论文阅读《Adversarial Multiview Clustering Networks With Adaptive Fusion》
目录
- 论文信息
- 一、Abstract
- 二、Introduction
- 三、Adversarial Multiview Clustering Network
-
- (一)多视图编码器模块
- (二)多视图生成对抗模块
- (三)深度聚类模块
- (四)总体目标函数
- (五)算法伪代码
论文信息
论文标题:Adversarial Multiview Clustering Networks With Adaptive Fusion
论文作者:Qianqian Wang,Zhiqiang Tao,Wei Xia,Quanxue Gao,Xiaochun Cao,Licheng Jiao
论文来源: 2022,TNNLS
论文地址:download
论文代码:download
一、Abstract
挑战:现有的深度多视图聚类(MVC)方法主要基于自动编码器网络,该网络寻找公共潜在变量来分别重建每个视图的原始输入。然而,由于特定于视图的重建损失,在多个视图上提取一致的潜在表示以进行聚类是一个挑战。
AMvC概述:为了应对这一挑战,本文提出了对抗式MVC(AMvC)网络。所提出的AMvC根据不同视图之间的融合潜在表示生成每个视图的样本,以鼓励更一致的聚类结构。具体来说,使用多视图编码器从所有视图中提取潜在描述,并使用相应的生成器生成重构样本。将判别网络和均方损失联合用于训练多视图编码器和生成器,以平衡每个视图潜在表示的清晰度和一致性。此外,还提出了一种自适应融合层来获得共享的潜在表示,并在该层上施加了聚类损失和 l 1 , 2 \mathcal{l}_{1,2} l1,2-norm约束,以提高聚类性能和区分潜在空间。
二、Introduction
然而,现有的基于自动编码器的deep-MVC方法有一些局限性:
1) 它们仅利用重建损失来学习重建样本与原始样本之间的一致性信息,而重建损失是视图特有的,很难在多个视图上提取一致的潜在表示进行聚类。
2) 共享表示可能没有足够的区分能力进行聚类。
3) 这些方法中使用了各种融合方法,但它们忽略了不同的视图通常在重要性方面有所不同。
三、Adversarial Multiview Clustering Network
l 1 , 2 \mathcal{l}_{1,2} l1,2-norm正则化使得共享潜在表示更容易区分。
 我们构建了由三个子模块组成的AMvC网络:多视图编码器模块E、多视图生成对抗模块(包含生成器G和鉴别器D)和深度聚类模块(包含加权自适应融合层和深度嵌入聚类层)。
我们构建了由三个子模块组成的AMvC网络:多视图编码器模块E、多视图生成对抗模块(包含生成器G和鉴别器D)和深度聚类模块(包含加权自适应融合层和深度嵌入聚类层)。

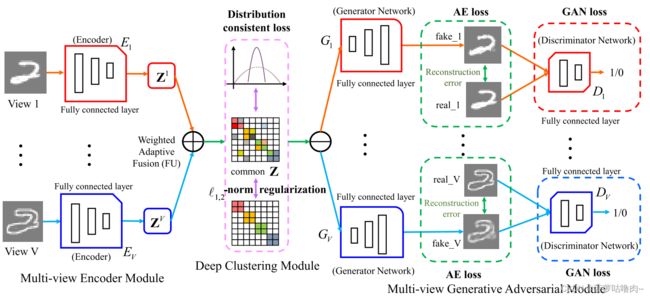
(一)多视图编码器模块
在多视图编码器网络 E = { E 1 , … , E v , … , E V } E=\left\{E_{1}, \ldots, E_{v}, \ldots, E_{V}\right\} E={E1,…,Ev,…,EV}中,对于每个视图,都有M层独立的完全连接网络和N层完全连接的共享参数网络。独立图层用于处理每个视图的不同特征尺寸。对于 v t h vth vth视图 X v X^{v} Xv,编码器 E v E_{v} Ev旨在学习潜在表示 Z v = { z 1 ( v ) , z 2 ( v ) , … , z n ( v ) } ( Z v ∈ R m × n ) \mathbf{Z}^{v}=\left\{z_{1}^{(v)}, z_{2}^{(v)}, \ldots, z_{n}^{(v)}\right\}\left(\mathbf{Z}^{v} \in R^{m \times n}\right) Zv={z1(v),z2(v),…,zn(v)}(Zv∈Rm×n)。具体而言,它将 d v d_{v} dv维输入数据 x i ( v ) x_{i}^{(v)} xi(v)映射到低维表示 z i ( v ) z_{i}^{(v)} zi(v)。这个映射可以表示为 Z v = E v ( X v ; θ E v ) \mathbf{Z}^{v}=E_{v}\left(\mathbf{X}^{v} ; \theta_{E_{v}}\right) Zv=Ev(Xv;θEv), E v E_{v} Ev表示 v t h vth vth视图的编码网络,其参数为 θ E v \theta_{E_{v}} θEv。
(二)多视图生成对抗模块
多视图生成器: G = { G 1 , … , G v , … , G V } G=\left\{G_{1}, \ldots, G_{v}, \ldots, G_{V}\right\} G={G1,…,Gv,…,GV}
多视图鉴别器: D = { D 1 , … , D v , … , D V } D=\left\{D_{1}, \ldots, D_{v}, \ldots, D_{V}\right\} D={D1,…,Dv,…,DV}
多视图生成器网络由具有共享参数的N层全连接网络和每个视图的M层独立全连接网络组成,可以生成所有视觉重建样本,并具有每个视图对应的潜在表示。
鉴别器网络由V个完全连接的层网络组成。每个鉴别器 D v D_{v} Dv由三个完全连接的层组成,我们应该注意, x i ( v ) x_{i}^{(v)} xi(v)是真实实例,而 x ^ i ( v ) \hat x_{i}^{(v)} x^i(v)是生成的样本。 D v D_{v} Dv将判别结果返回给生成器 G v G_{v} Gv,以更新其参数。通过这种方式,鉴别器作为正则化器来指导我们的多视点编码器网络E的训练,以提高嵌入表示的鲁棒性,并有效地解决过拟合问题。
(三)深度聚类模块
为了获得共享的潜在表示Z,我们在模型中引入了加权自适应融合层FU,它将V个潜在表示 Z v Z_{v} Zv自适应地融合到公共表示 Z = f ( { Z v } v = 1 V ; β ) Z=f \left(\left\{ Z^{v}\right \}_{v=1}^{V};\beta \right) Z=f({Zv}v=1V;β), f ( ⋅ ; β ) f(·;β) f(⋅;β)表示融合函数。为了寻找一个聚类友好的潜在空间,我们在网络中开发了一个独特的深度嵌入聚类层 C U CU CU。嵌入的聚类层在每次迭代后都包含新的聚类质心。我们使用共享表示Z和簇质心 { μ j } j = 1 k \left\{\mu_{j}\right\}_{j=1}^{k} {μj}j=1k来获得当前数据分布和目标数据分布。此外,我们利用当前数据分布和目标数据分布的 K u l l b a c k – L e i b l e r ( K L ) Kullback–Leibler(KL) Kullback–Leibler(KL)散度作为目标函数,迭代更新共享表示Z和簇质心 { μ j } j = 1 k \left\{\mu_{j}\right\}_{j=1}^{k} {μj}j=1k。
(四)总体目标函数
min E , G , β , μ max D L A E + λ 1 L G A N + λ 2 L C L U + λ 3 L 12 \min _{E, G, \beta, \mu} \max _{D} \mathcal{L}_{\mathrm{AE}}+\lambda_{1} \mathcal{L}_{\mathrm{GAN}}+\lambda_{2} \mathcal{L}_{\mathrm{CLU}}+\lambda_{3} \mathcal{L}_{12} E,G,β,μminDmaxLAE+λ1LGAN+λ2LCLU+λ3L12
包括四个部分:自动编码器(AE)损失,GAN损失,聚类损失CLU,1,2-范数正则化。
L A E = ∑ v = 1 V ∥ X v − X ^ v ∥ F 2 \mathcal{L}_{\mathrm{AE}}=\sum_{v=1}^{V}\left\|\mathbf{X}^{v}-\hat{\mathbf{X}}^{v}\right\|_{\mathrm{F}}^{2} LAE=∑v=1V∥∥∥Xv−X^v∥∥∥F2
L G A N = ∑ v = 1 V ( E x v ∼ P ( X v ) [ log D v ( x v ) ] + E x ^ v ∼ P ( X ^ v ) [ log ( 1 − D v ( x ^ v ) ) ] ) \mathcal{L}_{\mathrm{GAN}}=\sum_{v=1}^{V}\left(\mathbb{E}_{x^{v} \sim P\left(\mathbf{X}^{v}\right)}\left[\log D_{v}\left(x^{v}\right)\right]+\mathbb{E}_{\hat{x}^{v} \sim P\left(\hat{\mathbf{X}}^{v}\right)}\left[\log \left(1-D_{v}\left(\hat{x}^{v}\right)\right)\right]\right) LGAN=∑v=1V(Exv∼P(Xv)[logDv(xv)]+Ex^v∼P(X^v)[log(1−Dv(x^v))])
实际数据分布和生成的数据分布
Z = f ( { Z v } v = 1 V ; β ) = ∑ v = 1 V β v Z v / ∑ v = 1 V β v \mathbf{Z}=f\left(\left\{\mathbf{Z}^{v}\right\}_{v=1}^{V} ; \beta\right)=\sum_{v=1}^{V} \beta_{v} \mathbf{Z}^{v} / \sum_{v=1}^{V} \beta_{v} Z=f({Zv}v=1V;β)=∑v=1VβvZv/∑v=1Vβv
L C L U = ∑ i ∑ j p i j log p i j q i j \mathcal{L}_{\mathrm{CLU}}=\sum_{i} \sum_{j} p_{i j} \log \frac{p_{i j}}{q_{i j}} LCLU=∑i∑jpijlogqijpij
L 12 = ∥ Z ∣ 1 , 2 = ∑ i ( ∑ j ∣ z i j ∣ ) 2 \mathcal{L}_{12}=\|\left.\mathbf{Z}\right|_{1,2}=\sqrt{\sum_{i}\left(\sum_{j}\left|z_{i j}\right|\right)^{2}} L12=∥Z∣1,2=∑i(∑j∣zij∣)2
(五)算法伪代码
