vgg16_conv_layers):
if isinstance(l1, nn.Conv2d) and isinstance(l2, nn.Conv2d):
assert l1.weight.size() == l2.weight.size()
assert l1.bias.size() == l2.bias.size()
# 赋值的是数据
l1.weight.data = l2.weight.data
l1.bias.data = l2.bias.data
# print(l1)
# print(l2)
def cross_entropy2d(input, target, weight=None, size_average=True):
n, c, h, w = input.size()
nt, ht, wt = target.size()
# Handle inconsistent size between input and target
if h > ht and w > wt: # upsample labels
target = target.unsequeeze(1)
target = F.upsample(target, size=(h, w), mode="nearest")
target = target.sequeeze(1)
elif h < ht and w < wt: # upsample images
input = F.upsample(input, size=(ht, wt), mode="bilinear")
elif h != ht and w != wt:
raise Exception("Only support upsampling")
input = input.transpose(1, 2).transpose(2, 3).contiguous().view(-1, c)
target = target.view(-1)
print('target',target.view(-1).shape)
loss = F.cross_entropy(input, target, weight=weight, size_average=size_average, ignore_index=250)
return loss
if __name__ == '__main__':
batch_size = 1
n_classes = 21
model = segnet(n_classes=n_classes, pretrained=True)
x = Variable(torch.randn(1, 3, 360, 480))
y = Variable(torch.LongTensor(np.ones((1, 360, 480), dtype=np.int)))
# print(x.shape)
start = time.time()
pred = model(x)
end = time.time()
print(end-start)
# print(pred.shape)
print('pred.type:', pred.type)
loss = cross_entropy2d(pred, y)
# print(loss)