Pytorch 带你一行一行分析训练脚本
目录
1.引言
2.数据集处理部分
2.引入网络模型、损失函数、优化器
3.训练过程
4.验证过程
1.引言
在使用pytorch进行深度学习模型训练时,训练脚本是不可或缺的一部分,本文将以一个经典的训练脚本为对象,一行一行分析其代码原理。
如下是一个使用ResNet进行图片分类任务的模型训练脚本代码:
import os
import sys
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms
import torchvision.models as models
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
dataset = MyDataset(r'./Data/new_label.csv',
r'E:\Thyroid Segmentation Project\Thyroid_US_Dataset\newdataset\multi_classification_cut_roi',
transform=data_transform["train"])
train_size = int(len(dataset) * 0.7)
val_size = len(dataset) - train_size
train_dataset, val_dataset = torch.utils.data.random_split(dataset, [train_size, val_size])
train_num = len(train_dataset)
val_num = len(val_dataset)
batch_size = 16
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=batch_size, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
net = models.resnet34()
in_channel = net.fc.in_features
net.fc = nn.Linear(in_channel, 5)
net.to(device)
# define loss function
loss_function = nn.CrossEntropyLoss()
# construct an optimizer
params = [p for p in net.parameters() if p.requires_grad]
optimizer = optim.Adam(params, lr=0.0001)
epochs = 3
best_acc = 0.0
save_path = './resNet34.pth'
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
for step, data in enumerate(train_loader):
images, labels = data
optimizer.zero_grad()
logits = net(images.to(device))
loss = loss_function(logits, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
rate = (step+1)/len(train_loader)
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.4f}".format(int(rate*100), a, b, loss), end="")
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
for val_data in validate_loader:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()我们可以将其拆解为三个部分:(1)数据集处理部分 (2)定义网络模型、损失函数、优化器 (3)训练和验证部分。以下本文将依次对这三个部分进行详细介绍。
2.数据集处理部分
训练集在送入网络前,需要被读取加载,并划分为训练集和验证集,并指定图像增强方法,然后以batch size为单位分批送入网络。
(1)transforms
torchvision.transfroms实现了丰富的图像增强方法,可以对PIL Image 和 Tensor进行转化,如:
transforms.RandomResizedCrop(224) # 将图片随机裁剪,并resize到224*224
transforms.RandomHorizontalFlip(p=0.5) # 将图片以0.5的概率水平翻转
transforms.CenterCrop(224) # 从图片中心位置,以224为尺寸进行裁剪
transforms.RandomRotation() # 按角度旋转图片
transforms.ToTensor() # 将图片转化为tensor,图片将会被归一化到[0, 1],且其维度会从(H x W x C)转为(C x H x W)
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 按mean和std归一化到[-1, 1] [0.485, 0.456, 0.406], [0.229, 0.224, 0.225]是从ImageNet数据集上得到mean和std
transforms.RandomErasing() # 在张量图像中随机选择一个矩形区域并擦除其像素注意,有些transforms只能对PIL或tensor类型之一使用,而有些transforms即能对PIL进行变换也可以对tensor进行变换。具体参见:https://pytorch.org/vision/stable/transforms.html
很多情况下,我们往往会使用多种增强方法,那么便可以使用transforms.Compose将多种变换方法串联组装起来,图片会依次经过transforms.Compose中的变换:
transforms.Compose([transforms.Grayscale(1),
transforms.Resize([224, 224]),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485], [0.229])
])为了方便对训练集和数据集采用不同的增强方法,我们可以使用一个字典来保存我们要使用的增强方法,如下代码所示,定义一个data_transform字典,该字典有两个key,分别为“train”和“val”,其value为图像增强的方法。
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}(2)dataset
对于一个图片分类任务,我们用两种方式读取数据集,一种是使用pytorch的dataset类(这个类往往需要根据自己的任务进行重写),另一种是直接使用ImageFolder。
# 方式一:使用重写的Dataset类
dataset = MyData(label_path,
image_root_path,
transform=data_transform["train"])
train_size = int(len(dataset) * 0.7)
val_size = len(dataset) - train_size
train_dataset, val_dataset = torch.utils.data.random_split(dataset, [train_size, val_size]) # 按比例划分成训练集和测试集
# 方式二:使用ImageFolder
import torchvision.datasets
train_dataset = datasets.ImageFolder(root=train_root_path,
transform=data_transform["train"])
val_dataset = datasets.ImageFolder(root=val_root_path,
transform=data_transform["val"])(3)DataLoader
dataset类是pytorch中表示数据集的抽象类,那么DataLoader作为一个迭代器,每次会产生一个batch size大小的数据。
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
batch_size = 32
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=batch_size, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))2.引入网络模型、损失函数、优化器
在对数据集的处理完成后,需要引入网络模型、定义损失函数和优化器等。
import torchvision.models as models
net = models.resnet34() # 使用 pytorch 自带的 resnet34
in_channel = net.fc.in_features # 取resnet34的全连接层的神经元个数
net.fc = nn.Linear(in_channel, class_num) # 将resnet34的最后一层神经元改为[in_channel, class_num],以适应你的分类类别
net.to(device) # 指定以GPU还是CPU运行模型 net.cuda() 只能指定GPU
loss_function = nn.CrossEntropyLoss() # 定义损失函数,这里使用交叉熵损失
params = [p for p in net.parameters() if p.requires_grad] 将网络中所有需要更新梯度的参数放入params
optimizer = optim.Adam(params, lr=0.0001) # 构建优化器,传入两个参数,前者为要优化的参数,后者为学习率其中device通过下面的代码获得:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 如果cuda:0可用则使用cuda:0,否则使用cpu。cuda:0 即第一张gpu
print(device)当然,如果你有多张显卡,你也可以使用如下代码,使用多张GPU训练:
# 指定某个GPU
os.environ['CUDA_VISIBLE_DEVICE']='1'
net.cuda()
# 如果是多GPU
os.environment['CUDA_VISIBLE_DEVICES'] = '0,1,2,3'
device_ids = [0,1,2,3]
net = torch.nn.Dataparallel(net, device_ids =device_ids)
net = torch.nn.Dataparallel(net) # 默认使用所有的device_ids
net = net.cuda()对于优化器,我们必须要传入两个参数,一个是需要更新梯度的网络参数,另一个是学习率。
我们可以直接更新网络中的所有参数:
optimiter = torch.optim.Adam(net.parameters(), lr=0.01)也可以对不同参数指定不同的优化器策略,如:
optimizer = optim.SGD([{'params': filter(lambda p: p.requires_grad, net.parameters())},
{'params': awl.parameters(), 'weight_decay': 0}],
lr=0.001,
weight_decay=1e-5)又如:
# 对bias和其他权重采取不同的优化策略
# 获取网络中的bias参数,和其他参数,保存至bias_p和weight_p, 用以传入optimizer,分别进行优化
weight_p, bias_p = [], []
for name, p in net.named_parameters():
if 'bias' in name:
bias_p += [p]
else:
weight_p += [p]
# 只对weight_p施加weight_decay
optimizer = torch.optim.SGD([{'params': weight_p, 'weight_decay': 1e-5},
{'params': bias_p, 'weight_decay': 0}],
lr=1e-2,
momentum=0.9)3.训练过程
这一节,我将会把代码拆解成小块进行解释。总体代码已经在本文开头给出。
epochs = 200
for epoch in range(epochs):
net.train()
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
images, labels = data(1)epoch指定了训练周期。
(2)net.train()标识了当前模型处于训练还是测试阶段。在模型训练时,前面必须加上net.train()。同样模型验证和测试时必须加上net.eval()。这个主要是为了更好的处理 Batch Normalization 和 Dropout。
我们知道,如果网络中含有BN层,在训练时会对每个mini batch计算其均值和方差,这样会保留每个batch的差异性,可以提高模型的泛化能力。网络训练完成后每个batch的均值和方差是固定的,测试时并没有mini batch这一概念,使用mini batch的均值和方差去计算全量数据,这显然是不科学的,net.eval()保证了BN层能够用全部训练数据的均值和方差,即测试过程中要保证BN层的均值和方差不变。
Dropout通过在训练时失活线性层中部分神经元,从而在一定程度上避免过拟合。而在验证和测试时,不需要Dropout。net.eval()保证了Dropout在验证和测试时不起作用。
用一句话概括:net.train(),和net.eval()是一对开关,net.train()开启了Dropout和BN,net.eval()关闭了Dropout和BN。
(3)for step, data in enumerate(train_loader, start=0):
enumerate可以将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。前文已经介绍了train_loader是一个可迭代的数据对象,那么配合enumerate,便可以按batch size大小返回数据。
事实上我们也可以通过如下方式返回批次数据:
for item in train_loader:
images, labels = item
print(len(images))
print(len(labels)).运行结果:
使用enumerate的好处是它可以返回数组下标(当前批次的序号,即代码中的step),我们不用创建中间变量去记录当且是第几个批次。
(4)训练过程核心代码
optimizer.zero_grad()
logits = net(images.to(device))
loss = loss_function(logits, labels.to(device))
loss.backward()
optimizer.step()optimizer.zero_grad() 就是把梯度置零,也就是把loss关于weight的导数变成0。在训练过程中,每一个batch会更新一次网络的梯度,当到下一个batch计算梯度时,前一个batch的梯度已经没用了,所以需要将其变成0。当然也有人通过累加多个小batch的梯度,然后再更新参数,从而变相的使用了大batch size。
logits = net(images.to(device)) 很好理解,就是将图片张量送入网络前向传播,images.to(device) 是让其在GPU上计算,注意,前面的net.to(device) 是让网络的参数在GPU上计算,而Pytorch不允许不同设备的参数一起计算,所以也需要将图片张量设置为GPU设备计算。如果images.to(device)看做 ,那么
,那么![]() 其实就是
其实就是 ,标签就是
,标签就是 。
。
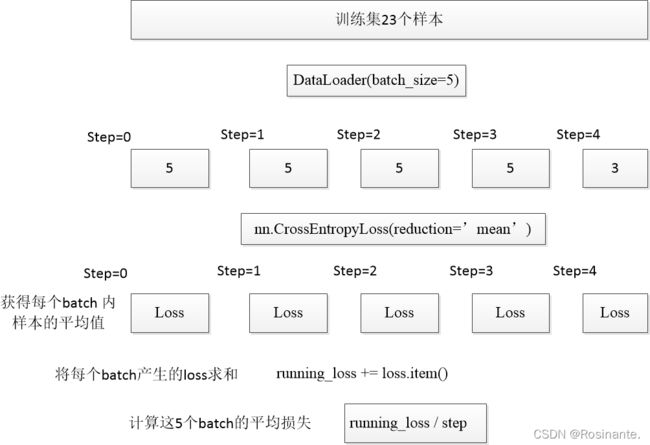
loss = loss_function(logits, labels.to(device)) 计算损失。我们知道,DataLoader每次向网络投喂一个batch size大小的数据,每个batch size大小的数据都会经历前向传播、计算损失、反向传播、更新梯度这一过程。这里的loss是一个batch的平均损失。我们使用的损失函数nn.CrossEntropyLoss()中有一个参数项reduction,它的可选参数有三个,分别是'none','mean'和'sum'。如果在一个batch内计算的话:
- 'none'代表的是batch内的每个元素都会计算一个损失,返回的结果还是一个batch;
- 'mean’代表的是是否进行平均,一个batch只返回一个;
- 'sum’代表的是将batch内的loss相加,一个batch也是只返回一个;
它的默认值是'mean',也就是说如果不指定reduction,默认返回一个batch的平均损失。
loss.backward() 反向传播,根据loss计算梯度。
optimizer.step() 更新梯度。torch中参数和它的梯度是绑定在一起的,optimizer通过在定义时传入其中的网络参数,以及反向传播之后参数的对应梯度,使用该优化器的优化方法来更新参数值。
(5)训练进度条
running_loss += loss.item()
rate = (step+1)/len(train_loader)
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.4f}".format(int(rate*100), a, b, loss), end="")
进度条显示效果:
![]()
以上代码主要是为了在训练过程中显示训练进度和实时损失。别认为它不重要而忽视它,事实上研究一下它可以帮助你很好的理解整个训练流程 (手动狗头)。
running_loss += loss.item() 由 loss_function(logits, labels.to(device)) 返回的loss类型为张量,所以需要item()取到其数值。前面已经讲过loss_function(logits, labels.to(device)) 返回的是每一个mini batch的平均损失,running_loss += loss.item() 就是将每个mini batch数量的样本的平均损失累加起来,方便后面计算每一个样本的平均损失。可能有点拗口,但看到后面就明白了。
rate = (step+1)/len(train_loader) 这行代码是在计算当前epoch完成了百分之多少。DataLoader按batch来投喂数据,那么假设训练集有1000张图片,batch_size=32,所以train_loader需要投喂![]() 次,也就是len(train_loader) 的值。step是通过enumerate获得的,它表示当前是第step个batch。因为enumerate的start=0,所以需要step+1。假如当前是第10个batch,那么当前epoch进行了百分之rate = 10/32。
次,也就是len(train_loader) 的值。step是通过enumerate获得的,它表示当前是第step个batch。因为enumerate的start=0,所以需要step+1。假如当前是第10个batch,那么当前epoch进行了百分之rate = 10/32。
a = "*" * int(rate * 50)和b = "." * int((1 - rate) * 50)。这两个就是进度条上的“*”和“.”的个数。这两个个数相加一共是50,不信去上图数一数(手动狗头)。
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.4f}".format(int(rate*100), a, b, loss), end="") 打印进度条,并输出每一个batch的loss。因为end="",所以该控制台输出在循环内部只回车不换行,执行完此循环过后换行。{:^3.0f}%[{}->{}]{:.4f} 四个占位符({}),分别对应int(rate*100) 表示百分比,a和b根据rate会此消彼长,loss是当前batch内的所有样本的平均loss。
4.验证过程
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
for val_data in val_loader:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('\r[epoch %d] train_loss: %.3f val_acc: %.3f' % (epoch + 1, running_loss / step, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)net.eval() 不多说了。
with torch.no_grad() python的上下文管理器with就不多介绍了,这句代码意思简单粗暴一句话就是:with wrap下的所有代码都不更新梯度。
predict_y = torch.max(outputs, dim=1)[1] 这代码的意思是获得这个batch中网络的预测标签 。 torch.max(outputs, dim=1)返回两个值,分别是最大值和其对应的索引,dim=1时按行返回最大索引,dim=0时按列返回最大索引。outputs是网络的输出,是一个尺寸为![]() 的张量。如下表所示,比如你在做15分类的任务,那么网络最后一层应该是一个15个神经元的线性层,如果batch size=3,那么网络会输出size为3*15的张量,每一行代表改batch内的一个样本,每一列代表网络对该列对应的类别预测的概率值。
的张量。如下表所示,比如你在做15分类的任务,那么网络最后一层应该是一个15个神经元的线性层,如果batch size=3,那么网络会输出size为3*15的张量,每一行代表改batch内的一个样本,每一列代表网络对该列对应的类别预测的概率值。
| 0 | 1 | 2 | 3 | |
| 1 | 0.3 | 0.2 | 0.4 | 0.1 |
| 2 | 0.9 | 0.05 | 0.03 | 0.02 |
| 3 | 0.7 | 0.2 | 0.05 | 0.05 |
通过 torch.max(outputs, dim=1)[1] 可以找到该行(也即该样本)对应的预测概率最大的索引。
acc += torch.eq(predict_y, val_labels.to(device)).sum().item() predict_y前面已经说了,它保存了网络对当前batch数据的预测类别。torch.eq()是对两个张量进行逐元素的比较,若相同位置的两个元素相同,则返回True;若不同,返回False。例如网络的预测值为predict_y=[2,0,0],实际的标签值为y=[2,1,0],那么torch.eq(predict_y, y)会返回[True, False, True],注意,在python中式可以对True和False进行数学运算的,True等价于1,False等价于0。那么通过.sum()对其求和,就是预测对的值,此时还是一个张量,所以需要.item()取出对应的值。注意此时的acc是当前batch的预测正确的个数,所以需要+=来得到所有batch的预测正确的个数。
val_accurate = acc / val_num 此时的acc是验证集上的所有预测正确的个数,val_num是验证集的样本个数,val_cacurate是验证集上的准确率。
print('\r[epoch %d] train_loss: %.3f val_acc: %.3f' % (epoch + 1, running_loss / step, val_accurate)) 每一个epoch 打印一下相关信息。step是批次,running_loss前面讲了是训练集上所有batch的损失,是每个mini batch的平均损失, running_loss / step就是训练集上每个样本的平均损失了(当你的训练集样本数能被batch size 整除时)。
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)这三行意思就是每次在验证集上获得一个新的最高的准确度,就保存一下模型。
print('Finished Training') 最后,让炼丹炉告诉你它炼完丹了。
后续我还会介绍对训练脚本的封装,以使其拓展性更强。