爬球赛回放
1.导入
from requests_html import HTMLSession
from requests_html import HTML
import json
import pyprind2.分析网站
通过用户的输入感兴趣的球队获取相应的视频
types = input('请输入你感兴趣的球队:')
if type(types) == str:
pass
else: # type==list
pass3.获取一到四节视频的网址
ptext = p.xpath('.//a//text()')
if ptext and '微博国语' in ptext[0] and '第' in ptext[0]:4.分析微博的Fetch/XHR
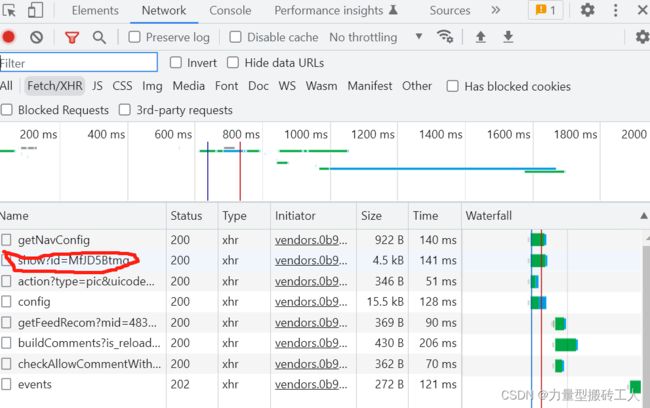
'https://weibo.com/ajax/statuses/show?id=' + 刚才url的后缀

可以发现视频的url 在里面
def get_video(url, title):
suffix = url.split('/')[-1]
new_url = 'https://weibo.com/ajax/statuses/show?id=' + suffix
response_f3 = s.get(new_url, headers=headers)
if response_f3.status_code == 200:
dici = json.loads(response_f3.text)
video_url = dici['page_info']['media_info']['stream_url_hd']
r = s.get(video_url, headers=headers)
with open('每日NBA/'+title+'.mp4', 'wb+') as f:
f.write(r.content)
f.close()
pbar.update()打包成exe
Pyinstaller -F demo.py
执行结果:
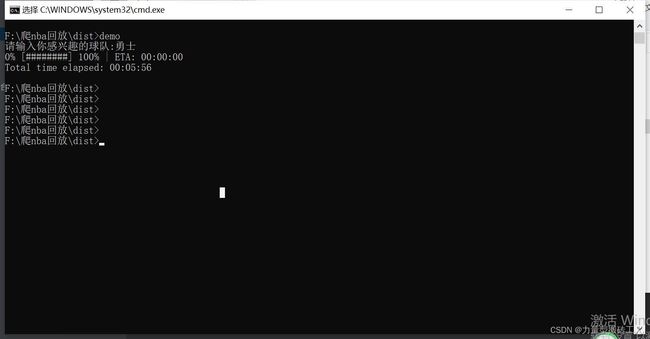

打包的解释器版本一定要统一
总结:要多观察url之间的联系,找出拼接的规律