【论文阅读】Realtime Robust Malicious Traffic Detection via Frequency DomainAnalysis
【论文阅读】Realtime Robust Malicious Traffic Detection via Frequency DomainAnalysis
原文标题:Realtime Robust Malicious Traffic Detection via Frequency DomainAnalysis
原文作者:Chuanpu Fu, Qi Li, Meng Shen, and Ke Xu
发表会议:2021 ACM Computer and Communications Security Conference(CCS)
原文链接:https://dl.acm.org/doi/10.1145/3460120.3484585
原文源代码:https://github.com/fuchuanpu/Whisper
ABSTRACT
基于机器学习 (ML) 的恶意流量检测是一种新兴的安全范式,特别是对于零日攻击检测,它是对现有基于规则的检测的补充。然而,现有的基于机器学习的检测由于交通特征提取效率低下,检测精度低,吞吐量低。因此,它们无法实时检测攻击,尤其是在高吞吐量网络中。特别是,这些类似于现有基于规则的检测的检测系统可以很容易地被复杂的攻击规避。为此,我们提出了 Whisper,这是一个基于 ML 的实时恶意流量检测系统,它通过利用频域特征实现高精度和高吞吐量。它利用频域特征表示的序列特征来实现有界信息损失,在保证高检测精度的同时,限制特征的规模以实现高检测吞吐量。特别是,攻击者不能轻易干扰频域特征,因此 Whisper 对各种规避攻击具有鲁棒性。我们对 42 种攻击类型的实验表明,与 state-of-theart 系统相比,Whisper 可以准确检测各种复杂和隐秘的攻击,最多可实现 18.36% 的改进,同时实现两个数量级的吞吐量。即使在各种规避攻击下,Whisper 仍然能够保持 90% 左右的检测准确率。
主要贡献
- 在以往基于机器学习检测的基础之上进行改进,可以利用频域特征实现高吞吐量网络中实现实时和稳健的检测。
- 在进行特征编码时,开发了自动编码向量模块,减少了手动编码所需要的工作量,同时保持了检测精度。
- 有着详尽的理论分析,包括特征提取的开销、信息损失程度等。
整体框架
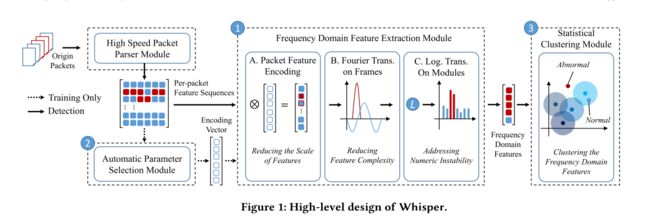
主要包括了以下四个模块。经过特征提取及特征编码,并对数据进行处理保证吞吐量与速度,最终使用统计聚类算法学习频域特征的模式,最终根据特征与聚类中心的距离判断流量类型。
高速数据包解析器模块。高速提取数据包特征,如数据包长度和到达时间间隔,保证处理效率。提取后的特征序列提供给特征提取模块和自动参数选择模块。
频率特征提取模块。提取频域特征,之后将每包特征序列编码为向量,并通过频域提取序列特征。注:不使用深度学习模型提取特征,因为处理延迟较长。
自动参数选择模块。该模块计算特征提取模块的编码向量。我们通过解决一个约束优化问题来决定编码向量,该问题减少了不同的每个数据包特征的相互干扰。
统计聚类模块。在本模块中,利用轻量级统计聚类算法从特征提取模块中学习频域特征的模式。在训练阶段,该模块计算良性流量频域特征的聚类中心和平均训练损失。在检测阶段,该模块计算频域特征与聚类中心之间的距离。如果距离明显大于训练损失,Whisper 会将流量检测为恶意流量。
实验评估
数据集
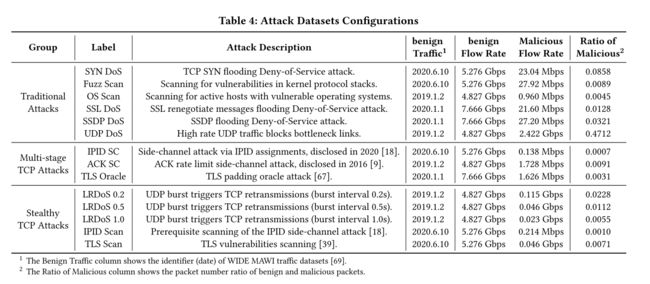
实验所使用的是 WIDE MAWI千兆骨干网络的四个最新数据集。训练时使用了20%的良性流量。
评估指标
真阳性率
假阳性率
ROC曲线下面积:横轴为假阳性率,纵轴为真阳性率的一条曲线
等错误率(EER-Equal Error Rate)
吞吐量
处理延迟
实验结果
准确率


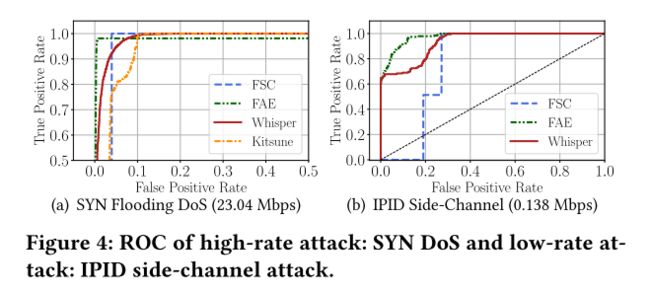
在本实验中,通过测量 TPR、FPR、AUC 和 EER 来评估不同系统的检测精度。表5说明了结果。我们发现 Whisper 可以检测到所有 14 种攻击,AUC 范围在 0.931 和 0.996 之间,EER 在 0.201 范围内。图 3 显示了聚类结果的散点图。为简单起见,我们选择两个具有 2000 个良性频域特征和 2000 个恶意频域特征的数据集,并随机选择两个维度的频域特征。我们观察到恶意流量具有远离聚类中心的频域特征。我们在图 4 中展示了两个数据集的 ROC 曲线。我们发现,通过利用频域特征,检测器可以检测高吞吐量网络中的低速率恶意流量,例如,Whisper 和 FAE 检测 138 Kbps IPID 侧信道恶意流量在 5.276 Gbps 骨干网络流量下,AUC 分别为 0.932 和 0.973。低速率 TCP DoS 攻击中突发间隔的增加导致 Kitsune、FSC、FAE 和 Whisper 的 AUC 分别下降 9.0%、7.0%、0.10% 和 0.06%。因此,与包级和传统流级检测相比,低速率 TCP DoS 攻击中的突发间隔对 Whisper 和 FAE 的检测精度影响可以忽略不计。然而,FAE 无法有效检测一些复杂的攻击,例如 ACK 节流侧信道攻击和 TLS 填充预言机攻击,并且只能达到至少 39.09% 的 Whisper 的 AUC。请注意,Whisper 在 4.8 Gbps 流量中准确识别出 2.3 Gbps 高速率在线恶意流。
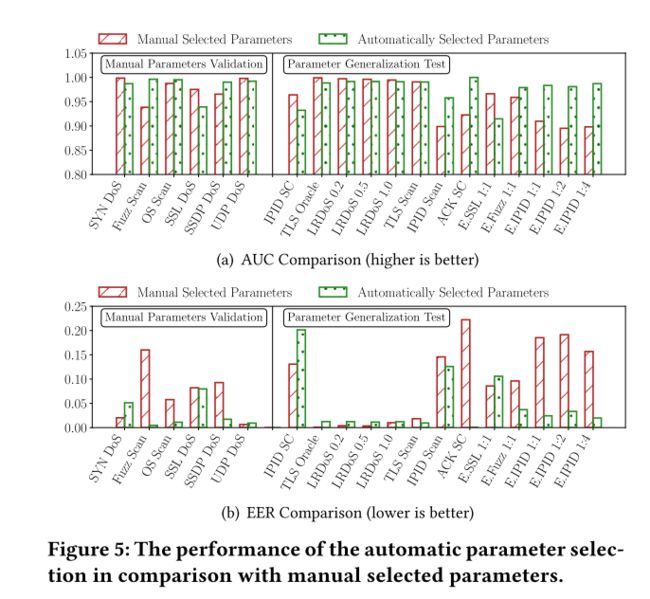
下图显示了在各种参数设置方面的检测精度。可以观察到与手动参数选择相比,自动参数选择模块平均实现了 9.99% 的 AUC 增加和 99.55% 的 EER 减少。
鲁棒性
假设攻击者知道存在恶意流量检测,其可以通过注入各种良性流量来规避检测。假设攻击者将良性 TLS 流量和 UDP 视频流量注入恶意流量,并将其伪装成良性流量进行规避。
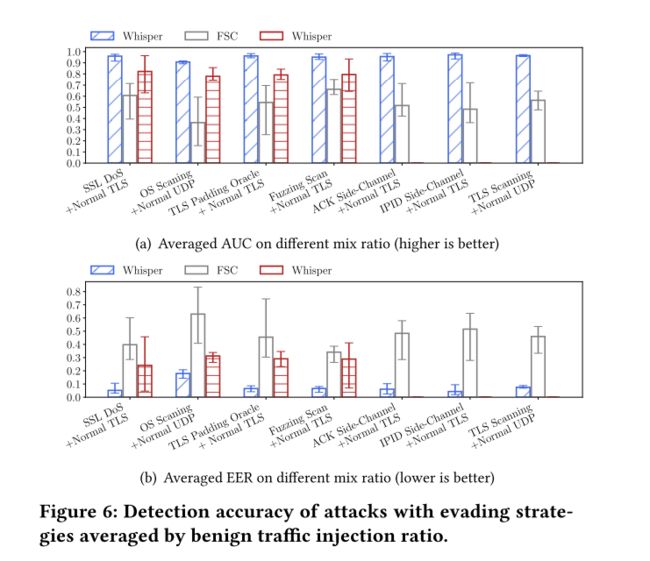
观察到具有高良性流量混合比的规避攻击容易规避检测。从图 6 中,我们得出结论,攻击者无法通过将良性流量注入恶意流量来逃避 Whisper。但是,攻击者逃避了其他检测系统的检测。
检测延迟和吞吐量
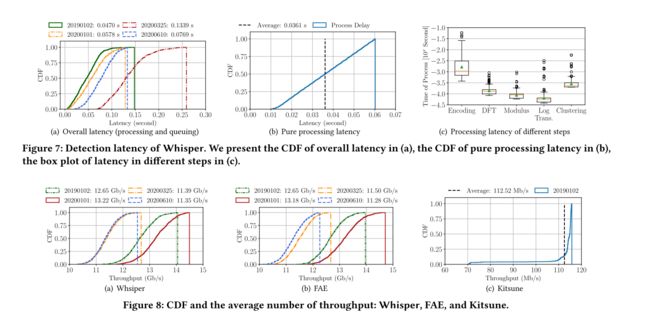
检测延迟。为了测量延迟,我们重放了四个具有不同流量速率的骨干网络流量数据集)。为简单起见,我们使用具有 0.5s 突发间隔的低速率 TCP DoS 攻击作为典型攻击,并测量整体检测延迟,即从发送第一个恶意数据包到检测到流量之间的时间间隔。整体检测时延包括传输时延、排队时延和处理时延。整体检测延迟的累积分布函数 (CDF) 如图 7(a) 所示。通过四个数据集,我们发现 Whisper 的检测延迟在 0.047 到 0.133 秒之间,这表明 Whisper 在高吞吐量网络中实现了实时检测。为了准确测量 Whisper 产生的处理延迟,我们以 0.5s 的突发间隔重放低速率 TCP DoS 数据集,构建轻负载网络场景并测量 Whisper 中四个模块的执行时间。处理延迟的 CDF 如图 7(b) 所示。我们观察到 Whisper 的处理延迟表现出均匀分布,因为大部分延迟是通过在轻负载情况下轮询来自数据包解析器模块的每个数据包特征而产生的。因此,我们可以得出结论,Whisperis 产生的平均处理延迟仅为 0.0361 秒,而 Whisper 引起的排队延迟占据了大部分。
实验的结果表明:Wisper能够在吞吐量最高为13.22Gbps时,在0.06秒检测出恶意流量,而不对检测的准确性造成影响。
设计细节及数学表示
频率特征提取模块
本模块从高速流量中提取频域特征。获取同一流的N个数据包的每个数据包特征。
特征表示。其表示的是,共有N个数据包,每个数据表有M个特征(属性)。
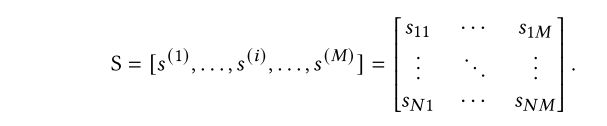
将数据包特征进行编码。对上述S矩阵进行线性变换,将特征编码成实数vi。

可以看到,w应为一个列向量,其将一个数据包的M个属性进行编码为一个实数vi,最终得到v。这一步的作用为,通过特征编码减少了特征的规模,降低处理开销。w的设定在后续“自动参数选择模块”提到。
接下来使用步长Wseg来分割向量,以通过约束数据包之间的长期依赖关系来降低频域特征的复杂性。帧过长会导致学习频域特征时非常复杂。用Nf来表示帧数,fi即为帧。

离散傅里叶变换。对每一帧fi执行离散傅里叶变换(DFT),通过频域提取序列特征,减少流级方法造成的信息损失。如下:

经过傅里叶变换后的结果为复数形式,无法直接作为机器学习算法的输入。因此需要进行处理。
计算复数模。首先将Fik表示为复数形式,即在复平面上为一个点。
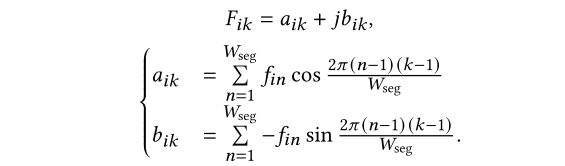
对于每个Fik,计算其复数模(pik)。由于上述fi为序列,则Fi也为序列。经过傅里叶变换加复数模计算操作后,将序列的前半部分组合为向量Pi。这是因为傅里叶变换对于实数向量的结果是共轭的,所以序列是对称的。如下:

对数变换。为了让上述频域特征稳定,防止机器学习训练中的浮点溢出,对Pi进行对数变换,并使用常数调整范围。
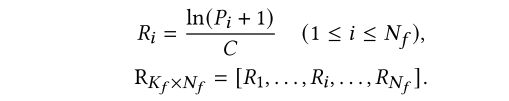
作为特征提取模块的输出,R的ℎ列分量是ℎ帧的频域特征。矩阵 R 是统计聚类模块的输入。
实现时作者收集了三种类型的良性流量(90%)和恶性流量(10%)。每种类型的流量选择了1500个连续数据包,即N=1500。每个数据包有三个属性,数据长度、协议类型和到达时间间隔,即M=3。
得到频域特征R之后,执行了最小-最大归一化操作,并将结果映射到RGB空间中进行可视化,如下图所示。最终可以看到恶意流量的品与特征相关区域明显较暗。

自动参数选择模块
上个模块提到,进行特征序列编码时需要用到编码向量w。作者将编码向量选择问题表述为一个有约束的优化问题,通过求解SMT问题来逼近原始问题的最优解。
首先,对于每个数据包的特征,可以将其看作是连续函数的采样。也就是说,对于N个数据包,其都有例如数据包长度的特征,该特征符合某连续函数,即这N个数据包在该特征上的取值可以看做是对该函数的取样。
选择参数时,作者考虑了以下几个方面:
-
编码向量w的范围和叠加函数的范围限定:
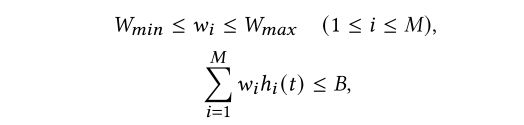
-
约束函数的顺序保留属性,以确保在特征提取模块执行数据包编码时,不同类型的每个数据包特征不会相互干扰(?):
![]()
- 优化以最大化函数之间的距离,以便我们可以最小化每个数据包特征的相互干扰并限制所有函数的范围。
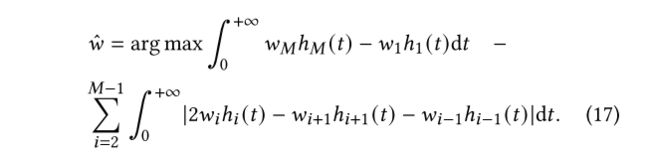
由于数据包是有限的,因此hi(t)的封闭形式不可用,即t无法趋近于正无穷,也就无法确定优化对象的凸性。作者将原点约束优化问题改造成具有优化对象 (18) 的可满足性模理论 (SMT) 问题 (19),以逼近上图公式最优解。
关于优化问题这篇文章讲的很清楚。
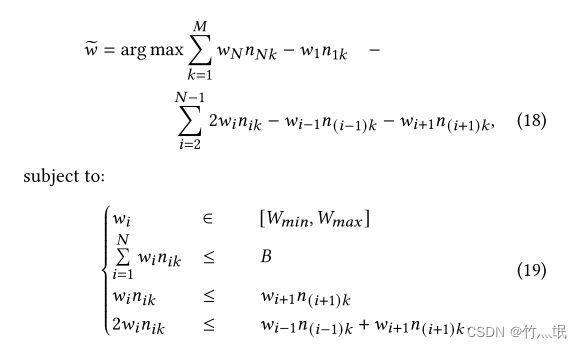
另外,作者提到将优化对象 (17) 中的绝对值运算改造成约束 (19),因为大多数 SMT 求解器不支持绝对值运算。
在实验部分,作者指出使用的是Z3 SMT求解器来解决SMT问题。
这里产生了一个疑问,显然17中的对绝对值求积分之后为正值,但在19中第四个约束中可以看到18中原求积分部分结果显然为负值,与之前17中的矛盾。
统计聚类模块
由于之前进行编码向量时考虑到的顺序保留属性,作者为了提高Whisper的鲁棒性并减少由极值引起的误报,其将频域特征矩阵R分割为长度为Wsin的采样窗口,用Nt来表示采样的数量,l表示起点。
则聚类算法的输入如下图所示。

执行聚类算法并获取所有聚类中心,用其来表示良性流量模式。用Ck表示Kk聚类中心。然后对每个ri,找到距其最近的聚类中心Ci,将平均L2范数作为训练损失train_loss。
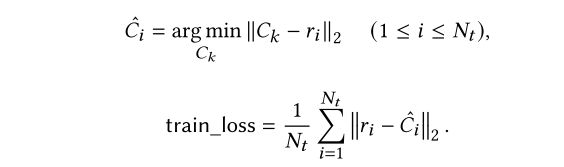
在检测时,计算流量频域特征切片后的ri与最近聚类中心之间的距离,计算L2范数作为估计误差。如果该误差明显大于某个阈值(x*train_loss),则可以认为流量是恶意的。
![]()
问题
-
design detail部分提到使用的是提取每个数据包的三个属性( = 3),包括数据包长度、协议类型和到达时间间隔
这个属性指的是特征吗?如果是的话,在实验部分又提到“选择两个具有 2000 个良性频域特征和 2000 个恶意频域特征的数据集”。
-
另外就是自动参数选择模块中提到的关于去掉绝对值的问题
感觉貌似是我理解错了,懂行的大佬评论区见