策略梯度法(policy gradient)算法简述
本文通过整理李宏毅老师的机器学习教程的内容,简要介绍深度强化学习(deep reinforcement learning)中的策略梯度法(policy gradient)。
李宏毅老师课程的B站链接:
李宏毅, 深度强化学习, policy gradient
相关笔记:
近端策略优化(proximal policy optimization)算法简述
DQN(deep Q-network)算法简述
actor-critic 相关算法简述
设:
一次游戏的轨迹(trajectory): τ \tau τ
玩家(actor)策略(policy): θ \theta θ
则激励(reward)的期望值可通过 N 次采样(sampling)估算(激励 R R R 是一个随机变量):
R ˉ θ = ∑ τ R ( τ ) P ( τ ∣ θ ) ≈ 1 N ∑ n = 1 N R ( τ n ) \bar R_{\theta} = \sum_{\tau} R(\tau) P(\tau | \theta) \approx \frac{1}{N} \sum_{n=1}^{N} R(\tau^{n}) Rˉθ=τ∑R(τ)P(τ∣θ)≈N1n=1∑NR(τn)
最优策略为:
θ ∗ = arg max θ R ˉ θ \theta^{*} = \arg \max_{\theta} \bar R_{\theta} θ∗=argθmaxRˉθ
优化方法即为梯度上升法(gradient ascent)。
激励的梯度:
▽ R ˉ θ = ∑ τ R ( τ ) ▽ P ( τ ∣ θ ) = ∑ τ R ( τ ) P ( τ ∣ θ ) ▽ P ( τ ∣ θ ) P ( τ ∣ θ ) = ∑ τ R ( τ ) P ( τ ∣ θ ) ▽ ln P ( τ ∣ θ ) ≈ 1 N ∑ n = 1 N R ( τ n ) ▽ ln P ( τ n ∣ θ ) \triangledown \bar R_{\theta} = \sum_{\tau} R(\tau) \triangledown P(\tau | \theta) = \sum_{\tau} R(\tau) P(\tau | \theta) \frac {\triangledown P(\tau | \theta)} {P(\tau | \theta)} = \sum_{\tau} R(\tau) P(\tau | \theta) \triangledown \ln P(\tau | \theta) \approx \frac{1}{N} \sum_{n=1}^{N} R(\tau^{n}) \triangledown \ln P(\tau^{n} | \theta) ▽Rˉθ=τ∑R(τ)▽P(τ∣θ)=τ∑R(τ)P(τ∣θ)P(τ∣θ)▽P(τ∣θ)=τ∑R(τ)P(τ∣θ)▽lnP(τ∣θ)≈N1n=1∑NR(τn)▽lnP(τn∣θ)
其中,取对数的操作原理:
d ln ( f ( x ) ) d x = 1 f ( x ) d f ( x ) d x \frac {d \ln (f(x))} {dx} = \frac{1}{f(x)} \frac{df(x)}{dx} dxdln(f(x))=f(x)1dxdf(x)
由于轨迹在策略的条件发生的概率:
P ( τ ∣ θ ) = p ( s 1 ) p ( a 1 ∣ s 1 , θ ) p ( r 1 , s 2 ∣ s 1 , a 1 ) p ( a 2 ∣ s 2 , θ ) p ( r 2 , s 3 ∣ s 2 , a 2 ) ⋯ = p ( s 1 ) ∏ t = 1 T p ( a t ∣ s t , θ ) p ( r t , s t + 1 ∣ s t , a t ) P(\tau | \theta) = p(s_1) p(a_1 | s_1, \theta) p(r_1, s_2 | s_1, a_1) p(a_2 | s_2, \theta) p(r_2, s_3 | s_2, a_2) \cdots = p(s_1) \prod_{t=1}^{T} p(a_t | s_t, \theta) p(r_t, s_{t+1} | s_t, a_t) P(τ∣θ)=p(s1)p(a1∣s1,θ)p(r1,s2∣s1,a1)p(a2∣s2,θ)p(r2,s3∣s2,a2)⋯=p(s1)t=1∏Tp(at∣st,θ)p(rt,st+1∣st,at)
其中, s s s 为各时刻的游戏状态(state), a a a 为玩家的动作(action)。
只有 p ( a t ∣ s t , θ ) p(a_t | s_t, \theta) p(at∣st,θ) 部分与玩家的策略 θ \theta θ 有关,另外两项 p ( s 1 ) p(s_1) p(s1) 和 p ( r t , s t + 1 ∣ s t , a t ) p(r_t, s_{t+1} | s_t, a_t) p(rt,st+1∣st,at) 均与玩家策略无关。
因此对数项的梯度:
ln P ( τ ∣ θ ) = ln p ( s 1 ) + ∑ t = 1 T [ ln p ( a t ∣ s t , θ ) + ln p ( r t , s t + 1 ∣ s t , a t ) ] ▽ ln P ( τ ∣ θ ) = ∑ t = 1 T ▽ ln p ( a t ∣ s t , θ ) \ln P(\tau | \theta) = \ln p(s_1) + \sum_{t=1}^{T} [\ln p(a_t | s_t, \theta) + \ln p(r_t, s_{t+1} | s_t, a_t)] \\ \triangledown \ln P(\tau | \theta) = \sum_{t=1}^{T} \triangledown \ln p(a_t | s_t, \theta) lnP(τ∣θ)=lnp(s1)+t=1∑T[lnp(at∣st,θ)+lnp(rt,st+1∣st,at)]▽lnP(τ∣θ)=t=1∑T▽lnp(at∣st,θ)
从而得出激励的梯度:
▽ R ˉ θ ≈ 1 N ∑ n = 1 N R ( τ n ) ▽ ln P ( τ n ∣ θ ) = 1 N ∑ n = 1 N R ( τ n ) ∑ t = 1 T n ▽ ln p ( a t n ∣ s t n , θ ) = 1 N ∑ n = 1 N ∑ t = 1 T n R ( τ n ) ▽ ln p ( a t n ∣ s t n , θ ) \triangledown \bar R_{\theta} \approx \frac{1}{N} \sum_{n=1}^{N} R(\tau^{n}) \triangledown \ln P(\tau^{n} | \theta) = \frac{1}{N} \sum_{n=1}^{N} R(\tau^{n}) \sum_{t=1}^{T_n} \triangledown \ln p(a^n_t | s^n_t, \theta) = \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} R(\tau^{n}) \triangledown \ln p(a^n_t | s^n_t, \theta) ▽Rˉθ≈N1n=1∑NR(τn)▽lnP(τn∣θ)=N1n=1∑NR(τn)t=1∑Tn▽lnp(atn∣stn,θ)=N1n=1∑Nt=1∑TnR(τn)▽lnp(atn∣stn,θ)
需要注意以下几点:
一,上式所乘的激励为全局收益,而非单步激励,否则无法学习到对后续时刻激励的动作。(第四点会做出相应改进)
二,取对数的原因:
由于取对数再求梯度相当于,对概率求梯度后除以概率本身:
▽ ln p ( a t n ∣ s t n , θ ) = ▽ p ( a t n ∣ s t n , θ ) p ( a t n ∣ s t n , θ ) \triangledown \ln p(a^n_t | s^n_t, \theta) = \frac {\triangledown p(a^n_t | s^n_t, \theta)} {p(a^n_t | s^n_t, \theta)} ▽lnp(atn∣stn,θ)=p(atn∣stn,θ)▽p(atn∣stn,θ)
而除以概率本身,可以防止某些激励不高的动作被采样多次,从而导致累积过多激励的结果:

三,引入基线(baseline):
当游戏的激励恒非负时,为防止未被采样到的高激励动作的概率值降低,故加入基线:

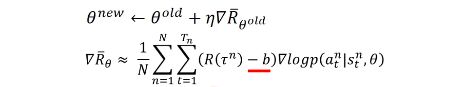
基线的一个最简单的设置方式,即对 R ( τ ) R(\tau) R(τ) 取平均值:
b ≈ E [ R ( τ ) ] b \approx E[R(\tau)] b≈E[R(τ)]
四,给每个动作分配合适的分数(credit):
每个时刻的动作,只考虑该时间点之后直到游戏结束的所有激励的总和:
▽ R ˉ θ ≈ 1 N ∑ n = 1 N ∑ t = 1 T n ( ∑ t ′ = t T n r t ′ n − b ) ▽ ln p ( a t n ∣ s t n , θ ) \triangledown \bar R_{\theta} \approx \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} (\sum_{t^{\prime}=t}^{T_n} r_{t^{\prime}}^n - b) \triangledown \ln p(a^n_t | s^n_t, \theta) ▽Rˉθ≈N1n=1∑Nt=1∑Tn(t′=t∑Tnrt′n−b)▽lnp(atn∣stn,θ)
进一步地,把未来的激励做一个折扣(discount),即时间越久,影响力就越小:
▽ R ˉ θ ≈ 1 N ∑ n = 1 N ∑ t = 1 T n ( ∑ t ′ = t T n γ t ′ − t r t ′ n − b ) ▽ ln p ( a t n ∣ s t n , θ ) \triangledown \bar R_{\theta} \approx \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} (\sum_{t^{\prime}=t}^{T_n} \gamma^{t^{\prime} - t} r_{t^{\prime}}^n - b) \triangledown \ln p(a^n_t | s^n_t, \theta) ▽Rˉθ≈N1n=1∑Nt=1∑Tn(t′=t∑Tnγt′−trt′n−b)▽lnp(atn∣stn,θ)
其中,折扣因子 γ \gamma γ 取值范围为 [ 0 , 1 ] [0, 1] [0,1],通常取 0.9 0.9 0.9 或 0.99 0.99 0.99,若取 0 0 0,则表示只关心即时激励,若取 1 1 1,则表示未来激励等同于即时激励。