Pytorch加速模型训练速度总结
这是总结了很多了网上的方法,然后经过实验感觉应该OK的:
前提是在显存够用的情况,并且batch_size足够大了(比如16+的时候了),只想着减少时间复杂度的情况下,所以这个时候一定是使用空间换取时间的(与checkpoint相反)
1.减少训练步骤中掺杂的其他的东西:
只留下 optimizer.zeors_grad() -> loss.backward()(最花时间,非常漫长)-> torch.nn.utils.clip_grad_norm_(有的时候中间会加上) -> optimizer.step()
这基础的几步,然后不要再加上其他的清零操作,比如:
self.model.zero_grad();
gc.collect();
等等
2.使用并行计算:(在有多卡的情况)
多卡的情况下,有DP,DDP等方式。
DP方式:
model = torch.nn.DataParallel(model).cuda();加上这行代码就OK了,在模型加载的时候,放上去就OK。
但是性能没有DDP好,也只是相对来说,用两张卡会比只用一张卡快上许多而已,batch_size提高而已。
DDP方式:
非常复杂,需要在dataloader,model,shuffle,optimizer等方面加上相关命令,而且运行的时候必须使用特定的语句进行训练,不然的话就会报错。
但是功能非常强大,不仅可以在同台不同卡上进行运行,而且还可以在不同机器的不同卡上运行,完全的实现了真正的分布式功能。
具体原理使用教程:
简单介绍pytorch中分布式训练DDP使用 (结合实例,快速入门)_liangcd+1的博客-CSDN博客_分布式训练ddp
3.进行混合进度精算:
前提:
确保服务器上的卡是支持tensor core的,不然就是无用功(好吧,我用的就是1080Ti正好是不可以用的那批次,2080Ti都可以用了,哭了。。。)
使用原理:
整体上来说就是需要在训练的时候,模型中所有的参数不是都是FP32的,有的时候可以换成FP16,所以可以在计算的过程中,有选择性的给参数划定数据内存,来提高计算的速度,让AMP决定用什么格式进行计算。一般来说,可以提升2倍,最好的可以提高5.5倍(再一次哭了)
链接:
https://blog.csdn.net/junbaba_/article/details/119078807?ops_request_misc=&request_id=&biz_id=102&utm_term=Pytoch%20%E4%BD%BF%E7%94%A8%E8%87%AA%E5%8A%A8%E6%B7%B7%E5%90%88%E7%B2%BE%E5%BA%A6%EF%BC%88AMP&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-119078807.142^v9^control,157^v4^new_style&spm=1018.2226.3001.4187 https://blog.csdn.net/junbaba_/article/details/119078807?ops_request_misc=&request_id=&biz_id=102&utm_term=Pytoch%20%E4%BD%BF%E7%94%A8%E8%87%AA%E5%8A%A8%E6%B7%B7%E5%90%88%E7%B2%BE%E5%BA%A6%EF%BC%88AMP&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-119078807.142%5ev9%5econtrol,157%5ev4%5enew_style&spm=1018.2226.3001.4187
https://blog.csdn.net/junbaba_/article/details/119078807?ops_request_misc=&request_id=&biz_id=102&utm_term=Pytoch%20%E4%BD%BF%E7%94%A8%E8%87%AA%E5%8A%A8%E6%B7%B7%E5%90%88%E7%B2%BE%E5%BA%A6%EF%BC%88AMP&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-119078807.142%5ev9%5econtrol,157%5ev4%5enew_style&spm=1018.2226.3001.4187
4.设置dataloader中的num_workers参数
前提:
这个我并没有使用,因为我发现我设置了后,变得更慢了…..
使用原理:
为了加快培训过程,我们将使用DataLoader类的num_workers可选属性。 num_workers属性告诉数据加载器实例要用于数据加载的子进程数。 默认情况下,num_workers值设置为零,零值告诉加载程序在主进程内部加载数据。 这意味着培训过程将在主要过程中按顺序进行。 在训练过程中使用了一批并且需要另一批之后,我们从磁盘读取了批数据。 现在,如果我们有一个工作进程,我们就可以利用我们的机器具有多个内核的事实。 这意味着在主流程准运行。 这就是速度的来源。 批处理使用其他工作进程加载,并在内存中排队。
而至于要设置为多少呢?就是需要测试了,一般来说有两种思路:一个是直接设置为cpu的个数就好了,一个是设置为GPU的数量*4。个人用的是后者,感觉跟快一些。但是最好还是测试一下会比较好,测试一下自己的模型+机器适合配备几个num_workers
设置的时候顺带把pn_memory=True!!!(我也不知道为什么。。。)
快慢大小:
一般来说,会快上20%?!
5.使用pytorch_lightning框架
优点:
是一种基于torch下的训练框架,以往的训练都需要自己造轮子,一步一步的设置,但是这个框架,可以直接通过调用几个框架,然后就设置好了整体的训练过程:dataloader,train循环,loss的反向传播等等,甚至连DDP都可以帮你实现!功能模块强大。
缺点:
需要重新学习一下这种新型框架的用法,不是很好学吧,费时;如果中间出现了问题,或者自己想在训练中间加上一些修正的范式,基本就别想了;高级一些的用法比如DDP的使用甚至要涉及到model文件内部的修改,感觉非常麻烦!
使用教程:
具体教程:https://zhuanlan.zhihu.com/p/353985363
简单使用教程:https://jishuin.proginn.com/p/763bfbd31a84
6.使用梯度累加:
原理:
就是每次在计算一次循环之后就进行loss的反向传播,实在是太浪费时间了,所以就隔着几个计算后,把loss叠加在一起再计算,比如4次的话,每次计算完loss就压缩1/4然后叠放到一起。然后反向计算回去。
疑惑点:
反正我还没有做过,因为自己的batch_size够大了,所以就没有进行测试,但是总感觉会让模型的效果变得怪怪的。
7.在模型中不需要进行梯度变换的地方加上torch.no_grad(),或者在CV的时候进行
8.关闭Pytorch的各种调试工具
比如:autograd.profiler,autograd.grad_check和autograd.anomaly_detection
9.清缓存类操作:
前提:
这个我用了,但是目前并没有提前出来,但是我感觉还是有必要的,因为随着模型的训练后面必然会占用很多内存的。
使用方法:
torch.cuda.empty_cache(),在每次进行一个epoch之前使用一下,这里千万记住,不是每一次调用model计算的时候进行,因为没有必要,而且这个函数本身自己也会花费相当一部分的时间,所以使用的时候以epoch为单位最合适。
10.CPU和GPU配合使用:
前提:
不是总是这样操作最好,要看情况,如果是非常频繁的进行两者之间的通信的话,不建议这么做,因为会导致大量操作花在两者的通信上,要知道设备之间的通信也是要花大量时间的,但是如果是这一部分完全没有必要在gpu上,或者在cpu上更合适,就可以如此用。
使用教程:
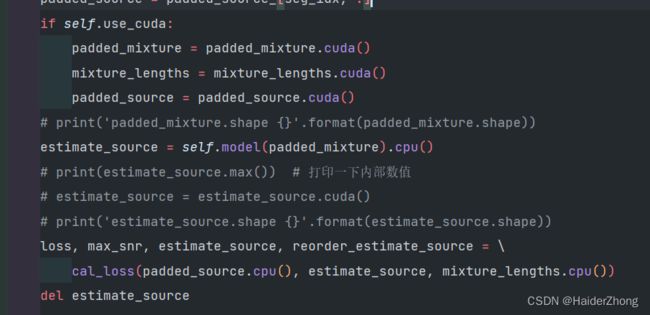
模型输出后,结果放在cpu上,然后使用cpu把数据进行计算,最后使用loss.backward(),而且有个小tip,记得删除计算出来的结果,节省内存使用。
感受:
提速是挺明显的!
总结:网上有非常多的方法,但是有的时候,确实需要自己去一一甄别,看对自己的模型有没有用。比如自己尝试到最后,发现其实最耗时的是loss.back_ward(),占到了每个epoch的60%+,这个时候就是感觉加速得到尽头的感觉了(当然加速是加速,总不能把model改掉对吧)。这个时候什么清内存,使用框架,转换CPU和GPU,减少通信等等奇淫异术都没有用了(除非把pytroch内部的源代码加速……)这些方法总结就是一个,全是奇淫异术!!!