科学计算Python库:Numpy入门
目录
- 前言
- 安装
- 导入
- 创建numpy数组
-
- 1、转换 (Python列表和元组)
- 2、 NumPy 内置创建函数
-
- arange
- zeros
- ones
- random
- linspace
- eye
- 3、原有数组操作
- 4、外部数据读取
- 常用函数
- 常用常量
- 数组维度(形状)编辑
-
- 1、数组重塑
- 2、添加轴
- 3、多维转一维
- 4、矩阵转置
- 索引/切片
-
- 1、基本索引
- 2、高级索引
-
- 整数数组索引
- 布尔数组索引
- 筛选
-
- 1、逻辑筛选
- 2、where筛选
- 3、去除重复值
- 排序
-
- 反转顺序
- 迭代
- 运算
-
- 1、基础运算
-
- 加
- 减
- 元素相乘
- 矩阵相乘
- 2、高级运算
- 3、数学处理函数
- 组合连接
- 拆分
- 数组并集、交集、差集
- Axis轴的个人理解
前言
NumPy 是 Python 中科学计算的基础包。它是一个 Python 库,提供多维数组对象、各种派生对象(例如掩码数组和矩阵)以及用于对数组进行快速操作的各种例程,包括数学、逻辑、形状操作、排序、选择、I/O 、离散傅里叶变换、基本线性代数、基本统计运算、随机模拟等等。科学计算离不开numpy,学习数据分析必先学numpy!!!
本文由浅入深,对numpy进行入门介绍。讲解了创建数组、索引数组、运算等使用。
放一个官方文档:Numpy官方文档
安装
pip install numpy
导入
import numpy as np
创建numpy数组
numpy数组叫ndarray
创建数组总结为四类
1、转换 (Python列表和元组)
a = np.array([2, 3, 4])
2、 NumPy 内置创建函数
( arange、zeros、ones 、random、linspace、eye)
arange
a = np.arange(6) # 1d array
print(a)
# [0 1 2 3 4 5]
b = np.arange(12).reshape(4, 3) # 2d array
print(b)
'''
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
'''
c = np.arange(24).reshape(2, 3, 4) # 3d array
print(c)
'''
[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]
'''
zeros
np.zeros((3, 4))
'''
array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
'''
ones
np.ones((2, 3, 4), dtype=np.int16)
'''
array([[[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]],
[[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]]], dtype=int16)
'''
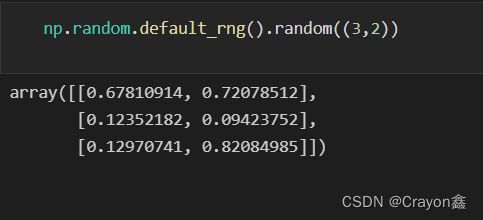
random
random创建数组:
关于numpy的random使用请看我的另一篇文章Numpy教程:Numpy.random使用(新)
# 简单创建
np.random.random((3,2))# 新版写法: np.random.default_rng().random((3,2))
# 根据输入数据打乱数据(不打乱原数据,返回一个新的)
np.random.permutation(data)# 新版写法:np.random.default_rng().permutation(data)
linspace
# 在指定的时间间隔内返回均匀分布的数字。
numpy.linspace(start=, stop=, num=50, axis=0)
# 实例
np.linspace(2.0, 3.0, num=5)
# 输出: array([2. , 2.25, 2.5 , 2.75, 3. ])
eye
eye可以创建E
numpy.eye(N, M=None, k=0, dtype=
k为0默认对角线上为1,k变大,往上偏移
np.eye(2, dtype=int)
array([[1, 0],
[0, 1]])
3、原有数组操作
# 数组重塑
ndarray.reshape()
4、外部数据读取
numpy.read_csv()
numpy.load()
常用函数
# 返回数组的轴(维度)数量
ndarray.ndim
# 数组的每一轴的数量,以元组形式返回。元组的元素个数也即维度数量
ndarray.shape
# 数组全部元素的数量
ndarray.size
# 数组的元素类型。科学计算64位浮点型最为常见
ndarray.dtype
# 数组每一个元素的字节大小
ndarray.itemsize
# 数组重塑
ndarray.reshape()
常用常量
# 正穷大
numpy.inf
# 负无穷大
numpy.NINF
# e
numpy.e
# 圆周率
numpy.pi
# 非数字
numpy.nan
数组维度(形状)编辑
1、数组重塑
# 数组reshape重塑, 不会改变原数组,函数返回修改后的数组
a = np.array([1, 2, 3, 4, 5, 6])
b=a.reshape((2,3)) # 传入的参数最好为元组,元组参数为你想重塑的最终形状
# 使用resize()会改变原数据,不推荐使用
a.resize((2,3))
小技巧:如果想自动推导shape形状,可以使用-1值占个位,计算机会自动处理
a = np.arange(30)
b =a.reshape((2, -1, 3)) # -1 means “whatever is needed”
b.shape # (2, 5,3)
2、添加轴
# 添加轴
a = np.array([1, 2, 3, 4, 5, 6])
b = np.expand_dims(a, axis=1)
print(b.shape)
# (6, 1)
3、多维转一维
ndarray.ravel() # 修改原数组
ndarray.flatten() # 返回一个新数组
4、矩阵转置
ndarray.transpose()
ndarray.T
索引/切片
1、基本索引
ndarray可以像python列表一样被索引
# 一维数组索引
s=np.array([1,2,3,4,5])
print(s)
# array([1, 2, 3, 4, 5])
print(s[2])
# 3
print(s[:2])
# array([1, 2])
# 二维数组索引
s=np.array([1,2,3,4]).reshape((2,2))
print(s)
'''
array([[1, 2],
[3, 4]])
'''
print(s[1,0]) # 等同于 print(s[1][0])
# 3
注意1:对多维数组使用“方括号加逗号”的索引只能用于numpy数组, 对python列表只能使用“多个方括号”分步索引
注意2:使用切片时( : ),要注意以下情况
>>> a=np.arange(4).reshape(2,2)
>>> a
array([[0, 1],
[2, 3]])
>>> a[0:2,0]
array([0, 2])
>>> a[0:2][0]
array([0, 1])
2、高级索引
想用数组索引,数组必须是一维的,这是前提
整数数组索引
y = np.arange(35).reshape(5, 7)
y
# 输出:
'''
array([[ 0, 1, 2, 3, 4, 5, 6],
[ 7, 8, 9, 10, 11, 12, 13],
[14, 15, 16, 17, 18, 19, 20],
[21, 22, 23, 24, 25, 26, 27],
[28, 29, 30, 31, 32, 33, 34]])'''
y[np.array([0, 2, 4]), np.array([0, 1, 2])]
# 输出: array([ 0, 15, 30])
布尔数组索引
x = np.array([[0, 1], [1, 1], [2, 2]])
rowsum = x.sum(-1)
x[rowsum <= 2, :]
# 输出:
'''
array([[0, 1],
[1, 1]])
'''
筛选
1、逻辑筛选
2、where筛选
numpy.where(condition, [x, y, ])
# 如果不加xy参数,返回符合条件的数组
>>> a=np.arange(4)
>>> np.where(a<2) # 等价于a[a<2]
(array([0, 1], dtype=int64),) # 注意,这里是元组
# 如果加了xy参数,根据条件从xy选择值
>>> a=np.arange(4)
>>> np.where(a<2,a,a*2)
array([0, 1, 4, 6])
3、去除重复值
>>> a=np.array([1,4,1,5,6,7,4])
>>> np.unique(a)
array([1, 4, 5, 6, 7])
# 不仅可以去除重复值,还可以统计重复的数量
>>> unique_values, occurrence_count = np.unique(a, return_counts=True)
>>> unique_values
array([1, 4, 5, 6, 7])
>>> occurrence_count
array([2, 2, 1, 1, 1], dtype=int64)
排序
反转顺序
np.flip()
#反转一维数组
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])
np.flip(arr)
# 输出: [8 7 6 5 4 3 2 1]
# 反转二维数组,可以加axis参数,不加则反转全部轴的内容
arr_2d = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
np.flip(arr_2d)
# 输出:
'''[[12 11 10 9]
[ 8 7 6 5]
[ 4 3 2 1]]'''
np.flip(arr_2d, axis=0)
# 输出:
'''[[ 9 10 11 12]
[ 5 6 7 8]
[ 1 2 3 4]]'''
迭代
# 迭代默认是沿第一个轴
>>> a=np.arange(4).reshape((2,2))
>>> for i in a:
... print(i)
...
[0 1]
[2 3]
如果想遍历所有元素,可以把多维数组平铺成一维数组遍历
>>> a=np.arange(4).reshape((2,2))
>>> for i in a.flat:
... print(i)
...
0
1
2
3
运算
1、基础运算
数组的运算可以是形状相同的运算,也可以是多维数组与一维数组运算。
加
+
减
-
元素相乘
# 元素相乘
*
# **是幂次方
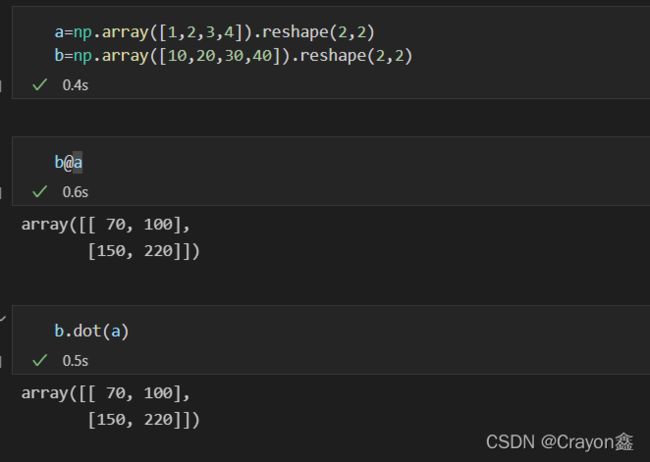
矩阵相乘
@
# 或者
.dot()
广播规则
对不同大小的矩阵进行这些算术运算,但前提是得有一个轴的形状是一样的。在这种情况下,NumPy 将使用其广播规则进行操作。其实就是把少的形状的数组复制成多的形状的数组,再运算。
# 广播规则实例
>>> data = np.array([[1, 2], [3, 4], [5, 6]])
>>> ones_row = np.array([[1, 1]])
>>> data + ones_row # 相加其实就是把ones_row扩展成[[1,1],[1,1],[1,1]],然后再进行运算
array([[2, 3],
[4, 5],
[6, 7]])
2、高级运算
对于多维数组,基础运算已经不能满足使用,以下介绍的都是可以添加参数axis的函数方法。
# 求和
ndarray.sum()
# 最大值
ndarray.min()
# 最小值
ndarray.max()
# 累计求和
ndarray.cumsum()
注意:如果不加axis参数,函数会把多维数组全部拆成一维的,再计算。加上axis参数并赋值,会返回指定轴方向的数组。
3、数学处理函数
# 三角函数
# 指数
numpy.exp(array_like)
# 平方
numpy.sqrt(array_like)
# 向下取整
numpy.floor(array_like)# np.floor([0.2,1.2,2.2]) # print:array([0., 1., 2.])
# 四舍五入
numpy.around(array_like, decimals=0, out=None)# np.around([0.37, 1.64], decimals=1) # print:array([0.4, 1.6])
# 向上取整
numpy.ceil(array_like)
# 转置
numpy.transpose(a, axes=None)[source]
组合连接
# 列堆叠
np.vstack((na1.na2))
# 行堆叠
np.hstack((na1.na2))
# stack 支持axis
np.stack((na1.na2))# axis为0时等于vstack。
#
拆分
# 将一个数组拆分为多个子数组。
numpy.split(ary, indices_or_sections, axis=0)
解释: indices_or_sections可以为整数也可以是一维数组
是整数时,数字是数组划分的数量
是一维数组时,一维数组代表的是划分数组的位置
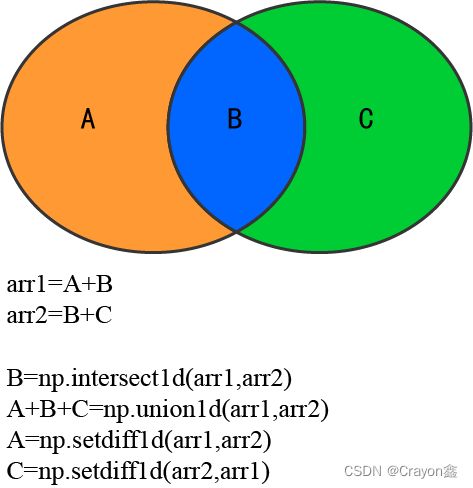
数组并集、交集、差集
注意:以下讲的都是针对一维数组操作的。
如果有两个一维数组,想取出这两个数组都有的数,那么可以使用数据交集函数:np.intersect1d(array1,array2)
如果想返回这两个多有的值,但是重复的不要再加一遍了,可以使用数组并集操作:np.union1d(array1,array2)
如果想返回一个数组中另一个数组没有的,可以使用差集操作:np.setdiff1d(array1,array2)
import numpy as np
# 并集
union=np.union1d(array1,array2)
# 交集
inter=np.intersect1d(array1,array2)
# 差集
diff=np.setdiff1d(array1,array2)
diff=np.setdiff1d(array2,array1)
Axis轴的个人理解
网上有人把axis=0理解为行,axis=1理解为列;这个只能用于理解二维数组,但是科学计算中,需要处理三维甚至多维的数组,“行列解释”无能为力。下面我将从“方括号解释”来解释一下axis的意思,这可以适用于多维数组。
轴(axis)其实可以理解为方括号“[]”,有几个方括号就有几个轴,数轴的顺序是从外往里数的,最外面的方括号是第一个轴(axis=0),次外面的是第二个轴(axis=1)。比如说下面的就是两个轴:
传入的shape为(3,2);意思是第一个轴就是3个,第二个轴就是2个。用“方括号解释”就是第一个括号里的元素有三个,先不管这个元素是什么玩意、多少东西,反正第一个括号就三个元素;然后看第二个参数是2,就是说刚才那个元素有个括号,里面有2个元素,因为没有指定dtype,默认是float64浮点值。