论文阅读“Deep Graph Clustering via Dual Correlation Reduction”(AAAI2022)
论文标题
论文作者、链接
作者:Yue Liu, Wenxuan Tu, Sihang Zhou, Xinwang Liu, Linxuan Song,Xihong Yang,En Zhu
链接:AAAI2022: Deep Graph Clustering via Dual Correlation Reduction
代码:GitHub - yueliu1999/DCRN: [AAAI 2022] An official source code for paper Deep Graph Clustering via Dual Correlation Reduction.
Introduction逻辑
论文动机&现有工作存在的问题
现有的图结点编码往往会导致表征崩塌,即将所有的点都映射到同一个特征表示上,这将会限制结点的表征能力,进一步导致聚类结果低下。
论文核心创新点
(1)使用暹罗网络来编码样本
(2)强制使得交叉视图样本的关联矩阵和特征关联矩阵分别逼近两个单位矩阵,由于潜特征的不同维数是去相关的,从而增强了潜特征的识别能力。
(3)使用过度平滑的GCN来解决特征崩塌的问题。
(4)引入了一个传播正则化项,使网络以浅层网络结构获得远距离信息。
相关工作
图聚类
特征崩塌
论文方法
模型目标是通过双重方法重新归纳信息相关性,避免表示崩溃。
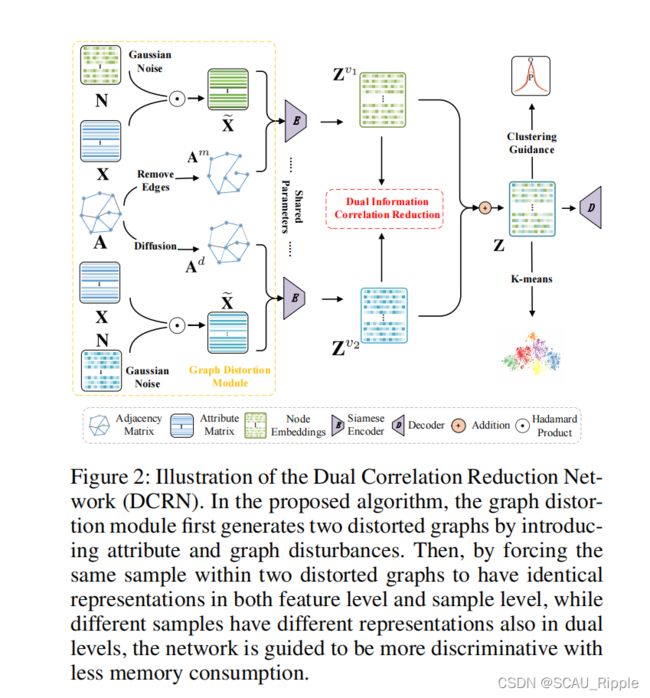
模型主要由两个部分组成:(1)图失扭曲模块(2)双路信息减相关(DICR)模块
标识以及问题定义
给定一个无向图![]() ,其中有C个类别的结点,
,其中有C个类别的结点,![]() 是结点集,
是结点集,![]() 是边集。这个无向图的特征矩阵为
是边集。这个无向图的特征矩阵为![]() ,并且原始的特征矩阵为
,并且原始的特征矩阵为![]() ,其中如果
,其中如果![]() 则
则![]() ,否则
,否则![]() 。
。
关联等级矩阵![]() 。
。
对于D的原始邻接矩阵A可以通过计算![]() 进行正则化
进行正则化![]() ,其中
,其中![]() 是单位矩阵。
是单位矩阵。
本文目标是训练一个以无监督的方式将所有节点嵌入到低维潜在空间的暹罗图编码器
图扭曲模块
图扭曲主要分成两种:(1)特征扭曲(2)边扭曲
特征扭曲:从高斯分布中![]() 随机生成一个噪音矩阵
随机生成一个噪音矩阵![]() ,产生被噪音影响的特征矩阵
,产生被噪音影响的特征矩阵![]() 可以由
可以由 获得,其中
获得,其中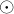 表示哈达玛积。
表示哈达玛积。
哈达玛积:哈达玛积_百度百科
边扭曲:有两种方法:
(1)基于相似性的边移除。先在潜空间上逐对计算余弦相似性,根据相似性矩阵生成掩膜矩阵![]() ,其中至少有10%的链接关系将被移除。根据下列公式计算边-掩膜邻接矩阵:
,其中至少有10%的链接关系将被移除。根据下列公式计算边-掩膜邻接矩阵:

其中,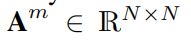
(2)另一个方式是图扩散。与MV-GRL相同,通过 Personalized PageRank (PPR) 将归一化邻接矩阵转化为图扩散矩阵,公式如下:
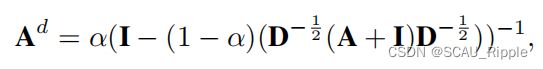
其中![]() 是传送概率,恒为0.2。
是传送概率,恒为0.2。
最后将两个视图记为![]()
对偶信息相关减弱
下图为dual information correlation reduction (DICR)机制的示意图,以双路的方式过滤潜在嵌入的冗余信息,分别为样本级的减相关sample-level correlation reduction (SCR) 以及特征级的减相关feature-level correlation reduction (FCR),由此防止特征崩塌。

样本级的减相关sample-level correlation reduction (SCR):对于暹罗网络学习到的两个视图的结点嵌入![]() 和
和![]() ,先计算跨视图的样本关联矩阵
,先计算跨视图的样本关联矩阵 :
:
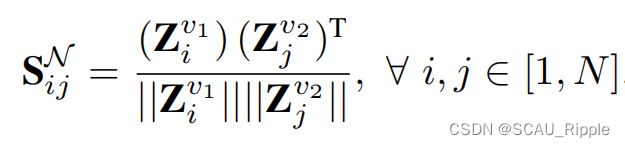
其中![]() 表示第i个结点嵌入的第一个视图与第j个结点的第二个视图的余弦相似性。然后,使得跨视图的样本关联矩阵
表示第i个结点嵌入的第一个视图与第j个结点的第二个视图的余弦相似性。然后,使得跨视图的样本关联矩阵![]() 与单位矩阵
与单位矩阵![]() 相等:
相等:

该式的第一项鼓励![]() 的对角线上的元素等于1,这使得两个不同的视图中每个节点的嵌入彼此一致。第二项鼓励
的对角线上的元素等于1,这使得两个不同的视图中每个节点的嵌入彼此一致。第二项鼓励![]() 的非对角线上的元素等于0,这使得不同结点的视图嵌入相异。这个模块的总体作用是让网络减少结点之间的多余信息,这样学到的特征嵌入更具有区分性。
的非对角线上的元素等于0,这使得不同结点的视图嵌入相异。这个模块的总体作用是让网络减少结点之间的多余信息,这样学到的特征嵌入更具有区分性。
特征级减相关feature-level correlation reduction (FCR):
首先将两个视图的结点嵌入![]() 和
和![]() 映射到簇级嵌入
映射到簇级嵌入 通过一个readout函数
通过一个readout函数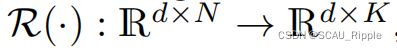 即:
即:

然后计算![]() 和
和![]() 的余弦相似性:
的余弦相似性:
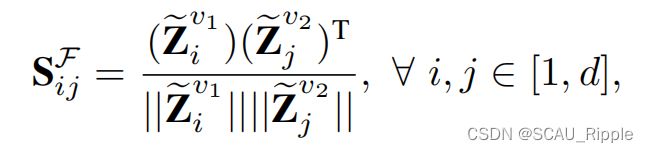
其中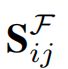 表示一个视图中第i维特征与另一个视图中第j维特征的相似度。与上文相似,令跨视图特征关联矩阵
表示一个视图中第i维特征与另一个视图中第j维特征的相似度。与上文相似,令跨视图特征关联矩阵![]() 与单位矩阵
与单位矩阵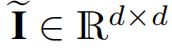 相等:
相等:
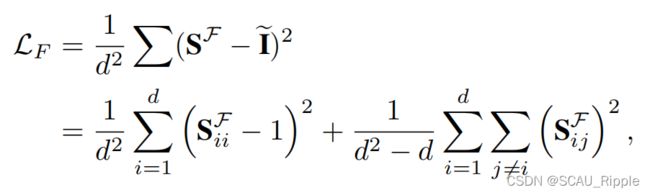
其中d是潜在嵌入向量的维度。该公式表示同一个维度特征在两个增强视图中的特征分别被拉近,而其他视图被推开。
最后用一个线性相加结合两个视图,得到合成的面向聚类的潜在嵌入![]() 用来执行k-means算法。
用来执行k-means算法。

正则化传播:为了避免模型过拟合的情况,本文引入一个正则化传播机制

其中,![]() 是Jensen-Shannon公式。添加了这个正则化之后,浅层网络也可以捕捉长距离信息来避免过拟合。
是Jensen-Shannon公式。添加了这个正则化之后,浅层网络也可以捕捉长距离信息来避免过拟合。
DICR模块目标函数为:
目标函数:全局目标函数由三部分组成:DICR,重构损失,聚类损失。

其中![]() 代表MSE均方误差,然后
代表MSE均方误差,然后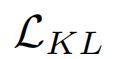 代表Kullback–Leibler散度。
代表Kullback–Leibler散度。
本文算法

消融实验设计
DICR模块的有效性
双路减相关的有效性
超参K敏感度
一句话总结
感觉本文挺有意思的,明明是简单的对比学习的损失函数,可以从图谱的角度解释,并且还有两种图增强的手段
论文好句摘抄(个人向)
(1)Deep graph clustering, which aims to reveal the underlying graph structure and divide the nodes into different groups, has attracted intensive attention in recent years.
(2)Deep graph clustering is a fundamental yet challenging task whose target is to train a neural network for learning representations to divide nodes into different groups without human annotations.
(3)It indicates that representation collapse is still an open problem which is restricting the performance of GCN-based clustering algorithms.