CVPR2022自适应/语义分割:Class-Balanced Pixel-Level Self-Labeling for Domain Adaptive Semantic Segmentation
CVPR2022自适应/语义分割:Class-Balanced Pixel-Level Self-Labeling for Domain Adaptive Semantic Segmentation用于域自适应语义分割的类平衡像素级自标记
- 0.摘要
- 1.概述
- 2.相关工作
-
- 2.1.语义分割
- 2.2.为语义分割设计的领域自适应
- 2.3.基于集群的特征表示学习
- 3.方法
-
- 3.1.整体框架
- 3.2.在线像素级自标记
-
- 3.2.1.像素级自标记
- 3.2.2.权重初始化
- 3.2.3.在线集群分配
- 3.3.类别平衡的自标记
-
- 3.3.1.类平衡抽样
- 3.3.2.分布对齐
- 3.4. 损失函数
- 4.实验
-
- 4.1.实验设置
-
- 4.1.1.实现细节
- 4.1.2.数据集
- 4.2. 和先进方法的比较
-
- 4.2.1.GTA5→Cityscapes
- 4.2.2.SYNTHIA→Cityscapes
- 4.2.3.定性结果
- 4.3.讨论
-
- 4.3.1.消融实验
- 4.3.2.不平等的分区约束
- 4.3.3.自我训练(ST) vs.自我标签(SL)
- 4.3.4.分布对齐的影响
- 4.3.5.参数敏感性分析
- 4.3.6.限制
- 5.结论
- 6.补充材料
- 参考文献
论文下载
开源代码
0.摘要
域自适应语义分割的目的是在监督源域数据的情况下学习模型,并在未标记的目标域上产生令人满意的密集预测。对于这一挑战性任务,一个流行的解决方案是自我训练,它选择目标样本上的高分预测作为训练的伪标签。然而,生成的伪标签往往包含大量的噪声,因为模型偏向于源域和大多数类别。为解决上述问题,我们建议直接探索目标域数据的内在像素分布,而不是过度依赖源域。具体来说,我们同时对像素进行聚类,并使用获得的聚类分配对标签进行整流。这个过程以在线的方式完成,因此伪标签可以与分割模型共同进化,而不需要额外的训练。为了克服长尾类的类不平衡问题,我们采用一种分布对齐技术,使簇分配的边缘类分布接近于伪标签的边缘类分布。所提出的方法,即类平衡像素级自标记(CPSL),在现有技术水平的基础上,大大提高了目标域的分割性能,特别是在长尾类上。
1.概述
语义分割是计算机视觉的一项基本任务,其目的是对图像进行密集的语义级预测[8,27,28,43,53]。它是许多应用程序的关键一步,包括自动驾驶、人机交互和增强现实,举几个例子。在过去的几年中,深度卷积神经网络(CNNs)的快速发展大大提高了语义分割的准确性和效率。然而,在一个领域中训练的深度模型在应用到未见域时,性能往往会大幅下降。例如,在自动驾驶中,当天气条件不断变化时,分割模型面临着巨大的挑战。从尽可能多的场景中收集数据是提高分割模型泛化能力的自然方法。然而,为大量的图像[11]注释像素标签是非常昂贵的。需要更有效和实用的方法来解决语义分割的领域转移问题
无监督域适应(Unsupervised Domain Adaptation, UDA)提供了一种将从一个标记源域学到的知识转移到另一个未标记目标域的重要方法。例如,我们可以使用GTA5[36]和SYNTHIA[37]等游戏引擎来收集许多合成数据,这些合成数据的密集注释很容易获得。接下来的问题是如何将经过标记的合成域训练出来的模型适应于未标记的真实图像域。UDA之前的大部分工作都是通过对抗式训练或辅助风格传输网络,在图像级别[17,25,33]、特征级别[7,17,18,24]或输出级别[29,32,39]对齐数据分布,从而弥合域差距。然而,这些技术增加了模型的复杂性,使训练过程不稳定,影响了模型的再现性和鲁棒性。
另一种重要的方法是自我训练[52,56,57],它可以通过选择目标域上的高分预测生成伪标签,并为下一轮训练提供监督。虽然这些方法已经产生了良好的性能,但仍有一些主要的局限性。一方面,分割模型倾向于源域,从而在目标域中产生的伪标签容易出错;另一方面,高度自信的预测可能只能为模型训练提供非常有限的监督信息。为了解决这些问题,有人提出了一些方法[50,51]来生成更准确和更有信息的伪标签。例如,与使用源域训练的分类器来生成伪标签不同,zhang等人[51]伪标签分配基于它们到类别原型的距离。然而,这些原型是在源域构建的,通常与目标域有很大的偏差。ProDA[50]利用与原型之间的特征距离来进行在线校正,但构造长尾类的原型具有挑战性,这常常导致性能不理想
与以往使用基于分类器的噪声伪标签进行监督的自训练方法不同,本文提出了一种基于目标域聚类的在线像素级自标记方法,并利用产生的软聚类分配对伪标签进行校正。我们的想法来源于这样一个事实,即基于像素的聚类分配可以揭示目标域内像素的内在分布,并为模型训练提供有用的监督。与传统的标签生成方法往往偏向源域相比,目标域中的聚类分配更可靠,因为它探索了数据的内在分布。考虑到segmentationdataset的类是高度不平衡的(如图2所示),我们采用分布对齐技术,使聚类分配的类分布接近于伪标签的类分布,这更有利于类不平衡的密集预测任务。提出的类平衡像素级自标记(CPSL)模块以即插即用的方式工作,它可以无缝地集成到现有的UDA自训练框架中。本工作的主要贡献如下:
- 开发了一种像素级自标记模块,用于领域自适应语义分割。我们以在线的方式聚类像素,同时根据产生的聚类分配纠正伪标签。
- 引入了一种分布对齐技术,将集群分配的类分布与伪标签的类分布对齐,旨在提高长尾类别的性能。采用类平衡采样策略,避免了伪标签生成过程中多数类别的支配性。
- 大量的实验证明,所提出的dcpsl模块在目标域上的分割性能比先进水平有很大的提高。它在“摩托车”、“火车”、“灯”等长尾类上表现得尤为突出
2.相关工作
2.1.语义分割
语义分割的目的是将图像分割成具有不同语义类别的区域。虽然完全卷积网络[28]极大地提高了语义分割的性能,但它们在探索视觉上下文方面的接受域相对较小。后来的许多研究集中在如何扩大FCNs的接受域来建模图像的远程上下文依赖性,如扩张卷积[8]、多层特征融合[27]、空间金字塔池[53]和非局部块的变体[15,20,22]。然而,由于这些模型泛化能力较弱,直接应用于不可见区域分割性能较差。因此,为了提高模型在新领域上的泛化能力,提出了许多领域自适应技术。
2.2.为语义分割设计的领域自适应
近年来,人们提出了许多弥补领域差距和提高自适应性能的工作。最具代表性的是基于对抗训练的方法[19,23,34,39,40],其目的是在中间特征或网络预测上对齐不同的域。基于风格转移的方法[6,9,10,44,48]在图像层面上最小化域间隙。例如,Changetal。[6]提出将图像分解为域不变结构和域特定纹理进行图像翻译。这些模型的训练过程相当复杂,因为需要同时训练多个网络,如鉴别器或样式转换网络。
UDA的另一个重要技术是自我训练[24,26,32,51,55,57],它迭代地在目标数据上生成espseudo标签,用于模型更新。Zouetal。[55]提出了一种类平衡的自训练方法,用于语义分割的领域适应。为了减少伪标签中的噪声,Zouet al.[57]进一步提出了一种置信度正则化自训练方法,该方法将伪标签作为可训练潜变量。Lianetal。[26]为探索目标领域的各种属性构建了一个金字塔课程。[51]通过选择源域的原型作为指导变量来实现类别感知的特性对齐。ProDA[50]更进一步,利用每个像素到原型的特征距离来修正由源模型预先计算的伪标签。然而,这些方法要么忽略了目标域图像的像素方面的内在结构,要么忽略了目标域图像的固有类分布,往往偏向于源域或多数类
2.3.基于集群的特征表示学习
我们的工作也与基于聚类的方法有关[2-4,21,45 - 47,54,58]。Caronet al.[4]迭代地对潜在表示执行K均值,并使用生成的集群分配来更新网络参数。最近,Asanoet al.[3]将聚类分配问题转化为一个最优运输问题,该问题可以通过Sinkhorn-Knopp算法的快速变种有效求解。SwAV[5]在执行聚类的同时强制同一图像的不同增强的集群分配之间的一致性。在本文中,我们将自标记从图像级的分类扩展到像素级的语义分割。此外,不同于Asanoet al.[3]和Caronet al.[4],我们以在线方式计算群集分配,使我们的方法可扩展到密集的像素预测任务
3.方法
3.1.整体框架

图1。类平衡像素级自标记(CPSL)框架。该模型包含一个主分割网络 f S E G f_{SEG} fSEG和动量更新版本 f S E G ’ f^’_{SEG} fSEG’。 f S E G ’ f^’_{SEG} fSEG’后面跟着一个自标记头 f S L f_{SL} fSL,在其动量版本的 f S L ’ f^’_{SL} fSL’上,它投射出嵌入到类概率向量中的像素特征。像素级自标记模块产生软聚类赋值 P S L P_{SL} PSL,逐步校正软伪标签 P S T P_{ST} PST。然后计算分割损失 L S E G t L_{SEG}^t LSEGt在预测的图P和修正后的伪标签 Y ^ t \hat{Y}^t Y^t之间。为了训练自标记头,我们从每张图像中随机采样像素,并使用包含前一批像素特征的记忆bankM来增加当前批次的像素特征。然后,我们通过强制类平衡来计算增强数据的最优传输赋值,并使用当前批次 Q c u r Q_{cur} Qcur的赋值来计算自标记损失 L S L L_{SL} LSL
在语义分割的无监督域自适应设置下,我们得到源域 D S = ( X n s , Y n s ) n = 1 N S D_S={(X^s_n,Y^s_n)}^{N_S}_{n=1} DS=(Xns,Yns)n=1NS中的一组标签数据,其中 X n s X^s_n Xns为源图像, Y n s Y^s_n Yns为原图像的标签 N S N_S NS为源图像数量,以及一组数量为 N T N_T NT的在目标域 D T = ( X n t , Y n t ) n = 1 N T D_T={(X^t_n,Y^t_n)}^{N_T}_{n=1} DT=(Xnt,Ynt)n=1NT的不具有标签的数据 X n t X^t_n Xnt。两个域共享相同的类别。我们的目标是通过使用 D S D_S DS中标记的源数据和 D T D_T DT中未标记的目标数据来学习一个模型,它可以在目标域中不可见的测试数据上很好地执行。
我们建议的CPSL的整体架构如图1所示。我们提出了一个像素级自标记模块(在绿色框中突出显示),通过聚类来探索目标域数据的内部像素分布,并减少伪标签中的噪声。在训练之前,我们首先通过在源域数据上预训练的预热模型生成每个目标域图像的软伪伪标签图 P S T ∈ R H × W × C P_{ST}∈R^{H×W×C} PST∈RH×W×C。由于大的偏移,得到的 P S T P_{ST} PST通常容易出错。因此,在训练过程中,我们用软聚类赋值对 P S T P_{ST} PST增量进行矫正,记为 P S L ∈ R H × W × C P_{SL}∈R^{H×W×C} PSL∈RH×W×C。具体而言, P S T P_{ST} PST的整改工作如下:
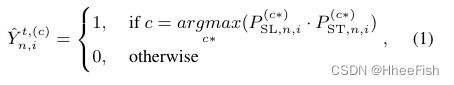
其中 Y ^ n , i t , ( c ) \hat{Y}^{t,(c)}_{n,i} Y^n,it,(c)表示目标图像 X n t X^t_n Xnt的第i个像素处的经校正的伪像素的第c个类别, P S L , n , i ( c ∗ ) P^{(c∗)}_{SL,n,i} PSL,n,i(c∗)表示 X n t X^t_n Xnt的第i个像素属于c类的概率。等式1具有类似于[35,38,50]的公式,其中 P S L P_{SL} PSL可以被视为修改软最大概率图 P S T P_{ST} PST的权重图。聚类赋值 P S L P_{SL} PSL利用了目标域的固有数据分布,因此它与严重依赖于源域的基于分类器的伪标签 P S T P_{ST} PST高度互补。
我们将目标域上的分割损失(由 L S E G t L^t_{SEG} LSEGt表示)定义为分割概率图 P n ∈ R H × W × C P_n∈R^{H×W×C} Pn∈RH×W×C和目标图像 X n t X^t_n Xnt的校正伪标签 X ^ n t \hat{X}^t_n X^nt之间的像素级交叉熵损失

此外,由 L S E G t L^t_{SEG} LSEGt表示的源域损失可以定义为标记图像上的标准像素交叉熵

然后获得总分割损失 L S E G L_{SEG} LSEG,作为它们的总和: L S E G = L S E G s + L S E G t L_{SEG}=L^s_{SEG}+L^t_{SEG} LSEG=LSEGs+LSEGt。
在下面的小节中,我们将详细解释CPSL模块的设计
3.2.在线像素级自标记
3.2.1.像素级自标记
传统的基于自训练的方法通常使用在源域上预先训练的模型来产生伪标签,这些伪标签通常包含很多噪声[51,55,57]。为了清除伪标签,我们建议通过对目标领域进行聚类来执行像素级自标记,并使用获得的聚类分配来校正伪标签。其基本动机是,像素聚类可以揭示目标域数据的内在结构,它是对源域数据上训练的分类器的补充。因此,聚类分配可以为训练域自适应分割模型提供额外的监督
具体来说,我们首先从输入图像中提取特征以获得 Z ∈ R H × W × D Z∈R^{H×W×D} Z∈RH×W×D并用 z i = z i ∣ ∣ z i ∣ ∣ 2 z_i=\frac{z_i}{||z_i||_2} zi=∣∣zi∣∣2zi对其进行归一化,其中 z i z_i zi是Z的第i个特征向量,长度为D。然后,我们从每个图像中随机采样一组像素 Z ^ = [ z 1 , ⋅ ⋅ ⋅ , z M ] \hat{Z}=[z_1,···,z_M] Z^=[z1,⋅⋅⋅,zM],并将其通过自标记头 f S L f_{SL} fSL。最后,我们通过进行softmax运算,得到它们的类概率向量 p ^ = [ p 1 , ⋅ ⋅ ⋅ , p M ] \hat{p}=[p_1,···,p_M] p^=[p1,⋅⋅⋅,pM]:

其中 f S L ( c ) ( z m ) f^{(c)}_{SL}(z_m) fSL(c)(zm)是自标记头的 z m z_m zm输出的第c个元素。 p m ( c ) p^{(c)}_m pm(c)表示像素属于第c类的概率。τ是温度参数。考虑到目标数据没有地面真值标签,我们通过自标记机制[3]训练自标记头 f S L f_{SL} fSL,该机制具有以下目标函数:

上式是最优运输问题[13]的一个实例,其中 Q = 1 M [ q 1 , ⋅ ⋅ ⋅ , q M ] Q=\frac{1}{M}[q_1,···,q_M] Q=M1[q1,⋅⋅⋅,qM]是一个运输分配,它被限制为满足约束条件Q的概率矩阵。 1 C 1_C 1C和 1 Q 1_Q 1Q分别表示维度为C和M的向量。分别将Q的边缘投影投影到它的行和列上。
通过将聚类分配问题表述为一个运时问题,可以用迭代Sinkhorn-Knopp 算法[13]有效地求解方程5对变量q的优化问题。最优解由:

其中 α ∈ R C α∈R^C α∈RC和 β ∈ R M β∈R^M β∈RM是两个纠正向量,即使对于密集的预测任务,也可以在线性时间内高效计算。ε是一个温度参数。
然后通过固定标签分配Q,通过相应的 P ^ \hat{P} P^最小化 L S L L_{SL} LSL来更新自标签头 f S L f_{SL} fSL,这与交叉熵损失的训练相同。
3.2.2.权重初始化
我们使用软聚类赋值 P S L P_{SL} PSL来修正基于分类器的伪标签 P S T P_{ST} PST。然而,聚类类别通常与分类器的类别不匹配,导致性能下降。为了克服这个问题,我们用类别原型初始化自标记头 f S L f_{SL} fSL的权重。具体来说,我们通过以下方法计算每个类别的原型 [ z ‾ 1 , ⋅ ⋅ ⋅ , ⋅ z ‾ C ] [\overline{z}_1,···,·\overline{z}_C] [z1,⋅⋅⋅,⋅zC]:
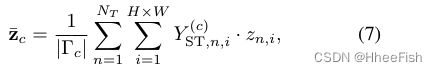
其中 ∣ Γ c ∣ |\Gamma _c| ∣Γc∣表示所有图像中属于第c类的像素的数量。 Y S T Y_{ST} YST是 P S T P_{ST} PST的硬版本。自标记过程可以看作是为不同的原型分配像素。通过这种方式,聚类类别能够匹配分类类别
3.2.3.在线集群分配
不同于Asanoetal。[3],其中分配Q是在全数据集上计算的,我们在训练期间对数据批进行在线聚类。考虑到微型批中的样本数量往往太少,无法覆盖所有类别,且不同批次之间的类分布差异很大,我们使用动态更新的内存空隙M来增强特征 Z ^ \hat{Z} Z^,以减少采样的随机性。具体地说,在整个训练过程中,我们在M中维护了一个由65,536个前一批像素特征组成的队列。在每次迭代中,我们在增强数据 Z a u g Z_{aug} Zaug上计算最优传输赋值,用 Q a u g Q_{aug} Qaug表示,但只使用当前批的赋值,用 Q c u r Q_{cur} Qcur表示,来计算自标记损失 L S L L_{SL} LSL。通过这种方式,我们可以更新自标记头,并使用它在线生成更准确的集群分配 P S L P_{SL} PSL。因此,伪标签将通过产生的聚类分配逐步改进,噪声将逐步减少,而无需额外的轮次训练
3.3.类别平衡的自标记
如图2所示,目前的语义分割数据集存在严重的类不平衡。一些长尾类的像素非常有限(例如,“红绿灯”,“标志”),一些类只出现在少数图像中(例如,“摩托车”,“火车”)。这样的问题将使训练一个健壮的分割模型变得困难,特别是对于那些长尾类。在这项工作中,我们提出了两种技术来解决这个问题。类平衡抽样和分布对齐
3.3.1.类平衡抽样
我们从每张图像中随机抽取像素,使内存库中数据的类分布接近于整个数据集的类分布。为了保证长尾类别的像素可以被平等地选取,我们以相同的比例从不同类别中选取样本,即, M H × W \frac{M}{H×W} H×WM,其中为每张图像中要采样的像素数。对于每个输入 X n t X^t_n Xnt,我们首先计算它的类分布 δ n \delta_n δn

其中 δ n ( c ) \delta^{(c)}_n δn(c)为图像 X n t X^t_n Xnt中第c类像素的比例。然后每个类别的样本数量由下式算出:

如果图像 X n t X^t_n Xnt不包含某些类别的像素,我们将随机抽样其他类别的其余像素,以生成M样本
3.3.2.分布对齐
如[3,4]中所讨论的,在Eq. 5同时优化Q和 P ^ \hat{P} P^可能会导致退化的结果,即所有数据点都被琐碎地分配到一个聚类中。为了避免这种情况,Asanoet al.[3]约束Q应该诱导数据的均分。然而,这种约束是不合理的,如果由 δ g t \delta_{gt} δgt标记的数据的地面真值类分布不均匀,则会降低性能。例如,在Cityscape数据集[11]中,最大类别(“道路”)的像素数大约是最小类别(“摩托车”)的300倍。
为了克服这一问题,我们提出了一种新的技术,即分布对齐,将聚类分配的分布对齐到地面真值类分布 δ g t \delta_{gt} δgt,旨在将像素划分为不等大小的子集。然而, δ g t \delta_{gt} δgt是未知的,因为无法获得目标域数据的真实标签。因此,我们提出用伪标签类分布的移动平均值 δ p s e u d o \delta_{pseudo} δpseudo来逼近 δ g t \delta_{gt} δgt。具体来说,我们首先根据下面固定的伪标签 Y S T t Y_{ST}^t YSTt初始化 δ p s e u d o \delta_{pseudo} δpseudo

在训练过程中,我们通过公式8计算每个图像的类分布 δ n \delta_n δn。然后每次训练迭代后的类分布 δ p s e u d o \delta_{pseudo} δpseudo用动量α∈[0,1]更新:

最后,我们强制聚类分配的类分布(由公式5表示)接近 δ p s e u d o \delta_{pseudo} δpseudo

我们的实证结果(参见图6)表明,所提出的分布对齐技术有效地避免了训练过程中多数类的主导地位。有关更多讨论,请参阅第4.3节
3.4. 损失函数
如图1所示,我们采用动量编码器来稳定自标记过程。为了进一步提高目标域上的模型泛化能力,并减轻从源域继承的偏差,下面[1,50],我们对分割网络进行一致性正则化。具体来说,我们从相同的输入X生成一个弱增强 X w X_w Xw和一个强增强 X s X_s Xs,并将 X w X_w Xw输入动量分割网络 f S E G ’ f^’_{SEG} fSEG’生成一个概率图 P w P_w Pw,它用于监督来自 f S E G f_{SEG} fSEG的强增强 X s X_s Xs的输出。然后我们强制 P w P_w Pw和 P s P_s Ps保持一致

式中, l K L l_{KL} lKL为kl发散度。 P s , n , i P_{s,n,i} Ps,n,i P w , n , i P_{w,n,i} Pw,n,i分别为 X n X_n Xn分割概率的第i个像素。
总损失函数定义为
![]()
λ1和λ2权衡参数。两者是相辅相成的。前者使用像素级聚类分配 P S L P_{SL} PSL对伪标签 P S T P_{ST} PST进行校正,有效地消除了对源域的偏差;后者通过对输入进行数据增强,对输出进行一致性正则化,提高了模型的泛化能力。

4.实验
4.1.实验设置
4.1.1.实现细节
我们使用DeepLabv2[8]实现分割模型,使用ResNet-101[16]作为骨干,并在ImageNet上预训练。采用[39]等对抗训练对分割模型进行热身。输入图像随机裁剪到896×512,批量大小设置为4。我们使用了一系列的数据增强,如RandAugment [12],Cutout [14], CutMix[49],并添加光度噪声,包括颜色抖动,随机模糊等。SGDM被用作优化器。分割模型和自标记头的初始学习率设为10−4和5×10−4,以幂0.9为指数衰减。权值衰减和动量分别设置为2×10−4和0.9。权衡参数λ1,λ2和温度参数τ,ε分别被经验设置为0.1,5,0.08和0.05。内存库的长度设置为65,536,我们对每张图像采样512像素进行聚类(M= 512),即内存库中有128张图像。对于动量网络,动量设置为0.999。我们的模型在PyTorch上使用4个特斯拉V100 gpu进行训练
4.1.2.数据集
根据[31,51,52],我们在实验中采用两个合成数据集(GTA5 [36], SYNTHIA[37])和一个真实数据集(Cityscapes[11])。GTA5数据包含24,966张分辨率为1914×1052的图像。游戏引擎生成相应的密集注释。SYNTHIA数据集包含9400张图片of1280×760像素,它与cityscape有16个公共类别,其中包含2975张训练图片和500张分辨率2048×1024的验证图片
4.2. 和先进方法的比较
我们将所提出的方法命名为类平衡像素级自标记(CPSL)。在[50]之后,在训练收敛之后,我们还会再进行两轮知识蒸馏,将知识转移到一个自我监督预先训练的学生模型中,得到的模型称为“CPSL+蒸馏”。我们将模型与具有代表性和最先进的方法进行比较,这些方法可分为两大类:基于对抗训练的方法,包括AdaptSeg [39], CyCADA [17],FADA [42], ADVENT[41],以及基于自我训练的方法,包括CBST [55], IAST [31], CAGUDA [51],ProDA [50], SAC[1]。在之前的工作之后,验证集的结果被报告为基于分类的交集过联合(IoU)和平均IoU (mIoU)。
4.2.1.GTA5→Cityscapes

表1。GTA5→城市景观适应任务实验结果。最高分用粗体突出显示
GTA5→Cityscapestask的结果如表1所示。在19个类别中,我们的CPSL在7个类别中获得了最好的mIoU得分,它获得了最高的mIoU得分,超过了第二好的方法ProDA[50]并拉开2.0的差距。这可以归因于对目标do-main的内在数据分布的探索,这为训练提供了额外的监督。通过应用知识蒸馏,进一步获得了5.1的性能增益,达到了60.8 mIoU,这是目前最新的水平。值得一提的是,我们的方法在“杆”、“光”、“火车”和“马达”等长尾类别上表现得特别好。例如,proda在小班“火车”上失败了,因为在构造长尾类别的原型时遇到了困难。通过应用分布对齐,CPSL缓解了类不平衡问题,在“列车”上获得了24.9个IoU,而不牺牲其他类别上的性能
4.2.2.SYNTHIA→Cityscapes

表2。SYNTHIA→Cityscapes适应任务实验结果。最高分用粗体突出显示
由于大的领域差距,这个适应任务比前一个更具有挑战性。miou超过13个类(mIoU13)和16个类(mIoU16)的情况见表2。在这项任务中,我们的模型仍然取得了显著的改进。CPSL在16类和13类中分别达到了54.4和61.7的mIoU,分别比排名第二的SAC[1]高出1.8和2.4。这是因为CPSL降低了标签噪声,校准了源域的偏置。蒸馏后的mIoU分别为57.9和65.3。在所有的16个类别中,我们的方法超过了其中的6个,特别是最难的类别,如“轻”,“摩托车”,“自行车”,等等。
4.2.3.定性结果
图3。我们的方法和ProDA[50]在GTA5→城市景观任务上的定性结果
我们的方法和ProDA在GTA5→Cityscapes分割的定性如图3所示。可以看出,我们的方法大大提高了长尾类的性能。“极”,“光”,“总线”,这要感谢类平衡抽样和分布对齐技术。ProDA[50]在这些类别上表现不好,因为它没有显式地在训练中强制类平衡
4.3.讨论
4.3.1.消融实验
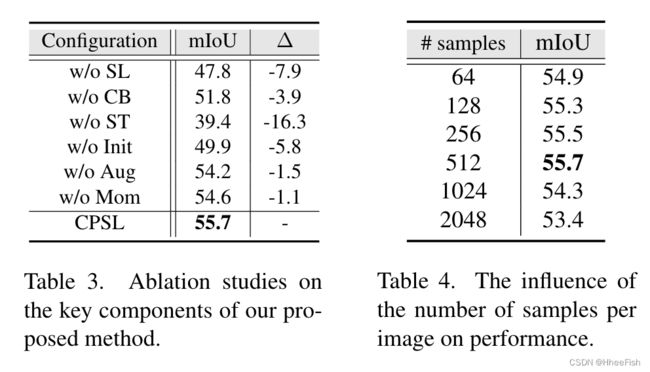
我们对GTA5→Cityscapes任务进行了消融研究,以调查每个组件在CPSL中的作用。为了便于表达,我们将“自我标记”、“自我训练”、“类平衡”、“权重初始化”、“数据增强”和“动量编码器”简称为“SL”、“ST”、“CB”、“Init”、“Aug”、“Mom”. tab3显示了通过切换每个组件的相应结果。我们有以下几点看法。
首先,去除SL组件导致mIoU下降7.9in,禁用CB组件导致mIoU下降3.9 in。这表明它们通过探索目标域图像的内在数据结构,在提高分割性能方面发挥着关键作用。第二,没有ST产生的伪标签的训练导致mIoU显著下降16.3。这并不奇怪,因为同时更新网络参数和生成伪标签将导致退化解[50,51]。第三,随机初始化自标记头(w/o Init)导致mIoU下降5.8,这是由于聚类和分类产生的类别不匹配造成的。第四,Aug和Mom组件分别为mIoU带来1.7和1.1的改善
4.3.2.不平等的分区约束

图4。mIoU和平均像素精度(MPA)评分在等/不等分区约束的验证集上进行评估。
为了进一步分析不平等划分对类不平衡数据集的影响,我们绘制了不同划分约束下mIoU和MPA分数的曲线,如图4所示,在mIoU方面可以观察到巨大的差距。然而,在MPA方面,相等分区略优于不等分区。这并不奇怪,因为在等分的约束下,许多属于大类别的像素被分配到小类别中,在很大程度上提高了小类别的像素精度,而不影响大类别。从而提高了MPA评分。更多细节可在补充文件中找到
4.3.3.自我训练(ST) vs.自我标签(SL)

图5。自我训练产生的标签作业与自我标签作业的互补性。
我们探索了由ST和SL产生的标签分配的互补性,并将结果可视化于图5。我们可以得出一个结论,在我们的CPSL中,ST和SL的整合比它们任何一个都能带来更好的结果。具体来说,ST在“天空”、“建筑”等容易转移的大类别上表现更好,而SL在“光”、“杆”等小类别上则有优势。因此,在一个视图中被错误分类的像素将在另一个视图中被纠正
4.3.4.分布对齐的影响
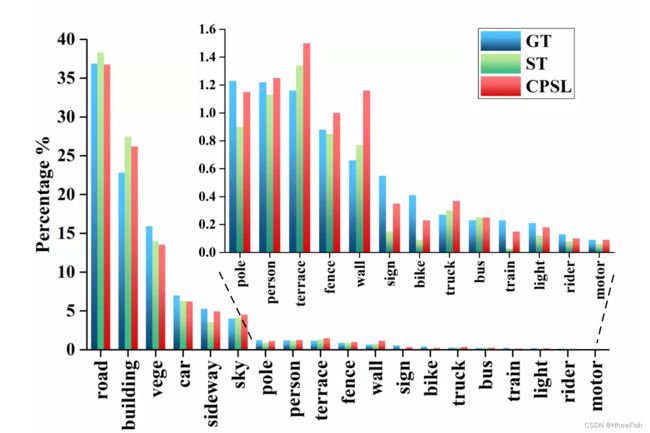
图6。Cityscapesdataset上类分布的比较。’ GT ‘表示基本真理类分布。’ ST ‘和’ cpsl '表示由自训练和类平衡像素级自标记产生的伪标签的类分布
我们比较了CPSL和传统自我训练(ST)产生的标签的类别分布。如图6所示,ST的结果与地真值(GT)失配严重。它的预测偏向于大多数类别,例如:“道路”和“建筑”,忽略了“火车”、“标志”和“自行车”等小类别。CPSL校正偏差,产生更接近于GT的类分布,这表明CPSL消除了目标域固有的类分布,避免了多数类逐渐占主导地位。
4.3.5.参数敏感性分析
在表4中,我们对GTA5→Cityscapes任务下的分割性能进行了评估,每个图像有不同的样本数量。我们的方法在很大范围内对该参数具有鲁棒性。在补充材料中可以发现更多的分析
4.3.6.限制
虽然CPSL通过自标记分配减轻了对源域的偏差,但它仍然依赖于基于自训练的伪标签,这可能会导致确认偏差。我们考虑在未来的工作中开发完全基于聚类的分配方法。
5.结论
我们提出了一个即插即用的模块,即类平衡像素级自标记(CPSL),它可以无缝地集成到自训练管道中,以提高域自适应语义分割性能。具体来说,我们在线进行像素级聚类,并使用产生的聚类分配来纠正seudo标签。一方面,通过探索目标域图像像素级的内在结构,降低标签噪声,校正对源域的偏差;另一方面,CPSL捕捉了目标领域固有的类别分布,有效地避免了多数类别逐渐占主导地位的现象。定性和定量分析都表明CPSL的性能大大优于现有的先进水平。特别是,它在不牺牲其他类别的性能的情况下,在长尾类上取得了很大的性能提升。
6.补充材料
为了更好地说明我们的方法的性能,我们实现了一个没有类平衡训练的CPSL变体,即。,纯像素级自标记(PSL)。PSL和cpsla的定性结果如图8所示。总的来说,CPSL能够在不同的场景中产生更精确的片段。具体来说,我们的方法在长尾类别上表现得更好。" bus ", " bicycle ", " person ", " light "。与PSL相比,CPSL的片段边界更清晰,更接近物体边界,如“自行车”和“人”。此外,值得注意的是,PSL在很大范围内错误地将“道路”类划分为“人行道”类,这归因于应用于集群分配的均分约束。如果真实的类分布不均匀,这个约束是没有用的,会使性能提升。但是,这个问题可以通过将集群分配的类分布与伪标签的类分布对齐来解决。







参考文献
[1] Nikita Araslanov and Stefan Roth. Self-supervisedaugmentation consistency for adapting semantic seg-mentation. InProceedings of the IEEE/CVF Con-ference on Computer Vision and Pattern Recognition,pages 15384–15394, 2021. 5, 6, 7
[2] Yuki Asano, Mandela Patrick, Christian Rupprecht,and Andrea Vedaldi. Labelling unlabelled videos fromscratch with multi-modal self-supervision.Advancesin Neural Information Processing Systems, 33:4660–4671, 2020. 2
[3] Y M Asano, C Rupprecht, and A Vedaldi.Self-labelling via simultaneous clustering and representa-tion learning. InICLR 2020 : Eighth InternationalConference on Learning Representations, 2020. 2, 4,5
[4] Mathilde Caron, Piotr Bojanowski, Armand Joulin,and Matthijs Douze. Deep clustering for unsuper-vised learning of visual features. InProceedings of theEuropean Conference on Computer Vision (ECCV),pages 132–149, 2018. 2, 5
[5] Mathilde Caron, Ishan Misra, Julien Mairal, PriyaGoyal, Piotr Bojanowski, and Armand Joulin. Un-supervised learning of visual features by contrast-ing cluster assignments. InThirty-fourth Conferenceon Neural Information Processing Systems (NeurIPS),volume 33, pages 9912–9924, 2020. 2
[6] Wei-Lun Chang, Hui-Po Wang, Wen-Hsiao Peng, andWei-Chen Chiu. All about structure: Adapting struc-tural information across domains for boosting seman-tic segmentation. In2019 IEEE/CVF Conference onComputer Vision and Pattern Recognition (CVPR),pages 1900–1909, 2019. 2
[7] Chaoqi Chen, Weiping Xie, Wenbing Huang, YuRong, Xinghao Ding, Yue Huang, Tingyang Xu, andJunzhou Huang. Progressive feature alignment for un-supervised domain adaptation. In2019 IEEE/CVFConference on Computer Vision and Pattern Recog-nition (CVPR), pages 627–636, 2019. 1
[8] Liang-Chieh Chen, George Papandreou, IasonasKokkinos, Kevin Murphy, and Alan L Yuille. Deeplab:Semantic image segmentation with deep convolutionalnets, atrous convolution, and fully connected crfs.IEEE transactions on pattern analysis and machineintelligence, 40(4):834–848, 2017. 1, 2, 6
[9] Yun-Chun Chen, Yen-Yu Lin, Ming-Hsuan Yang, andJia-Bin Huang. Crdoco: Pixel-level domain transferwith cross-domain consistency. In2019 IEEE/CVFConference on Computer Vision and Pattern Recogni-tion (CVPR), pages 1791–1800, 2019. 2
[10] Jaehoon Choi, Taekyung Kim, and Changick Kim.Self-ensembling with gan-based data augmentationfor domain adaptation in semantic segmentation. In2019 IEEE/CVF International Conference on Com-puter Vision (ICCV), pages 6830–6840, 2019. 2
[11] Marius Cordts, Mohamed Omran, Sebastian Ramos,Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson,Uwe Franke, Stefan Roth, and Bernt Schiele. Thecityscapes dataset for semantic urban scene under-standing. InProceedings of the IEEE conference oncomputer vision and pattern recognition, pages 3213–3223, 2016. 1, 5, 6
[12] Ekin D Cubuk, Barret Zoph, Jonathon Shlens, andQuoc V Le. Randaugment: Practical automated dataaugmentation with a reduced search space. InPro-ceedings of the IEEE/CVF Conference on ComputerVision and Pattern Recognition Workshops, pages702–703, 2020. 6
[13] Marco Cuturi. Sinkhorn distances: Lightspeed com-putation of optimal transport. InAdvances in NeuralInformation Processing Systems 26, volume 26, pages2292–2300, 2013. 4
[14] Terrance DeVries and Graham W Taylor. Improvedregularization of convolutional neural networks withcutout.arXiv preprint arXiv:1708.04552, 2017. 6
[15] Jun Fu, Jing Liu, Haijie Tian, Yong Li, Yongjun Bao,Zhiwei Fang, and Hanqing Lu. Dual attention net-work for scene segmentation. InProceedings of theIEEE/CVF Conference on Computer Vision and Pat-tern Recognition, pages 3146–3154, 2019. 2
[16] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and JianSun. Deep residual learning for image recognition.InProceedings of the IEEE conference on computervision and pattern recognition, pages 770–778, 2016.6
[17] Judy Hoffman, Eric Tzeng, Taesung Park, Jun-YanZhu, Phillip Isola, Kate Saenko, Alexei A. Efros, andTrevor Darrell. Cycada: Cycle-consistent adversar-ial domain adaptation. InInternational Conference onMachine Learning, pages 1989–1998, 2017. 1, 6
[18] Judy Hoffman, Dequan Wang, Fisher Yu, and TrevorDarrell.Fcns in the wild: Pixel-level adversar-ial and constraint-based adaptation.arXiv preprintarXiv:1612.02649, 2016. 1
[19] Weixiang Hong, Zhenzhen Wang, Ming Yang, andJunsong Yuan.Conditional generative adversarialnetwork for structured domain adaptation. In2018IEEE/CVF Conference on Computer Vision and Pat-tern Recognition, pages 1335–1344, 2018
[20] Jie Hu, Li Shen, and Gang Sun.Squeeze-and-excitation networks. InProceedings of the IEEE conference on computer vision and pattern recognition,pages 7132–7141, 2018. 2
[21] Jiabo Huang, Qi Dong, Shaogang Gong, and XiatianZhu. Unsupervised deep learning by neighbourhooddiscovery. InInternational Conference on MachineLearning, pages 2849–2858, 2019. 2
[22] Zilong Huang, Xinggang Wang, Lichao Huang,Chang Huang, Yunchao Wei, and Wenyu Liu. Cc-net: Criss-cross attention for semantic segmentation.InProceedings of the IEEE/CVF International Con-ference on Computer Vision, pages 603–612, 2019. 2
[23] Myeongjin Kim and Hyeran Byun. Learning textureinvariant representation for domain adaptation of se-mantic segmentation. In2020 IEEE/CVF Conferenceon Computer Vision and Pattern Recognition (CVPR),pages 12975–12984, 2020. 2
[24] Ruihuang Li, Xu Jia, Jianzhong He, Shuaijun Chen,and Qinghua Hu. T-svdnet: Exploring high-order pro-totypical correlations for multi-source domain adapta-tion. InProceedings of the IEEE/CVF InternationalConference on Computer Vision, pages 9991–10000,2021. 1, 2
[25] Yunsheng Li, Lu Yuan, and Nuno Vasconcelos. Bidi-rectional learning for domain adaptation of seman-tic segmentation. In2019 IEEE/CVF Conference onComputer Vision and Pattern Recognition (CVPR),pages 6936–6945, 2019. 1
[26] Qing Lian, Lixin Duan, Fengmao Lv, and BoqingGong. Constructing self-motivated pyramid curricu-lums for cross-domain semantic segmentation: A non-adversarial approach.In2019 IEEE/CVF Interna-tional Conference on Computer Vision (ICCV), pages6757–6766, 2019. 2, 6
[27] Guosheng Lin, Anton Milan, Chunhua Shen, and IanReid. Refinenet: Multi-path refinement networks forhigh-resolution semantic segmentation. InProceed-ings of the IEEE conference on computer vision andpattern recognition, pages 1925–1934, 2017. 1, 2
[28] Jonathan Long, Evan Shelhamer, and Trevor Darrell.Fully convolutional networks for semantic segmen-tation.InProceedings of the IEEE conference oncomputer vision and pattern recognition, pages 3431–3440, 2015. 1, 2
[29] Yawei Luo, Liang Zheng, Tao Guan, Junqing Yu,and Yi Yang. Taking a closer look at domain shift:Category-level adversaries for semantics consistentdomain adaptation. In2019 IEEE/CVF Conferenceon Computer Vision and Pattern Recognition (CVPR),pages 2507–2516, 2019. 1
[30] Fengmao Lv, Tao Liang, Xiang Chen, and Gu-osheng Lin. Cross-domain semantic segmentation viadomain-invariant interactive relation transfer. In2020IEEE/CVF Conference on Computer Vision and Pat-tern Recognition (CVPR), pages 4334–4343, 2020. 6
[31] Ke Mei, Chuang Zhu, Jiaqi Zou, and ShanghangZhang. Instance adaptive self-training for unsuper-vised domain adaptation. InEuropean Conference onComputer Vision, pages 415–430, 2020. 6
[32] Luke Melas-Kyriazi and Arjun K Manrai. Pixmatch:Unsupervised domain adaptation via pixelwise consis-tency training. InProceedings of the IEEE/CVF Con-ference on Computer Vision and Pattern Recognition,pages 12435–12445, 2021. 1, 2
[33] Zak Murez, Soheil Kolouri, David Kriegman, RaviRamamoorthi, and Kyungnam Kim. Image to imagetranslation for domain adaptation. In2018 IEEE/CVFConference on Computer Vision and Pattern Recogni-tion, pages 4500–4509, 2018. 1
[34] Fei Pan, Inkyu Shin, Francois Rameau, Seokju Lee,and In So Kweon.Unsupervised intra-domainadaptation for semantic segmentation through self-supervision. In2020 IEEE/CVF Conference on Com-puter Vision and Pattern Recognition (CVPR), pages3764–3773, 2020. 2
[35] Hang Qi, Matthew Brown, and David G Lowe. Low-shot learning with imprinted weights. InProceedingsof the IEEE conference on computer vision and pat-tern recognition, pages 5822–5830, 2018. 3
[36] Stephan R Richter, Vibhav Vineet, Stefan Roth, andVladlen Koltun. Playing for data: Ground truth fromcomputer games. InEuropean conference on com-puter vision, pages 102–118. Springer, 2016. 1, 6
[37] German Ros, Laura Sellart, Joanna Materzynska,David Vazquez, and Antonio M Lopez. The synthiadataset: A large collection of synthetic images for se-mantic segmentation of urban scenes. InProceedingsof the IEEE conference on computer vision and pat-tern recognition, pages 3234–3243, 2016. 1, 6
[38] Jake Snell, Kevin Swersky, and Richard S. Zemel.Prototypical networks for few-shot learning. InAd-vances in Neural Information Processing Systems,volume 30, pages 4077–4087, 2017. 3
[39] Yi-Hsuan Tsai, Wei-Chih Hung, Samuel Schulter, Ki-hyuk Sohn, Ming-Hsuan Yang, and Manmohan Chan-draker. Learning to adapt structured output space forsemantic segmentation. In2018 IEEE/CVF Confer-ence on Computer Vision and Pattern Recognition,pages 7472–7481, 2018. 1, 2, 6
[40] Yi-Hsuan Tsai, Kihyuk Sohn, Samuel Schulter, andManmohan Chandraker. Domain adaptation for struc-tured output via discriminative patch representationsIn2019 IEEE/CVF International Conference on Com-puter Vision (ICCV), pages 1456–1465, 2019. 2
[41] Tuan-Hung Vu, Himalaya Jain, Maxime Bucher,Matthieu Cord, and Patrick Perez. Advent: Adversar-ial entropy minimization for domain adaptation in se-mantic segmentation. In2019 IEEE/CVF Conferenceon Computer Vision and Pattern Recognition (CVPR),pages 2517–2526, 2019. 6
[42] Haoran Wang, Tong Shen, Wei Zhang, Lingyu Duan,and Tao Mei. Classes matter: A fine-grained adversar-ial approach to cross-domain semantic segmentation.InECCV (14), pages 642–659, 2020. 6
[43] Wenguan Wang, Tianfei Zhou, Fisher Yu, Jifeng Dai,Ender Konukoglu, and Luc Van Gool.Exploringcross-image pixel contrast for semantic segmentation.InProceedings of the IEEE/CVF International Con-ference on Computer Vision, pages 7303–7313, 2021.1
[44] ZuxuanWu,XintongHan,Yen-LiangLin,Mustafa G ̈okhan Uzunbas, Tom Goldstein, Ser NamLim, and Larry S. Davis. Dcan: Dual channel-wisealignment networks for unsupervised scene adapta-tion. InProceedings of the European Conference onComputer Vision (ECCV), pages 518–534, 2018. 2
[45] Junyuan Xie, Ross Girshick, and Ali Farhadi. Un-supervised deep embedding for clustering analysis.InICML’16 Proceedings of the 33rd InternationalConference on International Conference on MachineLearning - Volume 48, pages 478–487, 2016. 2
[46] Xueting Yan, Ishan Misra, Abhinav Gupta, DeeptiGhadiyaram, and Dhruv Mahajan. Clusterfit: Improv-ing generalization of visual representations. In2020IEEE/CVF Conference on Computer Vision and Pat-tern Recognition (CVPR), pages 6509–6518, 2020. 2
[47] Jianwei Yang, Devi Parikh, and Dhruv Batra. Jointunsupervised learning of deep representations and im-age clusters. In2016 IEEE Conference on ComputerVision and Pattern Recognition (CVPR), pages 5147–5156, 2016. 2
[48] Yanchao Yang and Stefano Soatto. Fda: Fourier do-main adaptation for semantic segmentation. InPro-ceedings of the IEEE/CVF Conference on ComputerVision and Pattern Recognition, pages 4085–4095,2020. 2, 6
[49] Sangdoo Yun, Dongyoon Han, Seong Joon Oh,Sanghyuk Chun, Junsuk Choe, and Youngjoon Yoo.Cutmix: Regularization strategy to train strong classi-fiers with localizable features. InProceedings of theIEEE/CVF International Conference on Computer Vi-sion, pages 6023–6032, 2019. 6
[50] Pan Zhang, Bo Zhang, Ting Zhang, Dong Chen, YongWang, and Fang Wen. Prototypical pseudo label de-noising and target structure learning for domain adap-tive semantic segmentation. 1, 2, 3, 5, 6, 7
[51] Qiming Zhang, Jing Zhang, Wei Liu, and DachengTao. Category anchor-guided unsupervised domainadaptation for semantic segmentation.arXiv preprintarXiv:1910.13049, 2019. 1, 2, 4, 6, 7
[52] Yang Zhang, Philip David, and Boqing Gong. Cur-riculum domain adaptation for semantic segmentationof urban scenes. In2017 IEEE International Confer-ence on Computer Vision (ICCV), pages 2039–2049,2017. 1, 6
[53] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiao-gang Wang, and Jiaya Jia. Pyramid scene parsingnetwork. InProceedings of the IEEE conference oncomputer vision and pattern recognition, pages 2881–2890, 2017. 1, 2
[54] Chengxu Zhuang, Alex Zhai, and Daniel Yamins.Local aggregation for unsupervised learning of vi-sual embeddings. In2019 IEEE/CVF InternationalConference on Computer Vision (ICCV), pages 6002–6012, 2019. 2
[55] Yang Zou, Zhiding Yu, BVK Kumar, and JinsongWang. Unsupervised domain adaptation for seman-tic segmentation via class-balanced self-training. InProceedings of the European conference on computervision (ECCV), pages 289–305, 2018. 2, 4, 6
[56] Yang Zou, Zhiding Yu, B. V. K. Vijaya Kumar,and Jinsong Wang. Unsupervised domain adaptationfor semantic segmentation via class-balanced self-training. InProceedings of the European Conferenceon Computer Vision (ECCV), pages 297–313, 2018. 1,6
[57] Yang Zou, Zhiding Yu, Xiaofeng Liu, B. V. K. Vi-jaya Kumar, and Jinsong Wang. Confidence regular-ized self-training. In2019 IEEE/CVF InternationalConference on Computer Vision (ICCV), pages 5982–5991, 2019. 1, 2, 4
[58] Miguel ́Angel Bautista, Artsiom Sanakoyeu, Ekate-rina Tikhoncheva, and Bj ̈orn Ommer.Cliquecnn:Deep unsupervised exemplar learning. InAdvances inNeural Information Processing Systems, volume 29,pages 3846–3854, 2016. 211