强化学习入门5—一文带你了解DQN
文章目录
- 深入了解 DQN
-
- 简介
- 值函数近似
- 怎么训练?
- 算法流程
- 小结
深入了解 DQN
本文是强化学习入门系列的第五篇。我们前面介绍了Q-learning,今天介绍一个深度版的Q-learning。
本节的学习目标:什么是DQN?与Q-learning的关系?什么是值函数近似?神经网络怎么训练?
简介
DQN即Deep Q Network。DQN属于model-free、value-based、off-policy的方法。于2013年DeepMind的论文 Playing Atari with Deep Reinforcement Learning 中提出。在2015年DeepMind的论文 Human-level Control Through Deep Reinforcement Learning 提出了采用CNN的新版的DQN。
回顾Q-learning,我们知道Q-learning是一种off-policy算法,算法的更新主要基于一张Q表格,Q表存储整个状态-动作空间的所有值,每次的学习都是更新这张Q表。其更新方式如下:
Q ( s , a ) ← Q ( s , a ) + α [ r + γ max a ′ Q ( s ′ , a ′ ) − Q ( s , a ) ] Q(s,a)\leftarrow Q(s,a)+\alpha[r+\gamma\max_{a'}Q(s',a')-Q(s,a)] Q(s,a)←Q(s,a)+α[r+γa′maxQ(s′,a′)−Q(s,a)]
但是,在现实中,智能体可能存在非常多的状态或者动作,这时想建立Q表显然内存是不允许的,在计算上也会面临很大的开销。为了解决状态空间过大(也称维度灾难),提出了DQN算法,其通过神经网络来实现Q值的计算。
值函数近似
简单来说,就是使用一个函数 f ( s , a ) f(s,a) f(s,a) 来近似 Q ( s , a ) Q(s,a) Q(s,a)。函数可以是线性的或非线性的。
Q ^ ( s , a ∣ θ ) ≈ Q ( s , a ) \hat{Q}(s,a|\theta)\approx Q(s,a) Q^(s,a∣θ)≈Q(s,a)
θ \theta θ 就是函数的参数。怎么拟合出这样的函数?那DQN是使用的是卷积神经网络CNN来拟合函数。CNN是把状态 s s s 作为输入,输出的是一个包含所有动作的价值的一个向量,对参数进行训练,直到收敛。下图是论文中的CNN结构
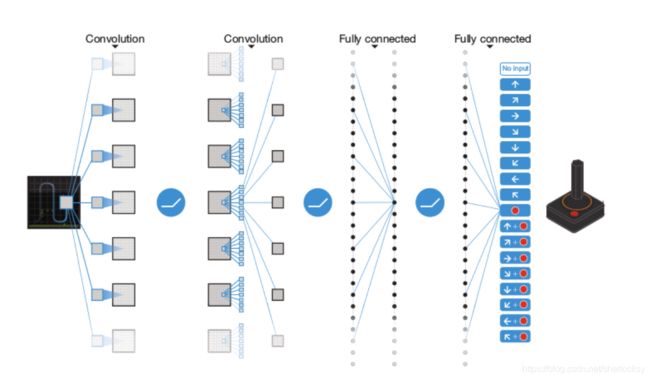
怎么训练?
我们知道,神经网络的训练需要有标签的数据,需要足够的样本才能训练参数。DQN为了解决这一问题,构造了一个经验池。
简单来说,就是先初始化后,利用 ϵ − g r e e d y \epsilon-greedy ϵ−greedy 随机策略,按照Q-learning那样先跑一段时间,然后将这一段时间内的状态 s s s、动作 a a a、奖励 r r r、下一时刻的状态 s ′ s' s′ 都存储在经验池里。
这一步也是DQN的重要步骤,有了经验池,DQN就可以重复学习。同时,训练时,就从经验池随机采样一个batch的样本数据,这种方法也叫 Experience Replay 经验回放,这样做有一个好处就是可以减弱数据之间的关联性,使得神经网络更稳定些。
有了样本,我们可以来构造如下的 Loss Function:
L ( θ ) = E [ ( Q t a r g e t − Q ( s , a ∣ θ ) ) 2 ] = E [ ( r + γ max a ′ ( Q ( s ′ , a ′ ∣ θ ) ) − Q ( s , a ∣ θ ) ) 2 ] L(\theta)=E[(Q_{target}-Q(s,a|\theta))^2] =E[(r+\gamma\max_{a'}(Q(s',a'|\theta))-Q(s,a|\theta))^2] L(θ)=E[(Qtarget−Q(s,a∣θ))2]=E[(r+γa′max(Q(s′,a′∣θ))−Q(s,a∣θ))2]
根据loss function计算梯度,使用SGD更新梯度,直到收敛到想要的 θ \theta θ。
算法流程
此处上15年CNN的版本伪代码

仔细看上面的伪代码,我们发现有两个神经网络的参数 θ , θ − \theta,\theta^{-} θ,θ−。实际上呢,DQN使用的是两个CNN,一个是用于计算 Q t a r g e t Q_{target} Qtarget 也就是 θ − \theta^- θ− 所在的网络,一个用于计算当前 Q ( s , a ) Q(s,a) Q(s,a) 也就是 θ \theta θ 。那为什么要再加一个 target network 呢?
其实这种方法也叫Fixed Q-targets。就是增加一个结构相同但参数不同的 target network。目的是为了防止原先的Q网络过拟合。试想,如果我们只有一个Q网络,那每次更新 θ \theta θ 的时候,目标值也会跟着改变,也就是说它所追求的目标一直是变化的。这样学到的网络可能就不是很稳定。那引入一个目标网络,固定住这个target,一段时间后再更新,这样我们原先的Q网络在更新 θ \theta θ 时追求的就是一个固定的目标。
小结
简单来说,DQN就是应用了神经网络,将状态作为神经网络的输入,输出所有的动作值, 然后按照 Q-learning 的原则,直接选择拥有最大值的动作当做下一步要做的动作。换句话说,在Q-learning上,使用神经网络来计算Q值,把Q-table变成了Q-Network,从而可以应对高维度的状态或动作空间问题。DQN也有缺点,比如DQN不能用于连续性控制问题,这是因为MAX Q的操作,使得DQN只能处理离散型问题。
参考
- 强化学习——从Q-Learning到DQN到底发生了什么? - 知乎
- DQN 神经网络 - 强化学习 (Reinforcement Learning) | 莫烦Python