MLOps极致细节:19. MLFlow 与 Pytorch 的使用案例1:mlflow.pytorch MNIST识别
MLOps极致细节:19. MLFlow 与 Pytorch 的使用案例1:mlflow.pytorch MNIST识别
本案例解释了如何在Pytorch中使用MLFlow,在MNIST中的两个案例。
- 解释
mlflow.pytorch的具体使用方式; - 解释
pl.LightningModule与pl.LightningDataModule的具体使用方式; - 解释
mlflow run以及mlflow ui的具体使用方式; - 通过MNIST的两个案例解释如何在pyTorch中使用mlFlow,以及结果。
运行环境:
- 平台:Win10。
- IDE:Visual Studio Code
- 需要预装:Anaconda3
- MLFlow当前版本:1.25.1
- 代码
觉得写的可以的话点个赞,收藏,加关注哦。
文章目录
- MLOps极致细节:19. MLFlow 与 Pytorch 的使用案例1:mlflow.pytorch MNIST识别
-
- 1 关于 MLFlow
- 2 关于如何在PyTorch中使用MLFlow
- 3 关于代码的运行
-
- 3.1 第一种运行代码方式:本地创建虚拟环境运行
- 3.2 第二种运行代码方式:mlflow run 指令运行
- 4 概念解释
-
- 4.1 mlflow.pytorch.autolog
- 4.2 pl.LightningModule
- 4.3 pl.LightningDataModule
- 4.4 MLproject 以及 conda.yaml 文件
- 5 一个简单的案例
-
- 5.1 代码
- 5.2 结果
- 6 一个较为完整的MNIST案例
1 关于 MLFlow
MLFlow是一个能够覆盖机器学习全流程(从数据准备到模型训练到最终部署)的新平台。它一共有四大模块(如下为官网的原文以及翻译):
- MLflow Tracking:如何通过API的形式管理实验的参数、代码、结果,并且通过UI的形式做对比。
- MLflow Projects:以可重用、可复制的形式打包ML代码,以便与其他数据科学家共享或部署到生产环境(MLflow项目)。
- MLflow Models:管理和部署从各种ML库到各种模型服务和推理平台(MLflow模型)的模型。
- MLflow Model Registry:提供一个中央模型存储,以协同管理MLflow模型的整个生命周期,包括模型版本控制、阶段转换和注释(MLflow模型注册表)。
在这个系列的前半部分,我们对MLFlow做了详细的介绍,以及每一个模块的案例讲解,这里不再赘述。
2 关于如何在PyTorch中使用MLFlow
mlflow.pytorch模块提供了一个用于记录和加载 PyTorch 模型的 API。
需要注意的是,MLFlow 无法直接和PyTorch一起使用,我们需要先装一下pytorch_lightning,当我们调用 pytorch_lightning.Trainer() 的 fit 方法时会执行自动记录(mlflow.pytorch.autolog)。
3 关于代码的运行
有两种种运行代码的方式,这里我们也会一一列举。如果我们是初学者,建议先尝试第一种方式。
3.1 第一种运行代码方式:本地创建虚拟环境运行
首先,我们在Windows的平台下安装Anaconda3。具体的安装步骤此处略过,参见Anaconda的官方文档。
安装完后,新建虚拟环境。在VSCode,使用conda create -n your_env_name python=X.X(2.7、3.6等)命令创建python版本为X.X、名字为your_env_name的虚拟环境。
这里我们输入conda create -n mlFlowEx python=3.8.2。
安装完默认的依赖后,我们进入虚拟环境:conda activate mlFlowEx。注意,如果需要退出,则输入conda deactivate。另外,如果Terminal没有成功切换到虚拟环境,可以尝试conda init powershell,然后重启terminal。
然后,我们在虚拟环境中下载好相关依赖:pip3 install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple。
这个案例的依赖包括:
mlflow==1.25.1
torchvision>=0.9.1
torch>=1.9.0
pytorch-lightning==1.6.1
关于mlflow的版本,1.23.1应该也是可以运行的。
我们将代码下载到本地:git clone https://gitee.com/yichaoyyds/mlflow-ex-pytorch.git。进入文件夹MNIST_pytorch后,我们看到几个.py文件,输入python mnist_ex2.py运行代码。
3.2 第二种运行代码方式:mlflow run 指令运行
这里我们不需要在本地新建一个虚拟环境(mlflow run 指令会自动新建),我们将代码下载到本地,进入文件夹MNIST_pytorch后,我们在terminal运行mlflow run -e ex2 .。注意,最后有一个.不要忘记,这个.的意思是当前文件夹路径。在之前的系列文章中,我们解释过,运行mlflow run之后,系统会去寻找指定文件夹下的MLproject文件。此文件包含了我们需要运行的脚本指令。
4 概念解释
在解释详细代码之前(其实代码很简单),我们有四个重要的概念(函数)需要解释。
4.1 mlflow.pytorch.autolog
mlflow.pytorch的其他函数我们都可以先不看,只要在train代码之前加上这行,mlflow就可以自动开始运行,包括保存artifacts,metrics,params,tag值。有很多值是自动生成的。在结果这个章节中,我们会详细解释。这里我们先解释mlflow.pytorch.autolog函数。
一般在代码中,我们直接使用mlflow.pytorch.autolog()即可,因为函数中的参数都有默认值,我们一般使用默认值就可以。这里我们来详细过一遍其中重要的参数。完整的函数定义如下:
mlflow.pytorch.autolog(log_every_n_epoch=1, log_every_n_step=None, log_models=True, disable=False, exclusive=False, disable_for_unsupported_versions=False, silent=False, registered_model_name=None)
log_every_n_epoch: 如果指定,则每 n 个 epoch 记录一次 metric 值。 默认情况下,每个 epoch 后都会记录 metric 值;log_models:如果为True,则经过训练的模型将记录在 MLflow artifacts 路径下。 如果为 False,则不记录经过训练的模型。注意,这里只会记录一个model,应该是性能最好的那个model。在Microsoft Azure MLOps中,它会记录每一个epoch的model。所以从性能角度上,Azure MLOps工具确实强大,但我们可以根据实际需要进行选择,毕竟Azure MLOps是付费的,而MLFlow是免费的。如果对 Azure MLOps 感兴趣,也可以翻看这个系列的其他文章。disable:如果为 True,则禁用 PyTorch Lightning 自动日志记录集成功能。 如果为 False,则启用。当PyTorch Lightning 在进行模型训练(进行初始化)的时候,Lightning 在后台使用 TensorBoard 记录器,并将日志存储到目录中(默认情况下在Lightning_logs/中)。相关链接。我们可以将这个默认日志功能关闭。这里我们建议开着自动日志功能,因为如果关闭,MLFlow的artifacts,metrics,params,tag默认保存的参数就无法保存;
4.2 pl.LightningModule
对于 PyTorch Lightning,有两个函数是至关重要,一个是pl.LightningModule,一个是pl.LightningDataModule。前者的包含了训练/验证/预测/优化的所有模块,后者则是数据集读取模块。我们通过PyTorch Lightning进行模型训练的时候,通常会继承这两个类。目前我对 PyTorch Lightning 不是很了解,所以这里我作为一个初学者的角度,针对这个案例进行一些相关的解读。
关于pl.LightningModule,和我们这个案例相关的函数包括:
forward,作用和torch.nn.Module.forward()一样,这里我们不再赘述;training_step,我们计算并返回训练损失和一些额外的metrics。validation_step,我们计算并返回验证损失和一些额外的metrics。test_step,我们计算并返回测试损失和一些额外的metrics。validation_epoch_end,在验证epoch结束后,计算这个epoch的平均验证accuracy。test_epoch_end,在测试epoch结束后,计算计算这个epoch的平均测试accuracy。configure_optimizers,选择要在优化中使用的优化器和学习率调度器。
此网页有详细的描述,这里不再赘述。
4.3 pl.LightningDataModule
pl.LightningDataModule 标准化了训练、验证、测试集的拆分、数据准备和转换。主要优点是一致的数据拆分、数据准备和跨模型转换,一个例子如下:
class MyDataModule(LightningDataModule):
def __init__(self):
super().__init__()
def prepare_data(self):
# download, split, etc...
# only called on 1 GPU/TPU in distributed
def setup(self, stage):
# make assignments here (val/train/test split)
# called on every process in DDP
def train_dataloader(self):
train_split = Dataset(...)
return DataLoader(train_split)
def val_dataloader(self):
val_split = Dataset(...)
return DataLoader(val_split)
def test_dataloader(self):
test_split = Dataset(...)
return DataLoader(test_split)
def teardown(self):
# clean up after fit or test
# called on every process in DDP
4.4 MLproject 以及 conda.yaml 文件
如果我们要使用mlflow run指令,那么我们就需要明白MLproject以及conda.yaml文件的作用。
MLproject文件:
name: mnist-example
conda_env: conda.yaml
entry_points:
ex1:
command: |
python mnist_ex1.py
ex2:
parameters:
max_epochs: {type: int, default: 5}
gpus: {type: int, default: 0}
strategy: {type str, default: "None"}
batch_size: {type: int, default: 64}
num_workers: {type: int, default: 3}
learning_rate: {type: float, default: 0.001}
patience: {type int, default: 3}
mode: {type str, default: 'min'}
verbose: {type bool, default: True}
monitor: {type str, default: 'val_loss'}
command: |
python mnist_ex2.py
--max_epochs {max_epochs}
--gpus {gpus}
--strategy {strategy}
--batch_size {batch_size}
--num_workers {num_workers}
--lr {learning_rate}
--es_patience {patience}
--es_mode {mode}
--es_verbose {verbose}
--es_monitor {monitor}
main:
command: |
python mnist_ex1.py
这里,我们有两个例子,Python脚本分别是mnist_ex1.py以及mnist_ex2.py,这里对应两个entry points:ex1以及ex2。如果我们需要调用前者,那么在terminal中,我们需要输入mlflow run -e ex1 .。如果我们不加-c选项,比如mlflow run .,则默认调用main下面的指令。
conda.yaml文件
channels:
- conda-forge
dependencies:
- python=3.8.2
- pip
- pip:
- mlflow==1.25.1
- torchvision>=0.9.1
- torch>=1.9.0
- pytorch-lightning==1.6.1
- -i https://pypi.tuna.tsinghua.edu.cn/simple
包含了这个项目的依赖项。当我们第一次运行mlflow run .的时候,系统会自动新建一个虚拟环境,安装对应的依赖(对应conda.yaml文件),最后运行对应的代码(对应MLproject文件)。
5 一个简单的案例
5.1 代码
首先我们介绍一个简单的案例,这个案例源于MLFlow官网。案例的目的在于通过 Pytorch Lightning 来训练一个简单的神经网络,并把MLFlow整合进去。Python Script在mnist_ex1.py中。
我们首先新建一个MNISTModel,继承于pl.LightningModule。这个类中,我们仅定义了向前传播(forward),训练(training_step),以及优化器的选择(configure_optimizers)。
class MNISTModel(pl.LightningModule):
def __init__(self):
super(MNISTModel, self).__init__()
self.l1 = torch.nn.Linear(28 * 28, 10)
def forward(self, x):
return torch.relu(self.l1(x.view(x.size(0), -1)))
def training_step(self, batch, batch_nb):
x, y = batch
loss = F.cross_entropy(self(x), y)
output = self.forward(x)
_, y_hat = torch.max(output, dim=1)
train_acc = accuracy(y_hat.cpu(), y.cpu())
#acc = accuracy(loss, y)
# Use the current of PyTorch logger
self.log("train_loss", loss, on_epoch=True)
self.log("train_acc", train_acc, on_epoch=True)
return loss
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=0.02)
接下来,我们就导入数据,进行训练,代码如下:
# Initialize our model
mnist_model = MNISTModel()
# Initialize DataLoader from MNIST Dataset
train_ds = MNIST("dataset", train=True,
download=True, transform=transforms.ToTensor())
train_loader = DataLoader(train_ds, batch_size=32)
# Initialize a trainer
trainer = pl.Trainer(max_epochs=20, progress_bar_refresh_rate=20)
# Auto log all MLflow entities
mlflow.pytorch.autolog()
# Train the model
with mlflow.start_run() as run:
trainer.fit(mnist_model, train_loader)
# fetch the auto logged parameters and metrics
print_auto_logged_info(mlflow.get_run(run_id=run.info.run_id))
另外,mnist_ex1_test.py主要解释了如何通过mlflow导入训练好的模型。代码如下:
import torch
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
from torchvision.datasets import MNIST
import mlflow.pytorch
'''
此段代码主要用于解释如何使用`mlflow.pytorch.load_model`
'''
# load and normalize the dataset
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)),
])
df_test = MNIST("dataset", download=True, train=False, transform=transform)
test_dataloader = DataLoader(df_test, batch_size=32, shuffle=True)
model_uri = 'runs:/42926a185dd34b6abfec60e1f411c972/model'
loaded_model = mlflow.pytorch.load_model(model_uri)
predicted=[]
gt=[]
acc = 0
correct_num = 0
print(len(test_dataloader))
with torch.no_grad():
n_correct=0
n_samples=0
for images,labels in test_dataloader:
images=images.reshape(-1,784)
output=loaded_model(images) #applying the model we have built
labels=labels
_,prediction=torch.max(output,1)
res = sum(x == y for x, y in zip(prediction.tolist(), labels.tolist()))
acc += res/len(labels)
#print(predicted)
#print(gt)
print("accuracy: ",acc/len(test_dataloader))
5.2 结果
这个案例是极其简单的,但通过这个案例,我们可以很清晰地看到 mlflow 在其中所起到的作用。我们来运行一下,这里我们选择第二种运行方式,mlflow run -e ex2 .,我把Terminal中打印的结果附在下面:
2022/05/06 16:35:24 INFO mlflow.utils.conda: Conda environment mlflow-2b2f5dd8758e4eb69f2ca3021cfd0c5b24edcc50 already exists.
2022/05/06 16:35:24 INFO mlflow.projects.utils: === Created directory C:\Users\gugut\AppData\Local\Temp\tmpvkjsu2ia for downloading remote URIs passed to arguments of type 'path' ===
2022/05/06 16:35:24 INFO mlflow.projects.backend.local: === Running command 'conda activate mlflow-2b2f5dd8758e4eb69f2ca3021cfd0c5b24edcc50 && python mnist_ex1.py
' in run with ID '11910f9b05044128a19934fbd632f72f' ===
C:\Users\gugut\anaconda3\envs\mlflow-2b2f5dd8758e4eb69f2ca3021cfd0c5b24edcc50\lib\site-packages\pytorch_lightning\trainer\connectors\callback_connector.py:96: LightningDeprecationWarning: Setting
`Trainer(progress_bar_refresh_rate=20)` is deprecated in v1.5 and will be removed in v1.7. Please
pass `pytorch_lightning.callbacks.progress.TQDMProgressBar` with `refresh_rate` directly to the Trainer's `callbacks` argument instead. Or, to disable the progress bar pass `enable_progress_bar =
False` to the Trainer.
rank_zero_deprecation(
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
2022/05/06 16:35:30 WARNING mlflow.utils.autologging_utils: You are using an unsupported version of pytorch. If you encounter errors during autologging, try upgrading / downgrading pytorch to a supported version, or try upgrading MLflow.
| Name | Type | Params
--------------------------------
0 | l1 | Linear | 7.9 K
--------------------------------
7.9 K Trainable params
0 Non-trainable params
7.9 K Total params
0.031 Total estimated model params size (MB)
C:\Users\gugut\anaconda3\envs\mlflow-2b2f5dd8758e4eb69f2ca3021cfd0c5b24edcc50\lib\site-packages\pytorch_lightning\trainer\connectors\data_connector.py:240: PossibleUserWarning: The dataloader, train_dataloader, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 8 which is the number of cpus on this machine) in the `DataLoader` init to improve performance.
rank_zero_warn(
Epoch 19: 100%|██████████████████████████| 1875/1875 [06:29<00:00, 4.81it/s, loss=0.74, v_num=3]
2022/05/06 16:42:05 WARNING mlflow.utils.autologging_utils: MLflow autologging encountered a warning: "C:\Users\gugut\anaconda3\envs\mlflow-2b2f5dd8758e4eb69f2ca3021cfd0c5b24edcc50\lib\site-packages\_distutils_hack\__init__.py:30: UserWarning: Setuptools is replacing distutils."
run_id: 11910f9b05044128a19934fbd632f72f
artifacts: ['model/MLmodel', 'model/conda.yaml', 'model/data', 'model/requirements.txt']
params: {'amsgrad': 'False', 'betas': '(0.9, 0.999)', 'epochs': '20', 'eps': '1e-08', 'lr': '0.02', 'maximize': 'False', 'optimizer_name': 'Adam', 'weight_decay': '0'}
metrics: {'train_acc': 0.70496666431427, 'train_acc_epoch': 0.70496666431427, 'train_acc_step': 0.90625, 'train_loss': 0.8139140605926514, 'train_loss_epoch': 0.8139140605926514, 'train_loss_step': 0.22626501321792603}
tags: {'Mode': 'training'}
2022/05/06 16:42:05 INFO mlflow.projects: === Run (ID '11910f9b05044128a19934fbd632f72f') succeeded ===
你看,首先,系统会去寻找相关的虚拟环境是否已经存在。由于我这里已经运行过代码,所以系统找到了对应的虚拟环境:mlflow.utils.conda: Conda environment mlflow-2b2f5dd8758e4eb69f2ca3021cfd0c5b24edcc50 already exists.。然后系统进入这个虚拟环境并且运行代码:conda activate mlflow-2b2f5dd8758e4eb69f2ca3021cfd0c5b24edcc50 && python mnist_ex1.py。运行代码后,mlFlow会新建一个run id,这里是11910f9b05044128a19934fbd632f72f。
在代码中,有一个print_auto_logged_info函数,它的功能就是打印mlFlow相关,比如run_id,artifacts,metrics,params,tag等。这里打印出来的结果如下:
run_id: 11910f9b05044128a19934fbd632f72f
artifacts: ['model/MLmodel', 'model/conda.yaml', 'model/data', 'model/requirements.txt']
params: {'amsgrad': 'False', 'betas': '(0.9, 0.999)', 'epochs': '20', 'eps': '1e-08', 'lr': '0.02', 'maximize': 'False', 'optimizer_name': 'Adam', 'weight_decay': '0'}
metrics: {'train_acc': 0.70496666431427, 'train_acc_epoch': 0.70496666431427, 'train_acc_step': 0.90625, 'train_loss': 0.8139140605926514, 'train_loss_epoch': 0.8139140605926514, 'train_loss_step': 0.22626501321792603}
tags: {'Mode': 'training'}
我们在代码中实际上并没有保存那么多参数,可见,通过mlflow.pytorch.autolog()函数,mlFlow自动从pyTorch Lightning(应该是代码运行后生产的日志中)获取了上面这些参数。
我们来运行一下mlflow ui,看看可视化的结果:
打开默认的IP:http://127.0.0.1:5000,点进对应的run列表(这里是11910f9b05044128a19934fbd632f72f),我们可以看到
Parameters的罗列:

Matrics的罗列:
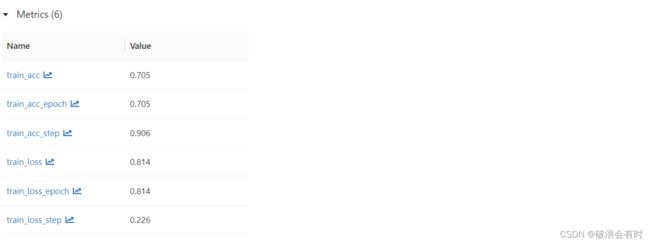
我们点进去train_acc_epoch看一下,可以看到每一个epoch结束后,mlFlow都会记录一个train accuracy值,在这个UI中可以展示出来。当然,这张图accuracy值比较差,因为毕竟只是简单地跑了一下代码,也没有加validation和test数据:
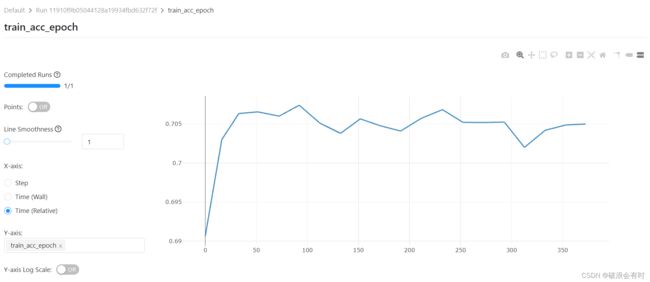
我们点进去train_loss_epoch看一下结果

Artifacts下面记录了最后训练完后保存的模型,以及依赖,模型说明,等等文件:

6 一个较为完整的MNIST案例
这里就不再赘述,直接上代码:
import pytorch_lightning as pl
import mlflow.pytorch
import os
import torch
from argparse import ArgumentParser
from pytorch_lightning.callbacks.early_stopping import EarlyStopping
from pytorch_lightning.callbacks import ModelCheckpoint
from pytorch_lightning.callbacks import LearningRateMonitor
from torch.nn import functional as F
from torch.utils.data import DataLoader, random_split
from torchvision import datasets, transforms
from mlflow.tracking import MlflowClient
try:
from torchmetrics.functional import accuracy
except ImportError:
from pytorch_lightning.metrics.functional import accuracy
class MNISTDataModule(pl.LightningDataModule):
def __init__(self, **kwargs):
"""
Initialization of inherited lightning data module
"""
super(MNISTDataModule, self).__init__()
self.df_train = None
self.df_val = None
self.df_test = None
self.train_data_loader = None
self.val_data_loader = None
self.test_data_loader = None
self.args = kwargs
# transforms for images
self.transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
)
def setup(self, stage=None):
"""
Downloads the data, parse it and split the data into train, test, validation data
:param stage: Stage - training or testing
"""
self.df_train = datasets.MNIST(
"dataset", download=True, train=True, transform=self.transform
)
self.df_train, self.df_val = random_split(self.df_train, [55000, 5000])
self.df_test = datasets.MNIST(
"dataset", download=True, train=False, transform=self.transform
)
def create_data_loader(self, df):
"""
Generic data loader function
:param df: Input tensor
:return: Returns the constructed dataloader
"""
return DataLoader(
df, batch_size=self.args["batch_size"], num_workers=self.args["num_workers"]
)
def train_dataloader(self):
"""
:return: output - Train data loader for the given input
"""
return self.create_data_loader(self.df_train)
def val_dataloader(self):
"""
:return: output - Validation data loader for the given input
"""
return self.create_data_loader(self.df_val)
def test_dataloader(self):
"""
:return: output - Test data loader for the given input
"""
return self.create_data_loader(self.df_test)
class LightningMNISTClassifier(pl.LightningModule):
def __init__(self, **kwargs):
"""
Initializes the network
"""
super(LightningMNISTClassifier, self).__init__()
# mnist images are (1, 28, 28) (channels, width, height)
self.optimizer = None
self.scheduler = None
self.layer_1 = torch.nn.Linear(28 * 28, 128)
self.layer_2 = torch.nn.Linear(128, 256)
self.layer_3 = torch.nn.Linear(256, 10)
self.args = kwargs
@staticmethod
def add_model_specific_args(parent_parser):
parser = ArgumentParser(parents=[parent_parser], add_help=False)
parser.add_argument(
"--batch_size",
type=int,
default=64,
metavar="N",
help="input batch size for training (default: 64)",
)
parser.add_argument(
"--num_workers",
type=int,
default=3,
metavar="N",
help="number of workers (default: 3)",
)
parser.add_argument(
"--lr",
type=float,
default=0.001,
metavar="LR",
help="learning rate (default: 0.001)",
)
return parser
def forward(self, x):
"""
:param x: Input data
:return: output - mnist digit label for the input image
"""
batch_size = x.size()[0]
# (b, 1, 28, 28) -> (b, 1*28*28)
x = x.view(batch_size, -1)
# layer 1 (b, 1*28*28) -> (b, 128)
x = self.layer_1(x)
x = torch.relu(x)
# layer 2 (b, 128) -> (b, 256)
x = self.layer_2(x)
x = torch.relu(x)
# layer 3 (b, 256) -> (b, 10)
x = self.layer_3(x)
# probability distribution over labels
x = torch.log_softmax(x, dim=1)
return x
def cross_entropy_loss(self, logits, labels):
"""
Initializes the loss function
:return: output - Initialized cross entropy loss function
"""
return F.nll_loss(logits, labels)
def training_step(self, train_batch, batch_idx):
"""
Training the data as batches and returns training loss on each batch
:param train_batch: Batch data
:param batch_idx: Batch indices
:return: output - Training loss
"""
x, y = train_batch
logits = self.forward(x)
loss = self.cross_entropy_loss(logits, y)
self.log("train_loss", loss, on_epoch=True)
return {"loss": loss}
def validation_step(self, val_batch, batch_idx):
"""
Performs validation of data in batches
:param val_batch: Batch data
:param batch_idx: Batch indices
:return: output - valid step loss
"""
x, y = val_batch
logits = self.forward(x)
loss = self.cross_entropy_loss(logits, y)
#self.log("validation_loss", loss, on_epoch=True)
return {"val_step_loss": loss}
def validation_epoch_end(self, outputs):
"""
Computes average validation accuracy
:param outputs: outputs after every epoch end
:return: output - average valid loss
"""
avg_loss = torch.stack([x["val_step_loss"] for x in outputs]).mean()
self.log("val_loss", avg_loss, sync_dist=True)
def test_step(self, test_batch, batch_idx):
"""
Performs test and computes the accuracy of the model
:param test_batch: Batch data
:param batch_idx: Batch indices
:return: output - Testing accuracy
"""
x, y = test_batch
output = self.forward(x)
_, y_hat = torch.max(output, dim=1)
test_acc = accuracy(y_hat.cpu(), y.cpu())
return {"test_acc": test_acc}
def test_epoch_end(self, outputs):
"""
Computes average test accuracy score
:param outputs: outputs after every epoch end
:return: output - average test loss
"""
avg_test_acc = torch.stack([x["test_acc"] for x in outputs]).mean()
self.log("avg_test_acc", avg_test_acc)
def configure_optimizers(self):
"""
Initializes the optimizer and learning rate scheduler
:return: output - Initialized optimizer and scheduler
"""
self.optimizer = torch.optim.Adam(self.parameters(), lr=self.args["lr"])
self.scheduler = {
"scheduler": torch.optim.lr_scheduler.ReduceLROnPlateau(
self.optimizer,
mode="min",
factor=0.2,
patience=2,
min_lr=1e-6,
verbose=True,
),
"monitor": "val_loss",
}
return [self.optimizer], [self.scheduler]
def print_auto_logged_info(r):
tags = {k: v for k, v in r.data.tags.items() if not k.startswith("mlflow.")}
artifacts = [f.path for f in MlflowClient().list_artifacts(r.info.run_id, "model")]
print("run_id: {}".format(r.info.run_id))
print("artifacts: {}".format(artifacts))
print("params: {}".format(r.data.params))
print("metrics: {}".format(r.data.metrics))
print("tags: {}".format(tags))
if __name__ == "__main__":
parser = ArgumentParser(description="PyTorch Autolog Mnist Example")
# Early stopping parameters
parser.add_argument(
"--es_monitor", type=str, default="val_loss", help="Early stopping monitor parameter"
)
parser.add_argument("--es_mode", type=str, default="min", help="Early stopping mode parameter")
parser.add_argument(
"--es_verbose", type=bool, default=True, help="Early stopping verbose parameter"
)
parser.add_argument(
"--es_patience", type=int, default=3, help="Early stopping patience parameter"
)
parser = pl.Trainer.add_argparse_args(parent_parser=parser)
parser = LightningMNISTClassifier.add_model_specific_args(parent_parser=parser)
mlflow.pytorch.autolog()
args = parser.parse_args()
dict_args = vars(args)
if "accelerator" in dict_args:
if dict_args["accelerator"] == "None":
dict_args["accelerator"] = None
model = LightningMNISTClassifier(**dict_args)
dm = MNISTDataModule(**dict_args)
dm.setup(stage="fit")
early_stopping = EarlyStopping(
monitor=dict_args["es_monitor"],
mode=dict_args["es_mode"],
verbose=dict_args["es_verbose"],
patience=dict_args["es_patience"],
)
checkpoint_callback = ModelCheckpoint(
dirpath=os.getcwd(), save_top_k=1, verbose=True, monitor="val_loss", mode="min"
)
lr_logger = LearningRateMonitor()
trainer = pl.Trainer.from_argparse_args(
args, callbacks=[lr_logger, early_stopping, checkpoint_callback], checkpoint_callback=True
)
with mlflow.start_run() as run:
trainer.fit(model, dm)
trainer.test(datamodule=dm)
# fetch the auto logged parameters and metrics
print_auto_logged_info(mlflow.get_run(run_id=run.info.run_id))