课程向:深度学习与人类语言处理 ——李宏毅,2020 (P17) -1
Overview of NLP Tasks
李宏毅老师2020新课深度学习与人类语言处理课程主页:
http://speech.ee.ntu.edu.tw/~tlkagk/courses_DLHLP20.html
视频链接地址:
https://www.bilibili.com/video/BV1RE411g7rQ
图片均截自课程PPT、且已得到李老师的许可:)
深度学习与人类语言处理 P17 系列文章目录
- Overview of NLP Tasks
- 前言
- I Overview
-
- 1.1 Text->Class
- 1.2 Text->Text
- 1.3 Input
- 1.4 Summary
- II NLP Tasks
-
- 2.1 Part-of-Speech (POS) Tagging 词性标注
- 2.2 Word Segmentation 分词
- 2.3 Parsing 语法分析
- 2.4 Coreference Resolution 指代消解
- 2.5 Summarization 摘要
-
- 2.5.1 Extractive Summarization 抽取式摘要
- 2.5.2 Abstractive Summarization 生成式摘要
- 2.6 Machine Translation 机器翻译
- 2.7 Grammar Error Correction 语法纠错
- 2.8 Sentiment Classification 情感分析
前言
在上一篇中(P17),我们讲解了 Speaker Verification 语者验证有关技术,输入语音,输出类别的模型。类似地,这样的模型可以用在很多不同的领域,如语音情绪判断、语音安全判断、语音关键词是否存在等等,而上一篇中我们只关注 语者验证,其他的应用大同小异,模型一样,都是语音分类问题。 .Speaker Verification 语者验证将从3个方面讲解:
1 Task Introduction
2 Speaker Embedding
3 End-to-end
到目前为止,我们讲解了很多与语音有关的任务,接下来要进入与文字有关的任务,也就是大家所熟知的NLP任务,请注意本篇类似科普类,不涉及任何技术模型等,可以用来归纳总结,而且李宏毅老师的分类清晰有序,还是很值得参考的。
而在本篇中,我们将讲述NLP任务概述,虽然NLP应用非常广泛、模型变化多端,但是总归起来来说,不脱以下几个变化:
文字->类别、文字->文字
I Overview
首先,如果你今天考虑的是输入一段文字,输出的是类别,这种模型大概有两种,如下图。
1.1 Text->Class

- 多对一 : 输入一段文字,只输出一个类别。这个类别代表整段文字的类别。(注意,这里包含了二分类和多分类,要理解好这个只输出一个类别的含义。)
- 多对多 : 输入一段文字,输出每一个token的类别(这里的token有很多种,如字母、subword、词汇等等)。
当你今天在处理 输入一段文字,输出类别的问题的时候,不外乎就这两种问题,而这两种问题如今就是用Bert来解或进阶版Bert,后续会讲;那在过去还没有Bert的时候,就是用LSTM + DNN。
1.2 Text->Text
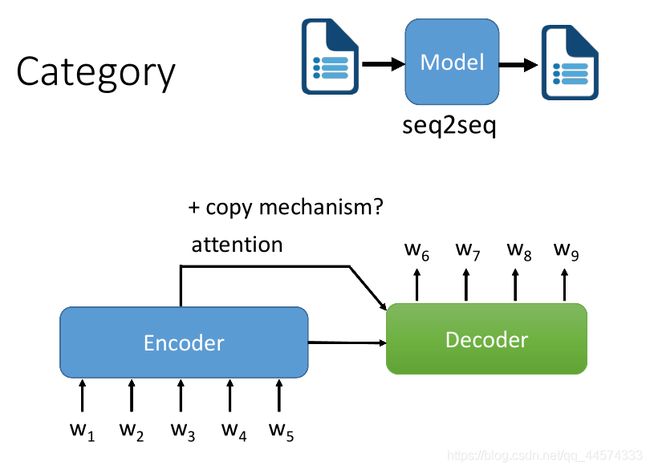
另外一种情况是,输入一段文字,输出一段文字。
对于此问题,我们很直觉地就会想到seq2seq (Encoder + Decoder)+ attention,不再细讲。
但在处理这样的问题时,我们是希望attention有copy的机制,Decoder的输出不需要完全是它自己产生的结果,是可以直接copy Encoder的输入作为它的输出,至于这个要怎么做,后续会讲。
1.3 Input
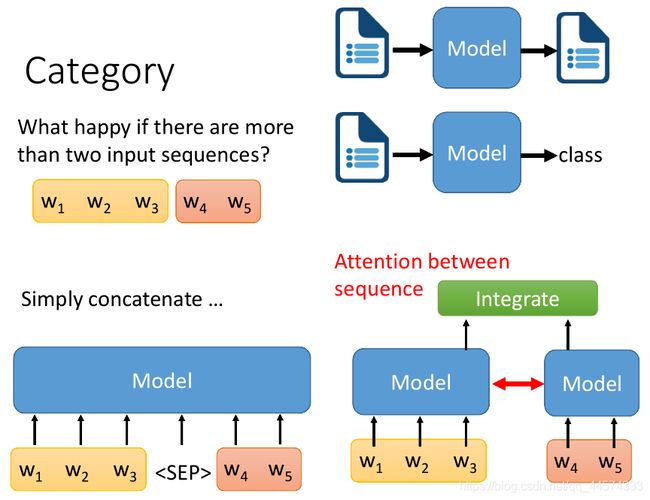
上述讲的都是输入为文字,输出不同的部分。那对于输入的部分呢?如果输入的部分是一个 sequence 那没有问题,直接用Encoder正常读即可。那输入的是多个sequence(即多个句子)该怎么办呢?
有大概两种可能的解法:
-
第一种:我们把两个sequence 分别用一个模型做Encode,然后把两个Encode的结果分别输入给一个负责整合(Integrate)的network (也就是后续任务的模型),再得到最终的输出(文字或类别)。有时候,我们会在这两个做Encode的模型间加上Attention,这种作法就是考虑第一句话可能会和第二句话有一定的指代关系、因果关系等。
-
第二种:简单地把这两个sequence连接在一起,中间加连接符即可,如
。这也是近年来流行的方法。
1.4 Summary

虽然NLP的任务千变万化,但是其实依据模型的输入输出可以分成如上图所示的几个大类
以下,就会将上图,根据不同的输入输出,划分出8个大类的NLP任务,这些NLP任务均会在下面很快地过一遍,告诉你这些任务是什么,属于哪一大类。
II NLP Tasks
2.1 Part-of-Speech (POS) Tagging 词性标注

输入:sequence
输出:class for each token
一个基础的NLP应用就是 POS Tagging,它的任务是将输入的句子中的每一个词进行词性标注
这件事请为什么重要呢?可以解决类似句子中相同词的意义,如上图的 saw 动词 看见 和 saw 名词,锯子。将这些词性和词绑在一起再丢到其他更复杂的NLP Down-stream的任务中就可以做得更好。
但是近年来,Down-stream的模型越来越强大,如Bert,Bert里面本身就有POS Tagging的能力,那就不需要再单独训练一个模型来作为前处理解决POS Tagging问题了。
2.2 Word Segmentation 分词

输入:sequence
输出:class for each token
这个也是常使用的前处理方法,尤其是中文,我们往往需要做 Word Segmentation 。 如果是英文,我们完全不需要 Word Segmentation ,因为英文的词汇和词汇之间有空白作为分割。但是中文不是,中文中没有空白作为分割,因此就需要一种方法来将句子进行分词。但是,在做分词时,其实没有最完美的分词,也因此有很多种各式各样的分词方法。
其实分词的方法就是,输入一段sequence,输出每一个token的二分类结果,如N/Y,N代表NO,表示不是词汇边界,Y代表Yes表示是词汇边界,进行切分,具体过程如上图。之后再以词汇为处理的单位交给Down-stream 任务。
但是这件事请是不是有必要,也是一件值得讨论的事请,因为如Bert这种模型就已经直接以中文的字为处理的基本单位来进行模型训练了,很有可能模型内部已经学到了分词这件事请。那到底需要不需要先做分词。再丢给Down-stream任务呢?还是要看模型的需要和效果。
2.3 Parsing 语法分析
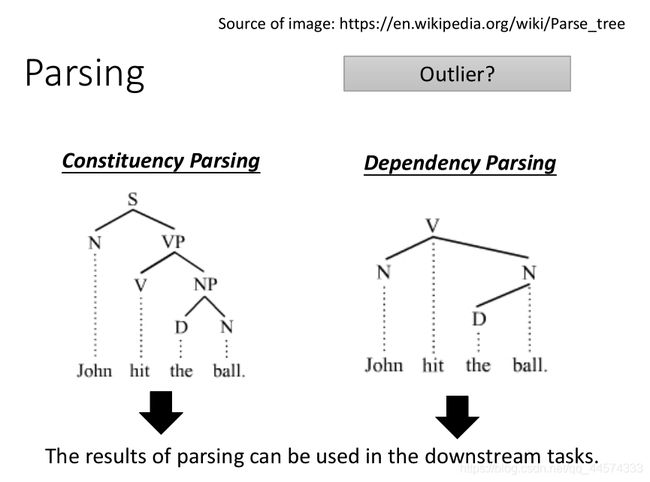
输入:sequence
输出:tree-structure
这个也是常使用的前处理方法,Parsing,输入一个句子,输出一个树状结构。同时Parsing又分为两种:
- Constituency Parsing : 成分句法分析,把句子组织成短语的形式,如上图所示的the ball是一个短语,hit the ball 也是一个短语
- Dependency Parsing : 依存句法分析,表现句子中词的依赖关系,如上图所示的the 和 ball 有一种关系,John和ball有一种关系
这里老师都没讲,是笔者自己查阅补充的,如有错误,恳请指正
Bert其实也学到了Parsing的讯息,作业里就有用Bert读Parsing的任务,那究竟该怎么做 Parsing 呢?具体会另外讲。
2.4 Coreference Resolution 指代消解

输入:sequence
输出:pairs in sequence
还有一个常常为当作前处理的任务,叫 Coreference Resolution 指代消解。它要做的是找出文章里面,哪些词汇属于同一个实体entity,尤其是代名词he she it,具体例子如上图所示。
同样,我们也会把经过指代消解的文章再当做其他NLP任务的输入,所以指代消解也是一个常用的前处理的方法。那究竟该怎么做 Coreference Resolution 呢?具体会另外讲。
2.5 Summarization 摘要

2.5.1 Extractive Summarization 抽取式摘要
输入:sequence
输出:class for each token (此处token为sentence)
Summarization 摘要 又分成两种,过去比较常用的是 Extractive Summarization,抽取式摘要,它所做的就是给机器一篇文章,这篇文章由多个句子组成,机器将其中的几个关键的句子简单地组合在一起作为摘要输出。
那用这种方法可以产生好的摘要么?当然不行,用这种方法很难产生好的摘要,但过去我们觉得机器的能力也就到这边,所以只要求机器做抽取式摘要,不要机器做更复杂的任务。
解法:那 Extractive Summarization 到底要怎么做呢?其实最简单地看来,这就是一个二分类的问题,对于文章中的每一个句子进行二分类,输出Yes/No,如果输出Yes表示要输出到最终的摘要中,No则表示不输出到最终的摘要中。
但是这么做,不会给你一个很好的结果,因为文章中可能有两个很关键的句子,不过它们的意思很像,如果选了其中一个,就不需要选另一个了。如果把句子分开来考虑是不够的,所以有了deep learning技术后,我们可以通过输出整篇文章给模型,如Bi-LSTM或Transformer,再让机器去决定文章中的每一个句子应该被放到摘要里,还是不放到摘要里。

2.5.2 Abstractive Summarization 生成式摘要
输入:sequence
输出:sequence
当然,随着近年来,seq2seq类模型的演化,我们已经可以做 第二种Summarization,即 Abstractive Summarization 生成式摘要,它的意思是说,不要从文章中抽取句子当作摘要,而要机器用自己的话来写摘要。
解法:那怎么让机器用自己的话写摘要呢?这也就是一个seq2seq问题,输入一个long的sequence,输出一个short的sequence,模型使用各种seq2seq模型即可。
但是,在摘要里面,输出的这个短句,和输入的长的句子往往会有共用的词汇。比如把文章中的句子稍作修改、删减可能就会是一个不错的摘要了,此时如果用seq2seq模型来解,就需要模型有copy的能力,那很多人会采取类似Pointer network的架构让模型有能力直接拷贝一些输入直接放到输出里面。
2.6 Machine Translation 机器翻译
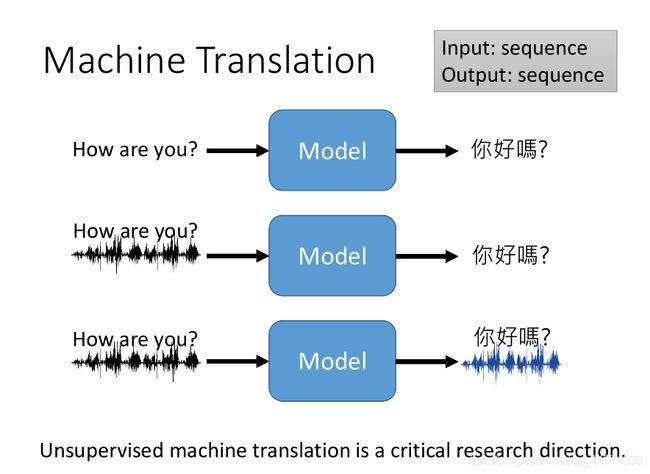
输入:sequence
输出:sequence
Machine Translation 机器翻译所解决的问题就是通过机器来实现多语种的翻译问题。如输入一段英文的sequence,输出一段对应语义的中文sequence。解法:这显然就是一个seq2seq问题。
但是,在机器翻译问题,人们往往想到的都是输入一段文字,输出另外一段文字。其实,今天我们甚至可以做到输入一段英文语音,直接输出一段对应的中文文字,但是为什么要这么直接转换呢?对于英文和中文可能不需要这么做,但是对于一些语言,它们甚至没有文字,那对于这种没有文字的语言,根本不可能做文字对文字的翻译,我们只能通过语音转直接换为普遍使用的语言文字。而且假设两种都没有文字的语言,甚至要做到语音对语音的直接转换的翻译,这种方法在文献上也是存在的,也是有人在研究的。
对 Machine Translation 机器翻译 而言,一个很关键的问题就是 Unsupervised Learning 无监督学习方法如何在机器翻译上使用。因为世界上的语言有非常多,有超过7000多种语言,如果都用Supervised Learning 有监督方法训练模型,我们就需要至少 7000x7000对的成对翻译语料来进行对应翻译模型的训练,这种规模和数据量的翻译语料显然是不切实际的。因此,在 机器翻译 领域很早就有研究如何用无监督学习方法做翻译,比如做中英互译,给机器看很多的英文语料和很多的中文语料,但注意这里的语料都是不成对的,希望机器自动学会把英文翻译成中文,把中文翻译成英文。这种方法今天是有机会实现的,我们之后就会讲这个实现方法的。
2.7 Grammar Error Correction 语法纠错

输入:sequence
输出:sequence
Grammar Error Correction 语法纠错,是指让机器改错字。举例来说,你写了一个错误的句子,“I are good”,输入给模型后希望可以得到正确的语法表示“I am good”。
解法:那像这样的 语法纠错 该怎么训练呢?当然今天就使用seq2seq模型来解决这个问题就可以了,同时也要求模型有一定的copy能力。
但是,还有更细化的方法是,将输入的句子中的每一个token都预测一个class的方式,如上图右侧。每一个词汇有三种可能的类别:
- C:保留
- R:替换
- A:后插入
此时的输入输出就变成了
输入:sequence
输出:class for each token
2.8 Sentiment Classification 情感分析
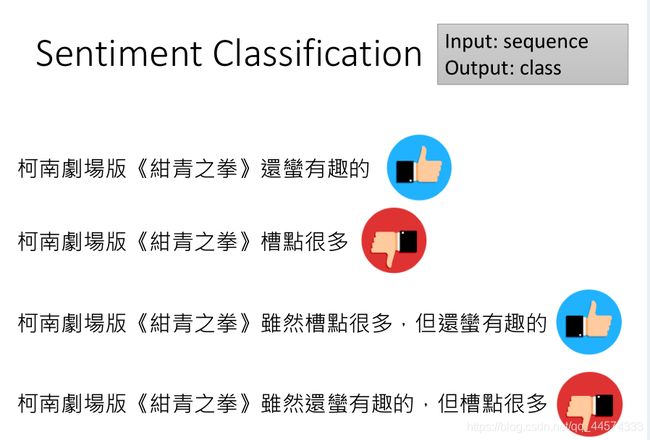
输入:sequence
输出:class
Sentiment Classification 情感分析,就是让机器看一段文字,让它告诉你说这段文字是正面的还是负面的。解法:这样的问题显然就是一个二分类的问题(或者多分类)。情感分析通常被用来用作网络上卖家通过对商品的评论情感分析统计来进行商品判断、电影评价如上图等。
但是,有时候一个句子是会蛮复杂的,可能这一句话里既有负面的词汇又有正面的词汇,如上图的“柯南剧场版《绀青之拳》虽然槽点很多,但还蛮有趣的”,不同的顺序凑起来情绪就不同,也因此若仅使用词汇情绪分数统计的方法其效果不会太好,网上是有很多 多领域、普遍的词汇情感值表的,笔者记得“河流:0.324分”。
本节视频过长,因此笔者将其分写了两篇,之后还会再出一篇只有文字的简略版总结。