机器学习——决策树剪枝处理
剪枝目的:
首先剪枝(pruning)的目的是为了避免决策树模型的过拟合。因为决策树算法在学习的过程中为了尽可能的正确的分类训练样本,不停地对结点进行划分,因此这会导致整棵树的分支过多,也就导致了过拟合。决策树的剪枝策略最基本的有两种:预剪枝(pre-pruning)和后剪枝(post-pruning):
预剪枝(pre-pruning):预剪枝就是在构造决策树的过程中,先对每个结点在划分前进行估计,若果当前结点的划分不能带来决策树模型泛华性能的提升,则不对当前结点进行划分并且将当前结点标记为叶结点。
后剪枝(post-pruning):后剪枝就是先把整颗决策树构造完毕,然后自底向上的对非叶结点进行考察,若将该结点对应的子树换为叶结点能够带来泛华性能的提升,则把该子树替换为叶结点。
预剪枝:
预剪枝就是在决策树生成过程中,在每次划分时,考虑是否能够带来决策树性能的提升。
如果可以提升决策树的性能则会进行划分。
如果不能则会停止生长。
一般的方法有如下几种:
1. 当树的深度达到一定的规模,则停止生长。
2. 达到当前节点的样本数量小于某个阈值的时候。
3. 计算每次分裂对测试集的准确性提升,当小于某个阈值,或不再提升甚至有所下降时,停止生长。
4. 当信息增益,增益率和基尼指数增益小于某个阈值的时候不在生长。
后剪枝:
后剪枝是先从训练集生成一颗完整的决策树,然后自底向上的对决策树进行剪枝,与预剪枝最大的不同就是:
决策树是否生长完整。
将数据分为训练集和测试集,用训练集去生成一颗完整的决策树,用测试集去剪枝。
该算法将树上的每个节点都作为剪枝的候选对象,通过如下步骤进行剪枝操作:
step1:删除以此节点为根节点的树,
step2:使其成为叶子结点,赋予该节点最常见的分类
step3:对比删除前和删除后的性能是否有所提升,如果有则进行删除,没有则保留。
代码实现:
数据集:
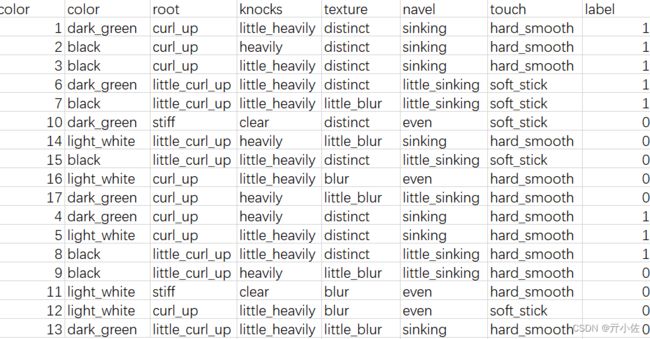
其中,前11个数据用作训练集(1,2,3,6,7,10,14,15,16,17,4)后6个数据用作测试集(5,8,9,11,12,13)
预剪枝:
预剪枝是在决策树生成过程中,在划分节点时,若该节点的划分没有提高其在训练集上的准确率,则不进行划分。
# -*- coding: utf-8 -*-
from numpy import *
import numpy as np
import pandas as pd
from math import log
import operator
import copy
import re
#计算数据集的基尼指数
def calcGini(dataSet):
numEntries=len(dataSet)
labelCounts={}
#给所有可能分类创建字典
for featVec in dataSet:
currentLabel=featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel]=0
labelCounts[currentLabel]+=1
Gini=1.0
#以2为底数计算香农熵
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
Gini-=prob*prob
return Gini
#对离散变量划分数据集,取出该特征取值为value的所有样本
def splitDataSet(dataSet,axis,value):
retDataSet=[]
for featVec in dataSet:
if featVec[axis]==value:
reducedFeatVec=featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
#对连续变量划分数据集,direction规定划分的方向,
#决定是划分出小于value的数据样本还是大于value的数据样本集
def splitContinuousDataSet(dataSet,axis,value,direction):
retDataSet=[]
for featVec in dataSet:
if direction==0:
if featVec[axis]>value:
reducedFeatVec=featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
else:
if featVec[axis]<=value:
reducedFeatVec=featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
#选择最好的数据集划分方式
def chooseBestFeatureToSplit(dataSet,labels):
numFeatures=len(dataSet[0])-1
bestGiniIndex=100000.0
bestFeature=-1
bestSplitDict={}
for i in range(numFeatures):
featList=[example[i] for example in dataSet]
#对连续型特征进行处理
if type(featList[0]).__name__=='float' or type(featList[0]).__name__=='int':
#产生n-1个候选划分点
sortfeatList=sorted(featList)
splitList=[]
for j in range(len(sortfeatList)-1):
splitList.append((sortfeatList[j]+sortfeatList[j+1])/2.0)
bestSplitGini=10000
slen=len(splitList)
#求用第j个候选划分点划分时,得到的信息熵,并记录最佳划分点
for j in range(slen):
value=splitList[j]
newGiniIndex=0.0
subDataSet0=splitContinuousDataSet(dataSet,i,value,0)
subDataSet1=splitContinuousDataSet(dataSet,i,value,1)
prob0=len(subDataSet0)/float(len(dataSet))
newGiniIndex+=prob0*calcGini(subDataSet0)
prob1=len(subDataSet1)/float(len(dataSet))
newGiniIndex+=prob1*calcGini(subDataSet1)
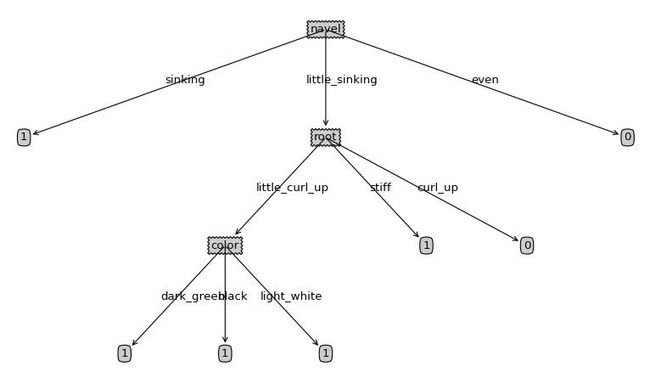
if newGiniIndex预剪枝结果:
后剪枝:
后剪枝决策树先生成一棵完整的决策树,再从底往顶进行剪枝处理。在以下代码中,使用的是深度优先搜索。
#由于在Tree中,连续值特征的名称以及改为了 feature<=value的形式
#因此对于这类特征,需要利用正则表达式进行分割,获得特征名以及分割阈值
def classify(inputTree,featLabels,testVec):
firstStr=inputTree.keys()[0]
if '<=' in firstStr:
featvalue=float(re.compile("(<=.+)").search(firstStr).group()[2:])
featkey=re.compile("(.+<=)").search(firstStr).group()[:-2]
secondDict=inputTree[firstStr]
featIndex=featLabels.index(featkey)
if testVec[featIndex]<=featvalue:
judge=1
else:
judge=0
for key in secondDict.keys():
if judge==int(key):
if type(secondDict[key]).__name__=='dict':
classLabel=classify(secondDict[key],featLabels,testVec)
else:
classLabel=secondDict[key]
else:
secondDict=inputTree[firstStr]
featIndex=featLabels.index(firstStr)
for key in secondDict.keys():
if testVec[featIndex]==key:
if type(secondDict[key]).__name__=='dict':
classLabel=classify(secondDict[key],featLabels,testVec)
else:
classLabel=secondDict[key]
return classLabel
#测试决策树正确率
def testing(myTree,data_test,labels):
error=0.0
for i in range(len(data_test)):
if classify(myTree,labels,data_test[i])!=data_test[i][-1]:
error+=1
#print 'myTree %d' %error
return float(error)
#测试投票节点正确率
def testingMajor(major,data_test):
error=0.0
for i in range(len(data_test)):
if major!=data_test[i][-1]:
error+=1
#print 'major %d' %error
return float(error)
#后剪枝
def postPruningTree(inputTree,dataSet,data_test,labels):
firstStr=inputTree.keys()[0]
secondDict=inputTree[firstStr]
classList=[example[-1] for example in dataSet]
featkey=copy.deepcopy(firstStr)
if '<=' in firstStr:
featkey=re.compile("(.+<=)").search(firstStr).group()[:-2]
featvalue=float(re.compile("(<=.+)").search(firstStr).group()[2:])
labelIndex=labels.index(featkey)
temp_labels=copy.deepcopy(labels)
del(labels[labelIndex])
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
if type(dataSet[0][labelIndex]).__name__=='str':
inputTree[firstStr][key]=postPruningTree(secondDict[key],\
splitDataSet(dataSet,labelIndex,key),splitDataSet(data_test,labelIndex,key),copy.deepcopy(labels))
else:
inputTree[firstStr][key]=postPruningTree(secondDict[key],\
splitContinuousDataSet(dataSet,labelIndex,featvalue,key),\
splitContinuousDataSet(data_test,labelIndex,featvalue,key),\
copy.deepcopy(labels))
if testing(inputTree,data_test,temp_labels)<=testingMajor(majorityCnt(classList),data_test):
return inputTree
return majorityCnt(classList)
data=df.values[:11,1:].tolist()
data_test=df.values[11:,1:].tolist()
labels=df.columns.values[1:-1].tolist()
myTree=postPruningTree(myTree,data,data_test,labels)
import plotTree
plotTree.createPlot(myTree)
#由于在Tree中,连续值特征的名称以及改为了 feature<=value的形式
#因此对于这类特征,需要利用正则表达式进行分割,获得特征名以及分割阈值
def classify(inputTree,featLabels,testVec):
firstStr=inputTree.keys()[0]
if '<=' in firstStr:
featvalue=float(re.compile("(<=.+)").search(firstStr).group()[2:])
featkey=re.compile("(.+<=)").search(firstStr).group()[:-2]
secondDict=inputTree[firstStr]
featIndex=featLabels.index(featkey)
if testVec[featIndex]<=featvalue:
judge=1
else:
judge=0
for key in secondDict.keys():
if judge==int(key):
if type(secondDict[key]).__name__=='dict':
classLabel=classify(secondDict[key],featLabels,testVec)
else:
classLabel=secondDict[key]
else:
secondDict=inputTree[firstStr]
featIndex=featLabels.index(firstStr)
for key in secondDict.keys():
if testVec[featIndex]==key:
if type(secondDict[key]).__name__=='dict':
classLabel=classify(secondDict[key],featLabels,testVec)
else:
classLabel=secondDict[key]
return classLabel
#测试决策树正确率
def testing(myTree,data_test,labels):
error=0.0
for i in range(len(data_test)):
if classify(myTree,labels,data_test[i])!=data_test[i][-1]:
error+=1
#print 'myTree %d' %error
return float(error)
#测试投票节点正确率
def testingMajor(major,data_test):
error=0.0
for i in range(len(data_test)):
if major!=data_test[i][-1]:
error+=1
#print 'major %d' %error
return float(error)
#后剪枝
def postPruningTree(inputTree,dataSet,data_test,labels):
firstStr=inputTree.keys()[0]
secondDict=inputTree[firstStr]
classList=[example[-1] for example in dataSet]
featkey=copy.deepcopy(firstStr)
if '<=' in firstStr:
featkey=re.compile("(.+<=)").search(firstStr).group()[:-2]
featvalue=float(re.compile("(<=.+)").search(firstStr).group()[2:])
labelIndex=labels.index(featkey)
temp_labels=copy.deepcopy(labels)
del(labels[labelIndex])
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
if type(dataSet[0][labelIndex]).__name__=='str':
inputTree[firstStr][key]=postPruningTree(secondDict[key],\
splitDataSet(dataSet,labelIndex,key),splitDataSet(data_test,labelIndex,key),copy.deepcopy(labels))
else:
inputTree[firstStr][key]=postPruningTree(secondDict[key],\
splitContinuousDataSet(dataSet,labelIndex,featvalue,key),\
splitContinuousDataSet(data_test,labelIndex,featvalue,key),\
copy.deepcopy(labels))
if testing(inputTree,data_test,temp_labels)<=testingMajor(majorityCnt(classList),data_test):
return inputTree
return majorityCnt(classList)
data=df.values[:11,1:].tolist()
data_test=df.values[11:,1:].tolist()
labels=df.columns.values[1:-1].tolist()
myTree=postPruningTree(myTree,data,data_test,labels)
import plotTree
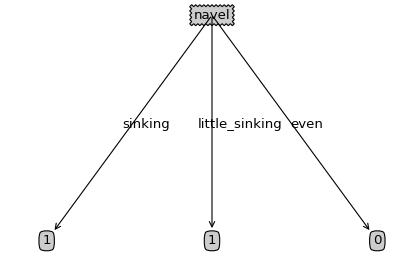
plotTree.createPlot(myTree)后剪枝结果: