MICCAI 2022 | ASA:用于预训练脑核磁分割的注意力对称自动编码器
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
题目:MICCAI 2022 | ASA:用于预训练脑核磁分割的注意力对称自动编码器开源
作者:黄俊嘉 李灏峰
论文地址:https://arxiv.org/abs/2209.08887
代码地址:https://github.com/lhaof/ASA
本文解读了深圳市大数据研究院联合中山大学发表在MICCAI 2022的《Attentive Symmetric Autoencoder for Brain MRI Segmentation》,该工作属于被提前接受(Early Accept)的前13%的文章。

本文提出了提出了一种基于Vision Transformer (ViT) 的新型注意力对称自动编码器 (ASA),用于 3D 大脑 MRI 分割任务,在三个脑 MRI 分割基准上优于最先进的自监督学习方法和医学图像分割模型。
1. 研究背景:
为磁共振成像 (MRI) 数据准确分割脑部病变、肿瘤或组织对于构建计算机辅助诊断 (CAD) 系统至关重要,并有助于医学专家改进诊断和治疗计划。十分有必要开发一种用于脑MRI的自动分割工具。而近几年基于图像块重建的自监督学习方法在训练自动编码器方面取得了巨大成功,其预训练的权重可以转移到微调图像理解的其他下游任务。然而,现有方法在应用于 3D 医学图像时很少研究重建斑块的各种重要性和解剖结构的对称性。
观察到这样特征,在本文中,作者提出了:
1. 新颖的注意力重建损失函数。
2. 一种新的对称位置编码方法。
3. 基于注意力对称自动编码器的用于脑 MRI 分割的自监督学习(Self-Supervised Learning, SSL) 框架。
该框架主要分为三个模块,对称位置编码模块,编码器-解码器模块和基于自注意力的重建损失模块
2. 研究方法
本文提出的主要框架主要分为三个模块,对称位置编码模块,编码器-解码器模块和基于自注意力的重建损失模块,整体框架如图1所示。此框架在三个公开数据集上进行了测试,对比了三种Transformer-based的方法和两种医学领域自监督的方法。

图1 ASA自监督结构示意图
2.1 基于注意力的重建损失模块
在这个模块中,作者主要考虑如何讲脑部区域重要性区分开来,文章中提出了一种基于注意力的重建损失,主要基于3D VHOG[6],文章通过梯度算子![]() 计算MRI图像中的各体素点梯度
计算MRI图像中的各体素点梯度![]() , 利用两个变量
, 利用两个变量![]() 来表示体素在球形坐标的位置:
来表示体素在球形坐标的位置:

对于每个图像块,都构建一个2D的直方图G,将直方图单位距离(bin,桶)设定为![]() ,接着为了计算G值,接着遍历图像块中的每一个体素,用
,接着为了计算G值,接着遍历图像块中的每一个体素,用![]() 表示当前体素的方向。具体来说,先确定体素的桶索引为
表示当前体素的方向。具体来说,先确定体素的桶索引为![]() ,
,![]()
然后将当前体素的梯度大小![]() 累加到2D的梯度直方图G对应的桶索引
累加到2D的梯度直方图G对应的桶索引![]() 中。处理完图像块的所有体素后,我们对图像块直方图进行
中。处理完图像块的所有体素后,我们对图像块直方图进行![]() 标准化,并计算出每个图像块直方图G的平均值
标准化,并计算出每个图像块直方图G的平均值![]() ,最后我们通过归一化所有图像块均值来获得第
,最后我们通过归一化所有图像块均值来获得第![]() 个图像块的重要程度
个图像块的重要程度![]() 。
。
最后采用均方误差 (MSE) 来衡量恢复的图像区域与原始图像区域之间的体素级差异,总损失可以表示为:

其中X,Y是重建图像和原始图像,N是图像中被掩码掩蔽的图像块数量。M是图像块中的体素数。![]() 表示图像 X 中第i个块的第j个体素值。
表示图像 X 中第i个块的第j个体素值。
2.2 对称位置编码模块
依据大脑结构的左右对称性的先验信息,本文提出了一种对称位置编码的方法,如图2所示,能够缩小两个对称的图像位置的编码差异,并且可以鼓励模型从这两个相关区域中获取更好的特征。对称位置编码能够让同一行中对称的图像块能够共享相同的位置编码。具体来说,令T×H×W,(t,h,w)表示图像块的编号和图像块的坐标,对称位置编码可以计算为式(3)

其中D是对称位置编码向量的维度数,与图像块的切入通道数相同,PE(⋅)表示为(t,h,w)处的图像块返回对称位置编码向量的第2i/(2i+1)个元素。对称位置编码模块被使用了两次,一次与图像块嵌入相加,另一次在编解码器中与掩码令牌相连接。
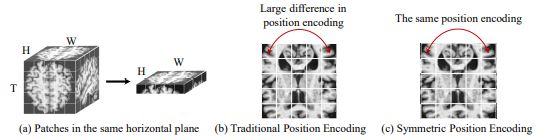
图2 对称位置编码模块示意
2.3 整体网络结构
文章提出的ASA框架在下游任务中的网络结构如图3所示,基于ViT[12]并借鉴Swin Transformer[13]提出了线性窗口的多头注意力和移动线性窗口的多头注意力,在一维层面进行窗口注意力机制。

图3 ASA下游任务网络结构
3 实验结果
作者采用计算 Dice 系数分数 (Dice) 和 95% Hausdorff 距离 (HD95) 以评估实验中的分割结果,在三个数据集上进行了对比实验和消融实验。
3.1 数据集
预训练数据集:预训练数据主要来自两个公共数据集的T1模态的MRI,包括来自阿尔茨海默病神经影像学倡议 (ADNI) 数据集[4]的9952例病例和来自开放存取系列影像研究(OASIS)数据集[5] 的 2041 例病例。
下游任务数据集:本文在三个MRI分割数据集上进行了测试,包括BraTS 2021数据集[1],IBSR数据集[2]和WMH数据集[3]。这三个数据集分别包含1251个,18个和60个MRI样本,分割目标也由肿瘤到脑部灰白质分割多样。
3.2 对比实验
作者将提出方法与现有的基于3D Transformer的图像分割模型(nnFormer[7] 、TransBTS[8] 、UNETR[10] )和 3D 自监督方法[11](相对 3D 补丁位置(3D-RPL)、3D Jigsaw)在三个数据集上进行比较,所有自监督方法都针对分割模型的编码器部分进行预训练并配合上U形解码器结构得到图像分割结果,结果如表1和表2所示。

表1 在BraTS 2021数据集上的分割结果
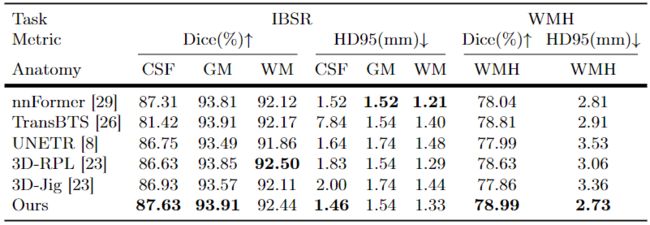
表2 在IBSR数据集和WMH数据集上的分割结果
在BraTS2021数据集上,作者提出的方法在 WT、TC、ET 上实现了 94.03%、90.29%、86.76% 的 Dice 分数和 3.61mm、3.78mm 和 10.25mm 的 HD95。与基于Transformer的方法相比,该方法在这两个指标上都取得了显着更好的性能。此外,ASA比使用相同图像分割网络的其他 SSL 方法显示出更具竞争力的结果。对于 ET 类别,ASA在 HD95 中比 3D-RPL 和 3D-Jig 低 3.46mm 和 1.54mm。可视化结果如图4所示,本文的方法在ET区域(蓝色)实现了更准确的预测。而在表2中的IBSR数据集和WMH数据集上,本文的方法在CSF和GM和WMH上都显示了最高的Dice分数。
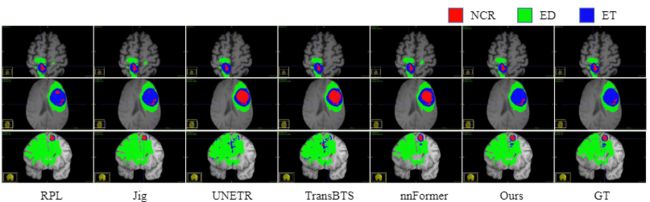
图4 可视化结果
3.2 消融实验
作者在BraTS 2021数据集上进行了详尽的消融实验,探索了基于注意力的重建损失(AR-Loss)和对称位置编码(SPE)以及自监督框架的作用,结果如表3所示。

表3 消融实验结果
在表3中,‘Baseline’表示分割网络从头开始训练的结果,‘w/SSL’表示使用由3D掩码自动编码器[9](MAE)自监督方法预训练模型后的结果,‘A-SSL’表示将基于注意力的重建损失引用的自监督网络后的结果,如表的上半部分所示,‘A-SSL’的方法在HD95指标上比SSL产生了更准确的分割结果,表明‘AR-Loss’可以鼓励编码器学习更好的边界信息表示。而在表的下半部分,作者比较了对称位置编码的作用,同样效果对比‘Baseline’在Dice分数中高出0.9%,这表明对称位置编码可以帮助编码器理解脑部的对称结构并获得分割特征。
4 总结
总的来说,作者为 3D 医学图像提出了一种新颖的自监督学习架构。 所提出的框架包含两个关键组件,对称位置编码和注意力重建损失。 编码可以有利于对称结构的特征学习,注意力损失强调基于重建的SSL的信息图像区域。 这两种技术都可以提高训练模型的泛化能力。本文是对主要方法的解读,更多的细节见原文。
注:文末附【医学图像交流群】二维码
参考文献
[1] Menze, B.H., Jakab, A., Bauer, S., Kalpathy-Cramer, J., Farahani, K., Kirby, J., Burren, Y., Porz, N., Slotboom, J., Wiest, R., et al.: The multimodal brain tumor image segmentation benchmark (brats). IEEE TMI 34(10), 1993–2024 (2014)
[2] Rohlfing, T., Brandt, R., Menzel, R., Maurer Jr, C.R.: Evaluation of atlas selection strategies for atlas-based image segmentation with application to confocal microscopy images of bee brains. NeuroImage 21(4), 1428–1442 (2004)
[3] Kuijf, H.J., Biesbroek, J.M., De Bresser, J., Heinen, R., Andermatt, S., Bento, M., Berseth, M., Belyaev, M., Cardoso, M.J., Casamitjana, A., et al.: Standardized assessment of automatic segmentation of white matter hyperintensities and results of the wmh segmentation challenge. IEEE TMI 38(11), 2556–2568 (2019)
[4] Jack Jr, C.R., Bernstein, M.A., Fox, N.C., Thompson, P., Alexander, G., Harvey, D., Borowski, B., Britson, P.J., L. Whitwell, J., Ward, C., et al.: The alzheimer’s disease neuroimaging initiative (adni): Mri methods. Journal of Magnetic Resonance Imaging: An Official Journal of the International Society for Magnetic Resonance in Medicine 27(4), 685–691 (2008)
[5] LaMontagne, P.J., Benzinger, T.L., Morris, J.C., Keefe, S., Hornbeck, R., Xiong, C., Grant, E., Hassenstab, J., Moulder, K., Vlassenko, A.G., et al.: Oasis-3: longitudinal neuroimaging, clinical, and cognitive dataset for normal aging and Alzheimer disease. MedRxiv (2019)
[6] Dupre, R., Argyriou, V., Greenhill, D., Tzimiropoulos, G.: A 3d scene analysis framework and descriptors for risk evaluation. In: 2015 International Conference on 3D Vision. pp. 100–108 (2015). https://doi.org/10.1109/3DV.2015.19
[7] Zhou, H.Y., Guo, J., Zhang, Y., Yu, L., Wang, L., Yu, Y.: nnformer: Interleaved transformer for volumetric segmentation. arXiv preprint arXiv:2109.03201 (2021)
[8] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information processing systems 30 (2017)
[9] He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners. arXiv preprint arXiv:2111.06377 (2021)[10] Hatamizadeh, A., Tang, Y., Nath, V., Yang, D., Myronenko, A., Landman, B., Roth, H.R., Xu, D.: Unetr: Transformers for 3d medical image segmentation. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 574–584 (2022)
[11] Taleb, A., Loetzsch, W., Danz, N., Severin, J., Gaertner, T., Bergner, B., Lippert, C.: 3d self-supervised methods for medical imaging. Advances in Neural Information Processing Systems 33, 18158–18172 (2020)
[12] Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020) [13] Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer: Hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF ICCV. pp. 10012–10022 (2021)
重磅!医学图像 交流群成立
扫描下方二维码,或者添加微信:CVer222,即可添加CVer小助手微信,便可申请加入CVer-医疗影像微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如医疗影像+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer222,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看