TGRS2021:Road Segmentation for Remote Sensing ImagesUsing Adversarial Spatial Pyrami对抗性空间金字塔网络的道路分割
TGRS2022:Road Segmentation for Remote Sensing ImagesUsing Adversarial Spatial Pyramid Networks基于对抗性空间金字塔网络的遥感图像道路分割
- 0.摘要
- 1.概述
- 2.方法
-
- 2.1.背景
- 2.2.生成器结构
- 2.3.鉴别器架构
- 2.4.真实图像测试
- 3.实验
-
- 3.1.数据集和实验设置
- 3.2.鉴别器的感受野分析
- 3.3.消融实验
- 参考文献
论文下载
0.摘要
道路提取在遥感图像中具有重要的应用价值。由于背景复杂、密度大,现有的方法大多无法准确提取出正确完整的路网。此外,他们还面临训练数据不足或人工标注成本高的问题。为了解决这些问题,我们引入了一种新的模型,将结构化域自适应应用于合成图像的生成和道路分割。我们将特征金字塔(FP)网络引入生成式对抗网络,以最小化源域和目标域之间的差异。一个发生器被学习产生高质量的合成图像,而鉴别器试图区分它们。我们还提出了一个FPnetwork,通过从网络的所有层中提取有效的特征来描述不同尺度的对象,从而提高了所提模型的性能。事实上,引入了一种新的尺度智慧架构来学习多级特征映射并改进特征的语义。为了优化模型,采用联合重建损失函数对模型进行训练,使伪图像与真实图像之间的差异最小化。在三个数据集上的大量实验证明了该方法在准确性和效率方面的优越性能。
1.概述
本文的直观想法是探索新的架构,以最小化源和目标域之间的特征空间差距,这可以提高对抗性学习的性能,生成真实的合成rs图像,用于道路分割。训练该网络将源图像的特征映射转换为目标图像的特征映射,同时保留特征的语义信息。我们提出了一个通用和轻量级的网络架构,可以很容易地集成到生成器。我们还引入了一个高效的空间金字塔网络来提取多尺度和全局上下文信息。提出的对抗性空间金字塔网络(ASPN)不需要从实际上不存在的对应域中匹配图像对。据我们所知,这是第一个将空间特征金字塔(FP)网络与RSroad分割的对抗性域适应集成在一起的工作。与现有方法相比,本文提出的无监督域适应体系结构具有以下优点:
- 网络体系结构:以往的方法[13]、[14]一般都是通过中间的特征空间基于两个域,从而隐含地对两个域采取相同的决策函数。ASPN利用多尺度特征映射与条件生成器和剩余学习;该架构的所有模块都被放置在一个单一的网络中,并拥有一个端到端的培训策略。
- 在生成器中,我们提出了一种高效的金字塔网络结构来提取多尺度的有效金字塔特征,以克服现有模型的局限性。在该金字塔网络中,首先提取并融合多尺度特征作为基础特征;接下来,我们将它们输入优化的u形网络(OUN:optimized U-shape network)[1]和特征模块级联(FMC),以产生额外的描述性和多尺度特征。我们还使用了名为scale-wise feature concatenate (SFC)的模块,它类似于初始网络[5],在广泛的尺度上合并特征。最后,收集相同大小的特征图,形成最后的FP。
2.方法
图1:所提出的金字塔域自适应网络的总体架构。
我们打算在有标记数据集的源域开发一个道路分割模型,并将系统推广到有未标记数据集的目标域。在本节中,我们首先介绍了GAN的背景,并描述了基于域适应结构的ASPN模型的设计。然后,我们讨论了所提出的架构的细节。
2.1.背景
GANs通常包含一个跟踪随机噪声的发生器(G)和一个鉴别器(D),前者用于创建样本,后者用于从真实样本中识别出虚假样本。条件GAN的基本框架可以观察到作为一个博弈和d之间,以找出最小最大问题的平衡
![]()
n∈Rdn是N(0,1)或U[−1,1]分布中的隐藏变量。为了生成基于输入的模型,DNN通常应用于G和D。在该体系结构中,生成器以合成图像的附加特征xs为条件。训练时,生成器G(xs,n;θG)=xsconv4+Gˆ(xs,n;θG)将合成的特征映射和噪声映射转换为调整后的特征映射。值得注意的是,在真实图像和合成图像的第四卷积层特征图之间的残差特征表示为Gˆ(xs,n;θG),而不是由生成器直接计算的计算xfm
期望xfm保持xs的真实语义。因此,xf输入鉴别器D (x,θD)和分类器T (x,θT)。在这里,鉴别器D(x,θD)的任务是在最后阶段从目标域的真实图像的特征映射中识别生成器创建的转换后的特征映射。分类器T (x,θT)将标签分配给输入图像中的每个像素,称为反卷积层[36]。图1说明了提出的ASPN模型的总体结构。目标是优化下面的min-max函数
![]()
∂是一个控制损失的权重。ld表示领域损失
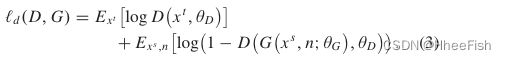
在反卷积中,我们引入了多项式函数损失lf(交叉熵损失)。

而∑|Ps|i=1和∑Scj=1决定了|Ps|的像素以及Sc语义类别的总和,1yi=k是第i个像素的独热编码。利用多尺度金字塔网络进行变换。多层感知器的实现是无差别的。在两个层次之间寻求最小-最大优化。通过第一级,鉴别器和像素级分类器经常更新,而条件生成器和特征提取器卷积1 - 4和单个OUN保持完整。在下一层,D稳定,而我们更新G, OUN和卷积1 - 4。应该认为它是用提取的和可推断的基础特征图训练的。使用提取的特征图训练T能导致类似的效率,同时由于GAN的稳定性问题,需要几轮初始化和多学习率。事实上,如果模型没有在源数据上得到训练,就有可能发生移位作业(例如class1变为2),目标函数仍然是最优的。Tenget al.[13]提出了在源图像和自适应图像上同样地训练分类器,消除了类的移位,显著地稳定了训练。一般来说,当G接受随机先验z∈Rr来优化个体参数时,两者的G和D都是循环重复的,θg和θd产生如下:

其中为小批量,为步长。事实上,在训练开始时,可以训练g来充分利用log(D(G(z)),而不是减少log(1−D(G(z)),以提供更强的梯度
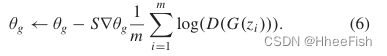
因此,我们的模型采用(6),因为它的性能更稳定。通过使用基础网络进行预训练,GAN能够产生更多的分布式记录。在这项工作中,我们提出了具有编码/解码路径的OUN(详细信息将在下一节中介绍)。因此,预训练解码器Dec可以选择合适的pixelsfromG(z)来恢复图像Dec(G(z))。对于给定的输入,训练Dis区分合成样品Dec(G(z))和真实onex。对所提出的模型进行如下训练:
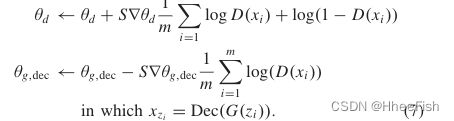
G的目的是生成无法与真实样本区分的样本。因此,G可以学习将不同的随机先验映射到相同的合成输出中,而不是创建不同的合成输出。这个问题被称为“模式崩溃”,发生在GAN 优化方法是求解最小-最大问题的时候
在我们的模型中使用了小批量平均,这是由小批量识别[37]的哲学驱动的。它为d提供了获取真样品和假样品(x1,x2,…,和G(z1),G(z2))的小批量的入口,而分类样品。给定一个样本来区分,小批量计算给定样本和小批量中其他样本之间的差距。Minibatch显示了小批量样本D的平均值,因此目标修改如下:
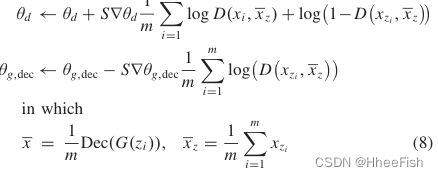
m表示小批量的大小。因此,在提供的样本上把小批的平均值串联起来并输入D
2.2.生成器结构
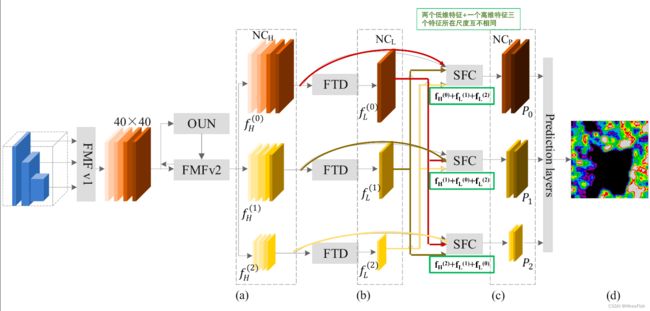
图2所示。FP网络的体系结构。(a)高维特征(b)低维特征©FP(d)特征图。
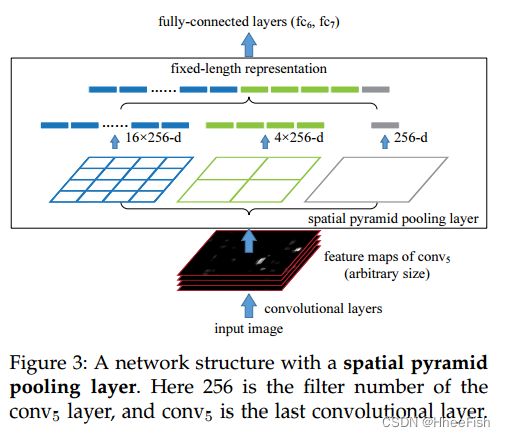
该生成器的目的是产生与真实图像相似的合成图像,以最小化域间隙。为了实现这一目标,我们提出了一个带有多个连接的FP网络来增强合成图像的表示,以及一些有助于检测多尺度目标和生成精确特征图的变换。FP中基于自底向上卷积网络的特征映射不能满足由深度变换函数实现的上层特征映射的需求;相比之下,浅层转换单元获得的低层特征映射也不能跨越限制小目标检测性能的第二个属性。此外,每一个生成的特征图都只是对应尺度的输出,所以其他尺度的相对信息无法成功合成。克服这些限制的一种选择是应用具有适当深度的转换函数,以保留足够的空间信息和高级语义信息。FP网络的结构如图2所示。在该模型中,利用骨干网和多级FP网络提取特征,然后通过非最大抑制(NMS)操作从输入图像生成特征映射。拟议的生成器网络包括四个部门。特征映射融合(FMF)、优化U形网络(OUN)、特征运输部门(FTD)和尺度特征拼接(SFC)。FMFv1通过结合主干的特征映射增强了基本特征的语义信息。OUN产生大量的多尺度特征集合,然后应用FMFv2将OUN产生的特征与基本特征融合,提取多阶段多尺度特征。连接的特征映射再次提供给下一个OUN(有六组OUN+FMFv2)。第一个OUN是刚从Xini那里学到的。最终的多级多尺度输出特征计算如下:
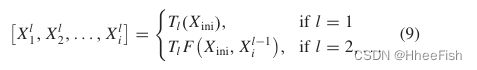
Xini表示从基础网络中提取的初始特征,Xli表示在第l个OUN中具有尺度i的特征,L表示OUN的总数,Tl表示第l个OUN的实现,F代表FFMv1的实现。此外,SFC通过尺度特征插值函数和调整后的注意方法来收集多阶段FP。各分部的详细情况如图3所示

图3所示。几个模块的详细结构。(一)OUN。(b) FMFv1。© FMFv2。(d) FTD。(e) SFC,块内的数字表示输入通道,Conv内核大小,步幅大小,输出通道
- 基本网络结构
与[4]类似,采用ResNet-101和VGGNet-16作为基网。在该FPnetwork中,ResNet-101和VGGNet-16的最后一层FC层通过卷积层进行切换,对它们的参数进行分段采样。在基网络中,第l层的输出表示为bl,骨干网的输出表示为Bnet ={b1,b2,…,bL},因此预测特征映射集可以表示为:
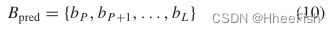
其中P>>l3。当P
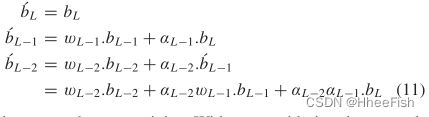
w和α是权重。不考虑通用化损失:

其中,Wl表示第二层输出生成的权重,最终特征表示为
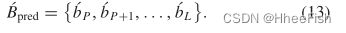
从(12)可以看出,最终特征(b’l)对应于合并(bl,bl+1,…,bL)。增强浅层信息的方法之一是与深层特征层次的线性组合 - FMF特征映射融合

(b) FMFv1。© FMFv2
该部门的任务是融合从不同层次提取的特征,并有一个规则来构建最后的多级金字塔特征图。首先,1×1卷积层用于压缩输入特征的所有通道,其次,为了组合这些特征映射,应用了拼接。特别的是,FMFv1从骨干网接收三个不同尺度的特征映射作为输入,它有两个不同的尺度上采样函数,可以将深度特征重新缩放到同等尺度,然后再进行特征拼接。另一方面,FMFv2接收到两个相同比例的特征图作为输入,一个是基本特征,另一个是前一个OUN的最大输出特征映射,我们生成下一个OUN的融合特征。这两个部门的详细结构分别如图3(b)和©所示。
- OUN优化U形网络
 与其他FP网络[1]、[4]相比,在所提FP网络中,使用了OUN,其细节如图3(a)所示。下采样路径有5个步幅为2的3×3卷积层序列。上采样路径接收不同层的结果作为它的参考集,而其他方法只接收残差网络骨干[36]中每一阶段最后一层的结果。此外,为了提高学习性能和保持特征的平滑性,在上行采样路径的每次上采样和相加过程后添加1×1卷积层。在每个OUN中(使用6个),上采样路径中的所有输出都配置了现阶段的多尺度特征。总体上,OUNs的叠加构建了从浅层到深层的多级多尺度特征。
与其他FP网络[1]、[4]相比,在所提FP网络中,使用了OUN,其细节如图3(a)所示。下采样路径有5个步幅为2的3×3卷积层序列。上采样路径接收不同层的结果作为它的参考集,而其他方法只接收残差网络骨干[36]中每一阶段最后一层的结果。此外,为了提高学习性能和保持特征的平滑性,在上行采样路径的每次上采样和相加过程后添加1×1卷积层。在每个OUN中(使用6个),上采样路径中的所有输出都配置了现阶段的多尺度特征。总体上,OUNs的叠加构建了从浅层到深层的多级多尺度特征。 - FTD特征运输部门

在FTD中,为了提高计算效率,实现了三个卷积层,尺寸分别为1×1、3×3和1×1,以减少信道数。此外,对于输入归一化和激活,使用批量归一化(BN)和参数校正线性单元(PReLU)。FTD中的1×1卷积将特殊特征映射通道NCH=D减少一半,NC是FTD的输出通道数 - 特征金字塔池Feature Pyramid Pooling
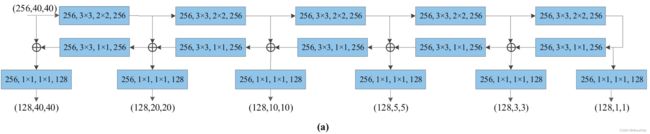
在分类和分段任务中,池层被广泛使用,1这些层不仅在空间上减小了特征图的大小,而且结合了子区域的上下文信息。[34]引入了一个模型,该模型使用不同的子区域池大小来生成FP用于目标检测和分割。如果基础网络生成带有D通道数的尺寸为W×H的特征图,首先到每个高维FP,池化,FH={f(0)H,f(1)H,…,f(N-1)H},f(n)H特征图空间大小为(W/2n)×(H/2n),表示第n阶段的FH, N表示金字塔的等级。因此,对特征映射进行降采样可以将空间大小减少一半。之后,FTD被用来减少信道数。同时,具有低维FP池的FTD输出表示为FL={F(0)L,F(1)L,…,F(N-1)L},而减少的通道数为CL=D/(N−1) - SFC尺度特征拼接
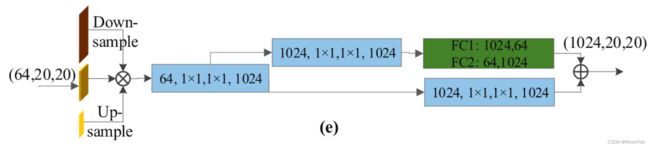
这一层的规则是结合OUNs逐步产生的多尺度特征来生成多尺度FP图。详细情况如图3(e)所示。首先,SFC将相同的尺度特征沿着通道维度连接在一起。由于SFC单元重用FL的特征图,我们可以高效地提取不同尺度的上下文信息获得具有NCp通道数的Pn。在SFC中,来自FH的特征映射与FL的特征映射通过跳跃连接进行聚合。因此,输出通道的数量达到2D/N,因此,聚合的特征图具有2D通道。连接后的FPs可以表示为X=[X1,X2,…,Xi],其中Xi=Concat(X1i,X2i,……,XLi)∈R(Wi×Hi×NC)表示尺寸为第i大的特征.在对不同比例的FPs应用聚合后,这个划分的输出包含了来自几个层深度的特征。然而,仅仅应用简单的聚合是不够的。因此,通道关注模块用于强制特性关注最具代表性的通道。全局平均池化[38]用于创建信道统计GP∈RNC组合段。为了精确地捕获通道依赖关系,如下所示使用两个完全连接的层
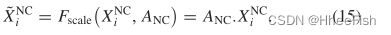
在整个网络训练之前,我们在数据集上对主干进行预训练。所提出的FP网络的输入大小为320×320,网络包含6个OUNs,其中每个OUN在下采样路径上有5个卷积层,在上采样路径上有5个卷积层,因此输出特征有6个不同的尺度。为了减少参数的数量,我们只对其OUN特征的每个尺度分配256个通道;因此,网络可以简单地在gpu上训练。在六个金字塔特征的基础上分别添加两个卷积层,实现位置回归和分类。在金字塔特征的每个像素上,设置6个三比值的锚点,概率评分(阈值)为0.05,以剔除得分较低的锚点。将阈值降低到0.01可以提高性能;然而,它也增加了处理时间
2.3.鉴别器架构
如图1所示,训练鉴别器来区分源域图像和目标域图像中所创建的特征。它接收矢量化的特征映射作为输入,并将它们传递给三个FC层,然后是一个带有softmax功能的分类层。FC三层的输出尺寸分别为4096、4096和1024。通过对真实图像和虚假图像的区分,提出了一种对抗损失算法,以帮助生成器生成与真实图像非常相似的合成图像表示。
2.4.真实图像测试
在测试部分,我们使用[39]中报告的以前的工作。真实图像经过特征提取器、卷积和OUN层,然后使用像素分类器进行道路分割[39]。生成器和鉴别器将不参与,所提出的体系结构应该具有几乎相似的解释复杂性。该模型通过一个NVIDIA GTX GeForce 1080 Ti GPU实现4.48 fps。为了讨论ASPN的计算代价,我们首先考虑一个双标头金字塔网络[36]。这里,I(j×j)表示图像,l=d(I)表示粗化图像,h=I−u(d(I))计算高通。为了简化计算,我们使用了一个不同的算子来生成图像。我们取(I)作为2×2pixels的每个不相交块的平均值,并作为从2×2块中消除平均值的因子。随后,u的秩为3d2/4,在这里,我们给u的范围赋了一个标准正交基,因此,i和(l,h)之间的线性映射是幺正的。为了创建一个概率密度p on Rd2,我们如下所示:
![]()
如果qi大于等于0,∫baq1(l)dl=1,并且对任意常数l都有∫baq0(l,h)dh=1,验证PHA是否为统一总体
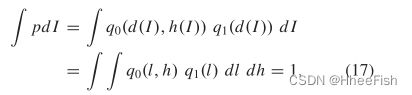
为q1取一组训练样本(l1,…,lN0),并相应地构造密度函数如下
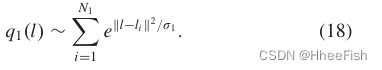
为了定义
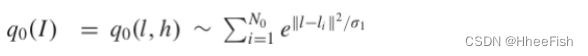
我们设置l=d(I),类似的方法用于每个更精细的尺度,而金字塔网络具有更多的层级。应考虑到,通常每个标度的低通滤波器被使用.此外,我们测量模型的真实高通与生成的高通样本。因此,使用有M层级数的金字塔,最后的对数似然计算如下:
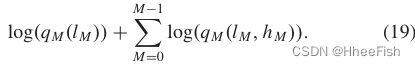

3.实验
在本节中,我们将详细说明使用数据集、实验结果,并将ASPN模型与其他模型的性能进行比较
3.1.数据集和实验设置
为了准确评估所提出模型的性能,我们在实验中使用了三个道路检测数据集。这些数据集具有从不同距离捕获的对象的不同分布和密度。为了提高训练样本的多样性,我们对数据增强进行了以下更改。
1) 随机垂直和水平翻转。
2) 随机转换[−8,8]像素。
3) 范围[1,1.5]内的随机缩放
实验数据如下:
1) DeepGlobe道路提取数据集:这是一个来自印度、泰国和印度尼西亚的2-tiles数据集。道路提取数据集具有复杂的道路环境。数据集保存6226个训练图像和2344个测试和验证图像。每个图像的大小为1024×1024,图像像素的地面分辨率为0.5m/像素。我们使用所有训练样本对主干进行预训练,使用1169个样本对网络进行训练,并忽略重复图像。
2) 马萨诸塞州道路数据集3:该数据集由马萨诸塞州的1711张图像组成。每个图像的大小为1500×1500像素,空间分辨率为1 m/像素,由红色、绿色和蓝色通道组成。该数据集是从航空图像中收集的。图像的基本真相包括两类,道路和非道路。
3) EPFL道路分割数据集4:数据集由150幅航空图像组成。每个图像的大小为400×400像素,空间分辨率为1m/像素。
在我们的条件GAN实验中,我们使用ResNet-101[46]作为骨干网络。我们使用VGGNet-16[47]对其进行初始化,并使用Adam优化器[48]进行训练。最小批包含来自源域的五个图像和来自目标域的5个图像。ASPN通过使用深度学习开源库Keras2.1.2和TensorFlow1.3.0 GPU作为后端深度学习引擎来实现。所有实现都使用Python 3.6。网络的所有实现都是在配备了一个Tel i7-6850K CPU、一个64 GB Ram和四个NVIDIA GTXGeforce 1080 Ti GPU的工作站上进行的,操作系统为Ubuntu16.04。
所有图像的大小都调整为320×320,因此,第一个卷积层输出的特征图为[64,320,320]。因此,n是一个320×320矩阵,基于正则分布NIJ进行采样u~(−1,1). 第一个卷积层特征映射作为附加信道连接起来,并反馈到所提出的金字塔网络。为了使用ResNet-101主干网训练建议的金字塔网络,整个训练时间花费5天,而使用VGG-16主干网,整个训练时间花费2.5天。
表1马萨诸塞州道路试验数据集上平均IOU和IIOU百分比、FID、参数数量(PARAM)和计算速度(FLOPS)的性能比较
在表1中,我们比较了ASPN与其他方法的性能;我们还评估了我们的模型在有和没有提出的金字塔网络的情况下的性能。在表1中,我们讨论了以下方面:主干网络类型、网络的初始输入大小、模型策略和模型的测试结果。我们还报告了在MassachusetsRoad数据集的不同设置下提出的金字塔网络的性能。
值得注意的是,具有VGG-16主干的拟议金字塔网络具有最佳性能,即使具有更强大的主干,其性能也优于其他最先进的模型。Huang等人[9]的IoU为25.6,Zhuet等人[24]使用FCN的IoU是41.7,Shrivastava等人[45]使用ResNet-101的IoU则为44.5,而Ouofhong等人[11]使用VGG-19的IoU即为45.5。针对两种类型的输入大小(512×512和320×320),基于不同的网络设置(4、6和8个OUNs,同时使用ResNet-101或VGG-16作为主干网络)评估了建议的ASPN模型的性能。在512和320输入图像大小上与FCN组装的ASPN的IoU分别为44.8和44.6。结果表明,在其他实现中,具有6个OUN和256个通道数的ASPN具有最佳性能。同时,8个OUNs的ASPN的性能几乎等于6个OUNs,但计算成本更高。此外,在ASPN中,VGG-16和ResNet-101在较大尺寸的输入图像上具有更好的性能,而在512×512的图像尺寸上,VGG-16的ASPN实现了最佳性能
3.2.鉴别器的感受野分析
图4.来自合成图像的样本和不同模块中注意力图的可视化。(a) 合成图像。(b) C4+FP的注意力图。(c) C1+FP的注意力图。(d) 注意图C4.(e)注意图C3.(f)注意图C2.(g)注意图C1
在图4中,我们展示了由ASPN生成的一些合成样本,以及融合多尺度特征图后注意力图的可视化。事实上,图4显示了在合成图像生成中使用多级和多尺度特征的效果。在鉴别器中,类似于[23],70×70的感受野用于检查不同等级的每个结构。鉴别器使用随机马尔可夫理论进行分类。在这种方法中,即使图像中的单个n×n个图像被视为伪图像,分类器也会将该图像作为伪图像进行计数。在鉴别器中完全连接层之前添加的卷积层显著增加了感受野的大小,而不增加模型深度和添加新参数。
3.3.消融实验

图5.定性结果。(a) 输入图像。(b) 这是注释的基本事实。(c) 通过ASPN(我们的)进行边界检测。(d) ASPN的测试结果(我们的)。(e) Hong等人的测试结果[11]。(f) Sun和Wu的测试结果[12]。红色矩形区域是特写,以便更好地显示
在本节中,我们评估了不同模块对所提出的ASPN模型性能的影响。表一和表二报告了ASPN和其他最先进方法的结果。已经观察到,域自适应模型比其他方法性能更好。ASPN与其他数据集相比,所有三个数据集的IoU和iIoU都更高。ASPN的IoU(最低3.8%)高于其他基线,并明确证明了推荐方法的熟练性。与其他方法[11]、[12]、[23]、[45]相比,ASPN优于它们,差距为3.5%∼5.3%。从表II和图5中,我们注意到来自EFPL和马萨诸塞州的适应性高于DeepGlobe,这主要是由于训练图像的数量和图像的结构。此外,我们在图6中显示了分割结果和合成数据量之间的趋势。
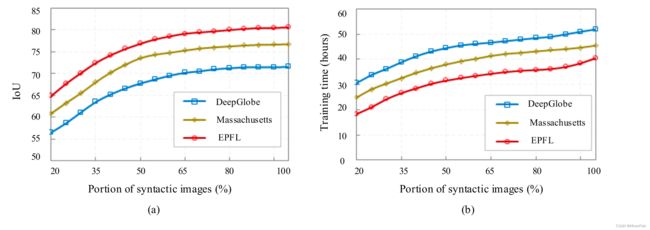
图6(a)合成图像的部分相对于IoU的变化。(b) 合成图像部分随训练时间的变化
图6(a)显示了在所有三个数据集上提出的模型的IOU。结果表明:1)采用更多的合成图像可以显著提高性能。例如,数据增加30%,可以将IoU提高9.5%。我们的模型的最佳性能分别在EFPLand和Massachusetts数据集上进行,因为这些数据集中的标签地图是通过光栅化道路中心线生成的,平均线厚度约为15-20像素,没有平滑。另一方面,DeepGlobe数据集是基于边缘的数据集,根据图像上道路的宽度进行注释。在该数据集中,道路标签的平均宽度约为10像素。因此,由于DeepGlobe数据集中图像的slim roadson,我们的模型没有在此数据集上具有高性能;2)除了合成数据的数量之外,图像的多样性对于训练好的模型也非常重要。图6(b)显示了具有不同合成数据量的ASPN的训练时间
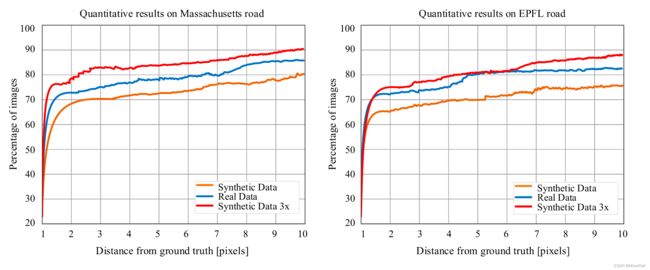
图7.来自马萨诸塞州和EPFL数据集的真实图像测试集上道路分割的定量结果。对于合成图像的多个训练样本(3×表示数据集的100%),曲线图表示累积曲线,作为距离地面真相关键点位置的函数。
图8.以行索引(图5中从上到下)为水平轴的合成图像上,上述两种方法和所提出的具有和不具有SFC模块的ASPN的定量比较。(a) PRI。(b) 瞧。(c) GCE。(d) BDE。
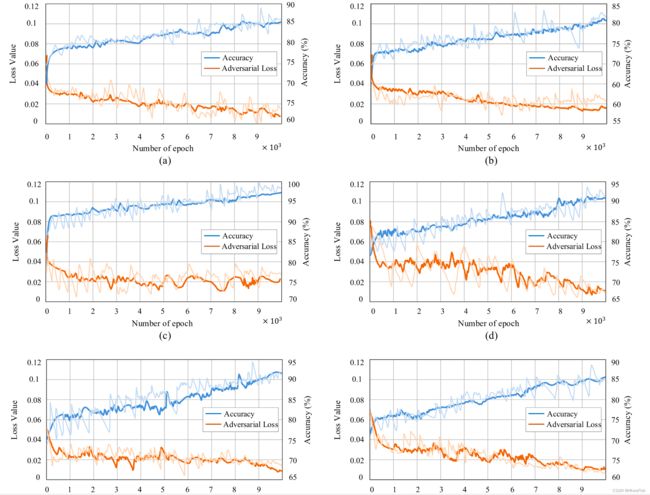
图9.在EPFL上应用跨域训练时准确性和对抗性损失之间的关系↔马萨诸塞州,EFPL↔DeepGlobe,马萨诸塞州↔DeepGlobe数据集。(a) EPFL↔马萨诸塞州。(b) EPFL↔DeepGlobe。(c) DeepGlobe↔EPFL。(d) 马萨诸塞州↔DeepGlobe。(e) DeepGlobe↔EPFL。(f) DeepGlobe↔马萨诸塞州
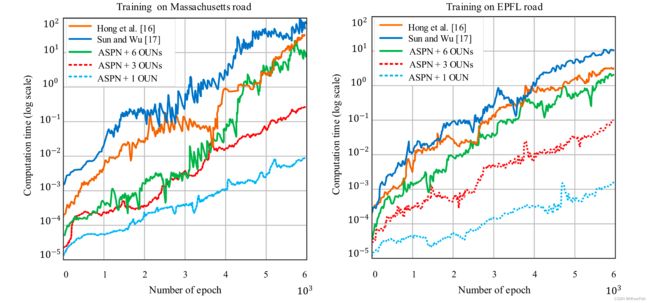
图10.在马萨诸塞州和EPFL数据集上训练时计算时间与迭代次数的关系。浅蓝色、红色和绿色分别指1、3和6盎司的Propose型号。橙色表示孙和吴的表现[12],深蓝色表示洪等人的表现[11]
参考文献
[1] Q. Zhao, T. Sheng, Y. Wang, Z. Tang, Y. Chen, L. Cai, and H. Ling,“M2Det: A single-shot object detector based on multi-level featurepyramid network,” inProc. AAAI Conf. Artif. Intell., vol. 33, 2019,pp. 9259–9266.
[2] C. Li, R. Cong, J. Hou, S. Zhang, Y. Qian, and S. Kwong, “Nestednetwork with two-stream pyramid for salient object detection in opticalremote sensing images,”IEEE Trans. Geosci. Remote Sens., vol. 57,no. 11, pp. 9156–9166, Nov. 2019.
[3] C. Henry, S. M. Azimi, and N. Merkle, “Road segmentation in SARsatellite images with deep fully convolutional neural networks,”IEEEGeosci. Remote Sens. Lett., vol. 15, no. 12, pp. 1867–1871, Dec. 2018.
[4] X. Chen, X. Lou, L. Bai, and J. Han, “Residual pyramid learning forsingle-shot semantic segmentation,”IEEE Trans. Intell. Transp. Syst.,vol. 21, no. 7, pp. 2990–3000, Jul. 2020.
[5] B. Yu, L. Yang, and F. Chen, “Semantic segmentation for high spatialresolution remote sensing images based on convolution neural networkand pyramid pooling module,”IEEE J. Sel. Topics Appl. Earth Observ.Remote Sens., vol. 11, no. 9, pp. 3252–3261, Sep. 2018.
[6] Y. Li, L. Guo, J. Rao, L. Xu, and S. Jin, “Road segmentation based onhybrid convolutional network for high-resolution visible remote sensingimage,”IEEE Geosci. Remote Sens. Lett., vol. 16, no. 4, pp. 613–617,Apr. 2019.
[7] Y. Liu, J. Yao, X. Lu, M. Xia, X. Wang, and Y. Liu, “RoadNet: Learningto comprehensively analyze road networks in complex urban scenes fromhigh-resolution remotely sensed images,”IEEE Trans. Geosci. RemoteSens., vol. 57, no. 4, pp. 2043–2056, Apr. 2019.
[8] J. D. Bermudez, P. N. Happ, R. Q. Feitosa, and D. A. B. Oliveira, “Syn-thesis of multispectral optical images from SAR/optical multitemporaldata using conditional generative adversarial networks,”IEEE Geosci.Remote Sens. Lett., vol. 16, no. 8, pp. 1220–1224, Aug. 2019.
[9] B. Huang, H. Zhang, H. Song, J. Wang, and C. Song, “Unified fusionof remote-sensing imagery: Generating simultaneously high-resolutionsynthetic spatial–temporal–spectral Earth observations,”Remote Sens.Lett., vol. 4, no. 6, pp. 561–569, Jun. 2013.
[10] C. Xu and B. Zhao, “Satellite image spoofing: Creating remote sensingdataset with generative adversarial networks (short paper),” inProc.10th Int. Conf. Geographic Inf. Sci. (GIScience). Wadern, Germany:Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik, 2018, pp. 67:1–67:6,Art. no. 67.
[11] W. Hong, Z. Wang, M. Yang, and J. Yuan, “Conditional generativeadversarial network for structured domain adaptation,” inProc. IEEEConf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 1335–1344.
[12] W. Sun and T. Wu, “Learning spatial pyramid attentive pooling in imagesynthesis and image-to-image translation,” 2019,arXiv:1901.06322.[Online]. Available: http://arxiv.org/abs/1901.06322
[13] W. Teng, N. Wang, H. Shi, Y. Liu, and J. Wang, “Classifier-constraineddeep adversarial domain adaptation for cross-domain semisupervisedclassification in remote sensing images,”IEEE Geosci. Remote Sens.Lett., vol. 17, no. 5, pp. 789–793, May 2020.
[14] R. Dong, D. Xu, J. Zhao, L. Jiao, and J. An, “Sig-NMS-based fasterR-CNN combining transfer learning for small target detection in VHRoptical remote sensing imagery,”IEEE Trans. Geosci. Remote Sens.,vol. 57, no. 11, pp. 8534–8545, Nov. 2019.
[15] Y. Ganinet al., “Domain-adversarial training of neural networks,”J. Mach. Learn. Res., vol. 17, no. 1, pp. 2030–2096, May 2015.
[16] M. Cordtset al., “The cityscapes dataset for semantic urban sceneunderstanding,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit.,Jun. 2016, pp. 3213–3223.
[17] T. Salimans, H. Zhang, A. Radford, and D. Metaxas, “Improving GANsusing optimal transport,” 2018,arXiv:1803.05573. [Online]. Available:http://arxiv.org/abs/1803.05573
[18] A. Odena, C. Olah, and J. Shlens, “Conditional image synthesis withauxiliary classifier GANs,” inProc. Int. Conf. Mach. Learn., 2017,pp. 2642–2651.
[19] P. Shamsolmoali, M. Zareapoor, R. Wang, D. K. Jain, and J. Yang,“G-GANISR: Gradual generative adversarial network for image superresolution,”Neurocomputing, vol. 366, pp. 140–153, Nov. 2019.
[20] M. O. Sghaier and R. Lepage, “Road extraction from very high resolu-tion remote sensing optical images based on texture analysis and beamlettransform,”IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens.,vol.9,no. 5, pp. 1946–1958, May 2016.
[21] G. Cheng, Y. Wang, S. Xu, H. Wang, S. Xiang, and C. Pan, “Automaticroad detection and centerline extraction via cascaded end-to-end con-volutional neural network,”IEEE Trans. Geosci. Remote Sens., vol. 55,no. 6, pp. 3322–3337, Jun. 2017.
[22] Y. Wei, K. Zhang, and S. Ji, “Simultaneous road surface and centerlineextraction from large-scale remote sensing images using CNN-basedsegmentation and tracing,”IEEE Trans. Geosci. Remote Sens., pp. 1–13,2020.
[23] A. Mathur, A. Isopoussu, F. Kawsar, N. B. Berthouze, and N. D. Lane,“FlexAdapt: Flexible cycle-consistent adversarial domain adaptation,”inProc. 18th IEEE Int. Conf. Mach. Learn. Appl., Dec. 2019,pp. 1989–1998.
[24] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-imagetranslation using cycle-consistent adversarial networks,” inProc. IEEEInt. Conf. Comput. Vis., Oct. 2017, pp. 2223–2232.
[25] Q. Wang, J. Gao, and X. Li, “Weakly supervised adversarial domainadaptation for semantic segmentation in urban scenes,”IEEE Trans.Image Process., vol. 28, no. 9, pp. 4376–4386, Sep. 2019.
[26] Y. Li, B. Peng, L. He, K. Fan, and L. Tong, “Road segmentationof unmanned aerial vehicle remote sensing images using adversarialnetwork with multiscale context aggregation,”IEEE J. Sel. TopicsAppl. Earth Observat. Remote Sens., vol. 12, no. 7, pp. 2279–2287,Jul. 2019.
[27] Q. Wang, Z. Qin, F. Nie, and X. Li, “Spectral embedded adaptiveneighbors clustering,”IEEE Trans. Neural Netw. Learn. Syst., vol. 30,no. 4, pp. 1265–1271, Apr. 2019.
[28] R. Bellens, S. Gautama, L. Martinez-Fonte, W. Philips, J. C.-W. Chan,and F. Canters, “Improved classification of VHR images of urban areasusing directional morphological profiles,”IEEE Trans. Geosci. RemoteSens., vol. 46, no. 10, pp. 2803–2813, Oct. 2008.
[29] J. Sivic and A. Zisserman, “Video Google: A text retrieval approach toobject matching in videos,” inProc. 9th IEEE Int. Conf. Comput. Vis.,Oct. 2003, pp. 1470–1477.
[30] T. Mao, H. Tang, and W. Huang, “Unsupervised classification ofmultispectral images embedded with a segmentation of panchromaticimages using localized clusters,”IEEE Trans. Geosci. Remote Sens.,vol. 57, no. 11, pp. 8732–8744, Nov. 2019.
[31] X. Lu, X. Zheng, and Y. Yuan, “Remote sensing scene classificationby unsupervised representation learning,”IEEE Trans. Geosci. RemoteSens., vol. 55, no. 9, pp. 5148–5157, Sep. 2017.
[32] Y. Zhang, C. Liu, M. Sun, and Y. Ou, “Pan-sharpening using an efficientbidirectional pyramid network,”IEEE Trans. Geosci. Remote Sens.,vol. 57, no. 8, pp. 5549–5563, Aug. 2019.
[33] T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie,“Feature pyramid networks for object detection,” inProc. IEEE Conf.Comput. Vis. Pattern Recognit., Jul. 2017, pp. 2117–2125.
[34] K. He, X. Zhang, S. Ren, and J. Sun, “Spatial pyramid pooling indeep convolutional networks for visual recognition,”IEEE Trans. PatternAnal. Mach. Intell., vol. 37, no. 9, pp. 1904–1916, Sep. 2015.
[35] J. Yang, J. Guo, H. Yue, Z. Liu, H. Hu, and K. Li, “CDnet: CNN-based cloud detection for remote sensing imagery,”IEEE Trans. Geosci.Remote Sens., vol. 57, no. 8, pp. 6195–6211, Aug. 2019.
[36] Y. Pang, T. Wang, R. M. Anwer, F. S. Khan, and L. Shao, “Efficientfeaturized image pyramid network for single shot detector,” inProc.IEEE Conf. Comput. Vis. Pattern Recognit., Jun. 2019, pp. 7336–7344.
[37] E. Choi, S. Biswal, B. Malin, J. Duke, W. F. Stewart, and J. Sun,“Generating multi-label discrete patient records using generativeadversarial networks,” 2017,arXiv:1703.06490. [Online]. Available:http://arxiv.org/abs/1703.06490
[38] J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018,pp. 7132–7141.
[39] P. Shamsolmoali, M. Zareapoor, R. Wang, H. Zhou, and J. Yang,“A novel deep structure U-Net for sea-land segmentation in remotesensing images,”IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens.,vol. 12, no. 9, pp. 3219–3232, Sep. 2019.
[40] M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter,“Gans trained by a two time-scale update rule converge to a localNASH equilibrium,” inProc. Adv. Neural Inf. Process. Syst., 2017,pp. 6626–6637.
[41] R. Unnikrishnan, C. Pantofaru,and M. Hebert, “Toward objectiveevaluation of image segmentation algorithms,”IEEE Trans. Pattern Anal.Mach. Intell., vol. 29, no. 6, pp. 929–944, Jun. 2007.
[42] M. Meilˇa, “Comparing clusterings: An axiomatic view,” inProc. 22ndInt. Conf. Mach. Learn. (ICML), 2005, pp. 577–584.
[43] D. Martin, C. Fowlkes, D. Tal, and J. Malik, “A database of humansegmented natural images and its application to evaluating segmentationalgorithms and measuring ecological statistics,” inProc. 8th IEEE Int.Conf. Comput. Vis. (ICCV), vol. 2, Jun. 2001, pp. 416–423.
[44] J. Freixenet, X. Mñoz, D. Raba, J. Martí, and X. Cufí, “Yet anothersurvey on image segmentation: Region and boundary information inte-gration,” inProc. Eur. Conf. Comput. Vis.Berlin, Germany: Springer,2002, pp. 408–422.
[45] A. Shrivastava, T. Pfister, O. Tuzel, J. Susskind, W. Wang, and R. Webb,“Learning from simulated and unsupervised images through adversarialtraining,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., Jun. 2017,pp. 2107–2116.
[46] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning forimage recognition,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit.,Jun. 2016, pp. 770–778.
[47] K. Simonyan and A. Zisserman, “Very deep convolutional networksfor large-scale image recognition,” 2014,arXiv:1409.1556. [Online].Available: http://arxiv.org/abs/1409.1556
[48] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,”2014,arXiv:1412.6980. [Online]. Available: http://arxiv.org/abs/1412.6980